ROC与AUC的定义与使用详解
分类模型评估:
| 指标 | 描述 | Scikit-learn函数 |
|---|---|---|
| Precision | 精准度 | from sklearn.metrics import precision_score |
| Recall | 召回率 | from sklearn.metrics import recall_score |
| F1 | F1值 | from sklearn.metrics import f1_score |
| Confusion Matrix | 混淆矩阵 | from sklearn.metrics import confusion_matrix |
| ROC | ROC曲线 | from sklearn.metrics import roc |
| AUC | ROC曲线下的面积 | from sklearn.metrics import auc |
回归模型评估:
| 指标 | 描述 | Scikit-learn函数 |
|---|---|---|
| Mean Square Error (MSE, RMSE) | 平均方差 | from sklearn.metrics import mean_squared_error |
| Absolute Error (MAE, RAE) | 绝对误差 | from sklearn.metrics import mean_absolute_error, median_absolute_error |
| R-Squared | R平方值 | from sklearn.metrics import r2_score |
ROC和AUC定义
ROC全称是“受试者工作特征”(Receiver Operating Characteristic)。ROC曲线的面积就是AUC(Area Under the Curve)。AUC用于衡量“二分类问题”机器学习算法性能(泛化能力)。
计算ROC需要知道的关键概念
首先,解释几个二分类问题中常用的概念:True Positive, False Positive, True Negative, False Negative。它们是根据真实类别与预测类别的组合来区分的。
假设有一批test样本,这些样本只有两种类别:正例和反例。机器学习算法预测类别如下图(左半部分预测类别为正例,右半部分预测类别为反例),而样本中真实的正例类别在上半部分,下半部分为真实的反例。
- 预测值为正例,记为P(Positive)
- 预测值为反例,记为N(Negative)
- 预测值与真实值相同,记为T(True)
- 预测值与真实值相反,记为F(False)
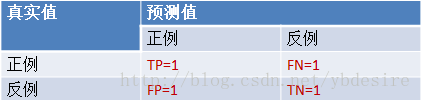
TP:预测类别是P(正例),真实类别也是PFP:预测类别是P,真实类别是N(反例)TN:预测类别是N,真实类别也是NFN:预测类别是N,真实类别是P

样本中的真实正例类别总数即TP+FN。TPR即True Positive Rate,TPR = TP/(TP+FN)。
同理,样本中的真实反例类别总数为FP+TN。FPR即False Positive Rate,FPR=FP/(TN+FP)。
还有一个概念叫”截断点”。机器学习算法对test样本进行预测后,可以输出各test样本对某个类别的相似度概率。比如t1是P类别的概率为0.3,一般我们认为概率低于0.5,t1就属于类别N。这里的0.5,就是”截断点”。
总结一下,对于计算ROC,最重要的三个概念就是TPR, FPR, 截断点。
截断点取不同的值,TPR和FPR的计算结果也不同。将截断点不同取值下对应的TPR和FPR结果画于二维坐标系中得到的曲线,就是ROC曲线。横轴用FPR表示。
sklearn计算ROC
sklearn给出了一个计算ROC的例子[1]。
- y = np.array([1, 1, 2, 2])
- scores = np.array([0.1, 0.4, 0.35, 0.8])
- fpr, tpr, thresholds = metrics.roc_curve(y, scores, pos_label=2)
- 1
- 2
- 3
- 1
- 2
- 3
通过计算,得到的结果(TPR, FPR, 截断点)为
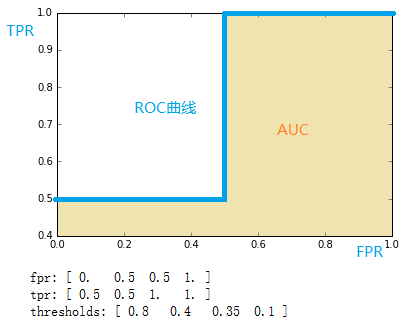
- fpr = array([ 0. , 0.5, 0.5, 1. ])
- tpr = array([ 0.5, 0.5, 1. , 1. ])
- thresholds = array([ 0.8 , 0.4 , 0.35, 0.1 ])#截断点
- 1
- 2
- 3
- 1
- 2
- 3
将结果中的FPR与TPR画到二维坐标中,得到的ROC曲线如下(蓝色线条表示),ROC曲线的面积用AUC表示(淡黄色阴影部分)。
详细计算过程
上例给出的数据如下
- y = np.array([1, 1, 2, 2])
- scores = np.array([0.1, 0.4, 0.35, 0.8])
- 1
- 2
- 1
- 2
用这个数据,计算TPR,FPR的过程是怎么样的呢?
1. 分析数据
y是一个一维数组(样本的真实分类)。数组值表示类别(一共有两类,1和2)。我们假设y中的1表示反例,2表示正例。即将y重写为:
y_true = [0, 0, 1, 1]- 1
- 1
score即各个样本属于正例的概率。
2. 针对score,将数据排序
| 样本 | 预测属于P的概率(score) | 真实类别 |
|---|---|---|
| y[0] | 0.1 | N |
| y[2] | 0.35 | P |
| y[1] | 0.4 | N |
| y[3] | 0.8 | P |
3. 将截断点依次取为score值
将截断点依次取值为0.1,0.35,0.4,0.8时,计算TPR和FPR的结果。
3.1 截断点为0.1
说明只要score>=0.1,它的预测类别就是正例。
此时,因为4个样本的score都大于等于0.1,所以,所有样本的预测类别都为P。
- scores = [0.1, 0.4, 0.35, 0.8]
- y_true = [0, 0, 1, 1]
- y_pred = [1, 1, 1, 1]
- 1
- 2
- 3
- 1
- 2
- 3

TPR = TP/(TP+FN) = 1
FPR = FP/(TN+FP) = 1
3.2 截断点为0.35
说明只要score>=0.35,它的预测类别就是P。
此时,因为4个样本的score有3个大于等于0.35。所以,所有样本的预测类有3个为P(2个预测正确,1一个预测错误);1个样本被预测为N(预测正确)。
- scores = [0.1, 0.4, 0.35, 0.8]
- y_true = [0, 0, 1, 1]
- y_pred = [0, 1, 1, 1]
- 1
- 2
- 3
- 1
- 2
- 3

TPR = TP/(TP+FN) = 1
FPR = FP/(TN+FP) = 0.5
3.3 截断点为0.4
说明只要score>=0.4,它的预测类别就是P。
此时,因为4个样本的score有2个大于等于0.4。所以,所有样本的预测类有2个为P(1个预测正确,1一个预测错误);2个样本被预测为N(1个预测正确,1一个预测错误)。
- scores = [0.1, 0.4, 0.35, 0.8]
- y_true = [0, 0, 1, 1]
- y_pred = [0, 1, 0, 1]
- 1
- 2
- 3
- 1
- 2
- 3
TPR = TP/(TP+FN) = 0.5
FPR = FP/(TN+FP) = 0.5
3.4 截断点为0.8
说明只要score>=0.8,它的预测类别就是P。所以,所有样本的预测类有1个为P(1个预测正确);3个样本被预测为N(2个预测正确,1一个预测错误)。
- scores = [0.1, 0.4, 0.35, 0.8]
- y_true = [0, 0, 1, 1]
- y_pred = [0, 0, 0, 1]
- 1
- 2
- 3
- 1
- 2
- 3

TPR = TP/(TP+FN) = 0.5
FPR = FP/(TN+FP) = 0
心得
用下面描述表示TPR和FPR的计算过程,更容易记住
- TPR:真实的正例中,被预测正确的比例
- FPR:真实的反例中,被预测正确的比例
最理想的分类器,就是对样本分类完全正确,即FP=0,FN=0。所以理想分类器TPR=1,FPR=0。
参考:
ROC与AUC的定义与使用详解的更多相关文章
- Java基础-变量的定义以及作用域详解
Java基础-变量的定义以及作用域详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.字面量 常量(字面量)表示不能改变的数值(程序中直接出现的值).字面量有时也称为直接量,包 ...
- 第7.15节 Python中classmethod定义的类方法详解
第7.15节 Python中classmethod定义的类方法详解 类中的方法,除了实例方法外,还有两种方法,分别是类方法和静态方法.本节介绍类方法的定义和使用. 一. 类方法的定义 在类中定 ...
- Spring MVC 学习总结(二)——控制器定义与@RequestMapping详解
一.控制器定义 控制器提供访问应用程序的行为,通常通过服务接口定义或注解定义两种方法实现. 控制器解析用户的请求并将其转换为一个模型.在Spring MVC中一个控制器可以包含多个Action(动作. ...
- C/C++ 定义与声明详解(转)
转自:http://blog.csdn.net/xiaoyusmile/article/details/5420252 1. 变量的定义.声明 变量的声明有两种情况: 一种是需要建立存储空间的.例如: ...
- 【转】单片机中volatile定义的作用详解
传送门:http://www.eeworld.com.cn/mcu/2011/0411/article_3928.html 一个定义为volatile的变量是说这变量可能会被意想不到地改变,这样,编译 ...
- C#结构体指针的定义及使用详解(intptr的用法)
在解析C#结构体指针前,必须知道C#结构体是如何定义的.在c#中同样定义该结构体. C#结构体指针之C#结构体的定义: [StructLayout(LayoutKind.Sequential)] pu ...
- 【iOS atomic、nonatomic、assign、copy、retain、weak、strong】的定义和区别详解
一.atomic与nonatomic 1.相同点 都是为对象添加get和set方法 2.不同点 atomic为get方法加了一把安全锁(及原子锁),使得方法get线程安全,执行效率慢 nonatomi ...
- Spring MVC 学习)——控制器与@RequestMapping详解
Spring MVC 学习总结(二)——控制器定义与@RequestMapping详解 一.控制器定义 控制器提供访问应用程序的行为,通常通过服务接口定义或注解定义两种方法实现. 控制器解析用户的请求 ...
- OSPF详解
OSPF 详解 (1) [此博文包含图片] (2013-02-04 18:02:33) 转载 ▼ 标签: 端的 第二 以太 第一个 正在 目录 序言 初学乍练 循序渐进学习OSPF 朱皓 入门之前 了 ...
随机推荐
- vue简单todolist
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- spark 机器学习 ALS原理(一)
1.线性回归模型线性回归是统计学中最常用的算法,当你想表示两个变量间的数学关系时,就可以用线性回归.当你使用它时,你首先假设输出变量(相应变量.因变量.标签)和预测变量(自变量.解释变量.特征)之间存 ...
- java递归、js递归,无限极分类菜单表
java-json import com.alibaba.fastjson.JSONObject; import java.util.ArrayList; import java.util.List; ...
- git命令——git rm、git mv
git rm git rm命令官方解释 删除的本质 在git中删除一个文件,本质上是从tracked files中移除对这些文件的跟踪.更具体地说,就是将这些文件从staging area移除.然后c ...
- Tkinter关于新建窗口内Entry无法获取值(值全为空)的解决办法
最近在做Python的课程作业,遇到一个问题,描述如下: 使用Python内置的Tkinter模块进行GUI编程 给一个按钮(或菜单)绑定事件,打开一个新窗口,新窗口内有Entry若干,通过textv ...
- 最近都会来学一点Python
https://www.cnblogs.com/hellosecretgarden/p/9206648.html 打开电脑,发现Python都是之前的代码,将近一年之前的时间. 最近都会重新掌握起来, ...
- github看项目-浏览器插件
浏览器插件,使用浏览器看github项目 原文:浏览 GitHub 太卡了?教你两招!
- The 2019 Asia Nanchang First Round Online Programming Contest The Nth Item
The Nth Item 思路: 先用特征根法求出通向公式,然后通向公式中出现了\(\sqrt{17}\),这个可以用二次剩余求出来,然后可以O(\(log(n)\))求出. 但是还不够,我们先对\( ...
- 个性化召回算法实践(二)——LFM算法
LFM算法核心思想是通过隐含特征(latent factor)联系用户兴趣和物品,找出潜在的主题和分类.LFM(latent factor model)通过如下公式计算用户u对物品i的兴趣: \[ P ...
- Codeforces Round #609 (Div. 2) C. Long Beautiful Integer
链接: https://codeforces.com/contest/1269/problem/C 题意: You are given an integer x of n digits a1,a2,- ...