python's seventh day for me set
数据类型的补充:
对于元祖: 如果只有一个元素,并且没有逗号,此元素是什么数据类型,该表达式就是什么数据类型。
tu = ('顾清秋')
tul = ('顾清秋',)
print(type(tu))
print(type(tul))
# <class 'str'>
# <class 'tuple'>
对于列表: 在循环一个列表时,最好不要进行删除的动作(一旦删除索引会随之改变),容易出错。
li = [1,2,3,4,5] #删除索引为奇数的元素
del li[1::2] #切片删除
print(li) # [1, 3, 5] li = [1,2,3,4,5] #删除索引为奇数的元素
for i in range (len(li)-1,-1,-1): #反向打印索引。
# print(i)
if i % 2 ==1: #检测索引是否为奇数
del li[i] #从后往前删除元素,不会影响前面的索引位置。
print(li) # [1, 3, 5] li = [1,2,3,4,5] #删除索引为奇数的元素
li2 = [] #定义一个空列表,用来存放索引为偶数的元素
for i in range(len(li)):
# print(i)
if i % 2 == 0:
li2.append(li[i]) #将索引为偶数的元素加入到li2中
li = li2 # 将列表li2中的索引为偶数的元素赋值给li
print(li) # [1, 3, 5]
对于字典: 在循环字典中,不能增加或者删除此字典的键值对。否则会报错(dictionary changed size during iteration)
# 将字典中含有k元素的键以及其对应的键值对删除。
dic = {'k1':'顾清秋','k2':'懒笨呆','name':'alex'}
li = [] #用来存放dic中含k元素的键。
for i in dic.keys():
# print(i)
if 'k' in i: #判断是否存在
li.append(i)
for i in li:
del dic[i] #删除dic中含k键的键值对。
print(dic) # {'name': 'alex'}
fromkeys()
dic = dict.fromkeys('abc','alex')
print(dic)
# {'c': 'alex', 'b': 'alex', 'a': 'alex'}
dic = dict.fromkeys([1,2,3],[])
print(dic)
# 1: [], 2: [], 3: []}
dic[1].append('顾清秋')
print(dic)
# {1: ['顾清秋'], 2: ['顾清秋'], 3: ['顾清秋']}
#由上面输出可以看出1,2,3所对应的[]是同一个空列表,一个改变其他的都随之改变。
tuple 与 list 之间的相互转换。
#将元祖转换成列表
tu = (1,2,3)
li = list(tu)
print(li) # [1, 2, 3] #将列表转换成元祖
li2 = [1,2,3]
tu2 = tuple(li2)
print(tu2) #(1, 2, 3)
数据类型转换成 bool 为 False
0, 空字符串, 空列表, 空字典, 空元祖。
tulpe ---> str (单向)
tu = ('顾清秋','lanbendai')
s = ''.join(tu)
print(s)
# 顾清秋lanbendai
集合 set
去重:
#去除li中重复的数字。
li = [11,22,33,33,44,22,55]
li = list(set(li)) #set()去除重复的数字,再转换成列表赋值给li
print(li) # {33, 11, 44, 22, 55}
集合的创建:
set1 = set({1,2,'guqingqiu'})
print(set1,type(set1))
# {'guqingqiu', 1, 2} <class 'set'>
集合的 增 :
add update
set1 = {'顾清秋','懒笨呆'}
set1.add('guqingqiu')
print(set1)
# {'顾清秋', '懒笨呆', 'guqingqiu'}
set1.update('abc')print(set1)
# {'懒笨呆', 'b', '顾清秋', 'a', 'guqingqiu', 'c'}
集合的 删 :
remove() 指定元素删除
set1 = {'顾清秋','懒笨呆'}
set1.remove('顾清秋')
print(set1)
# {'懒笨呆'}
pop() 随机删除
set1 = {'顾清秋','懒笨呆'}
print(set1 .pop()) #有返回值
print(set1)
# 懒笨呆
# {'顾清秋'}
clear 清空集合
set1 = {'顾清秋','懒笨呆'}
set1.clear()
print(set1)
#set() #空集合
del 直接删除集合。
集合的 查
用 for 循环查看
set1 = {'顾清秋','懒笨呆'}
for i in set1:
print(i)
# 顾清秋
# 懒笨呆
集合的 交集 :
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 & set2)
print(set1.intersection(set2))
# {4, 5}
# {4, 5}
集合的 反交集 :
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 ^ set2)
print(set1.symmetric_difference(set2))
# {1, 2, 3, 6, 7, 8}
# {1, 2, 3, 6, 7, 8}
集合的 并
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 | set2)
print(set1.union(set2))
# {1, 2, 3, 4, 5, 6, 7, 8}
# {1, 2, 3, 4, 5, 6, 7, 8}
集合的 差集 :
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 - set2)#哪个集合在前面打印的就是哪个集合多出来的
print(set2 - set1)
# {1, 2, 3}
# {8, 6, 7}
集合的 子集 :
set1 = {1,2,3}
set2 = {1,2,3,4,5,6}
print(set1.issubset(set2)) #子集
print(set2.issuperset(set1)) #set2 是 set1的超集
# True
# True
集合的 冻集合 :
frozenset() 将集合转换成不可变类型
set1 = {'顾清秋','懒笨呆'}
set2 = frozenset(set1)
print(set2,type(set2))
# frozenset({'顾清秋', '懒笨呆'}) <class 'frozenset'>
对于赋值运算,指向的是同一个内存地址。字典,列表,集合都一样。
l1 = [1,2,3]
l2 = l1
l2.append(111)
print(l1,l2) # [1, 2, 3, 111] [1, 2, 3, 111]

浅 copy() 第一层创建的是新的内存地址,但是第二层开始,指向的都是同一个内存地址,所以对于第二层以及更深的层数来说,将会保持一致性。
l1 = [1,2,[1,2,3],4]
l2 = l1.copy()
l1[2].append(666)
print(l1[2])
print(l2[2])
print(l1,id(l1[2]))
print(l2,id(l2[2])) # [1, 2, 3, 666]
# [1, 2, 3, 666]
# [1, 2, [1, 2, 3, 666], 4] 1872001973960
# [1, 2, [1, 2, 3, 666], 4] 1872001973960
deep.copy()
对于深 copy来说,两个是完全独立的,改变任意一个任何元素(无论多少层),另一个绝对不改变。
import copy #调用copy库
l1 = [1,2,[1,2,3],4]
l2 = copy.deepcopy(l1)
l1[2].append(666)
print(l1,l2)
print(id(l1[2]),id(l2[2])) # [1, 2, [1, 2, 3, 666], 4] [1, 2, [1, 2, 3], 4]
# 1803667445192 1803667444808
切片赋值 一个改变另一个随之改变 第一层的id 内存位置不同,但子层id一致。类似于浅copy().
l1 = [1,2,3,[22,33]]
l2 = l1[:]
l1[3].append(666)
print(l1)
print(l2) # [1, 2, 3, [22, 33, 666]]
# [1, 2, 3, [22, 33, 666]]
==================================
s = 'guqingqiu'
s1 = s.encode('utf-8') #unicode ---> utf-8 编码
print(s1)
s3 = s1.decode('utf-8') # utf-8 ---> unicode 解码
print(s3) # b'guqingqiu'
# guqingqiu
utf -8 转成 gbk
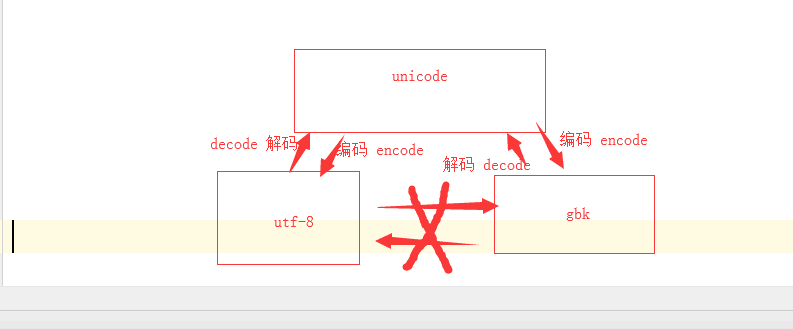
s = '老男孩'
s1 = s.encode('gbk') #unicode ---> gbk
print(s1)
s2 = s1.decode('gbk').encode('utf-8') # gbk -->unicode-->utf-8
print(s2) # b'\xc0\xcf\xc4\xd0\xba\xa2'
# b'\xe8\x80\x81\xe7\x94\xb7\xe5\xad\xa9'
python's seventh day for me set的更多相关文章
- Python从入门到精通之Seventh!
函数浅析:可以减少代码重用,保持一致性,可扩展性,易维护性. 定义方法:def 函数名(形参): '''功能注释''' 代码块 打印函数名时,会出现函数的内存地址.两个函数名相同时, ...
- 结合使用 Oracle Database 11g 和 Python
结合使用 Oracle Database 11g 和 Python 本教程介绍如何结合使用 Python 和 Oracle Database 11g. 所需时间 大约 1 个小时 概述 Python ...
- Python迭代和解析(5):搞懂生成器和yield机制
解析.迭代和生成系列文章:https://www.cnblogs.com/f-ck-need-u/p/9832640.html 何为生成器 生成器的wiki页:https://en.wikipedia ...
- python 全栈开发,Day30(第一次面向对象考试)
月考题: python 全栈11期月考题 一 基础知识:(70分) 1.文件操作有哪些模式?请简述各模式的作用(2分) 2.详细说明tuple.list.dict的用法,以及它们的特点(3分) 3.解 ...
- 正则表达式匹配可以更快更简单 (but is slow in Java, Perl, PHP, Python, Ruby, ...)
source: https://swtch.com/~rsc/regexp/regexp1.html translated by trav, travmymail@gmail.com 引言 下图是两种 ...
- Python Base Four
35. In python, file operation syntax is similar to c. open(file,'r',……) //the first parameters is ne ...
- Python考试_第三次
- python 全栈11期月考题 一 基础知识:(70分) 1.文件操作有哪些模式?请简述各模式的作用(2分) 2.详细说明tuple.list.dict的用法,以及它们的特点(3分) 3.解释生成 ...
- python中关于传递参数模块argprase的一些小坑
今天在写代码的时候遇到了一个关于parser的一些小坑,记录在此备用. 我们知道在python中可以用argprase来传递一些参数给代码执行,来看下面的例子,假设现在有一个test文件夹,下面有3个 ...
- Python中的多进程与多线程(一)
一.背景 最近在Azkaban的测试工作中,需要在测试环境下模拟线上的调度场景进行稳定性测试.故而重操python旧业,通过python编写脚本来构造类似线上的调度场景.在脚本编写过程中,碰到这样一个 ...
随机推荐
- SessionUtils
import com.diyfintech.constant.Constant.SuperAdmin; import com.diyfintech.pojo.SysUser; import org.a ...
- Java基础13:反射与注解详解
Java基础13:反射与注解详解 什么是反射? 反射(Reflection)是Java 程序开发语言的特征之一,它允许运行中的 Java 程序获取自身的信息,并且可以操作类或对象的内部属性. Orac ...
- AI实现五子棋机器人(一)
前言: 前几天在 csdn 下载资源的时候才发现自己 csdn 有近 200 的下载积分,看了看共享的资源,哈哈 ... 7年前写的五子棋游戏很受欢迎. 下载地址:新手入门五子棋游戏 刚入行的 ...
- iOS自动化探索(六)自动化测试框架pytest - fixtures
Fixture介绍 fixture是pytest特有的功能,它用pytest.fixture标识,定义在函数前面.在编写测试函数的时候,可以将此函数名称做为传入参数,pytest将会以依赖注入方式,将 ...
- 20-THREE.JS 混合材质
<!DOCTYPE html> <html> <head> <title></title> <script src="htt ...
- Apk大瘦身
Android的apk文件越来越大了这已经是一个不争的事实.在Android 还是最初版本的时候,一个app的apk文件大小也还只有2 MB左右,到了现在,一个app的apk文件大小已经升级到10MB ...
- Android 用户界面---定制组件(Custom Components)
基于布局类View和ViewGroup的基本功能,Android为创建自己的UI界面提供了先进和强大的定制化模式.首先,平台包含了各种预置的View和ViewGroup子类---Widget和layo ...
- js 设置日期函数
前三十天: var now = new Date(); var prev = now.setDate( now.getDate() - 30 ) vm.sDate = comm.getFormatDa ...
- iOS开发之谓词Predicate和对象数组的排序
我们在开发中经常使用的Predicate谓词,主要是正则表达式的使用,今天给大家简单的讲讲怎样去使用谓词. 因为内容比较简单,所以直接上代码展示: NSMutableArray *people_arr ...
- (转) Myisam和Innodb索引实现的不同(存储结构)
转自 : https://blog.csdn.net/donghaixiaolongwang/article/details/60751543