One-Hot Encoding(独热编码)
前几天查了一些与独热编码相关的资料后,发现看不进去...看不太懂,今天又查了一下,然后写了写代码,通过自己写例子加上别人的解释后,从结果上观察,明白了sklearn中独热编码做了什么事。
下面举个例子解释一下:
code:
from sklearn.preprocessing import OneHotEncoder
import numpy as np train = np.array([
[0, 1, 2],
[1, 1, 0],
[2, 0, 1],
[3, 1, 1]
])
one_hot = OneHotEncoder()
one_hot.fit(train)
print(one_hot.transform([[1, 0, 1]]).toarray())
Output:
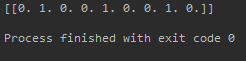
这里的output输出的是什么?怎么与例子中的矩阵关系起来?例子给的是一组4行3列的矩阵,从列来看它的特点是第1列4个数都不同,第2列只有二进制数(0,1),第3列有3个不同的数。
这样的数值矩阵对应的文本类表单可以是这样的:
| 姓名 | 性别 | 成绩 |
| 鸣人:0 | 男:1 | 32:2 |
| 佐助:1 | 男:1 | 99:0 |
| 小樱:2 | 女:0 | 87:1 |
| 佐井:3 | 男:1 | 87:1 |
于是
one_hot.transform([[1, 0, 1]]).toarray()
编码的结果这样理解:
第1列:矩阵第一列有4个不同的数,用4位表示,1出现在[0,1,2,3]中的下标为1的位置上,所以对应的独热码为:[0,1,0,0]。
第2列:矩阵第二列有2个不同的数,用2位表示,0出现在[0,1]中的下标为0的位置上,所以对应的独热码为:[1,0]。
第3列:矩阵第三列有3个不同的数,用3位表示,1出现在[0,1,2]的下标为1的位置上,所以对应的独热码为:[0,1,0]。
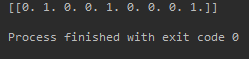
可以用例子证明上面的结论:
Input:[[1,0,2]]
Output:
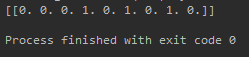
Input:[[3,1,1]
Output:
假如要进行编码的数据没有出现在对应列中将会出现错误:
Input:[[4,1,1]]
Output:

等等,还可以自行写其他例子验证一下。
现在我们就知道了独热编码做了什么了,它先统计每列中每个数据出现的次数并去除重复的,然后在没有重复数据的数据集上对不同列的数据进行相应的编码。按这样的规则编码的结果就可以只有0,1出现了。
参考资料:
1.https://blog.csdn.net/google19890102/article/details/44039761
2.https://blog.csdn.net/pipisorry/article/details/61193868
3.https://blog.csdn.net/counsellor/article/details/60145426
One-Hot Encoding(独热编码)的更多相关文章
- One-hot encoding 独热编码
http://blog.sina.com.cn/s/blog_5252f6ca0102uy47.html
- 【转】数据预处理之独热编码(One-Hot Encoding)
原文链接:http://blog.csdn.net/dulingtingzi/article/details/51374487 问题由来 在很多机器学习任务中,特征并不总是连续值,而有可能是分类值. ...
- 机器学习实战:数据预处理之独热编码(One-Hot Encoding)
问题由来 在很多机器学习任务中,特征并不总是连续值,而有可能是分类值. 例如,考虑一下的三个特征: ["male", "female"] ["from ...
- 数据预处理:独热编码(One-Hot Encoding)
python机器学习-sklearn挖掘乳腺癌细胞( 博主亲自录制) 网易云观看地址 https://study.163.com/course/introduction.htm?courseId=10 ...
- 数据预处理:独热编码(One-Hot Encoding)和 LabelEncoder标签编码
一.问题由来 在很多机器学习任务中,特征并不总是连续值,而有可能是分类值. 离散特征的编码分为两种情况: 1.离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one- ...
- 数据预处理之独热编码(One-Hot Encoding)(转载)
问题由来 在很多机器学习任务中,特征并不总是连续值,而有可能是分类值. 例如,考虑一下的三个特征: ["male", "female"] ["from ...
- 机器学习 数据预处理之独热编码(One-Hot Encoding)
问题由来 在很多机器学习任务中,特征并不总是连续值,而有可能是分类值. 例如,考虑一下的三个特征: ["male", "female"] ["from ...
- 数据预处理之独热编码(One-Hot Encoding)
问题的由来 在很多机器学习任务中,特征并不总是连续值,而有可能是分类值. 例如,考虑以下三个特征: ["male","female"] ["from ...
- 虚拟变量和独热编码的区别(Difference of Dummy Variable & One Hot Encoding)
在<定量变量和定性变量的转换(Transform of Quantitative & Qualitative Variables)>一文中,我们可以看到虚拟变量(Dummy Var ...
随机推荐
- 深入delphi编程理解之消息(一)WINDOWS原生窗口编写及消息处理过程
通过以sdk方式编制windows窗口程序,对理解windows消息驱动机制和delphi消息编程有很大的帮助. sdk编制windows窗口程序的步骤: 1.对TWndClass对象进行赋值; 2. ...
- mybatis - 执行 getById
1. getById 的执行 前面一篇 提到过, Mapper.java 创建的时候, 会通过 jdk 代理的方式来创建, 且代理处理类为: MapperProxy . 所以当执行 UserMappe ...
- spring boot 配置logback日志之jdbcTemplate打印sql语句配置
配置jdbcTemplate打印sql 用mybaties打印语句很好配置,后来用了JdbcTemplate就不知道怎么打印了,其实JdbcTemplate执行sql语句的过程会做打印sql语句的操作 ...
- java篇 之 静态
Final:不可改变 Static:静态修饰符,在编译阶段就能确定了,可以修饰成员变量,相应的称之为静态变量 是一个共享的变量(被这个类和这个类所产生的对象所共享的,他是唯一的,出生时间 为类第一次产 ...
- makefile的书写
工作中会遇到makefile的书写,有必要做一些笔记.尽管网上有”万能模板“可以使用,但我觉得还是有必要从最基础的写起. 平常在windows下开发,不知道自己用过makefile,其实大部分IDE里 ...
- jvm系列(一)之内存模型
JVM内存结构 Java内存模型是指Java虚拟机的内存模型,我们来看下Java内存模型的图片: VM内存模型主要分为三块:Java 堆内存(Heap).方法区(Non-Heap).JMV栈(JVM ...
- win server 挂载
新建服务器角色,选择[NFS服务器]. mount -o nolock \\x.x.x.x.x.x\! z:/*链接到*/
- 【Android】网络通信
https://www.bilibili.com/video/av78497129?p=4 本文为此视频笔记 1.一些标准设定 (读头部和内容) --->运行,出现权限警告: --->运行 ...
- 正则表达式regex回溯分析
正则表达式的回溯 现在我们来正式认识一下回溯.以字符串“abbc”为例,正则表达式为“ab{1,3}c”,再匹配的时候,a.b.b,匹配完成,这时候,正则表达式会继续用c和b进行比较,发现不符合,这时 ...
- MyBatis学习(五)
Spring和MyBaits整合 1.整合思路 需要spring通过单例方式管理SqlSessionFactory. spring和mybatis整合生成代理对象,使用SqlSessionFactor ...