【HBase】知识小结+HMaster选举、故障恢复、读写流程
1:什么是HBase
HBase是一个高可靠性,高性能,面向列,可伸缩的分布式数据库,提供海量数据存储功能,一个结构化的分布式存储系统,不同于一般的关系型数据库,它适合半结构化和非结构化数据存储。
2:HBase表的特点
大:一个表中可以有数十亿行,上百万列
无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列
面向列:面向列存储和权限控制
稀疏:空列并不占用存储空间,可以设计的非常稀疏
数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入的时间戳
数据类型单一:Hbase中的数据都是字符串,没有类型
3:HBase架构
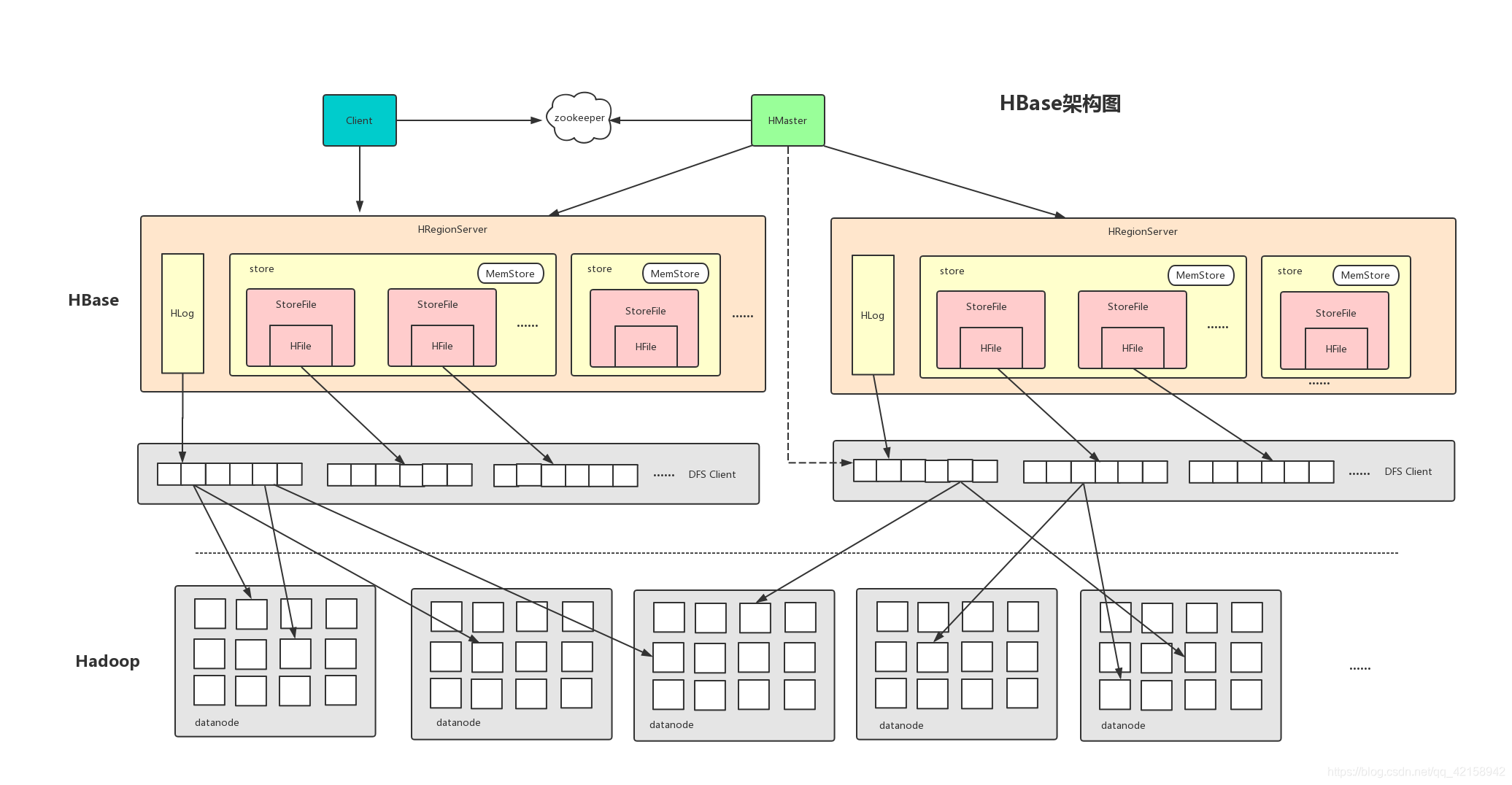
HBase由client,zookeeper,HMaster,HRegionServer,HRegion以及StoreFile和HFile组成
Client
是HBase的接口,并维护cache来加快对HBase的访问,client不是直接和HMaster直接通信,而是和ZooKeeper,通过Zookeeper返回HRegionServer,在client去找对应的HRegionServer
HMaster是主节点
HMaster进程负责管理所有的RegionServer,包括新的RegionServer的注册,RegionServer的故障切换处理。负责RegionServer的负载均衡。发现失效的RegionServer并重新分配其上的Region。管理用户对table的增删改查工作。GFS上的垃圾文件回收。处理Schema更新请求.
Zookeeper
保证任何时候集群只有一个Master。存储region的寻址入口。实现监控RegionServer的上线和下线信息,并实现通知给Master。存储HBase的schma和table元数据.
HRegion Server
HRegionServer是HBase的从点,它负责提供表数据读写等服务,是数据存储和计算单元。一台HRegionServer管理多个Region和一个Hlog
Region Server负责维护Master分配给它的Region,处理对这些Region的IO请求
Region Server负责切分在运行过程中变得过大的Region
Region
一个region由一个或多个store组成,每个store存储该region一个列簇的数据,一个store包含一个memstore缓存以及若干StoreFile文件,Memstore缓存客户端向region插入的数据,当HregionServer中的Memstore大小达到配置容量上限时,RegionServer会将Memstore中的数据刷新(flush)到HDFS中,成为Hfile。
Region是将一个数据表按Key值范围横向划分为一个个的子表,实现分布式存储
Region分为元数据Region以及用户Region两类
元数据Region也叫Meta Region,记录了每个Region的路由信息,每个子表的存放位置,起始Key值,元数据Region存放在Root表中,Root表则存放在Zookeeper中
读取Region数据的路由需要以下几步
1:在Zookeeper只查找Meta Region的地址
2:再由Meta Region中寻找User Region的地址
Zookeeper(HMaster选举流程)
主备Master同时向ZooKeeper注册自己的节点信息,谁先写入,谁就是主节点
注册写入时会查询有没有相对应的节点,如果有,这个HMaster查看主节点是谁,如果主Master有相对应的节点并且实时更新了,那么这个HMaster就会自动作为备节点,进入休眠状态
备节点会实时监听ZooKeeper的状态主节点的信息
在系统开始时,主备节点都会向Zookeeper里面创建一个目录,比如叫HBase,在目录中写入节点信息,创建之前先去查询里面有没有这个目录以及目录里面文件的时间戳信息与当前节点的时间戳信息做对比,如果对比超过了5秒钟,那说明这个节点已经损坏了主节点每隔一秒更新下时间戳,备节点每隔一秒去查询下时间戳,当主节点宕机时,时间戳没更新,备节点查询超过5秒钟没有更新,意味着主节点已经宕机,备节点非常高兴的把自己的节点信息写入,变成主节点
保证任何时候,集群中只有一个Master
存储所有Region的寻址入口
实时监控Region Server的状态,将Region Server的上线和下线信息实时通知给Master
存储HBase的Schema,包括有哪些Table,每个Table有哪些Column family
MemStore和StoreFile
MenStore相当于缓存功能,数据会先写入MemStore,然后再写入StoreFile
当MemStore大小达到某个值时,会进行刷盘操作,启动flashcache进程,把MenStore数据生成StoreFile文件
HDFS也会有合并文件的操作,不适合存储文件数量太多的文件,HDFS不适合文件随机的修改和删除,所有操作都是在文件的末尾做追加
HBase数据的修改和删除是在数据合并时,才会真正的做修改和删除
4:HBase Write-Ahead_log(WAL)机制,容错与恢复
该机制用于数据的容错和恢复
每个HRegionServer中都有一个HLog对象,HLog是一个实现Write Ahead log的类,在每次用户操作写入MemStore的同时,也会写一份数据到HLog文件中,HLog文件定期滚动出新的,并删除旧的文件,即已经持久化到StoreFile中的数据,当HRegionServer意外终止后,HMaster会通过Zookeeper感知到,HMaster首先会处理遗留的HLog文件,将其中不同Region的Log数据进行拆分,分别放到相应Region的目录下,然后再将失效的Region重新分配,领取到这些Region的HRegionServer在Load Region的过程中,会发现有历史HLog需要处理,因此会Replay Hlog中的数据到MemStore中,然后Flush到StoreFiles,完成数据恢复
1.RegionServer故障,ZK感知到。
2.通知HMaster
3.HMstaer拆分Hlog,根据所属region来拆分。
4.拆分后,存放到对应的region的目录里面去。
5.把故障的region分配到其他的RegionServer.
6.新的RegionServer加载故障的region,加载相应的Hlog文件。
5:HBase的写流程
数据写请求首先发给client,client查询该数据应该往哪个地方存储,会去zookeeper查询MetaRegion获取现在要写入数据应该在哪个Region里面,获取到之后,再根据获取额结果做个分组,发给各个RegionServer,数据并发写入,数据先写入MemStore,然后再写入HLog,写完后,HMaster也会做相应的更新,然后才会返回写成功
当MemStore达到一定值时,也会做个刷盘操作,生成一个新的HFile文件,当HFile文件变多之后,也会做个合并,数据最终存放在DataNode里面
1.客户端发起写请求
2.客户端会和ZK通讯,请求meta-region的路由信息。
3.得到ZK返回后,会和相应的RegionServer通讯。
4.在相应的meta-region表中读到数据存放位置。
5.将数据根据regionserver和region进行的分组打包
6.获得region锁机制
7.并行发送到各个RegionServer上。
8.数据写入相应Store里面的MemStore,同时会在Hlog里面写一份。
9.RegionServer通知HMaster更新信息。
10.返回写成功。
PS:HBase,数据删除,是在数据整合/合并的时候完成的。
数据越来越多,生成的StoreFile越来越大,数据合并;分裂成形成新的StoreFile;
数据持续增加,RegionServer会把Region分裂成两个region,通知HMaster更新信息。
6:HBase的读流程
客户端发起请求,通过Zookeeper寻找到Meta表所在RegionServer,通过RowKey查找Meta表,获取所要读取的Region所在RegionServer,请求发送到该RegionServer,由其具体处理数据读取
1.客户端发起读请求。
2.客户端回合ZK通讯,请求ROOT表,读元数据region的路由信息。
3.收到ZK返回之后,会和相应的Regionserver.找到相应的meta-region,获取数据的位置
4.收到返回后,到数据所在的Region上读取数据。
【HBase】知识小结+HMaster选举、故障恢复、读写流程的更多相关文章
- HBase 数据读写流程
HBase 数据读写流程 2016-10-18 杜亦舒 读数据 HBase的表是按行拆分为一个个 region 块儿,这些块儿被放置在各个 regionserver 中 假设现在想在用户表中获取 ro ...
- HBase二级索引、读写流程
HBase二级索引.读写流程 一.HBse二级索引方案 1.1 基于Coprocessor方案 1.2 Phoenix二级索引特点 1.3 Phoenix 二级索引方案 二.HBase读写流程 2.1 ...
- Hbase的读写流程
HBase读写流程 1.HBase读数据流程 HRegionServer保存着meta表以及表数据,要访问表数据,首先Client先去访问zookeeper,从zookeeper里面获取meta表所在 ...
- zookeeper的读写流程
zookeeper的读写流程 基本架构 节点数要求是奇数. 常用的接口是 get/set/create/getChildren. 读写流程 写流程 客户端连接到集群中某一个节点 客户端发送写请求 服务 ...
- S3C6410 SPI全双工读写流程分析(原创)【转】
转自:http://blog.csdn.net/hustyangju/article/details/21165721 原创博文,知识共享!转载请注明出处:http://blog.csdn.net/h ...
- Android app开发知识小结
Android知识小结 这是一个知识的总结,所以没有详解的讲解. 一.分辨率Android中dp长度.sp字体使用.px像素.in英寸.pt英寸1/72.mm毫米 了解dp首先要知道density,d ...
- HDFS文件读写流程
一.HDFS HDFS全称是Hadoop Distributed System.HDFS是为以流的方式存取大文件而设计的.适用于几百MB,GB以及TB,并写一次读多次的场合.而对于低延时数据访问.大量 ...
- C/C++ 位域知识小结
C/C++ 位域知识小结 几篇较全面的位域相关的文章: http://www.uplook.cn/blog/9/93362/ C/C++位域(Bit-fields)之我见 C中的位域与大小端问题 内存 ...
- 【转】linux IO子系统和文件系统读写流程
原文地址:linux IO子系统和文件系统读写流程 我们含有分析的,是基于2.6.32及其后的内核. 我们在linux上总是要保存数据,数据要么保存在文件系统里(如ext3),要么就保存在裸设备里.我 ...
随机推荐
- 微信小程序-swiper(轮播图)抖动问题
ps:问题 组件swiper(轮播图)真机上不自动滚动 一直卡在那里抖动 以前遇到这个问题,官方一直没有正面回复.就搁置了,不过有大半年没写小程序了也没去关注,今天就去看了下官方文档,发觉更新了点好东 ...
- 可怕!CPU竟成了黑客的帮凶!
本故事根据CPU真实漏洞改编 前情回顾 还记得我吗,我是阿Q,就是那个CPU一号车间的阿Q啊.如果你忘记了我,记得看看这里回忆一下哦:完了!CPU一味求快出事儿了! 自从我们车间用上了乱序执行和分支预 ...
- [hdu4768]二分
http://acm.hdu.edu.cn/showproblem.php?pid=4768 题意:n个传单分别发给编号为ai, ai + ci, ai + 2 * ci, .. , ai + k * ...
- jstree 反选,测试400条数据左右有点卡
$("#reversecheckallmachines").on("change", function () { var checkedNodes = []; ...
- PMS学习
一,PMS的adb相关重要指令 1,adb shell dumpsys package(dump所有的系统内apk信息) 2,adb shell dumpsys package “com.androi ...
- 7、会话框添加查看get与post请求类型
前言 在使用fiddler抓包的时候,查看请求类型get和post每次只有点开该请求,在Inspectors才能查看get和post请求,不太方便.于是可以在会话框直接添加请求方式. 一.添加会话框菜 ...
- ES6新增API
1.Object.assign(a,b,c) a.b均为对象,意思是把b对象的属性添加到a上面去.如果a中已经定义了某个属性,b也定义了的话就会覆盖a的,就是后面覆盖前面的,后面生命的有效.是 一种浅 ...
- vue element-ui el-form-item 循环渲染,验证表单内容
data里面如下图:
- docer run 、docker attach 与 docker exec的区别
进入容器的方式有以下三种: 使用ssh登陆进容器 使用nsenter.nsinit等第三方工具 使用Docker本身提供的工具 最佳方案为使用Docker本身提供的工具 docker run:创建和启 ...
- 【雕爷学编程】MicroPython动手做(04)——零基础学MaixPy之尝试运行
1.hello micropython #MicroPython动手做(04)——零基础学MaixPy之基本示例 #程序之一:hello micropython #MicroPython动手做(04) ...