Mapreduce实例——WordCount
实验步骤
- 切换目录到/apps/hadoop/sbin下,启动hadoop。
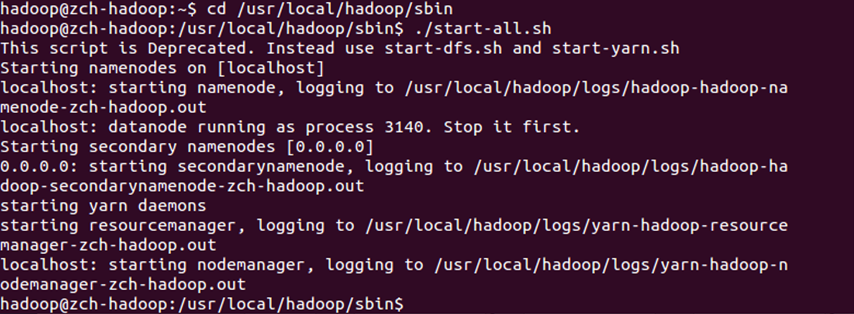
cd /apps/hadoop/sbin
./start-all.sh
2.在linux上,创建一个目录/data/mapreduce1。

mkdir -p /data/mapreduce1
3.切换到/data/mapreduce1目录下,自行建立文本文件buyer_favorite1。
依然在/data/mapreduce1目录下,使用wget命令,从
网络下载hadoop2lib.tar.gz,下载项目用到的依赖包。
将hadoop2lib.tar.gz解压到当前目录下。
tar -xzvf hadoop2lib.tar.gz
4.将linux本地/data/mapreduce1/buyer_favorite1,上传到HDFS上的/mymapreduce1/in目录下。若HDFS目录不存在,需提前创建。
- hadoop fs -mkdir -p /mymapreduce1/in
- hadoop fs -put /data/mapreduce1/buyer_favorite1 /mymapreduce1/in
5.打开Eclipse,新建Java Project项目。并将项目名设置为mapreduce1。
6.在项目名mapreduce1下,新建package包。并将包命名为mapreduce 。
7.在创建的包mapreduce下,新建类。并将类命名为WordCount。
8.添加项目所需依赖的jar包,右键单击项目名,新建一个目录hadoop2lib,用于存放项目所需的jar包。
9.添加代码
10.打开终端或使用hadoop eclipse插件,查看hdfs上,程序输出的实验结果。


hadoop fs -ls /mymapreduce1/out
hadoop fs -cat /mymapreduce1/out/part-r-00000
Mapreduce实例——WordCount的更多相关文章
- 实验6:Mapreduce实例——WordCount
实验目的1.准确理解Mapreduce的设计原理2.熟练掌握WordCount程序代码编写3.学会自己编写WordCount程序进行词频统计实验原理MapReduce采用的是“分而治之”的 ...
- 大型数据库技术实验六 实验6:Mapreduce实例——WordCount
现有某电商网站用户对商品的收藏数据,记录了用户收藏的商品id以及收藏日期,名为buyer_favorite1. buyer_favorite1包含:买家id,商品id,收藏日期这三个字段,数据以“\t ...
- MapReduce实例2(自定义compare、partition)& shuffle机制
MapReduce实例2(自定义compare.partition)& shuffle机制 实例:统计流量 有一份流量数据,结构是:时间戳.手机号.....上行流量.下行流量,需求是统计每个用 ...
- MapReduce实例&YARN框架
MapReduce实例&YARN框架 一个wordcount程序 统计一个相当大的数据文件中,每个单词出现的个数. 一.分析map和reduce的工作 map: 切分单词 遍历单词数据输出 r ...
- 利用python操作mrjob实例---wordcount
网上利用java实现mr操作实例相对较多,现将python实现mr操作实例---Wordcount分享如下: 在操作前,需要作如下准备: 1.确保linux系统里安装有python3.5,pyt ...
- Java编程MapReduce实现WordCount
Java编程MapReduce实现WordCount 1.编写Mapper package net.toocruel.yarn.mapreduce.wordcount; import org.apac ...
- eclipse运行mapreduce的wordcount
1,eclipse安装hadoop插件 插件下载地址:链接: https://pan.baidu.com/s/1U4_6kLFNiKeLsGfO7ahXew 提取码: as9e 下载hadoop-ec ...
- Mapreduce 测试自带实例 wordcount
2.7.3版本的hadoop: jar程序所在目录:$HADOOP_HOME/shar/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar 1.本 ...
- Hadoop实战2:MapReduce编程-WordCount实例-streaming-python环境
这是搭建hadoop环境后的第一个MapReduce程序: 基于hadoop streaming的python的脚本: 1 map.py文件,把文本的内容划分成单词: #!/usr/bin/pytho ...
随机推荐
- Fedora26下Mysql改密码Unknown column 'password' in 'field list'
本意向修改一个用户的密码,网上搜到的命令为如下 1 mysql> update user set password=password(“新密码”) where user=”用户名”; 执行后报错 ...
- WebRTC之Android客户端
一.WebRTC的Android客户端搭建 1.libjingle_peerconnection_so.so 2.libjingle_peerconnection.jar 3.客户端源码一份(可以在g ...
- Thread的join方法
一个线程在执行的过程中,可能调用另一个线程,前者可以称为调用线程,后者成为被调用线程. Thread.Join方法的使用场景:调用线程挂起,等待被调用线程执行完毕后,继续执行. 如下案列: 当NewT ...
- Win10中小娜无法搜索本地应用
解决方案 1.win+X - Windows PowerShell(管理员) 2. 输入Get-AppXPackage -Name Microsoft.Windows.Cortana | Fo ...
- ubuntu13.10安装tomcat
步骤: ubuntu :13.10(32bit) -->i586 jdk 1.7 安装JDK 步骤: 1.官网下载如下图: 2.点击java SE7,下载jdk1.7 3.点击接受,并下载对应的 ...
- 关于Action模型驱动无法获取属性的问题
这两天在练习ssh小项目发现action层怎都无法获取Ajax传过来的json: 1.检查表单name和action定义属性名是否一致 2.get/Set方法 3.表单和属性名的命名问题,驼峰法
- C++ 类型、类型转换
C++ 数据类型 基本内置类型 字面值常量和字面值类型 类类型 隐式的类类型转换 聚合类 字面值常量类 constexpr 构造函数 类的静态成员 使用编程语言进行编程时,需要用到各种变量来存储各种信 ...
- C# Stream篇(三) -- TextWriter 和 StreamWriter---转载
C# Stream篇(三) -- TextWriter 和 StreamWriter TextWriter 和 StreamWriter 目录: 为何介绍TextWriter? TextWriter的 ...
- 关联容器:unordered_map详细介绍
版权声明:博主辛辛苦苦码的字哦~转载注明一下啦~ https://blog.csdn.net/hk2291976/article/details/51037095 介绍 1 特性 2 Hashtabl ...
- Spark教程——(8)本地执行spark-sql程序
在程序中设定Spark SQL的运行模式: //.setMaster("local")设置本地运行模式 val conf = new SparkConf().setAppName( ...