MySQL慢查询优化
MySQL数据库是常见的两个瓶颈是CPU和I/O的瓶颈,CPU在饱和的时候一般发生在大量数据进行比对或聚合时。磁盘I/O瓶颈发生在装入数据远大于内存容量的时候,如果应用分布在网络上,那么查询量相当大的时候那么平瓶颈就会出现在网络上。而出现上诉情况最常见的就是慢查询导致。本文就将对慢查询优化进行简单介绍,一是介绍慢查询的分析语句EXPLAIN,一是通过部分常见的慢查询进行分析讲解,希望读完后能对查询优化有所提高。
EXPLAIN命令用于SQL语句的查询执行计划(QEP)。这条命令的输出结果能够让我们了解MySQL 优化器是如何执行SQL 语句的。这条命令并没有提供任何调整建议,但它能够提供重要的信息帮助我们做出优化决策。
EXPLAIN结果集为id,select_type,table,type,possible_keys,key,key_len
,ref,rows,Extra,本文主要针对select_type,type,ref,Extra进行讲解。
select_type 列提供了各种表示table 列引用的使用方式的类型。最常见的值包括SIMPLE、PRIMARY、DERIVED 和UNION。其他可能的值还有UNION RESULT、DEPENDENT SUBQUERY、DEPENDENT UNION、UNCACHEABLE UNION 以及UNCACHEABLE QUERY。
- SIMPLE:对于不包含子查询和其他复杂语法的简单查询,这是一个常见的类型。(这个也是最理想的)
- PRIMARY:这是为更复杂的查询而创建的首要表(也就是最外层的表)。这个类型通常可以在DERIVED 和UNION 类型混合使用时见到。
- DERIVED:当一个表不是一个物理表时,那么就被叫做DERIVED。一般代表生成了临时表或子查询,建议优化。
- UNION:这是UNION 语句其中的一个SQL 元素。代表使用了UNION,建议优化
type这是最重要的字段之一,显示查询使用了何种类型。从最好到最差的连接类型为system、const、eq_reg、ref、range、index和ALL:
- system、const:可以将查询的变量转为常量. 如id=1; id为 主键或唯一键.
- eq_ref:访问索引,返回某单一行的数据.(通常在联接时出现,查询使用的索引为主键或惟一键)
- ref:访问索引,返回某个值的数据.(可以返回多行) 通常使用=时发生
- range:这个连接类型使用索引返回一个范围中的行,比如使用>或<查找东西,并且该字段上建有索引时发生的情况(注:不一定好于index)
- index:以索引的顺序进行全表扫描,优点是不用排序,缺点是还要全表扫描
- ALL:全表扫描,应该尽量避免
前面简单介绍了EXPLAIN的结果集,下面将通过生产实际的慢查询来进行优化讲解。
案例1:
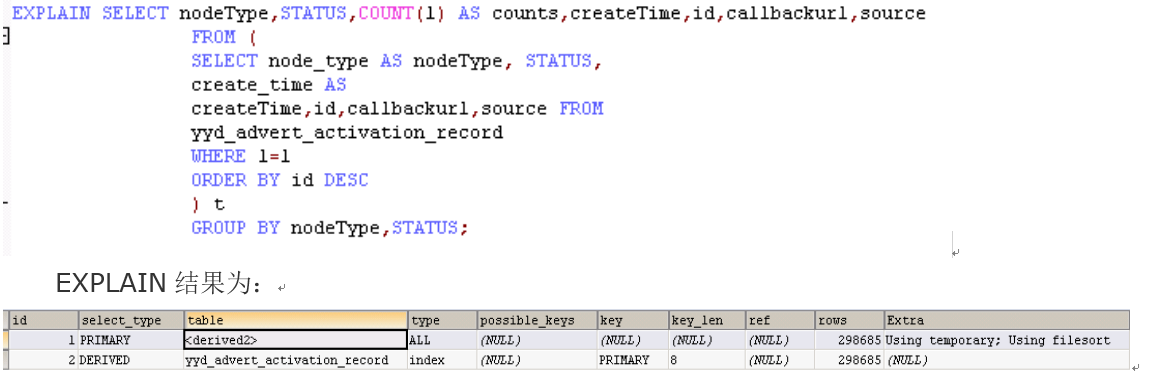
执行顺序通过ID判断,从大到小,首先从select_type为DERIVED,type为index,Extra为NULL可得出该查询对yyd_advert_activation_record进行了全表查询,然后从select_type为PRIMARY,table为<derived2>,type为all,Extra为Using temporary; Using filesort可得出查询使用子查询,生成了临时表并排序。
出现这种语句,首先线上不应该有这种全量统计类的需求,而且并发较高,这个对线上会造成极大的压力。其次该语句的语法上没有优化空间,从数据上看,这个张表从17年1月就没有数据更新,这个查询每次查询数据一致,所以这个查询需求联系开发删除。
案例2:
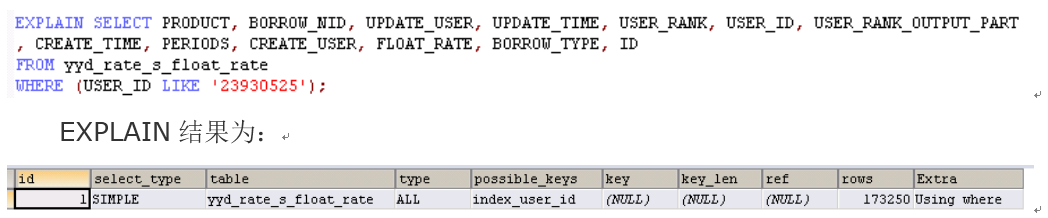
该查询select_type为SIMPLE,possible_key为index_user_id可以看出user_id上有索引,但是type为all,Extra为Using where可以看出这个查询实际是全表扫描USER_ID LIKE '23930525',仔细分析USER_ID的数据类型为BIGINT(20),就可知该查询问题在于使用了like,使得USER_ID转换为varchar类型进行匹配,导致索引无法使用。该查询优化建议为将like改为=
案例3:
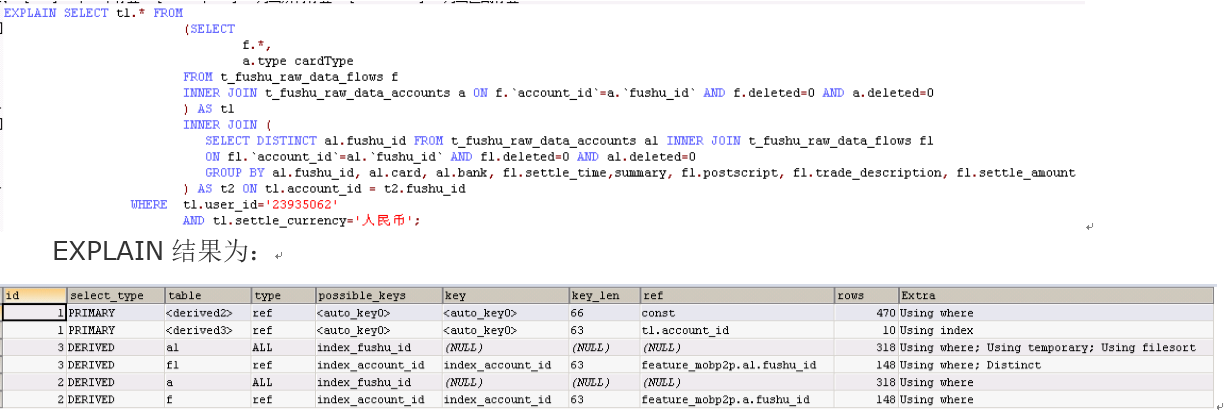
从结果集可以看出这个查询使用了两次子查询,并且在第二个子查询中使用了临时表排序,虽然rows显示查询量不大,但实际查询还是全表扫描。该查询实际执行需要14秒,扫描17W+数据。
仔细分析该查询,两个子查询关联条件和表都一致,第二个子查询只是进行了group by和distinct排序和聚合,但是结果fushu_id又是表的关联条件,所以第二个子查询完全没有必要,直接修改为如下即可。查询优化后只需0.004s。

案例4:
虎哥:
我们这边要在对账库上进行insert select, 但是发现这条语句效率极低,已经执行2小时以上,根本不出结果
INSERT into mt_M_direct_1807_A11 SELECT * from mt_M_direct_1807_A1 a GROUP BY a.`订单id` HAVING COUNT(a.`订单id`) >1; 很慢, 将这条语句拆解成
请DBA帮忙查一下原因
我:
SELECT a.* from mt_M_direct_1807_A1 a GROUP BY a.`订单id` HAVING COUNT(a.`订单id`) >1; 这个也很慢,但是执行
SELECT a.`订单id` from mt_M_direct_1807_A1 a GROUP BY a.`订单id` HAVING COUNT(a.`订单id`) >1 这个就很快,
优化后,insert执行,只需要20S的时间,可以将语句优化成:
insert into mt_M_direct_1807_A11 SELECT b.* from mt_M_direct_1807_A1 b where b.`订单id` FROM (SELECT a.`订单id` from mt_M_direct_1807_A1 a GROUP BY a.`订单id` HAVING COUNT(a.`订单id`) >1);
以上只是比较典型的慢查询优化案例,线上还有很多类型的情况导致慢查询的产生从而影响服务器性能和程序效率,希望今后在开发SQL的时候能够多考虑相关情况,可通过EXPLAIN来进行判断是否查询性能有问题,编写优质代码。
MySQL慢查询优化的更多相关文章
- php mysql 一个查询优化的简单例子
PHP+Mysql是一个最经常使用的黄金搭档,它们俩配合使用,能够发挥出最佳性能,当然,如果配合Apache使用,就更加Perfect了. 因此,需要做好对mysql的查询优化.下面通过一个简单的例子 ...
- WebAPI调用笔记 ASP.NET CORE 学习之自定义异常处理 MySQL数据库查询优化建议 .NET操作XML文件之泛型集合的序列化与反序列化 Asp.Net Core 轻松学-多线程之Task快速上手 Asp.Net Core 轻松学-多线程之Task(补充)
WebAPI调用笔记 前言 即时通信项目中初次调用OA接口遇到了一些问题,因为本人从业后几乎一直做CS端项目,一个简单的WebAPI调用居然浪费了不少时间,特此记录. 接口描述 首先说明一下,基于 ...
- MySQL in查询优化
https://blog.csdn.net/gua___gua/article/details/47401621 MySQL in查询优化<一> 原创 2015年08月10日 17:57: ...
- 查询优化 | MySQL慢查询优化
Explain查询:rows,定位性能瓶颈. 只需要一行数据时,使用LIMIT1. 在搜索字段上建立索引. 使用ENUM而非VARCHAR. 选择区分度高的列作为索引. 采用扩展索引,而不是新建索引 ...
- MySQL 慢查询优化
为什么查询速度会慢 1.慢是指一个查询的响应时间长.一个查询的过程: 客户端发送一条查询给服务器 服务器端先检查查询缓存,如果命中了缓存,则立可返回存储在缓存中的结果.否则进入下一个阶段 服务器端进行 ...
- MySQL SQL查询优化技巧详解
MySQL SQL查询优化技巧详解 本文总结了30个mysql千万级大数据SQL查询优化技巧,特别适合大数据里的MYSQL使用. 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 ...
- 关于mysql的查询优化
由于工作原因,最近甲方客户那边多次反应了他们那边的系统查询速度慢,经过排除之后,发现他们那边的数据库完全没有用到索引,简直坑得一笔,通过慢查询日志分析,为数据表建立了适当的索引之后,查询速度明显的提高 ...
- 《MySQL慢查询优化》之SQL语句及索引优化
1.慢查询优化方式 服务器硬件升级优化 Mysql服务器软件优化 数据库表结构优化 SQL语句及索引优化 本文重点关注于SQL语句及索引优化,关于其他优化方式以及索引原理等,请关注本人<MySQ ...
- MySQL 的查询优化
说起 MySQL 的查询优化,相信大家收藏了一堆奇技淫巧:不能使用 SELECT *.不使用 NULL 字段.合理创建索引.为字段选择合适的数据类型..... 你是否真的理解这些优化技巧?是否理解它背 ...
随机推荐
- django 线上教育平台开发记录
1.环境搭建 2.新建项目 1).首先通过 django-admin 新建一个项目,(例如项目名为mxonline) django-admin startproject mxonline 运行后会出现 ...
- P3097 [USACO13DEC]最优挤奶Optimal Milking
P3097 [USACO13DEC]最优挤奶Optimal Milking 题意简述:给定n个点排成一排,每个点有一个点权,多次改变某个点的点权并将最大点独立集计入答案,输出最终的答案 感谢@zht4 ...
- 数据分析与展示---Matplotlib入门
简介: 一:Matplotlib库的介绍 (一)简单使用 二:区域划分subplot 三:plot函数 四:pyplot的中文显示 (一)方法一:修改rcParams参数 (二)方法二(推荐),在有中 ...
- JS中的getter与setter
一.什么是getter和setter getter 是一种获得属性值的方法,setter是一种设置属性值的方法 getter负责查询值,它不带任何参数,setter则负责设置键值,值是以参数的形式传递 ...
- bzoj千题计划161:bzoj1589: [Usaco2008 Dec]Trick or Treat on the Farm 采集糖果
http://www.lydsy.com/JudgeOnline/problem.php?id=1589 tarjan缩环后拓扑排序上DP #include<cstdio> #includ ...
- C#_连接数据库实现 登录注册界面
//编写登录界面逻辑 using System; using System.Collections.Generic; using System.ComponentModel; using System ...
- 【精选】Ubuntu 14.04 安装Nginx、php5-fpm、ThinkPHP5.0(已经测试上线)
sudo apt-get update 安裝Nginx https://www.vultr.com/docs/setup-nginx-rtmp-on-ubuntu-14-04 安裝完成後,Nginx的 ...
- java抽象类和普通类的区别
1.抽象类不能被实例化. 2.抽象类可以有构造函数,被继承时子类必须继承父类一个构造方法,抽象方法不能被声明为静态. 3.抽象方法只需申明,而无需实现,抽象类中可以允许普通方法有主体 4.含有抽象方法 ...
- .NET 定时器类及使用方法
Timer类实现定时任务 //2秒后开启该线程,然后每隔4s调用一次 System.Threading.Timer timer = new System.Threading.Timer((n) =&g ...
- [转载]WebStorm快捷键操作
http://www.cnblogs.com/yangjinjin/archive/2013/01/30/2883172.html 1. ctrl + shift + n: 打开工程中的文件,目的是打 ...