centos搭建单节点hadoop
由于本地机器资源有限,搭建单节点hadoop供开发、测试。
1、安装java
mkdir /usr/local/java
cd /usr/local/java
tar zxvf jdk-8u181-linux-x64.tar.gz
rm -f jdk-8u181-linux-x64.tar.gz
---设置jdk环境变量
vi /etc/profile
JAVA_HOME=/usr/local/java/jdk1.8.0_181
JRE_HOME=/usr/local/java/jdk1.8.0_181/jre
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$JAVA_HOME/bin:$PATH
export PATH JAVA_HOME CLASSPATH
source /etc/profile
java -version
2、增加用户
useradd hadoop
配置免密登陆(需开启ssh服务)
yum install -y openssh-server
yum install -y openssh-clients
systemctl start sshd.service
su - hadoop
ssh-keygen -t rsa -P ''
cat id_rsa.pub > ~/.ssh/authorized_keys
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
3、创建目录和解压缩
mkdir -p /opt/hadoop
上传hadoop-2.8.5.tar.gz 至/opt/hadoop
chown -R hadoop:hadoop /opt/hadoop
mkdir -p /u01/hadoop
mkdir /u01/hadoop/tmp
mkdir /u01/hadoop/var
mkdir /u01/hadoop/dfs
mkdir /u01/hadoop/dfs/name
mkdir /u01/hadoop/dfs/data
chown -R hadoop.hadoop /u01/hadoop
su - hadoop
cd /opt/hadoop
tar -xzvf hadoop-2.8.5.tar.gz
rm -f hadoop-2.8.5.tar.gz
4、配置环境变量
vi ~/.bashrc
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.5
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
source ~/.bashrc
5、修改配置文件
路径:/opt/hadoop/hadoop-2.8.5/etc/hadoop
- hadoop-env.sh
JAVA_HOME=/usr/local/java/jdk1.8.0_181
- core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/u01/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
- hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/u01/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/u01/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.permissions</name>
<value>true</value>
<description>need not permissions</description>
</property>
</configuration>
- mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop01:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/u01/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- yarn-site.xml
- slaves
hadoop01
6、启动服务
---初始化HDFS文件系统
hdfs namenode -format
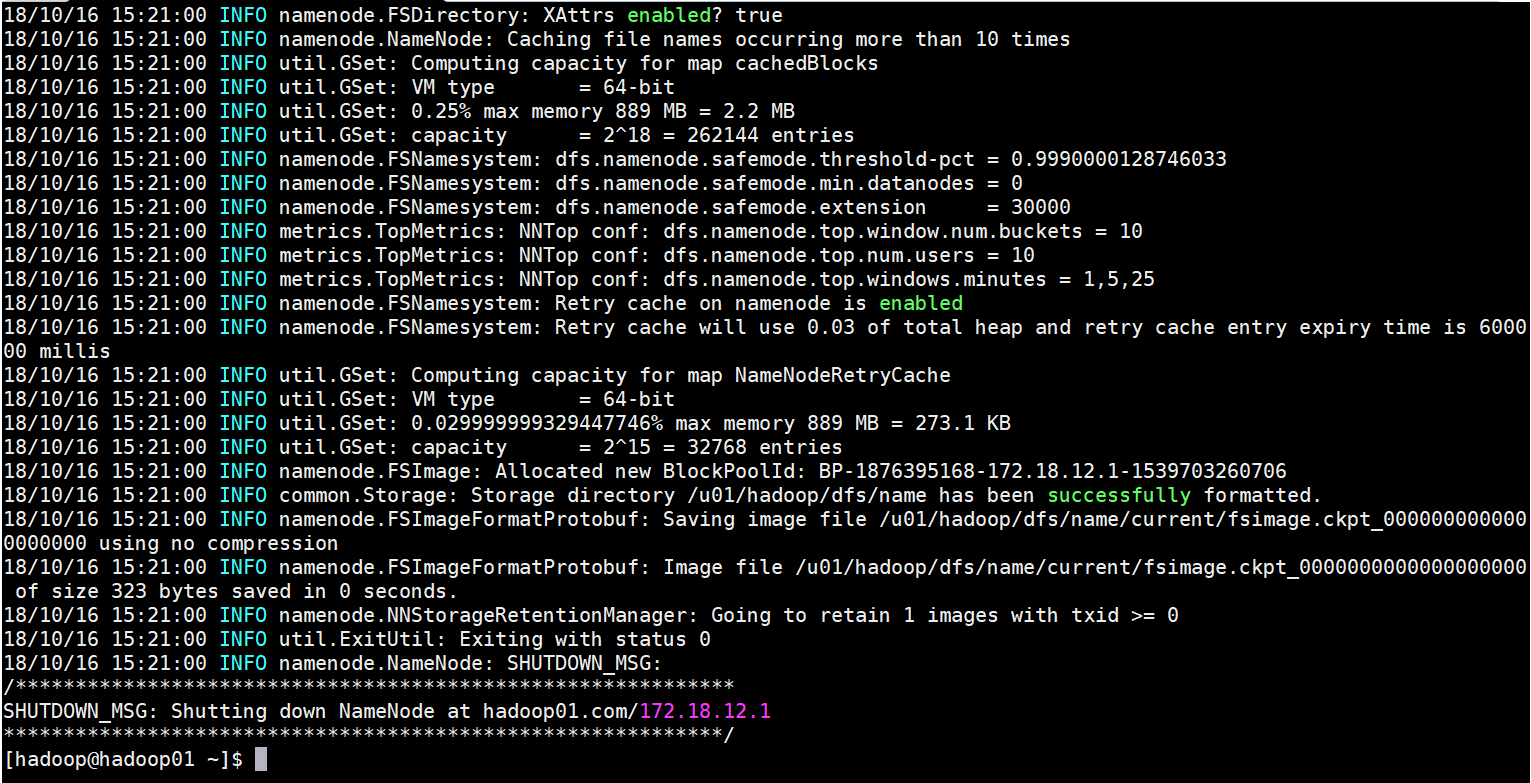
---启动Hadoop服务
start-dfs.sh #启动Hadoop
start-yarn.sh #启动yarn
jps #查看服务状态
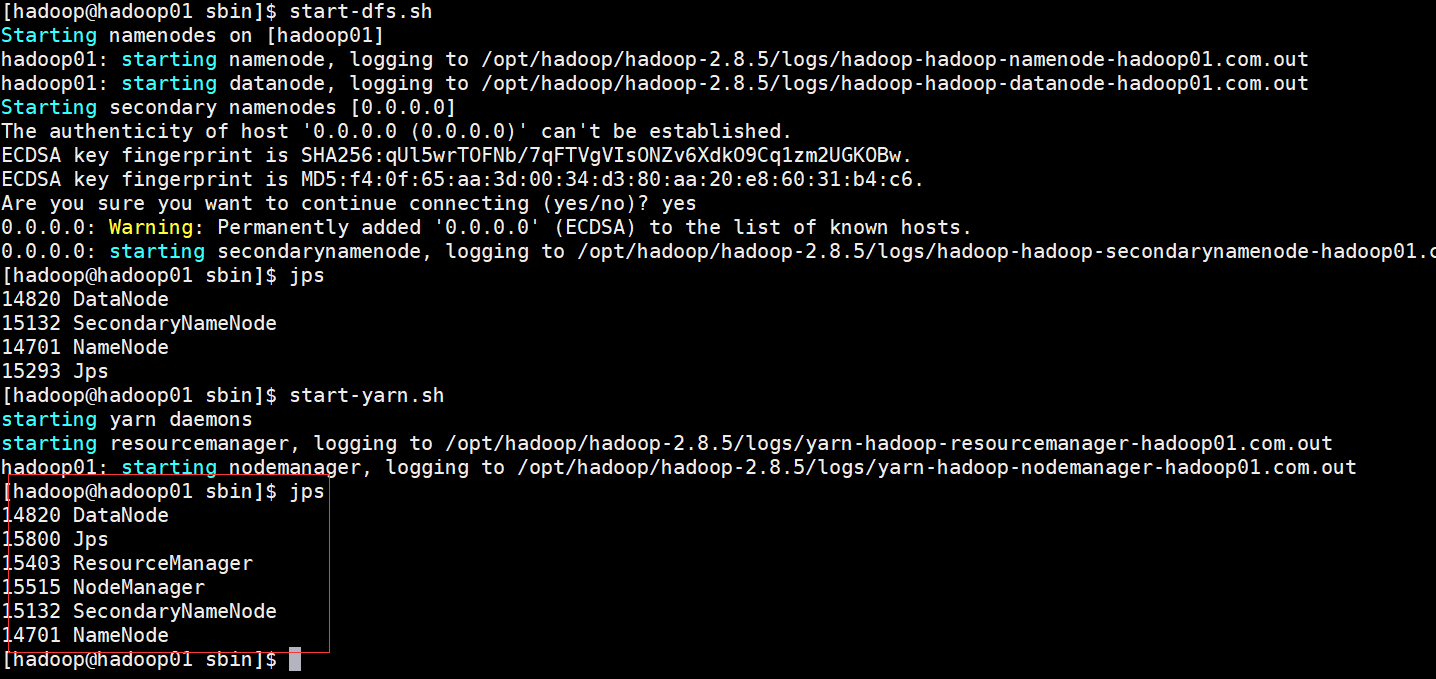
如图有5个服务起来
如果启动报错可以通过以下单独启动
hadoop-daemon.sh start namenode
hadoop-daemon.sh start datanode
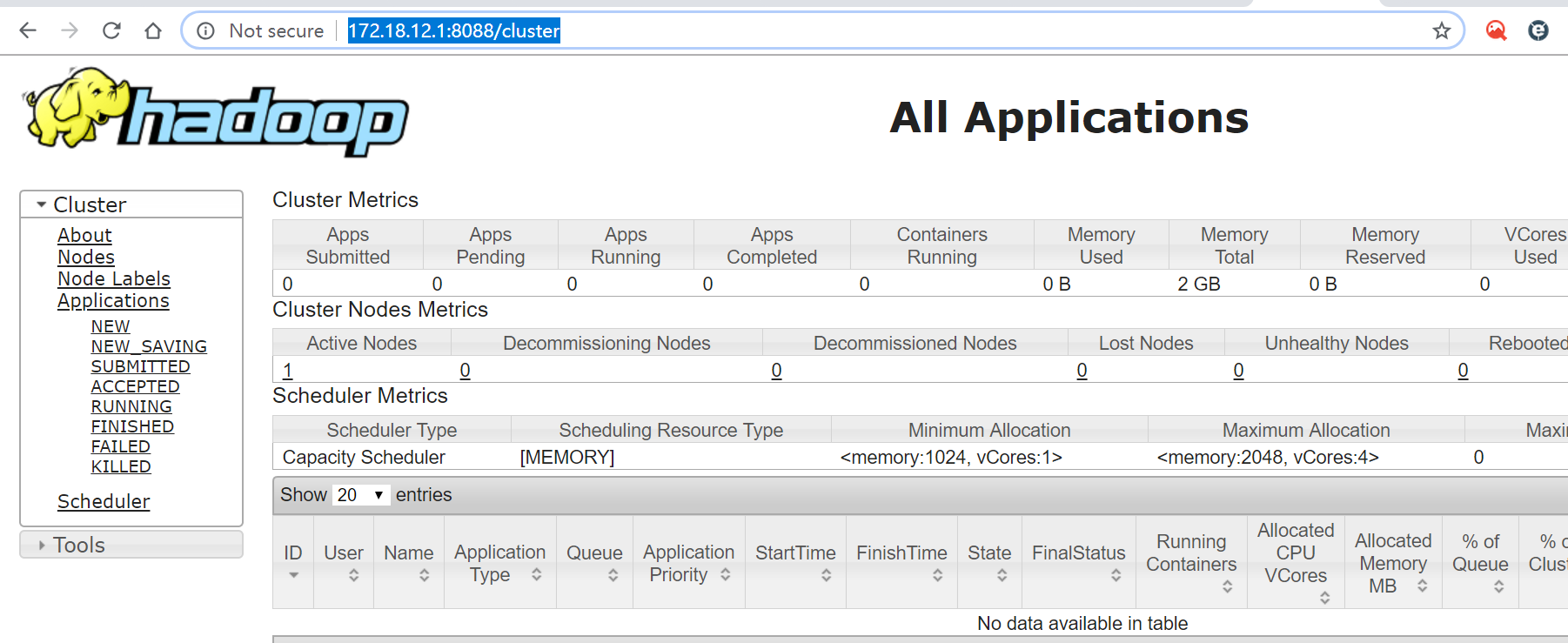
登录验证:
http://172.18.12.1:8088/cluster
尝试创建文件
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/hadoop
hdfs dfs -put start-dfs.sh /user/hadoop
centos搭建单节点hadoop的更多相关文章
- 搭建单节点Hadoop应用环境
虚拟机: VirtualBox 5 Server操作系统: Ubuntu Server 14.04.3 LTS 如果对虚拟机空间和性能不做考虑, 且不习惯用Linux命令, 你也可以使用Ubuntu ...
- 基于Docker快速搭建多节点Hadoop集群--已验证
Docker最核心的特性之一,就是能够将任何应用包括Hadoop打包到Docker镜像中.这篇教程介绍了利用Docker在单机上快速搭建多节点 Hadoop集群的详细步骤.作者在发现目前的Hadoop ...
- hadoop集群搭建——单节点(伪分布式)
1. 准备工作: 前提:需要电脑安装VM,且VM上安装一个Linux系统 注意:本人是在学习完尚学堂视频后,结合自己的理解,在这里做的总结.学习的视频是:大数据. 为了区分是在哪一台机器做的操作,eg ...
- Zookeeper在Centos7上搭建单节点应用
(默认机器上已经安装并配置好了jdk) 1.下载zookeeper并解压 $ tar -zxvf zookeeper-3.4.6.tar.gz 2.将解压后的文件夹移动到 /usr/local/ 目录 ...
- dcoker 搭建单节点redis
1.安装docker 1.检查内核版本,必须是3.10及以上 [root@localhost ~]# uname -r 2.安装docker [root@localhost ~]# yum insta ...
- 吴裕雄--天生自然HADOOP操作实验学习笔记:单节点伪分布式安装
实验目的 了解java的安装配置 学习配置对自己节点的免密码登陆 了解hdfs的配置和相关命令 了解yarn的配置 实验原理 1.Hadoop安装 Hadoop的安装对一个初学者来说是一个很头疼的事情 ...
- kafka系列一:单节点伪分布式集群搭建
Kafka集群搭建分为单节点的伪分布式集群和多节点的分布式集群两种,首先来看一下单节点伪分布式集群安装.单节点伪分布式集群是指集群由一台ZooKeeper服务器和一台Kafka broker服务器组成 ...
- ASP.NET Core on K8S学习初探(1)K8S单节点环境搭建
当近期的一个App上线后,发现目前的docker实例(应用服务BFF+中台服务+工具服务)已经很多了,而我司目前没有专业的运维人员,发现运维的成本逐渐开始上来,所以容器编排也就需要提上议程.因此我决定 ...
- Hadoop的单节点集群详细启动步骤
见,如下博客 hadoop-2.2.0.tar.gz的伪分布集群环境搭建(单节点) 很简单,不多赘述.
随机推荐
- Myeclipse下PHP开发环境搭建及运行
外接CSDN链接 http://blog.csdn.net/yuxiangaaaaa/article/details/54948426 这是php初始设置,后面进行重新设置
- Jmeter_请求原件之参数化txt
把数据存放在TXT上进行参数化,然后运行 用于注册,登录等不同的用例 1.登录接口地址: http://test.lemonban.com/futureloan/mvc/api/member/logi ...
- SpringBoot启动使用elasticsearch启动异常:Received message from unsupported version:[2.0.0] minimal compatible
SpringBoot启动使用elasticsearch启动异常:Received message from unsupported version:[2.0.0] minimal compatible ...
- ssh paramiko && subprocess
subprocess: #!/usr/bin/python3 import paramiko import os import sys import subprocess curPath = os.p ...
- 「JSOI2014」歌剧表演
「JSOI2014」歌剧表演 传送门 没想到吧我半夜切的 这道题应该算是 \(\text{JSOI2014}\) 里面比较简单的吧... 考虑用集合关系来表示分辨关系,具体地说就是我们把所有演员分成若 ...
- 「JSOI2010」找零钱的洁癖
「JSOI2010」找零钱的洁癖 传送门 个人感觉很鬼的一道题... 首先我们观察到不同的数最多 \(50\) 个,于是考虑爆搜. 但是这样显然不太对啊,状态数太多了. 然后便出现了玄学操作: \(\ ...
- 设计模式课程 设计模式精讲 3-8 迪米法特原则讲解及Coding
1 课程讲解 1.1 定义 1.2 特质 1.3 重点 2 代码演练 2.1 反例 2.2 正例 1 课程讲解 1.1 定义 定义:一个对象应该对其他对象保持最少的了解.又叫最少知道原则. 1.2 特 ...
- pycharm中Terminal中运行用例
1.设置终端路径 2.单个用例文件运行 3.多个用例文件,例如加载用例的文件运行 1.可能会出现如下错误(参考:https://blog.csdn.net/qq_36829091/article/d ...
- Servlet 学习(四)
HTTP 响应的构成1.HTTP 响应行: 协议.状态.描述 HTTP 1.1 中定义的状态代码 100-199 是信息性代码,标示客户应该采取的其它动作 200-299 表示请求成功 300-399 ...
- Gof 设计模式
设计模式的用途(参考) 设计模式代表了最佳实践,通常被有经验的面向对象的软件开发人员采用.设计模式是软件开发人员在软件开发过程中面临一般问题的解决方案.这些解决方案是众多软件开发人员在相当长的时间的实 ...