Hadoop2.7.7 centos7 完全分布式 配置与问题随记
Hadoop2.7.7 centos7 完全分布式 配置与问题随记
这里是当初在三个ECS节点上搭建hadoop+zookeeper+hbase+solr的主要步骤,文章内容未经过润色,请参考的同学搭配其他博客一同使用,并记得根据实际情况调整相关参数。
0.prepare
jdk,推荐1.8
关闭防火墙
开放ECS安全组
三台机器之间的免密登陆ssh
ip映射:【question1】hadoop启动时出现报错java.net.BindException: Cannot assign requested address
说明ip映射没有配置正确,正确的方式是在每一个节点上,都执行"内外外"的配置方式,即将本机与本机的内网ip对应,其他机器设置为外网ip
下面的文件要在每个节点上都修改
1. vi /etc/profile
1. vi /etc/profile
/opt/hadoop/hadoop-2.7.7
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.7
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH
#使环境变量生效
souce /etc/profile
#检验
hadoop version
2. vi /.../hadoop-2.7.7/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Gwj:8020</value>
<description>定义默认的文件系统主机和端口</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
<description>流文件的缓冲区为4K</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/hadoop-2.7.7/tempdata</value>
<description>A base for other temporary directories.</description>
</property>
</configuration>
3. vi /.../hadoop-2.7.7/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop/hadoop-2.7.7/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/hadoop-2.7.7/dfs/data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!--后增,如果想让solr索引存放到hdfs中,则还须添加下面两个属性-->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!--【question2】SecondayNameNode默认与NameNode在同一台节点上,在实际生产过程中有安全隐患。解决方法:加入如下配置信息,指定NameNode和SecondaryNameNode节点位置-->
<property>
<name>dfs.http.address</name>
<value>Gwj:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Ssj:50090</value>
</property>
</configuration>
4. vi /.../hadoop-2.7.7/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>local</value>
</property>
<!-- 指定mapreduce jobhistory地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<!-- 任务历史服务器的web地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
</configuration>
5. vi /.../hadoop-2.7.7/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Gwj</value>
<description>指定resourcemanager所在的hostname</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序 </description>
</property>
</configuration>
6.vi /.../hadoop-2.7.7/etc/hadoop/slaves
老版本是slaves文件,3.0.3 用 workers 文件代替 slaves 文件
将localhost删掉,加入dataNode节点的主机名
[root@Gwj ~]# cat /opt/hadoop/hadoop-2.7.7/etc/hadoop/slaves
Ssj
Pyf
7.首次使用进行格式化
hdfs namenode -format
8.启动
/.../hadoop-2.7.7/sbin/start/start-all.sh
hdfs
/.../hadoop-2.7.7/sbin/start/start-dfs.sh
Yarn
/.../hadoop-2.7.7/sbin/start/start-yarn.sh
#start可替换为stop、status
9.检验
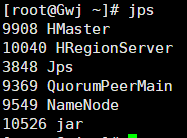
使用jps检验
hadoop
hdfs
Master---NameNode (SecondaryNameNode)
Slave---DataNode
Yarn
Master---ResourceManager
Slave---NodeManager
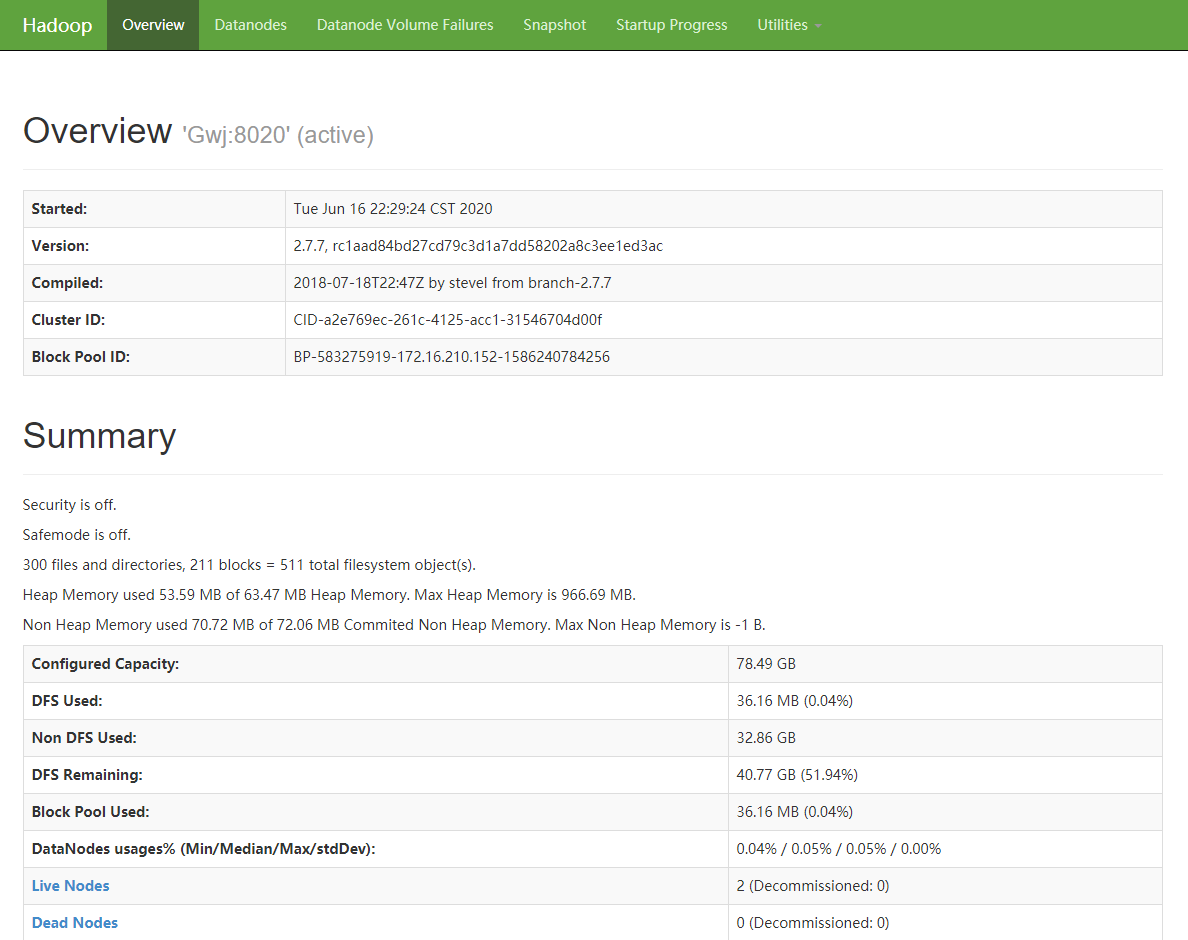
或者使用 “Master ip+50070”
---以下的yarn未设置,注意<configuration>!!!
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>The https adddress of the RM web application.</description>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
<discription>每个节点可用内存,单位MB,默认8182MB,根据阿里云ECS性能配置为2048MB</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
Hadoop2.7.7 centos7 完全分布式 配置与问题随记的更多相关文章
- hadoop安装教程,分布式配置 CentOS7 Hadoop3.1.2
安装前的准备 1. 准备4台机器.或虚拟机 4台机器的名称和IP对应如下 master:192.168.199.128 slave1:192.168.199.129 slave2:192.168.19 ...
- 在Linux(Centos7)系统上对进行Hadoop分布式配置以及运行Hadoop伪分布式实例
在Linux(Centos7)系统上对进行Hadoop分布式配置以及运行Hadoop伪分布式实例 ...
- Data - Hadoop伪分布式配置 - 使用Hadoop2.8.0和Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- Ubuntu14.04下hadoop-2.6.0单机配置和伪分布式配置
需要重新编译的教程:http://blog.csdn.net/ggz631047367/article/details/42460589 在Ubuntu下创建hadoop用户组和用户 hadoop的管 ...
- Hadoop安装教程_单机/伪分布式配置_CentOS6.4/Hadoop2.6.0
Hadoop安装教程_单机/伪分布式配置_CentOS6.4/Hadoop2.6.0 环境 本教程使用 CentOS 6.4 32位 作为系统环境,请自行安装系统.如果用的是 Ubuntu 系统,请查 ...
- 分布式配置hadoop2.5.0 2.6.x
1. sudo vim /etc/hostname 在master的机器上,改成 master 在slave上写 slave01,02,03...... 配置好后重启. 2. sudo vi ...
- CentOS7-64bit 编译 Hadoop-2.5.0,并分布式安装
摘要 CentOS7-64bit 编译 Hadoop-2.5.0,并分布式安装 目录[-] 1.系统环境说明 2.安装前的准备工作 2.1 关闭防火墙 2.2 检查ssh安装情况,如果没有则安装ssh ...
- 转载:Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
原文 http://www.powerxing.com/install-hadoop/ 当开始着手实践 Hadoop 时,安装 Hadoop 往往会成为新手的一道门槛.尽管安装其实很简单,书上有写到, ...
- Hadoop安装教程_单机/伪分布式配置_Hadoop2.6.0/Ubuntu14.04
摘自: http://www.cnblogs.com/kinglau/p/3796164.html http://www.powerxing.com/install-hadoop/ 当开始着手实践 H ...
随机推荐
- swagger--Failed to load API definition.
打开 http://localhost:5000/swagger/v1/swagger.json 提示错误 An unhandled exception occurred while processi ...
- ModelAndView的部分回顾
ModelAndView的部分回顾 //@RestController @Controller //@SessionAttributes("user") //把modelandvi ...
- 【Flutter实战】移动技术发展史
老孟导读:大家好,这是[Flutter实战]系列文章的第一篇,这并不是一篇Flutter技术文章,而是介绍智能手机操作系统.跨平台技术的演进以及我对各种跨平台技术看法的文章. 智能手机操作系统 塞班( ...
- Dubbo+Zookeeper集群案例
一.开源分布式服务框架 1.Dubbo是阿里巴巴公司开源的一个高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以Spring框架无缝集成. Dubbo是一款高性 ...
- Azure AD(四)知识补充-服务主体
一,引言 又到了新的一周了,也到了我新的分享的时间了,还记得上一周立得Flag,其中 “保证每周输出一篇文章” ,让我特别“在意”(这里用词不太恰当).主要是我的一个大学舍友,他突然问了我一个关于写博 ...
- CentOS6.5 开机启动自动运行redis服务
[一].查找和设置自己的redis路径参数 环境变量 PATH=/usr/local/bin:/sbin/:/usr/bin:/bin 端口 REDISPORT=6379 文件位置 EXEC=/usr ...
- php使用json_encode中遇见问题?
注:php版本5.4下,不支持json_encode对中文的处理,要么升级php版本. json_encode($value,$options) 其中有2个比较常用到的参数: 1.JSON_UNESC ...
- (九)HttpClient获取cookies
原文链接:https://blog.csdn.net/cheny1p1ng/article/details/90780024 旧版本DefaultHttpClient 使用getCookieStore ...
- WeChair项目Beta冲刺(6/10)
团队项目进行情况 1.昨日进展 Beta冲刺第六天 昨日进展: 前后端并行开发,项目按照计划有条不絮进行 2.今日安排 前端:扫码占座功能和预约功能并行开发 后端:扫码占座后端逻辑开发,编码预约 ...
- 多语言工作者の十日冲刺<3/10>
这个作业属于哪个课程 软件工程 (福州大学至诚学院 - 计算机工程系) 这个作业要求在哪里 团队作业第五次--Alpha冲刺 这个作业的目标 团队进行Alpha冲刺--第三天(05.02) 作业正文 ...