StratifiedShuffleSplit 交叉验证
python中数据集划分函数StratifiedShuffleSplit的使用
文章开始先讲下交叉验证,这个概念同样适用于这个划分函数
1.交叉验证(Cross-validation)
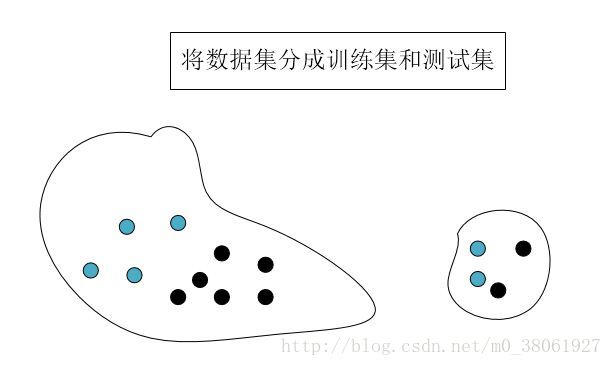
交叉验证是指在给定的建模样本中,拿出其中的大部分样本进行模型训练,生成模型,留小部分样本用刚建立的模型进行预测,并求这小部分样本的预测误差,记录它们的平方加和。这个过程一直进行,直到所有的样本都被预测了一次而且仅被预测一次,比较每组的预测误差,选取误差最小的那一组作为训练模型。下图所示
2.StratifiedShuffleSplit函数的使用
官方文档
用法:
from sklearn.model_selection import StratifiedShuffleSplit
StratifiedShuffleSplit(n_splits=10,test_size=None,train_size=None, random_state=None)2.1 参数说明
参数 n_splits是将训练数据分成train/test对的组数,可根据需要进行设置,默认为10
参数test_size和train_size是用来设置train/test对中train和test所占的比例。例如:
1.提供10个数据num进行训练和测试集划分
2.设置train_size=0.8 test_size=0.2
3.train_num=num*train_size=8 test_num=num*test_size=2
4.即10个数据,进行划分以后8个是训练数据,2个是测试数据
注*:train_num≥2,test_num≥2 ;test_size+train_size可以小于1*
参数 random_state控制是将样本随机打乱
2.2 函数作用描述
1.其产生指定数量的独立的train/test数据集划分数据集划分成n组。
2.首先将样本随机打乱,然后根据设置参数划分出train/test对。
3.其创建的每一组划分将保证每组类比比例相同。即第一组训练数据类别比例为2:1,则后面每组类别都满足这个比例
2.3 具体实现
from sklearn.model_selection import StratifiedShuffleSplit
import numpy as np
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4],
[1, 2],[3, 4], [1, 2], [3, 4]])#训练数据集8*2
y = np.array([0, 0, 1, 1,0,0,1,1])#类别数据集8*1
ss=StratifiedShuffleSplit(n_splits=5,test_size=0.25,train_size=0.75,random_state=0)#分成5组,测试比例为0.25,训练比例是0.75
for train_index, test_index in ss.split(X, y):
print("TRAIN:", train_index, "TEST:", test_index)#获得索引值
X_train, X_test = X[train_index], X[test_index]#训练集对应的值
y_train, y_test = y[train_index], y[test_index]#类别集对应的值
运行结果:
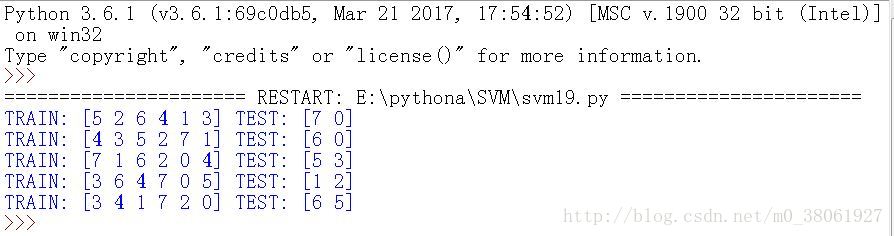
从结果看出,1.训练集是6个,测试集是2,与设置的所对应;2.五组中每组对应的类别比例相同
from:https://blog.csdn.net/m0_38061927/article/details/76180541
StratifiedShuffleSplit 交叉验证的更多相关文章
- 使用sklearn进行交叉验证
模型评估方法 假如我们有一个带标签的数据集D,我们如何选择最优的模型? 衡量模型好坏的标准是看这个模型在新的数据集上面表现的如何,也就是看它的泛化误差.因为实际的数据没有标签,所以泛化误差是不可能直接 ...
- MATLAB曲面插值及交叉验证
在离散数据的基础上补插连续函数,使得这条连续曲线通过全部给定的离散数据点.插值是离散函数逼近的重要方法,利用它可通过函数在有限个点处的取值状况,估算出函数在其他点处的近似值.曲面插值是对三维数据进行离 ...
- 交叉验证(Cross Validation)原理小结
交叉验证是在机器学习建立模型和验证模型参数时常用的办法.交叉验证,顾名思义,就是重复的使用数据,把得到的样本数据进行切分,组合为不同的训练集和测试集,用训练集来训练模型,用测试集来评估模型预测的好坏. ...
- scikit-learn一般实例之一:绘制交叉验证预测
本实例展示怎样使用cross_val_predict来可视化预测错误: # coding:utf-8 from pylab import * from sklearn import datasets ...
- oracle ebs应用产品安全性-交叉验证规则
转自: http://blog.itpub.net/298600/viewspace-625138/ 定义: Oracle键弹性域可以根据自定义键弹性域时所定义的规则,执行段值组合的自动交叉验证.使用 ...
- SVM学习笔记(二):什么是交叉验证
交叉验证:拟合的好,同时预测也要准确 我们以K折交叉验证(k-folded cross validation)来说明它的具体步骤.{A1,A2,A3,A4,A5,A6,A7,A8,A9} 为了简化,取 ...
- 交叉验证 Cross validation
来源:CSDN: boat_lee 简单交叉验证 hold-out cross validation 从全部训练数据S中随机选择s个样例作为训练集training set,剩余的作为测试集testin ...
- k-折交叉验证(k-fold crossValidation)
k-折交叉验证(k-fold crossValidation): 在机器学习中,将数据集A分为训练集(training set)B和测试集(test set)C,在样本量不充足的情况下,为了充分利用数 ...
- paper 35 :交叉验证(CrossValidation)方法思想
交叉验证(CrossValidation)方法思想简介 以下简称交叉验证(Cross Validation)为CV.CV是用来验证分类器的性能一种统计分析方法,基本思想是把在某种意义下将原始数据(da ...
随机推荐
- Python3.6全栈开发实例[005]
5.接收两个数字参数,返回比较大的那个数字. def compare(a,b): return a if a > b else b # 三元表达式 print(compare(20,100))
- 判断点是否在区域的python实现(射线法)
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2018-10-07 15:49:37 # @Author : Sheldon (thi ...
- [转] CentOS---网络配置详解
原文地址: http://blog.chinaunix.net/uid-26495963-id-3230810.html 一.配置文件详解在RHEL或者CentOS等Redhat系的Linux系统里, ...
- PhoneGap 兼容IOS上移20px(包括启动页,拍照)
引自:http://stackoverflow.com/questions/19209781/ios-7-status-bar-with-phonegap 情景:在ios7下PhoneGap app会 ...
- HDF及HDF-EOS数据格式简介
HDF-EOS数据格式介绍 HDF(Hierarchy Data Format )数据格式是美国伊利诺伊大学国家超级计算应用中心(NCSA ,National Central for Super co ...
- Apache Shiro:【2】与SpringBoot集成完成登录验证
Apache Shiro:[2]与SpringBoot集成完成登录验证 官方Shiro文档:http://shiro.apache.org/documentation.html Shiro自定义Rea ...
- HBase基本知识介绍及典型案例分析
本次分享的内容主要分为以下五点: HBase基本知识: HBase读写流程: RowKey设计要点: HBase生态介绍: HBase典型案例分析. 首先我们简单介绍一下 HBase 是什么. HBa ...
- Mycat实现Mysql数据库读写分离
Linux和Windows环境下搭建Mycat数据读写分离 前提需要:1.服务器装有JVM虚拟机,就是JDK.2.两个Mysql数据库已经实现主从复制,参考:https://www.cnblogs.c ...
- MySQL密码的恢复方法
MySQL密码的恢复方法之一 1.首先确认服务器出于安全的状态,也就是没有人能够任意地连接MySQL数据库. 因为在重新设置MySQL的root密码的期间,MySQL数据库完全出于没有密码保护的 状态 ...
- Java 集合系列13之 TreeMap详细介绍(源码解析)和使用示例
转载 http://www.cnblogs.com/skywang12345/p/3310928.html https://www.jianshu.com/p/454208905619