pandas DataFrame的创建方法
pandas DataFrame的增删查改总结系列文章:
在pandas里,DataFrame是最经常用的数据结构,这里总结生成和添加数据的方法:
①、把其他格式的数据整理到DataFrame中;
②在已有的DataFrame中插入N列或者N行。
1. 字典类型读取到DataFrame(dict to DataFrame)
假如我们在做实验的时候得到的数据是dict类型,为了方便之后的数据统计和计算,我们想把它转换为DataFrame,存在很多写法,这里简单介绍常用的几种:
方法一:直接使用pd.DataFrame(data=test_dict)即可,括号中的data=写不写都可以,具体如下:
test_dict = {'id':[1,2,3,4,5,6],'name':['Alice','Bob','Cindy','Eric','Helen','Grace '],'math':[90,89,99,78,97,93],'english':[89,94,80,94,94,90]}
#[1].直接写入参数test_dict
test_dict_df = pd.DataFrame(test_dict)
#[2].字典型赋值
test_dict_df = pd.DataFrame(data=test_dict)
那么,我们就得到了一个DataFrame,如下:

应该就是这个样子了。
方法二:使用from_dict方法:
test_dict_df = pd.DataFrame.from_dict(test_dict)
结果是一样的,不再重复贴图。
其他方法:如果你的dict变量很小,例如{'id':1,'name':'Alice'},你想直接写到括号里:
test_dict_df = pd.DataFrame({'id':1,'name':'Alice'}) # wrong style
这样是不行的,会报错ValueError: If using all scalar values, you must pass an index,是因为如果你提供的是一个标量,必须还得提供一个索引Index,所以你可以这么写:
test_dict_df = pd.DataFrame({'id':1,'name':'Alice'},pd.Index(range(1)))
后面的可以写多个pd.Index(range(3),就会生成三行一样的,是因为前面的dict型变量只有一组值,如果有多个,后面的Index必须跟前面的数据组数一致,否则会报错:
pd.DataFrame({'id':[1,2],'name':['Alice','Bob']},pd.Index(range(2))) #must be 2 in range function.
关于选择列,有些时候我们只需要选择dict中部分的键当做DataFrame的列,那么我们可以使用columns参数,例如我们只选择'id','name'列:
test_dict_df = pd.DataFrame(data=test_dict,columns=['id','name']) #only choose 'id' and 'name' columns
这里就不在多写了,后续变更颜色添加内容。
2. csv文件构建DataFrame(csv to DataFrame)
我们实验的时候数据一般比较大,而csv文件是文本格式的数据,占用更少的存储,所以一般数据来源是csv文件,从csv文件中如何构建DataFrame呢? txt文件一般也能用这种方法。
方法一:最常用的应该就是pd.read_csv('filename.csv')了,用 sep指定数据的分割方式,默认的是','
df = pd.read_csv('./xxx.csv')
如果csv中没有表头,就要加入head参数
3. 在已有的DataFrame中,增加N列或者N行
加入我们已经有了一个DataFrame,如下图:
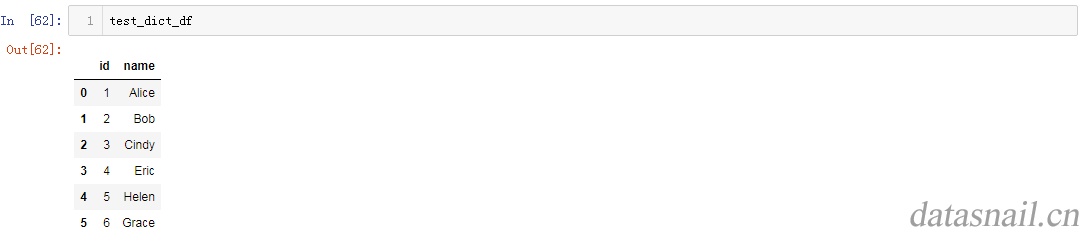
3.1 添加列
此时我们又有一门新的课physics,我们需要为每个人添加这门课的分数,按照Index的顺序,我们可以使用insert方法,如下:
new_columns = [92,94,89,77,87,91]
test_dict_df.insert(2,'pyhsics',new_columns)
#test_dict_df.insert(2,'pyhsics',new_columns,allow_duplicates=True)
此时,就得到了添加好的DataFrame,需要注意的是DataFrame默认不允许添加重复的列,但是在insert函数中有参数allow_duplicates=True,设置为True后,就可以添加重复的列了,列名也是重复的:

3.2 添加行
此时我们又来了一位新的同学Iric,需要在DataFrame中添加这个同学的信息,我们可以使用loc方法:
new_line = [7,'Iric',99]
test_dict_df.loc[6]= new_line
但是十分注意的是,这样实际是改的操作,如果loc[index]中的index已经存在,则新的值会覆盖之前的值。
当然也可以把这些新的数据构建为一个新的DataFrame,然后两个DataFrame拼起来。可以用append方法,不过不太会用,提供一种方法:
test_dict_df.append(pd.DataFrame([new_line],columns=['id','name','physics']))
本想一口气把CURD全写完,没想到写到这里就好累。。。其他后续新开篇章在写吧。
相关代码:(https://github.com/dataSnail/blogCode/blob/master/python_curd/python_curd_create.ipynb)(在DataFrame中删除N列或者N行)(在DataFrame中查询某N列或者某N行)(在DataFrame中修改数据)
pandas DataFrame的创建方法的更多相关文章
- pandas DataFrame的修改方法
pandas DataFrame的增删查改总结系列文章: pandas DaFrame的创建方法 pandas DataFrame的查询方法 pandas DataFrame行或列的删除方法 pand ...
- pandas DataFrame的查询方法(loc,iloc,at,iat,ix的用法和区别)
pandas DataFrame的增删查改总结系列文章: pandas DaFrame的创建方法 pandas DataFrame的查询方法 pandas DataFrame行或列的删除方法 pand ...
- 把pandas dataframe转为list方法
把pandas dataframe转为list方法 先用numpy的 array() 转为ndarray类型,再用tolist()函数转为list
- pandas.DataFrame的groupby()方法的基本使用
pandas.DataFrame的groupby()方法是一个特别常用和有用的方法.让我们快速掌握groupby()方法的基础使用,从此数据分析又多一法宝. 首先导入package: import p ...
- pandas.DataFrame 中save方法
In [5]: frame.save('frame_pickle') ----------------------------------------------------------------- ...
- Pandas:DataFrame数据选择方法(索引)
#首先创建我们的Series对象,然后合并到dataframe对象里面去 import pandas as pd import numpy as np area=pd.Series({,,,}) po ...
- pandas DataFrame行或列的删除方法
pandas DataFrame的增删查改总结系列文章: pandas DaFrame的创建方法 pandas DataFrame的查询方法 pandas DataFrame行或列的删除方法 pand ...
- pandas.DataFrame学习系列1——定义及属性
定义: DataFrame是二维的.大小可变的.成分混合的.具有标签化坐标轴(行和列)的表数据结构.基于行和列标签进行计算.可以被看作是为序列对象(Series)提供的类似字典的一个容器,是panda ...
- pandas.DataFrame——pd数据框的简单认识、存csv文件
接着前天的豆瓣书单信息爬取,这一篇文章看一下利用pandas完成对数据的存储. 回想一下我们当时在最后得到了六个列表:img_urls, titles, ratings, authors, detai ...
随机推荐
- 如何打卡后缀为3ds的文件
打开.3DS文件 3DS文件怎么打开? 用它吧:a3dsviewer,顾名思义,一个3D文件浏览工具,为用户提供一个快速和简单的3DS文件浏览器很容易. 这里是一些主要特点的“a3dsviewer”: ...
- 数据库——MySQL——存储引擎
现实生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制:比如处理文本用txt类型,处理表格用excel,处理图片用png等.数据库中的表也应该有不同的类型,表的类型不同,会对 ...
- [oracle]索引与索引表管理
(一)索引的概念 索引是一种与表或簇相关的数据库对象,能够为数据的查询提供快捷的存取路径,减少磁盘I/O,提高检索效率. 索引由索引值及记录相应物理地址的ROWID两个部分构成,并按照索引值有序排列, ...
- Object C学习笔记24-关键字总结(转)
学习Object C也有段时间了,学习的过程中涉及到了很多Object C中的关键字,本文总结一下所涉及到的关键字以及基本语法. 1. #import #import <> 从syste ...
- flask中的response
1.Response 在flask中你想向前端返回数据,必须是Response的对象,这里和django必须是HttpResponse 对象一样, 主要将返回数据的几种方式 视图函数中return 字 ...
- 取消Eclipse的自动代码格式化
前段时间在Eclipse里面设置了java文件保存时自动格式化,在java->Code Style->Formatter里设置了自定义的格式化的样式,这样每次保存后都会自动格式化代码,用了 ...
- mysql的密码忘记了,怎么办, 来来来.
尤其是在学习的过程, 也是天天和数据库打交道, 难免会有脑子短路的时候, 比如root密码忘记了, 你说怎么办~~~, 没关系, 往下看 mysql提供了一种跳过用户认证的配置, 参数, 你配置上这个 ...
- python实现简单决策树(信息增益)——基于周志华的西瓜书数据
数据集如下: 色泽 根蒂 敲声 纹理 脐部 触感 好瓜 青绿 蜷缩 浊响 清晰 凹陷 硬滑 是 乌黑 蜷缩 沉闷 清晰 凹陷 硬滑 是 乌黑 蜷缩 浊响 清晰 凹陷 硬滑 是 青绿 蜷缩 沉闷 清晰 ...
- tp5多条件查询
->where('m.user_nickname|w.nickname|c.companyname','like','%'.$search.'%')\
- Python Web开发中,WSGI协议的作用和实现原理详解
首先理解下面三个概念: WSGI:全称是Web Server Gateway Interface,WSGI不是服务器,python模块,框架,API或者任何软件,只是一种规范,描述web server ...