Oracle常见的表连接的方法
1 排序合并连接SMJ
Sort merge join
排序合并总结:
1 通常情况下,排序合并连接的效率远不如hash join,前者适用范围更广,hj只使用于等值连接,smj范围更广(<,>,>=,<=)
2 通常情况下,smj并不适合OLTP系统,排序操作是非常昂贵的操作,
2 嵌套循环连接NL
优化器会根据一定的规则来确定表T1,T2谁是驱动表,谁是被驱动表,驱动表用于外层循环,被驱动表用于内存循环,这里假设驱动表时T1,被驱动表时T2
目标sql中指定的谓词条件去访问T1,得到的结果集为1
然后遍历驱动结果集1同时遍历被驱动表T2,即先取出1中的第一条记录,接着遍历T2并按照条件去判断T2中是否存在配匹的记录,然后在取出1中的第二条记录。。。。
嵌套循环总结:
1 如果t1对应的驱动结果集较少,同时t2的连接列上又有唯一性索引,则效率会很高
2 只要驱动结果集很少就具备嵌套循环的前提条件
3 嵌套循环可以实现快速响应,即可以第一时间返回经过连接且满足条件的记录,而不必等待所有的连接操作全部做完才返回连接结果
如果使用了nl连接,并且t2的连接列上index,那么oracle访问该index是通常会使用单块读,则t1的返回n条结果,就会是t2访问该index n次,如果要回表,
则会回表n次,这就使得不在index 或者data buffer cache中的数据,发生物理I/O,
Oracle 11g使用了向量I/O,提高nl的连接效率
nested loop
outer table --驱动表
inner table
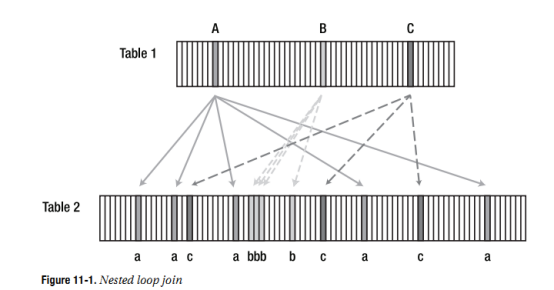
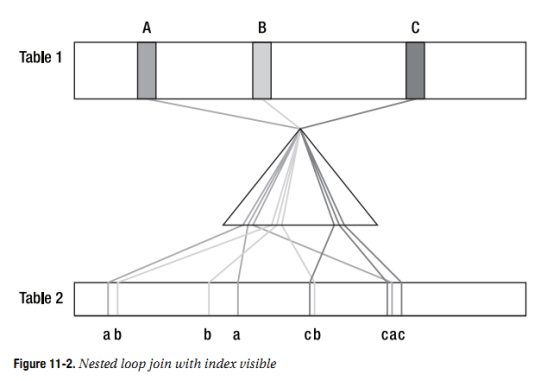
The second picture, shown in Figure 11-2, includes a representation of working through
an index on the second table, because an index is usually involved in this way when there is a
nested loop around.
例
create table t1 (col1 number, col2 varchar2(1)); create table t2 (col2 varchar2(1), col3 varchar2(2)); insert into t1 values(1,'A');
insert into t1 values(2,'B');
insert into t1 values(3,'C');
insert into t2 values('A','A1');
insert into t2 values('B','B1');
insert into t2 values('D','D1');
Connected to:
Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - 64bit Production
With the Partitioning, OLAP and Data Mining options SQL> set linesize 1000
SQL> set pagesize 1000
SQL> set timing on
SQL> set autot trace only
SP2-0158: unknown SET option "only"
SQL> set autotrace traceonly;
SQL> select t1.col1,t1.col2,t2.col3
2 from t1,t2
3 where t1.col2=t2.col2;
Elapsed: 00:00:00.04
Execution Plan
----------------------------------------------------------
Plan hash value: 2253255382
--------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 60 | 4 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T2 | 1 | 5 | 1 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 3 | 60 | 4 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL | T1 | 3 | 45 | 3 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | IDX_T2 | 1 | | 0 (0)| 00:00:01 |
--------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("T1"."COL2"="T2"."COL2")
Note
-----
- dynamic sampling used for this statement
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
13 consistent gets
0 physical reads
0 redo size
469 bytes sent via SQL*Net to client
337 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
2 rows processed
3 哈希连接HJ
哈希连接是两个表在做连接时只要依靠哈希运算来得到结果集(仅适合CBO),在解析目标sql 时是否考虑哈希连接受限制与隐含参数(_HASH_JOIN_ENABLED),
默认值TRUE,如果值为false,强制使用hint,也是会走hj的
1 oracle会根据参数HASH_AREA_SIZE,DB_BLOCK_SIZE,_HASH_MULTIBLOCK_IO_COUNT来决定hash partition的数量,所有hash partition的集合称为Hash table,
2 表t1,t2在目标sql中的谓词条件后,得到结果集中的数据量较少的那个结果集会被oracle选为哈希连接的驱动结果集,假设t1的结果集1较少(驱动结果集),t2的结果2(被驱动结果集)
3 oracle会遍历结果集1,读取1中的每一条记录,并对每一条记录按照该记录t1中的连接列做哈希运算,
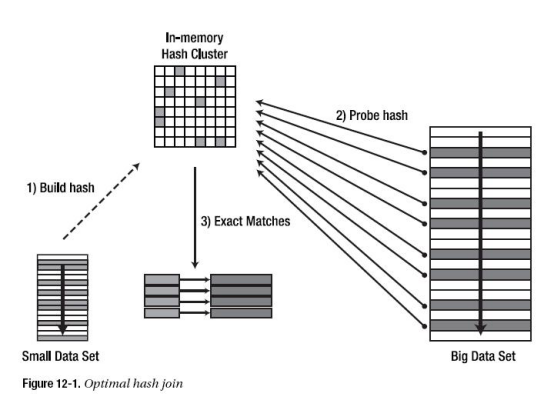
--小表在数据在指定谓词后做哈希运算放入pga中(超过放入temp),大表数据按照连接列做哈希运算,然后大表去配匹pga中的值,遍历完为止
哈希连接的优缺点:
1 哈希连接不一定会排序,大多数情况下不需要排序
2 哈希连接的驱动表所对应的连接列的可选择性尽可能的好,会影响hash bucket中的记录数,哈希连接中,遍历hash bucket的动作发生在pga工作区中,不消耗逻辑读,
3 哈希连接适用于CBO,等值连接
4 哈希连接适合大表跟小表的连接,2个表做哈希连接,在指定了谓词后的sql中得到的数量较少的结果集所对应的hash table能完全容纳在pga中,则效率会很高。
SQL> select /*+ leading (t1) use_hash(t2) */
2 t1.col1,t1.col2,t2.col3
3 from t1,t2
4 where t1.col2=t2.col2;
Elapsed: 00:00:00.25
Execution Plan
----------------------------------------------------------
Plan hash value: 1838229974
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 60 | 7 (15)| 00:00:01 |
|* 1 | HASH JOIN | | 3 | 60 | 7 (15)| 00:00:01 |
| 2 | TABLE ACCESS FULL| T1 | 3 | 45 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| T2 | 3 | 15 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("T1"."COL2"="T2"."COL2")
Note
-----
- dynamic sampling used for this statement
Statistics
----------------------------------------------------------
7 recursive calls
0 db block gets
32 consistent gets
0 physical reads
0 redo size
469 bytes sent via SQL*Net to client
337 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
2 sorts (memory)
0 sorts (disk)
2 rows processed
4笛卡尔连接cross join
2个表在做连接是,没有指定任何连接条件的连接
SQL> select
2 t1.col1,t1.col2,t2.col3
3 from t1,t2; 9 rows selected. Elapsed: 00:00:00.03 Execution Plan
----------------------------------------------------------
Plan hash value: 787647388 -----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 9 | 162 | 8 (0)| 00:00:01 |
| 1 | MERGE JOIN CARTESIAN| | 9 | 162 | 8 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL | T1 | 3 | 45 | 3 (0)| 00:00:01 |
| 3 | BUFFER SORT | | 3 | 9 | 5 (0)| 00:00:01 |
| 4 | TABLE ACCESS FULL | T2 | 3 | 9 | 2 (0)| 00:00:01 |
-----------------------------------------------------------------------------
5 反连接Anti join
做子查询展开时,oracle会经常把那些外部where条件为 no exists,not in ,<>all的子查询转换成对应的反连接
SQL> select * from t1
2 where t1.col2 not in (select col2 from t2);
Elapsed: 00:00:00.01
Execution Plan
----------------------------------------------------------
Plan hash value: 895956251
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 15 | 5 (0)| 00:00:01 |
|* 1 | FILTER | | | | | |
| 2 | TABLE ACCESS FULL| T1 | 3 | 45 | 3 (0)| 00:00:01 |
|* 3 | TABLE ACCESS FULL| T2 | 3 | 6 | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter( NOT EXISTS (SELECT /*+ */ 0 FROM "T2" "T2" WHERE
LNNVL("COL2"<>:B1)))
3 - filter(LNNVL("COL2"<>:B1))
SQL> select * from t1
2 where not exists (select 1 from t2 where t1.col2=t2.col2);
Elapsed: 00:00:00.01
Execution Plan
----------------------------------------------------------
Plan hash value: 1534930707
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 17 | 3 (0)| 00:00:01 |
| 1 | NESTED LOOPS ANTI | | 1 | 17 | 3 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL| T1 | 3 | 45 | 3 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | IDX_T2 | 3 | 6 | 0 (0)| 00:00:01 |
-----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("T1"."COL2"="T2"."COL2")
alter session set "_optimizer_null_aware_antijoin"=false
6 半连接semi join
半连接跟普通的连接不同,半连接会去重?
对子查询展开,exists,in等
SQL> select * from t1
2 where t1.col2 in (select col2 from t2);
Elapsed: 00:00:00.01
Execution Plan
----------------------------------------------------------
Plan hash value: 3783859632
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 51 | 3 (0)| 00:00:01 |
| 1 | NESTED LOOPS SEMI | | 3 | 51 | 3 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL| T1 | 3 | 45 | 3 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | IDX_T2 | 3 | 6 | 0 (0)| 00:00:01 |
----------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 3 - access("T1"."COL2"="COL2")
SQL> select * from t1
2 where exists (select 1 from t2 where t1.col2=t2.col2);
Elapsed: 00:00:00.01
Execution Plan
----------------------------------------------------------
Plan hash value: 3783859632
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 51 | 3 (0)| 00:00:01 |
| 1 | NESTED LOOPS SEMI | | 3 | 51 | 3 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL| T1 | 3 | 45 | 3 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN | IDX_T2 | 3 | 6 | 0 (0)| 00:00:01 |
----------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 3 - access("T1"."COL2"="T2"."COL2")
总结一下
- 在哪种情况下用哪种连接方法比较好:
A)排序合并连接(Sort Merge Join, SMJ):
a) 对于非等值连接,这种连接方式的效率是比较高的。
b) 如果在关联的列上都有索引,效果更好。
c) 对于将2个较大的表源做连接,该连接方法比NL连接要好一些。
B)嵌套循环(Nested Loops, NL):
a) 如果驱动表(外部表)比较小,并且在被驱动表(内部表)上有唯一索引,或有高选择性非唯一索引时,使用这种方法可以得到较好的效率。
b)嵌套循环连接有其它连接方法没有的的一个优点是:可以先返回已经连接的行,而不必等待所有的连接操作处理完才返回数据,这可以实现快速的响应时间。
C)哈希连接(Hash Join, HJ):
a) 这种方法是在oracle7后来引入的,使用了比较先进的连接理论,一般来说,其效率应该好于其它2种连接,但是这种连接只能用在CBO优化器中,
而且需要设置合适的hash_area_size参数,才能取得较好的性能。
b) 在2个较大的表源之间连接时会取得相对较好的效率,在一个表源较小时则能取得更好的效率。
c) 只能用于等值连接中
Oracle常见的表连接的方法的更多相关文章
- Oracle 导出空表的新方法(彻底解决)
背景 使用Exp命令在oracle 11g 以后不导出空表(rowcount=0),是最近在工作中遇到一个很坑的问题,甚至已经被坑了不止一次,所以这次痛定思痛,准备把这个问题彻底解决.之所以叫新方法, ...
- 转载 ORACLE中实现表变量的方法
源文地址:http://blog.itpub.net/750077/viewspace-2134222/ 经常看到SQLSERVER 中用表变量类型的方式就能做到缓存一个比较大的中间结果, 然后再对这 ...
- 移动Oracle的用户表空间文件方法
原文:http://www.linuxidc.com/Linux/2014-07/104702.htm 1.以sys用户登录 sqlplus /nologSQL>connect s ...
- Oracle数据库锁表的查询方法以及解锁的方法
1,锁表语句简单查询方法 select t2.username,t2.sid,t2.serial#,t2.logon_time from v$locked_object t1,v$session ...
- oracle三种表连接方式
1. 排序合并连接(Sort Merge Join) 排序合并连接的执行过程如下所示: * 将每个行源的行按连接谓词列排序 * 然后合并两个已排序的行源,并返回生成的行源 例如: select * f ...
- 查看oracle是否锁表以及解决方法
Oracle数据库操作中,我们有时会用到锁表查询以及解锁和kill进程等操作,那么这些操作是怎么实现的呢?本文我们主要就介绍一下这部分内容.(1)锁表查询的代码有以下的形式: select count ...
- Oracle三大经典表连接适用情况
1.1环境准备 1.2 Nested Loops Join 从上面的试验来看,nested loop jion基本上是没有限制的,可以支持所有的运算. 1.3 Hash Join 1.4 Merge ...
- Oracle 优化器_表连接
概述 在写SQL的时候,有时候涉及到的不仅只有一个表,这个时候,就需要表连接了.Oracle优化器处理SQL语句时,根据SQL语句,确定表的连接顺序(谁是驱动表,谁是被驱动表及 哪个表先和哪个表做链接 ...
- ORACLE 表连接详解
在ORACLE中,表连接方式主要有:内连接,外连接,自连接: 内连接: 这是最常用的连接查询 SELECT * FROM A INNER JOIN B ON A.ID=B.ID SELECT * FR ...
随机推荐
- CSS打造固定表头
html代码: <!DOCTYPE html> <html> <head lang="en"> <meta charset="U ...
- LeetCode第[15]题(Java):3Sum (三数之和为目标值)——Medium
题目难度:Medium 题目: Given an array S of n integers, are there elements a, b, c in S such that a + b + c ...
- spring学习(6)
1 spring概念 (1)spring核心两部分 (2)spring一站式框架 (3)spring版本 可以使用基本的javaBean代替EJB,EJB是重量级框架. 1 spring是一个开源的轻 ...
- appium自动化测试(三)
一. 层级定位和list 先通过find_element_by_XXX找到父级元素webelement,再通过webelement.find_element_by_XXX寻找子元素 二. 滑动屏幕 滑 ...
- 使用ZooKeeper实现Java跨JVM的分布式锁(优化构思)
一.使用ZooKeeper实现Java跨JVM的分布式锁 二.使用ZooKeeper实现Java跨JVM的分布式锁(优化构思) 三.使用ZooKeeper实现Java跨JVM的分布式锁(读写锁) 说明 ...
- 剑指offer--31.二叉树中和为某一值的路径
深度优先搜索 --------------------------------------------------------------------------------------------- ...
- Android 框架学习1:EventBus 3.0 的特点与如何使用
前面总结了几篇基础,在这过程中看着别人分享自定义 View.架构或者源码分析,看起来比我写的"高大上"多了,内心也有点小波动. 但是自己的水平自己清楚,基础不扎实画再多源码流程图也 ...
- 旧书重温:0day2【5】shellcode变形记
紧接上一篇,结合第一篇 //这篇文章主要成功溢出一个带有缓冲区溢出的小程序,其中我们的shellcode被strcpy截断了所以我们需要变形shellcode,这个实验中也出现了很多意想不到的拦路虎, ...
- Laraver 框架资料
重定向: return redirect()->to('http://www.baidu.com'); 重定向到内部路由 return redirect()->route(‘name’); ...
- BZOJ - 4771 七彩树 (可持久化线段树合并)
题目链接 对每个结点建立两棵线段树,一棵记录该结点的子树下每种颜色对应的最小深度,另一棵记录子树下的每个深度有多少结点(每种颜色的结点只保留最浅的深度即可),自底而上令父节点继承子结点的线段树,如果合 ...