Python可视化 | Seaborn包—kdeplot和distplot
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib
import matplotlib.pyplot as plt
from scipy.stats import skew
from scipy.stats.stats import pearsonr
%config InlineBackend.figure_format = 'retina'
%matplotlib inline
一、kdeplot(核密度估计图)
核密度估计(kernel density estimation)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一。通过核密度估计图可以比较直观的看出数据样本本身的分布特征。
x=np.random.randn(100) #随机生成100个符合正态分布的数
sns.kdeplot(x)
sns.kdeplot(x,cut=0) #cut:参数表示绘制的时候,切除带宽往数轴极限数值的多少(默认为3)
sns.kdeplot(x,cumulative=True)#cumulative :是否绘制累积分布
sns.kdeplot(x,cumulative = True,shade=True,color = 'r')
#shade:若为True,则在kde曲线下面的区域中进行阴影处理,color控制曲线及阴影的颜色

sns.kdeplot(x,cumulative = True,shade=True,color = 'r',vertical = True)#vertical:表示以X轴进行绘制还是以Y轴进行绘制

二元Kde图像
y=np.random.randn(100)
sns.kdeplot(x,y,shade=True,cbar = True)#cbar:参数若为True,则会添加一个颜色棒(颜色帮在二元kde图像中才有)

二、distplot()
displot()集合了matplotlib的hist()与核函数估计kdeplot的功能,增加了rugplot分布观测条显示与利用scipy库fit拟合参数分布的新颖用途。sns.distplot(x,color="g")

通过hist和kde参数调节是否显示直方图及核密度估计(默认hist,kde均为True)
fig,axes = plt.subplots(1,3)
sns.distplot(x,ax = axes[0]) #左图 参数ax= 把图形放在哪个框里
sns.distplot(x,hist = False ,ax = axes[1]) #中图
sns.distplot(x,kde = False, ax = axes[2]) #右图

bins:int或list,控制直方图的划分
fig,axes = plt.subplots(1,2)
sns.distplot(x,kde = False,bins = 20,ax = axes[0]) #kde=False 纵轴表示的时频数不再是频率
sns.distplot(x,kde = False,bins = [x for x in range(4)],ax = axes[1])

rug:控制是否生成观测数值的小细条
fig,axes = plt.subplots(1,2)
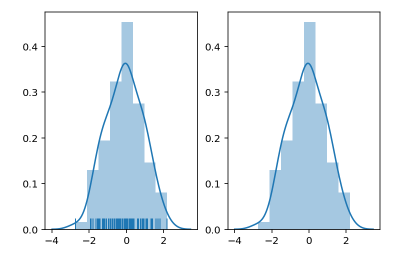
sns.distplot(x,rug=True,ax = axes[0]) #左图
sns.distplot(x,ax = axes[1]) #右图
fit:控制拟合的参数分布图形,能够直观地评估它与观察数据的对应关系(黑色线条为确定的分布)
from scipy.stats import *
sns.distplot(x,hist = False,fit =norm) #fit = norm 拟合正态分布

? hist_kws, kde_kws, rug_kws, fit_kws参数接收字典类型,可以自行定义更多高级的样式
sns.distplot(x,kde_kws={"label":"KDE"},vertical=True,color="y")

?norm_hist:若为True, 则直方图高度显示密度而非计数(含有kde图像中默认为True)
fig,axes=plt.subplots(1,2)
sns.distplot(x,norm_hist=True,kde=False,ax=axes[0]) #左图
sns.distplot(x,kde=False,ax=axes[1]) #右图

Python可视化 | Seaborn包—kdeplot和distplot的更多相关文章
- Python可视化 | Seaborn包—heatmap()
seaborn.heatmap()的参数 seaborn.heatmap(data, vmin=None, vmax=None, cmap=None, center=None, robust=Fals ...
- 二叉树的python可视化和常用操作代码
二叉树是一个重要的数据结构, 本文基于"二叉查找树"的python可视化 pybst 包, 做了一些改造, 可以支持更一般的"二叉树"可视化. 关于二叉树和二叉 ...
- Python图表数据可视化Seaborn:1. 风格| 分布数据可视化-直方图| 密度图| 散点图
conda install seaborn 是安装到jupyter那个环境的 1. 整体风格设置 对图表整体颜色.比例等进行风格设置,包括颜色色板等调用系统风格进行数据可视化 set() / se ...
- Matplotlib和Seaborn演示Python可视化
数据可视化:就是使用图形图表等方式来呈现数据,图形图表能够高效清晰地表达数据包含的信息. Seaborn是基于matplotlib,在matplotlib的基础上进行了更高级的API封装,便于用户可以 ...
- Python可视化:Seaborn库热力图使用进阶
前言 在日常工作中,经常可以见到各种各种精美的热力图,热力图的应用非常广泛,下面一起来学习下Python的Seaborn库中热力图(heatmap)如何来进行使用. 本次运行的环境为: windows ...
- Python可视化库-Matplotlib使用总结
在做完数据分析后,有时候需要将分析结果一目了然地展示出来,此时便离不开Python可视化工具,Matplotlib是Python中的一个2D绘图工具,是另外一个绘图工具seaborn的基础包 先总结下 ...
- 【转】Python 可视化神器-Plotly Express
转自:https://mp.weixin.qq.com/s/FNpNJSMK5Vs8pwi0PbbBzw 说明:图片无法直接复制,请查看原文 导读:Plotly Express 是一个新的高级 Pyt ...
- Python可视化库
转自小小蒲公英原文用Python可视化库 现如今大数据已人尽皆知,但在这个信息大爆炸的时代里,空有海量数据是无实际使用价值,更不要说帮助管理者进行业务决策.那么数据有什么价值呢?用什么样的手段才能把数 ...
- python可视化基础
常用的python可视化工具包是matplotlib,seaborn是在matplotlib基础上做的进一步封装.入坑python可视化,对有些人来说如同望山跑死马,心气上早输了一节.其实学习一门新知 ...
随机推荐
- 【代码审计】VAuditDemo 前台搜索注入
在search.php中 $_GET['search']未经过任何过滤传入到$query的执行语句中
- Hibernate学习(二)
持久化对象的声明周期 1.Hibernate管理的持久化对象(PO persistence object )的生命周期有四种状态,分别是transient.persistent.detached和re ...
- 吴裕雄 python 神经网络——TensorFlow训练神经网络:全模型
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data INPUT_NODE = 784 ...
- 2016-2017学年第三次测试赛 习题H MCC的考验
问题 H: MCC的考验 时间限制: 1 Sec 内存限制: 128 MB 题目描述 MCC男神听说新一期的选拔赛要开始了,给各位小伙伴们带来了一道送分题,如果你做不出来,MCC会很伤心的. 给定一 ...
- Laravel 6.X 数据库迁移 创建表 与 修改表
数据库迁移创建表 本篇文章中使用的是mysql数据库,其他数据库需要修改env文件和app配置,请其他地方搜索一下就会找到. 创建示例 1.创建users表: 命令行键入 php artisan ma ...
- 洛谷 T2691 桶哥的问题——送桶
嗯... 题目链接:https://www.luogu.org/problem/T2691 这道题有一点贪心的思想吧...并且思路与题目是倒着来的(貌似这种思路已经很常见的... 先举个栗子: 引出思 ...
- Java笔记---成员初始化
成员初始化 成员初始化 Java尽力保证所有变量可以在使用前可以初始化. void f(){ int i; System.out.println(i); //! i++; //开幕雷击:这里就报错了, ...
- xshell编码设置-----支持中文
1. 点击 设置 图标 2. 选择 UTF-8 3. 重启xshell即可
- 一起探讨Go 语言为什么能成功?
导读 两位创造者Rob Pike和Robert Griesemer一起探讨了Go成功的原因. 常言道,历史不会重演,但总会惊人的相似. 如果您想创建一种编程语言,多向那些有经验的人士学习,他们有很多可 ...
- LSTM算法公式
参考:<基于强化学习的开放领域聊天机器人对话生成算法>