hive元数据库理解
在hive2.1.1 里面一共有59张表
表1 VERSION
select * from VERSION limit ;
version表存hive的版本信息,该表中数据只有一条,如果存在多条,会造成hive启动不起来。
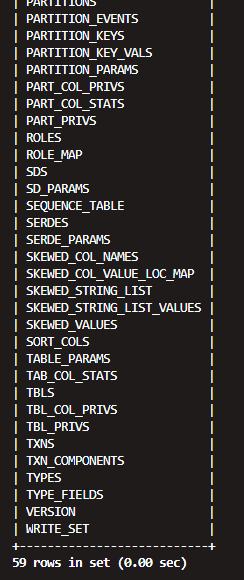
表2 DBS
select * from DBS;
DB_ID:数据库ID,DESC:数据库描述,DB_LOCATION_URI:数据HDFS路径,NAME:数据库名,OWNER_NAME:数据库所有者用户名,OWNER_TYPE:所有者角色。
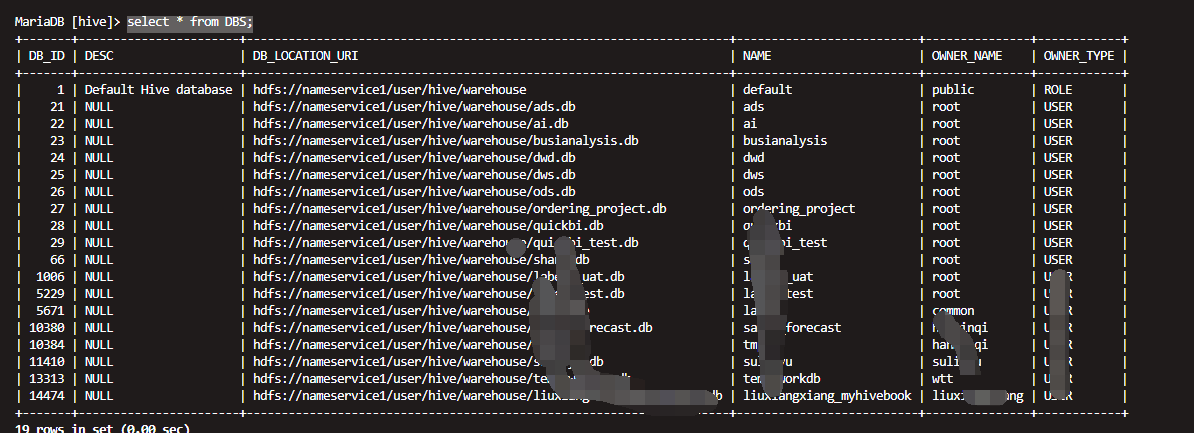
表3 DATABASE_PARAMS
select * from DATABASE_PARAMS
该表存储数据库的相关参数,在CREATE DATABASE时候用 WITH DBPROPERTIES (property_name=property_value, …)指定的参数。
表4 TBLS
select * from TBLS limit ;
bls表显示表的详细信息,tbl_id为主键,唯一表示该表,里面存放表的创建时间create_time,表所属的库id(DB_ID),表的拥有着(OWNER),SD_ID ,表的名称TBL_NAME,表的类型(TBL_TYPE)表示内部表还是外部表.

表5
select * from table_params

如表的最后一次ddl时间,表的注释,如果是非分区表还有该表对应着HDFS文件个数,大小.(通过TBL_ID 来关联表)
表6 TBL_PRIVS
select * from TBL_PRIVS
如表的最后一次ddl时间,表的注释,如果是非分区表还有该表对应着HDFS文件个数,大小

Hive文件存储信息相关的元数据表
SDS:
该表对应的文件存储的基本信息,如INPUT_FORMAT、OUTPUT_FORMAT、是否压缩等。TBLS表中的SD_ID与该表关联,可以获取Hive表的存储信息
SDS、SD_PARAMS、SERDES、SERDE_PARAMS,由于HDFS支持的文件格式很多,而建Hive表时候也可以指定各种文件格式,Hive在将HQL解析成MapReduce时候,需要知道去哪里,使用哪种格式去读写HDFS文件,而这些信息就保存在这几张表中.
hive元数据库理解的更多相关文章
- hive元数据库表分析及操作
在安装Hive时,需要在hive-site.xml文件中配置元数据相关信息.与传统关系型数据库不同的是,hive表中的数据都是保存的HDFS上,也就是说hive中的数据库.表.分区等都可以在HDFS找 ...
- hive 元数据库表描述
元数据库表描述 这一节描述hive元数据库中比较重要的一些表的作用,随着后续对hive的使用逐渐补充更多的内容. mysql元数据库hive中的表: 表名 作用 BUCKETING_COLS 存储bu ...
- hive 的理解
什么是Hive 转自: https://blog.csdn.net/qingqing7/article/details/79102691 1.Hive简介 Hive 是建立在 Hadoop 上的数据仓 ...
- Hive 元数据库表信息
Hive 的元数据信息通常存储在关系型数据库中,常用MySQL数据库作为元数据库管理. 1. 版本表 i) VERSION -- 查询版本信息 2. 数据库.文件存储相关 i) DBS -- 存储 ...
- 配置hive元数据库mysql时候出现 Unable to find the JDBC database jar on host : master
解决办法: cd /usr/share/java/,(没有java文件夹,自行创建)rz mysql-connector-java-***.jar,mv mysql-connector-java-* ...
- 【原创】大数据基础之Hive(4)hive元数据库核心表结构
1 dbs +-------+-----------------------+----------------------------------------------+------------+- ...
- hive 未初始化元数据库报错
启动hive-metastore和hive-server2 用beeline连接hive报错 [root@node04 hive]# beeline Beeline version 0.13.1-cd ...
- hive的简单理解--笔记
Hive的理解 数据仓库的工具 Hive仅仅是在hadoop上面包装了SQL: Hive的数据存储在hadoop上 Hive的计算由MR进行 Hive批量处理数据 Hive的特点 1 可扩展性(h ...
- Hive体系结构介绍
http://www.aboutyun.com/thread-6217-1-1.html 1.Hive架构与基本组成 下面是Hive的架构图. 图1.1 Hive体系结构 Hive ...
随机推荐
- SQL编写自定义函数
-- 通过一个子级ID 返回一级分类名称alter function calcclass(@dclassid as int)returns varchar(50)asbegin-- 通过一个子级ID ...
- leetcode 207课程表
class Solution { public: bool canFinish(int numCourses, vector<vector<int>>& prerequ ...
- LC 413. Arithmetic Slices
A sequence of number is called arithmetic if it consists of at least three elements and if the diffe ...
- 《Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization》课堂笔记
Lesson 2 Improving Deep Neural Networks:Hyperparameter tuning, Regularization and Optimization 这篇文章其 ...
- SqlServer数据库查看被锁表以及解锁Kill杀死进程
步骤1.查看锁表进程 2.杀死进程 --1.查询锁表进程 spid.和被锁表名称 tableName select request_session_id spid,OBJECT_NAME ...
- [转载]Jupyter Notebook 的快捷键
原文:http://blog.csdn.net/lawme/article/details/51034543 Jupyter Notebook 的快捷键 Jupyter Notebook 有两种键盘输 ...
- Django学习笔记(一)Django基础
新建项目 django-admin startproject my_site #会在当前目录新建my_site目录,可自行修改目录名 django-admin startproject my_site ...
- 安装VMWare tools 及安装后/mnt中有hgfs但没共享文件的解决办法
一.首先是安装VMWare tools打开虚拟机软件,在菜单栏‘虚拟机’子菜单下‘安装VMware Tools' 1.以root身份进入Linux 2.此时把linux的/dev/cdrom设备挂载到 ...
- php 二维数据排序 排行榜
php 二维数据排序 排行榜 $rateCount = array(); foreach($groupUsers as $user){ $rateCount[] = $user['rate']; } ...
- 【3.2】【mysql基本实验】mysql GTID复制(基于空数据的配置)
概述:本质上和传统异步复制没什么区别,就是加了GTID参数. 且可以用传统的方式来配置主从,也可以用GTID的方式来自动配置主从. 这里使用GTID的方式来自动适配主从. 需要mysql5.6.5以上 ...