11_Hive TransForm 案例
1.需求:将Json格式的数据处理后插入新表中
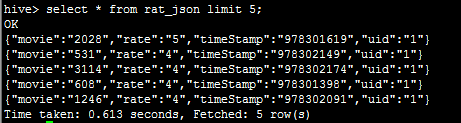
数据文件如下:rating.json,文件格式:{"movie":"2858","rate":"5","timeStamp":"978159467","uid":"17"}
{"movie":"2028","rate":"5","timeStamp":"978301619","uid":"1"}
{"movie":"531","rate":"4","timeStamp":"978302149","uid":"1"}
{"movie":"3114","rate":"4","timeStamp":"978302174","uid":"1"}
{"movie":"608","rate":"4","timeStamp":"978301398","uid":"1"}
{"movie":"1246","rate":"4","timeStamp":"978302091","uid":"1"}
{"movie":"1357","rate":"5","timeStamp":"978298709","uid":"2"}
{"movie":"3068","rate":"4","timeStamp":"978299000","uid":"3"}
{"movie":"1537","rate":"4","timeStamp":"978299620","uid":"3"}
{"movie":"434","rate":"2","timeStamp":"978300174","uid":"4"}
{"movie":"2126","rate":"3","timeStamp":"978300123","uid":"5"}
{"movie":"2067","rate":"5","timeStamp":"978298625","uid":"6"}
{"movie":"1265","rate":"3","timeStamp":"978299712","uid":"7"}
实现步骤:
1.使用Hive创建原始表rate_json,并将rating.json文件加载到该表
hive> create table rat_json(line string) row format delimited;
hive> load data local inpath '/root/rating.json' into table rat_json;
2.实现方案1:自定义函数实现json数据字段的切分
2.1:开发java类继承UDF,然后重载evaluate方法
2.2:上传jar包至服务器,并将jar包添加到hive的classpath下:hive>add jar /data/udf.jar;
2.3:创建临时函数与开发好的java class关联:create temporary function parsejson as 'cn.hive.demo.JsonParser';
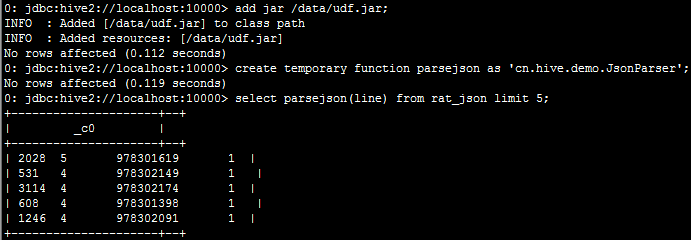
3.实现方案2:使用内置函数split进行字段切分,然后保存到一张新表中;

insert overwrite table t_rating
select split(parsejson(line),'\t')[0]as movieid,split(parsejson(line),'\t')[1] as rate,
split(parsejson(line),'\t')[2] as timestring,split(parsejson(line),'\t')[3] as uid
from rat_json limit 10;

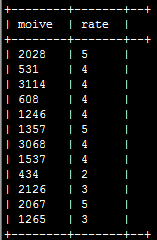
4.实现方案3:使用内置jason函数;
select get_json_object(line,'$.movie') as moive,get_json_object(line,'$.rate') as rate from rat_json;
5.实现方案4:Hive的 Transform 关键字提供了在SQL中调用自写脚本的功能,适合实现Hive中没有的功能又不想写UDF的情况
使用transform+python脚本的方式
根据上述过程,将原始表rat_json中的json格式的数据进行切分并存储到t_rating表中:
5.1:编辑一个Python脚本:weekday_mapper.py
#!/bin/python
import sys
import datetime for line in sys.stdin://标准输出到屏幕上的东西
line = line.strip()
movieid, rating, unixtime,userid = line.split('\t')//t_rating表输出到屏幕上的数据是以table键隔开显示的
weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
print '\t'.join([movieid, rating, str(weekday),userid])
5.2:将文件加入hive的classpath:hive> add file /root/weekday_mapper.py;
5.3:执行查询
hive>create table u_data_new as
SELECT
TRANSFORM (movieid, rate, timestring,uid)
USING 'python weekday_mapper.py'
AS (movieid, rate, weekday,uid)
FROM t_rating;
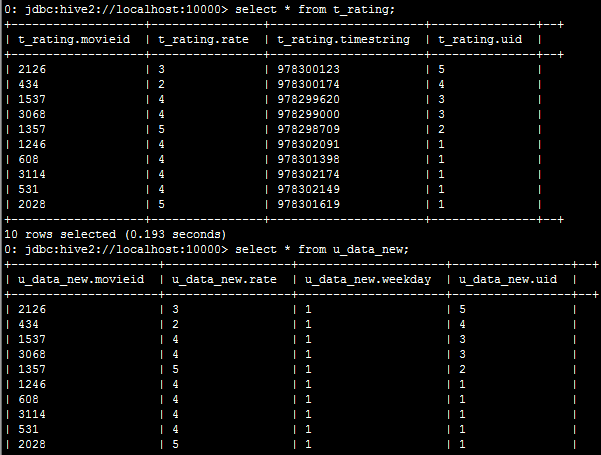
使用transform+python的方式去转换unixtime为weekday
11_Hive TransForm 案例的更多相关文章
- day11hadoop高可用和Hive
PS:视频一直就是在演示 高可用(比较偏运维一点) PS:Active是对外提供服务的,standBy是从属备用的:但是他们是怎样保证同步的数据的呢?一个运行中zookeeper上的第三方那个工具 ...
- Hive的DML操作
1. Load 在将数据加载到表中时,Hive 不会进行任何转换.加载操作是将数据文件移动到与 Hive表对应的位置的纯复制/移动操作. 语法结构: load data [local] inpath ...
- css3 知识点积累
-moz- 兼容火狐浏览器-webkit- 兼容chrome 和safari1.角度 transform:rotate(30dge) 水平线与div 第四象限30度 transform: ...
- 机械表小案例之transform的应用
这个小案例主要是对transform的应用. 时钟的3个表针分别是3个png图片,通过setInterval来让图片转动.时,分,秒的转动角度分别是30,6,6度. 首先,通过new Date函数获取 ...
- 56、Spark Streaming: transform以及实时黑名单过滤案例实战
一.transform以及实时黑名单过滤案例实战 1.概述 transform操作,应用在DStream上时,可以用于执行任意的RDD到RDD的转换操作.它可以用于实现,DStream API中所没有 ...
- H5案例分享:移动端滑屏 touch事件
移动端滑屏 touch事件 移动端触屏滑动的效果的效果在电子设备上已经被应用的越来越广泛,类似于PC端的图片轮播,但是在移动设备上,要实现这种轮播的效果,就需要用到核心的touch事件.处理touch ...
- 通过案例对 spark streaming 透彻理解三板斧之三:spark streaming运行机制与架构
本期内容: 1. Spark Streaming Job架构与运行机制 2. Spark Streaming 容错架构与运行机制 事实上时间是不存在的,是由人的感官系统感觉时间的存在而已,是一种虚幻的 ...
- 通过案例对 spark streaming 透彻理解三板斧之一: spark streaming 另类实验
本期内容 : spark streaming另类在线实验 瞬间理解spark streaming本质 一. 我们最开始将从Spark Streaming入手 为何从Spark Streaming切入 ...
- 精选19款华丽的HTML5动画和实用案例
下面是本人收集的19款超酷HTML5动画和实用案例,觉得不错,分享给大家. 1.HTML5 Canvas火焰喷射动画效果 还记得以前分享过的一款HTML5烟花动画HTML5 Canvas烟花特效,今天 ...
随机推荐
- iOS-XMPP(转)
IM的实现原理 在我最初学习编程的时候,曾经用JAVA实现了一个最简单版的IM通讯,即通过Socket建立两台电脑之间的连接,然后发送IO流来进行即时通讯,我们现在所使用的IM软件尽管看上去非常 ...
- python之selenium多窗口切换
前提: 在页面操作过程中有时候点击某个链接会弹出新的窗口,这就需要主机切换到新打开的窗口上.WebDriver提供了switch_to.window()方法,可以实现在不同的窗口之间切换. 内容: 以 ...
- Re-ranking Person Re-identification with k-reciprocal Encoding
Re-ranking Person Re-identification with k-reciprocal Encoding Abstract In this paper, we propose a ...
- 【文章存档】Local Git 如何部署分支
又来存档文章了,链接 https://docs.azure.cn/zh-cn/articles/azure-operations-guide/app-service-web/aog-app-servi ...
- 2019-10-20 李宗盛 linux
Linux Linux简介(了解) Linux介绍:Linux是类UNIX计算机的统称 Linux操作系统的内核也是Linux Linux是由芬兰大学生Linux Torvalds于1991年编写 L ...
- 在图中寻找最短路径-----深度优先算法C++实现
求从图中的任意一点(起点)到另一点(终点)的最短路径,最短距离: 图中有数字的点表示为图中的不同海拔的高地,不能通过:没有数字的点表示海拔为0,为平地可以通过: 这个是典型的求图中两点的最短路径:本例 ...
- table固定头部,tbody内容滚动
直觉的感受是修改thead与tbody,尝试了以下几种方法,但均告失败. 1. 将tbody设置为块状元素,然后设置表格的高度与溢出: 1. 将thead设置为绝对定位,然后设置表格的高度与溢出: 1 ...
- C++中如何设计一个类只能在堆或者栈上创建对象,面试题
设计一个类,该类只能在堆上创建对象 将类的构造函数私有,拷贝构造声明成私有.防止别人调用拷贝在栈上生成对象. 提供一个静态的成员函数,在该静态成员函数中完成堆对象的创建 注意 在堆和栈上创建对象都会调 ...
- python 入门(基础)
1. python的常见数据类型(str , list ,dict,set) str (字符串的操作方法) astr = " Hello Workd " astr.strip() ...
- Java建造者模式(思维导图)
图1 建造者模式[点击查看大图] 基本的知识点已在思维导图中,下面是demo 1,Builder 为创建一个产品对象的各个部件指定抽象接口 public interface PersonBuilder ...