CFS调度器
一、前言
随着内核版本的演进,其源代码的膨胀速度也在递增,这让Linux的学习曲线变得越来越陡峭了。这对初识内核的同学而言当然不是什么好事情,满腔热情很容易被当头浇灭。我有一个循序渐进的方法,那就是先不要看最新的内核,首先找到一个古老版本的内核(一般都会比较简单),将其吃透,然后一点点的迭代,理解每个版本变更背后的缘由和目的,最终推进到最新内核版本。
本文就是从2.4时代的任务调度器开始,详细描述其实现并慢慢向前递进。当然,为了更好的理解Linux调度器设计和实现,我们在第二章给出了一些通用的概念。之后,我们会在第四章讲述O(1)调度器如何改进并提升调度器性能。真正有划时代意义的是CFS调度器,在2.6.23版本的内核中并入主线。它的设计思想是那么的眩目,即便是目前最新的内核中,完全公平的设计思想仍然没有太大变化,这些我们会在第六章描述。第五章是关于公平调度思想的引入,通过这一章可以了解Con Kolivas的RSDL调度器,它是开启公平调度的先锋,通过这一章的铺垫,我们可以更顺畅的理解CFS。
二、任务调度器概述
为了不引起混乱,我们一开始先澄清几个概念。进程调度器是传统的说法,但是实际上进程是资源管理的单位,线程才是调度的单位,但是线程调度器的说法让我觉得很不舒服,因此最终采用进程调度器或者任务调度器的说法。为了节省字,本文有些地方也直接简称调度器,此外,除非特别说明,本文中的“进程”指的是task struct代表的那个实体,毕竟这是一篇讲调度器的文档。
任务调度器是操作系统一个很重要的部件,它的主要功能就是把系统中的task调度到各个CPU上去执行满足如下的性能需求:
1、对于time-sharing的进程,调度器必须是公平的
2、快速的进程响应时间
3、系统的throughput要高
4、功耗要小
当然,不同的任务有不同的需求,因此我们需要对任务进行分类:一种是普通进程,另外一种是实时进程。对于实时进程,毫无疑问快速响应的需求是最重要的,而对于普通进程,我们需要兼顾前三点的需求。相信你也发现了,这些需求是互相冲突的,对于这些time-sharing的普通进程如何平衡设计呢?这里需要进一步将普通进程细分为交互式进程(interactive processs)和批处理进程(batch process)。交互式进程需要和用户进行交流,因此对调度延迟比较敏感,而批处理进程属于那种在后台默默干活的,因此它更注重throughput的需求。当然,无论如何,分享时间片的普通进程还是需要兼顾公平,不能有人大鱼大肉,有人连汤都喝不上。功耗的需求其实一直以来都没有特别被调度器重视,当然在linux大量在手持设备上应用之后,调度器不得不面对这个问题了,当然限于篇幅,本文就不展开了。
为了达到这些设计目标,调度器必须要考虑某些调度因素,比如说“优先级”、“时间片”等。很多RTOS的调度器都是priority-based的,官大一级压死人,调度器总是选择优先级最高的那个进程执行。而在Linux内核中,优先级就是实时进程调度的主要考虑因素。而对于普通进程,如何细分时间片则是调度器的核心思考点。过大的时间片会严重损伤系统的响应延迟,让用户明显能够感知到延迟,卡顿,从而影响用户体验。较小的时间片虽然有助于减少调度延迟,但是频繁的切换对系统的throughput会造成严重的影响。因为这时候大部分的CPU时间用于进程切换,而忘记了它本来的功能其实就是推动任务的执行。
由于Linux是一个通用操作系统,它的目标是星辰大海,既能运行在嵌入式平台上,又能在服务器领域中获得很好的性能表现,此外在桌面应用场景中,也不能让用户有较差的用户体验。因此,Linux任务调度器的设计是一个极具挑战性的工作,需要在各种有冲突的需求中维持平衡。还好,经过几十年内核黑客孜孜不倦的努力,Linux内核正在向着最终目标迈进。
三、2.4时代的O(n)调度器
网上有很多的linux内核考古队,挖掘非常古老内核的设计和实现。虽然我对进程调度器历史感兴趣,但是我只对“近代史”感兴趣,因此,让我们从2.4时代开始吧,具体的内核版本我选择的是2.4.18版本,该版本的调度器相关软件结构可以参考下面的图片:
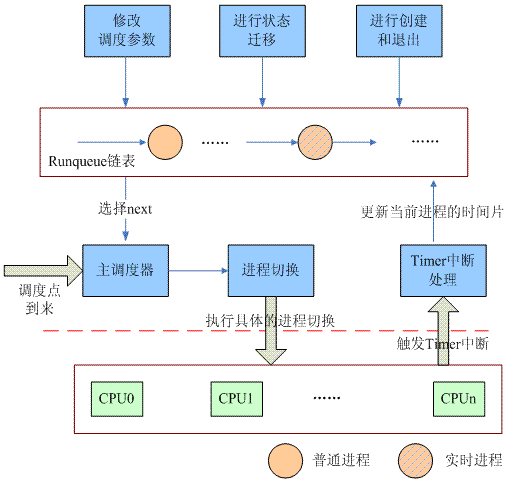
本章所有的描述都是基于上面的软件结构图。
1、进程描述符
|
struct task_struct { volatile long need_resched; long counter; long nice; unsigned long policy; int processor; unsigned long cpus_runnable, cpus_allowed; struct list_head run_list; unsigned long rt_priority; ...... }; |
对于2.4内核,进程切换有两种,一种是当进程由于需要等待某种资源而无法继续执行下去,这时候只能是主动将自己挂起(调用schedule函数),引发一次任务调度过程。另外一种是进程欢快执行,但是由于各种调度事件的发生(例如时间片用完)而被迫让出CPU,被其他进程抢占。这时候的调度并不是立刻发送,而是延迟执行,具体的方法是设定当前进程的need_resched等于1,然后静静的等待最近一个调度点的来临,当调度点到来的时候,内核会调用schedule函数,抢占当前task的执行。
nice成员就是普通进程的静态优先级,通过NICE_TO_TICKS宏可以将一个进程的静态优先级映射成缺省时间片,保存在counter成员中。因此在一次调度周期开始的时候,counter其实就是该进程分配的CPU时间额度(对于睡眠的进程还有些奖励,后面会描述),以tick为单位,并且在每个tick到来的时候减一,直到耗尽其时间片,然后等待下一个调度周期从头再来。
Policy是调度策略,2.4内核主要支持三种调度策略,SCHED_OTHER是普通进程,SCHED_RR和SCHED_FIFO是实时进程。SCHED_RR和SCHED_FIFO的调度策略在rt_priority不同的时候,都是谁的优先级高谁先执行,唯一的不同是相同优先级的处理:SCHED_RR采用时间片轮转,而SCHED_FIFO采用的策略是先到先得,先占有CPU的进程会持续执行,直到退出或者阻塞的时候才会让出CPU。也只有这时候,其他同优先级的实时进程才有机会执行。如果进程是实时进程,那么rt_priority表示该进程的静态优先级。这个成员对普通进程是无效的,可以设定为0。除了上面描述的三种调度策略,policy成员也可以设定SCHED_YIELD的标记,当然它和调度策略无关,主要处理sched_yield系统调用的。
Processor、cpus_runnable和cpus_allowed这三个成员都是和CPU相关。Processor说明了该进程正在执行(或者上次执行)的逻辑CPU号;cpus_allowed是该task允许在那些CPU上执行的掩码;cpus_runnable是为了计算一个指定的进程是否适合调度到指定的CPU上去执行而引入的,如果该进程没有被任何CPU执行,那么所有的bit被设定为1,如果进程正在被某个CPU执行,那么正在执行的CPU bit设定为1,其他设定为0。具体如何使用cpus_runnable可以参考can_schedule函数。
run_list成员是链接入各种链表的节点,下一小节会描述内核如何组织task,这里不再赘述。
2、如何组织task
Linux2.4版本的进程调度器使用了非常简陋的方法来管理可运行状态的进程。调度器模块定义了一个runqueue_head的链表头变量,无论进程是普通进程还是实时进程,只要进程状态变成可运行状态的时候,它会被挂入这个全局runqueue链表中。随着系统的运行,runqueue链表中的进程会不断的插入或者移除。例如当fork进程的时候,新鲜出炉的子进程会挂入这个runqueue。当阻塞或者退出的时候,进程会从这个runqueue中删除。但是无论如何变迁,调度器始终只是关注这个全局runqueue链表中的task,并把最适合的那个任务丢到CPU上去执行。由于整个系统中的所有CPU共享一个runqueue,为了解决同步问题,调度器模块定义了一个自旋锁来保护对这个全局runqueue的并发访问
除了这个runqueue队列,系统还有一个囊括所有task(不管其进程状态为何)的链表,链表头定义为init_task,在一个调度周期结束后,重新为task赋初始时间片值的时候会用到该链表。此外,进入sleep状态的进程分别挂入了不同的等待队列中。当然,由于这些进程链表和调度关系不是那么密切,因此上图中并没有标识出来。
3、动态优先级和静态优先级
所谓静态优先级就是task固有的优先级,不会随着进程的行为而改变。对于实时进程,静态优先级就是rt_priority,而对于普通进程,静态优先级就是(20 – nice)。然而实际上调度器在进行调度的时候,并没有采用静态优先级,而是比对动态优先级来决定谁更有资格获得CPU资源,当然动态优先级的计算是基于静态优先级的。
在计算动态优先级(goodness函数)的时候,我们可以分成两种情况:实时进程和普通进程。对于实时进程而言,动态优先级等于静态优先级加上一个固定的偏移:
|
weight = 1000 + p->rt_priority; |
之所以这么做是为了将实时进程和普通进程区别开,这样的操作也保证了实时进程会完全优先于普通进程的调度。而对于普通进程,动态优先级的计算稍微有些复杂,我们可以摘录部分代码如下:
|
weight = p->counter; if (!weight) goto out; weight += 20 - p->nice; |
对于普通进程,计算动态优先级的策略如下:
(1) 如果该进程的时间片已经耗尽,那么动态优先级是0,这也意味着在本次调度周期中该进程已经再也没有机会获取CPU资源了。
(2) 如果该进程的时间片还有剩余,那么其动态优先级等于该进程剩余的时间片和静态优先级之和。之所以用(20-nice value)表示静态优先级,主要是为了让静态优先级变成单调上升。之所以要考虑剩余时间片是为了奖励睡眠的进程,因为睡眠的进程剩余的时间片较多,因此动态优先级也就会高一些,更容易被调度器调度执行。
调度器是根据动态优先级来进行调度,谁大就先执行谁。我们可以用普通进程作为例子:如果进程静态优先级高(即nice value小),剩余时间片多,那么必定是优先执行。如果静态优先级高,但是所剩时间片无几,那么可能会让位给其他剩余时间片较多,优先级适中的任务。静态优先级低的任务毫无疑问是受到双重打击,因为本来它的缺省时间片就不多,而且优先级也很低。不过,无论静态优先级如何高,只要时间片用完,那么低优先级的任务总是能够有机会执行,不至于饿死。
在计算普通进程的动态优先级的时候,除了考虑进程剩余时间片信息和静态优先级,调度器也会酌情考虑cache和TLB的性能问题。例如,例如A和B进程优先级相同,剩余的时间片都是3个tick,但是A进程上一次就是运行在本CPU上,如果选择A,可能会有更好的cache和TLB的命中率,从而提高性能。在这种情况下,调度器会提升A进程的动态优先级。此外,如果备选进程和当前进程共享同一个地址空间,那么在计算调度指数的时候也会做小小的倾斜。这里有两种可能的情况:一种是备选进程和当前进程在一个线程组中(即是进程中的两个线程),另外一种情况是备选进程是内核线程,这时候,它往往会借用上一个进程地址空间。不论是哪一种情况,在进程切换的时候,由于不需要进行进程地址空间的切换,因此也会有性能的优势。
3、调度时机
对于2.4内核,产生调度的时机主要包括:
(1) 进程主动发起调度。
(2) 在timer中断处理中发现当前进程耗尽其时间片
(3) 进程唤醒的时候(例如唤醒一个RT进程)。更详细的信息可以参考下一个小节。
(4) 父进程在fork的时候,其时间片会均分到父子进程,但是如果只剩下一个tick,这个tick会分配给子进程,而父进程的时间片则被清零,这时候,进程遭遇的场景等同与在timer中断处理中发现当前进程耗尽其时间片。如果父进程在fork的时候,其时间片较大,父子进程的时间片都不为0,这时候的场景类似于唤醒进程。因为这两个场景都是向runqueue中添加了一个task node,从而引发的调度。
(5) 进程切换的时候。当在系统中的某个CPU上发生了进程切换,例如A任务切换到了B任务,这时候是否A任务就失去了执行的机会了呢?当然也未必,因为虽然竞争本CPU失败,但是也许其他的CPU上运行的task动态优先级还不如A呢,抑或正好其他CPU有进入idle状态,正等待着新进程入驻。
(6) 用户进程主动让出CPU的时候
(7) 用户进程修改调度参数的时候
上面的种种场景,除了进程主动调度之外,其他的场景都不是立刻调度schedule函数,而是设定need_resched标记,然后等待调度点的到来。由于2.4内核不是preemptive kernel,因此调度点总是在返回用户空间的时候才会到来。当调度点到来的时候,进程调度就会在该CPU上启动。抢占的场景太多,我们选择进程唤醒的场景来详细描述,其他场景大家自行分析吧。
4、进程唤醒的处理
当进程被唤醒的时候(try_to_wake_up),该task会被加入到那个全局runqueue中,但是是否启动调度还需要进行一系列的判断。为了能清楚的描述这个场景,我们定义执行唤醒的那个进程是waker,而被唤醒的进程是wakee。Wakeup有两种,一种是sync wakeup,另外一种是non-sync wakeup。所谓sync wakeup就是waker在唤醒wakee的时候就已经知道自己很快就进入sleep状态,而在调用try_to_wake_up的时候最好不要进行抢占,因为waker很快就主动发起调度了。此外,一般而言,waker和wakee会有一定的亲和性(例如它们通过share memory进行通信),在SMP场景下,waker和wakee调度在一个CPU上执行的时候往往可以获取较佳的性能。而如果在try_to_wake_up的时候就进行调度,这时候wakee往往会调度到系统中其他空闲的CPU上去。这时候,通过sync wakeup,我们往往可以避免不必要的CPU bouncing。对于non-sync wakeup而言,waker和wakee没有上面描述的同步关系,waker在唤醒wakee之后,它们之间是独立运作,因此在唤醒的时候就可以尝试去触发一次调度。
当然,也不是说sync wakeup就一定不调度,假设waker在CPU A上唤醒wakee,而根据wakee进程的cpus_allowed成员发现它根本不能在CPU A上调度执行,那么管他sync不sync,这时候都需要去尝试调度(调用reschedule_idle函数),反正waker和wakee命中注定是天各一方(在不同的CPU上执行)。
我们首先看看UP上的情况。这时候waker和wakee在同一个CPU上运行(当然系统中也只有一个CPU,哈哈),这时候谁能抢占CPU资源完全取决于waker和wakee的动态优先级,如果wakee的动态优先级大于waker,那么就标记waker的need_resched标志,并在调度点到来的时候调用schedule函数进行调度。
SMP情况下,由于系统的CPU资源比较多,waker和wakee没有必要争个你死我活,wakee其实也可以选择去其他CPU执行,相关的算法大致如下:
(1) 优先调度wakee去系统其他空闲的CPU上执行,如果wakee上次运行的CPU恰好处于idle状态的时候,可以考虑优先将wakee调度到那个CPU上执行。如果不是,那么需要扫描系统中所有的CPU找到最合适的idle CPU。所谓最合适就是指最近才进入idle的那个CPU。
(2) 如果所有的CPU都是busy的,那么需要遍历所有CPU上当前运行的task,比对它们的动态优先级,找到动态优先级最低的那个CPU。
(3) 如果动态优先级最低的那个task的优先级仍然高于wakee,那么没有必要调度,runqueue中的wakee需要耐心等待下一次机会。如果wakee的动态优先级高于找到的那个动态优先级最低的task,那么标记其need_resched标志。如果不是抢占waker,那么我们还需要发送IPI去触发该CPU的调度。
当然,这是2.4内核调度器的设计选择,实际上这样的操作值得商榷。限于篇幅,本文就不再展开叙述,如果有机会写负载均衡的文章就可以好好的把这些关系梳理一下。
5、主调度器算法
主调度器(schedule函数)核心代码如下:
|
list_for_each(tmp, &runqueue_head) { p = list_entry(tmp, struct task_struct, run_list); int weight = goodness(p, this_cpu, prev->active_mm); if (weight > c) c = weight, next = p; } |
list_for_each用来遍历runqueue_head链表上的所有的进程,临时变量p就是本次需要检查的进程描述符。如何判断哪一个进程是最适合调度执行的进程呢?我们需要计算进程的动态优先级(对应上面程序中的变量weight),它是通过goodness函数实现的。动态优先级最大的那个进程就是当前最适合调度到CPU执行的进程。一旦选中,调度器会启动进程切换,运行该进程以替换之前的那个进程。
根据代码可知:即便链表第一个节点就是最合的下一个要调度执行的进程,调度器算法仍然会遍历全局runqueue链表,一一比对。由此我们可以判断2.4内核中的调度器的算法复杂度是O(n)。一旦选中了下一个要执行的进程,进程切换模块就会在该CPU上执行具体的进程切换。
对于SCHED_RR的实时进程,优先级相等的情况下还需要有一个时间片轮转的概念。因此,在遍历链表之前我们就先处理该进程的时间片处理:
|
if (unlikely(prev->policy == SCHED_RR)) if (!prev->counter) { prev->counter = NICE_TO_TICKS(prev->nice); move_last_runqueue(prev); } |
如果时间片(对应上面程序中的prev->counter)用完,SCHED_RR的实时进程会被移到runqueue链表的尾部。通过这样的处理,优先级相等的SCHED_RR在遍历runqueue链表的时候会命中链表中的第一个task,从而实现时间片轮转的概念。这里有一个比较奇葩的事情就是SCHED_RR的时间片是根据其nice value设定,而实际上nice value应该只适用于普通进程的。
6、时间片处理
普通进程的时间片处理思路是这样:
(1)每个进程根据其静态优先级可以固定分配一个缺省的时间片,静态优先级越大,分配的时间片就越大。
(2)一旦Runqueue中的进程被调度执行,那么其时间片就会在tick到来的时候递减,如果进程时间片耗尽,那么该进程将失去分配CPU资源的资格。
(3)Runqueue中的进程的时间片全部被用完之后,我们称一个调度周期结束,这时候需要为runqueue中的进程重新设定其缺省时间片,这样,一个新的调度周期又开始了。
如何确定每个进程的缺省时间片呢?由于时间片是按照tick来分配的,那么最小的时间片也是1个tick,也就是说最低优先级(nice value等于19)的缺省时间片就是1个tick。对于中间优先级(nice value等于0)的时间片,我们将其设定为50ms左右,具体的算法大家可以自行参考NICE_TO_TICKS的代码实现。不得不承认这个根据nice value计算缺省时间片的过程还是很丑陋的,不同的HZ设定,计算得到的缺省时间片是不一样的。也就是说系统的调度行为和HZ的设定有关,这叫有代码洁癖的同学如何能够接受。不论如何,我们还是给出实际的例子来感受一下:
|
-20 |
-10 |
0 |
10 |
19 |
|
|
HZ=100 |
11个tick 110ms |
8个tick 80ms |
6个tick 60ms |
3个tick 30ms |
1个tick 10ms |
|
HZ=1000 |
81个tick 81ms |
61个tick 61ms |
41个tick 41ms |
21tick 21ms |
3个tick 3ms |
当runqueue中所有进程的时间片耗尽之后,这时候就会开启一次重新加载进程缺省时间片的过程,代码如下(在schedule函数中):
|
if (unlikely(!c)) { struct task_struct *p; for_each_task(p) p->counter = (p->counter >> 1) + NICE_TO_TICKS(p->nice); goto repeat_schedule; } |
这里c就是遍历runqueue链表之后找到的最大动态优先级,如果它等于0则说明:首先,系统中没有处于可运行状态的实时进程,其次,所有的处于可运行状态的普通进程都已经消耗完了它们的时间片,这时候是需要重新“充值”了。for_each_task这个宏是遍历所有系统中的进程描述符,不论是否是可运行状态的。对于挂入runqueue链表中的普通进程而言,其当前的时间片p->counter已经是等于0了,因此它获得的新的时间片就是NICE_TO_TICKS(p->nice),也就是根据nice value计算得到的缺省时间片。对于挂入等待队列中处于睡眠状态的进程而言,其时间片p->counter还有剩余,当然会累积到进程时间片配额中,这也算是对睡眠进程的一种奖励吧。为了防止经常睡眠的交互式进程获得过于庞大的时间片,这里并不是累积其全部存留时间片,而是打了个对折(p->counter >> 1)。
新的一个周期开始了,当前进程已经在CPU上奔跑了,消耗其时间片的代码位于timer中断处理中,如下:
|
if (--p->counter <= 0) { p->counter = 0; p->need_resched = 1; } |
每一个tick到来的时候,进程的时间片都会减一,当时间片是0的时候,调度器剥夺其执行的权力,从而从而引发一次调度,选择其他时间片不是0的进程运行,直到runqueue中的所有进程时间片耗尽,又会重新赋值,开始一个新的周期。调度器就这样周而复始,推动整个系统的运作。
四、2.6时代的O(1)调度器
1、Why O(1)调度器
如果简单是判断调度器好坏的唯一标准,那么无疑O(n)调度器是最优秀的调度器。虽然它非常的简单,容易理解,但是存在严重的扩展性问题和性能问题。下面让我们一起来控诉O(n)调度器的“七宗罪”,同时这也是Ingo Molnar发起O(1)调度器项目背后的原因。
(1)算法复杂度问题
让人最不爽的就是对runqueue队列的遍历,当系统中runnable进程不多的时候,遍历链表的开销还可以接受,但是随着系统中runnable状态的进程数目增多,那么调度器select next的运算量也随之呈线性的增长,这也是我们为什么叫它O(n)调度器的原因。
此外,调度周期结束后,调度器会为所有进程的时间片进行“充值“的动作。在大型系统中,同时存在的进程(包括睡眠的进程)可能会有数千个,为每一个进程计算其时间片的过程太耗费时间。
(2)SMP扩展性问题
2.4内核的O(n)调度器有非常差的SMP扩展性。我们知道,O(n)调度器是通过一个链表来管理系统中的所有的等待调度的进程,访问这个runqueue链表的场景很多:进行调度的时候,我们需要遍历runqueue,找到合适的next task;wakeup或者block进程的时候,我们需要从runqueue中增加节点或者删除节点……在访问runqueue这个链表的时候,我们都会首先会上自旋锁,同时disable本地CPU中断,然后访问链表执行相应的动作,完成之后释放锁,开中断。通过这样的内核同步机制,我们可以保证来自多个CPU对runqueue链表的并发访问。当系统中的CPU数目比较少的时候,自旋锁的开销还可以接受,但是在大型系统中,CPU数目非常多,这时候runqueue spin lock就成为系统的性能瓶颈。
(3)CPU空转问题
每当runqueue链表中的所有进程耗尽了其时间片,这时候就需要启动对系统中所有进程时间片重新计算的过程。这个计算过程异常丑陋,需要遍历系统中的所有进程(注意:是所有进程!),为进程描述符的counter成员赋一个新值。而这个操作足以把该CPU上的L1 cache全部干掉。当完成了时间片重新计算过程后,你几乎面对的就是一个全空的L1 cache(当然不是全空,主要是cache中的数据没有任何意义,这时候L1 cache的命中率急剧下降)。除此之外,时间片重新计算过程会带来CPU资源的浪费,我们用下面的图片来描述:
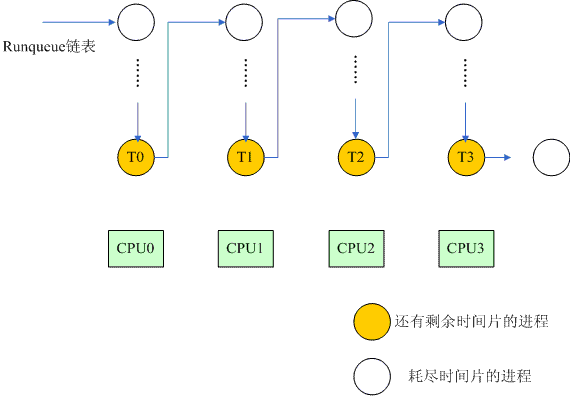
在runqueue队列中的全部进程时间片被耗尽之前,系统总会处于这样一个状态:最后的一组尚存时间片的进程分分别调度到各个CPU上去。我们以4个CPU为例,T0~T3分别运行在CPU0~CPU3上。随着系统的运行,CPU2上的T2首先耗尽了其时间片,但是这时候,其实CPU2上也是无法进行调度的,因为遍历runqueue链表,找不到适合的进程调度运行,因此它只能是处于idle状态。也许随后T0和T3也耗尽其时间片,从而导致CPU0和CPU3也进入了idle状态。现在只剩下最后一个进程T1仍然在CPU1上运行,而其他系统中的处理器处于idle状态,白白的浪费资源。唯一能改变这个状态的是T1耗尽其时间片,从而启动一个重新计算时间片的过程,这时候,正常的调度就可以恢复了。随着系统中CPU数目的加大,资源浪费会越来越严重。
(4)task bouncing issue
一般而言,一个进程最好是从一而终,假如它运行在系统中的某个CPU中,那么在其处于可运行状态的过程中,最好是一直保持在该CPU上运行。不过在O(n)调度器下,很多人都反映有进程在CPU之间跳来跳去的现象。其根本的原因也是和时间片算法相关。在一个新的周期开后,runqueue中的进程时间片都是满满的,在各个CPU上调度进程的时候,它可选择的比较多,再加上调度器倾向于调度上次运行在本CPU的进程,因此调度器有很大的机会把上次运行的进程调度到同一个处理器上。但是随着runqueue中的进程一个个的耗尽其时间片,cpu可选择的余地在不断的压缩,从而导致进程执行在一个和它亲和性不大的处理器(例如上次该进程运行在CPU0,但是这个将其调度到CPU1执行,但是实际上该进程和CPU0的亲和性更大些)。
(5)RT进程调度性能问题
实时调度的性能一般。通过上一节的介绍,我们知道,实时进程和普通进程挂在一个链表中。当调度实时进程的时候,我们需要遍历整个runqueue列表,扫描并计算所有进程的调度指数,从而选择出心仪的那个实时进程。按理说实时进程和普通进程位于不同的调度空间,两不相干,但是现在调度实时进程还需要扫描计算普通进程,这样糟糕的算法让那些关注实时性的工程师不能忍受。
当然,上面的这些还不是关键,最重要的是整个linux内核不是抢占式内核,在整个内核态都不能被抢占。对于一些比较耗时(可能几个毫秒)的系统调用或者中断处理,必须返回用户空间才启动调度是不可接受的。除了内核抢占性之外,优先级翻转问题也需要引起调度器的重视,否则即便一个rt进程变成runnable状态了,但是也只能眼睁睁的看着比它优先级低的进程运行,直到该rt进程等待的资源被释放。
(6)交互式普通进程的调度延迟问题
O(n)并不区分交互式进程和批处理进程,它只是奖励经常睡眠的那些进程。但是有些批处理进程也属于IO-bound进程,例如数据库服务进程,它本身是一个后台进程,对调度延迟不敏感,但是由于它需要和磁盘打交道,因此也会经常阻塞在disk IO上。对这样的后台进程进行动态优先级的升高其实是没有意义的,会增大其他交互式进程的调度延迟。另外一方面,用户交互式进程也可能是CPU-bound的,而这时候调度器不会正确的了解到该进程的调度需求并对其进行补偿。
(7)时间片粒度问题。
用户感知到的响应延迟是和系统负载相关,我们可以用runnable进程数目来粗略的描述系统的负载。当系统负载高的时候,runqueue中的进程数目会比较多,一次调度周期的时间就会比较长,例如在HZ=100的情况下,runqueue上有5个runnable进程,nice value是0,每个时间片配额是60ms,那么一个调度周期就是300ms。随着runnable进程增大,调度周期也变大。当一个进程耗尽其时间片之后,只能等待下一个调度周期到来。因此随着调度周期变大,系统响应也会变的较差。
虽然O(n)调度器存在不少的issue,但是社区的人还是基本认可这套算法的,因此在设计新的调度器的时候并不是完全推翻O(n)调度器的设计,而是针对O(n)调度器的问题进行改进。在本章中我们选择2.6.11版本的内核来描述O(1)调度器如何运作。鉴于O(1)调度器和O(n)调度器没有本质区别,因此我们只是描述它们之间不同的地方。
2、O(1)调度器的软件功能划分
下图是一个O(1)调度器的软件框架:
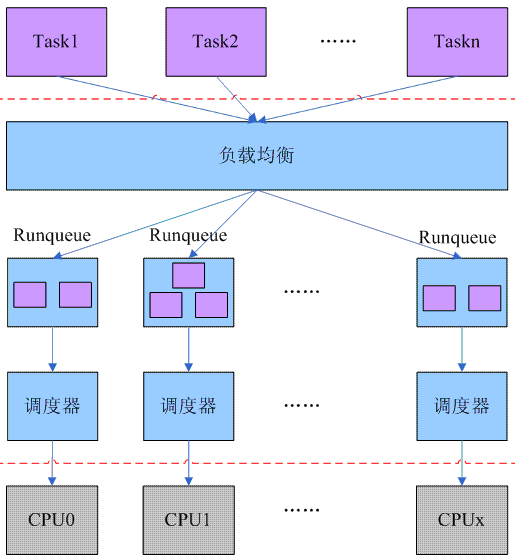
O(n)调度器中只有一个全局的runqueue,严重影响了扩展性,因此在O(1)调度器中引入了per-CPU runqueue的概念。系统中所有的可运行状态的进程首先经过负载均衡模块挂入各个CPU的runqueue,然后由主调度器和tick调度器驱动该CPU上的调度行为。由于篇幅的原因,我们在本文中不讲解负载均衡模块,把重点放在单个CPU上的任务调度算法。
由于引入了per-CPU runqueue,O(1)调度器删除了全局runqueue的spin lock,而是把这个spin lock放入到per-CPU runqueue数据结构中(rq->lock),通过把一个大锁细分成小锁,可以大大降低调度延迟,提升系统响应时间。这种方法在内核中经常使用,是一个比较通用的性能优化方法。
通过上面的软件结构划分可以解决O(n)调度的SMP扩展性问题和CPU空转问题。此外,好的复杂均衡算法也可以解决O(n)调度器的task bouncing 问题。
3、O(1)调度器的runqueue结构
O(1)调度器的基本优化思路就是把原来runqueue上的单链表变成多个链表,即每一个优先级的进程被挂入不同链表中。相关的软件结构可以参考下面的图片:
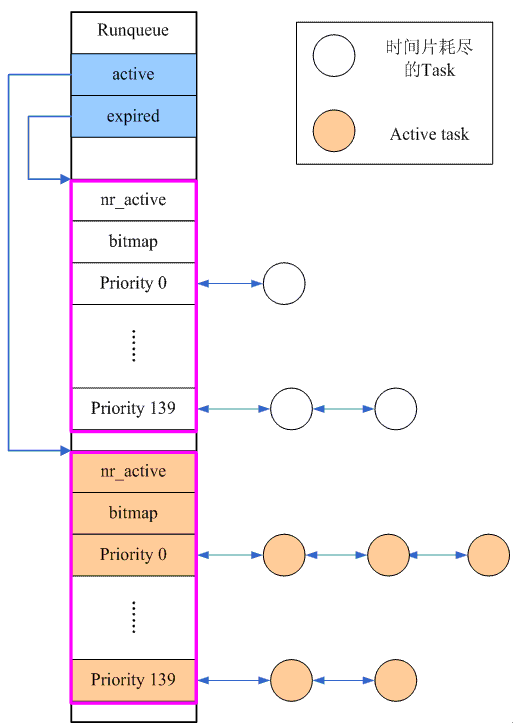
在调度器中,runqueue是一个很重要的数据结构,它最重要的作用是管理那些处于可运行状态的进程。O(1)调度器引入了优先级队列的概念来管理task,具体由struct prio_array抽象:
|
struct prio_array { unsigned int nr_active; unsigned long bitmap[BITMAP_SIZE]; struct list_head queue[MAX_PRIO]; }; |
由于支持140个优先级,因此queue成员中有140个分别表示各个优先级的链表头,不同优先级的进程挂入不同的链表中。bitmap 是表示各个优先级进程链表是空还是非空。nr_active表示这个队列中有多少个task。在这些队列中,100~139是普通进程的优先级,其他的是实时进程的优先级。因此,在O(1)调度器中,RT进程和普通进程被区分开了,普通进程根本不会影响RT进程的调度。
Runqueue中有两个优先级队列(struct prio_array)分别用来管理active(即时间片还有剩余)和expired(时间片耗尽)的进程。Runqueue中有两个优先级队列的指针,分别指向这两个优先级队列。随着系统的运行,active队列的task一个个的耗尽其时间片,挂入到expired队列。当active队列的task为空的时候,切换active和expired队列,开始一轮新的调度过程。
虽然在O(1)调度器中task组织的形式发生了变化,但是其核心思想仍然和O(n)调度器一致的,都是把CPU资源分成一个个的时间片,分配给每一个runnable的进程。进程用完其额度后被抢占,等待下一个调度周期的到来。
4、核心调度算法
主调度器(就是schedule函数)的主要功能是从该CPU的runqueue找到一个最合适的进程调度执行。其基本的思路就是从active优先级队列中寻找,代码如下:
|
idx = sched_find_first_bit(array->bitmap); queue = array->queue + idx; next = list_entry(queue->next, task_t, run_list); |
首先在当前active优先级队列的bitmap寻找第一个非空的进程链表,然后从该链表中找到的第一个节点就是最适合下一个调度执行的进程。由于没有遍历整个链表的操作,因此这个调度器的算法复杂度是一个常量,从而解决了O(n)算法复杂度的issue。
如果当前active优先级队列中“空无一人”(nr_active等于0),那么这时候就需要切换active和expired优先级队列了:
|
if (unlikely(!array->nr_active)) { rq->active = rq->expired; rq->expired = array; array = rq->active; } |
切换很快,并没有一个遍历所有进程重新赋default时间片的操作(大大缩减了runqueue临界区的size)。这些都避免了O(n)调度器带来的种种问题,从而提高了调度器的性能。
5、静态优先级和动态优先级
在前面的小节中,我们有意的忽略了优先级队列中“优先级”的具体含义,现在是需要澄清的时候了。其实优先级队列中“优先级”指的是动态优先级,从这个角度看,O(1)和O(n)调度器的调度算法又统一了,都是根据动态优先级进行调度。
O(1)的静态优先级的概念和O(n)是类似的,对于实时进程保存在进程描述符的rt_priority成员中,取值范围是1(优先级最低)~99(优先级最高)。对于普通进程,静态优先级则保存在static_prio成员中,取值范围是100(优先级最高)~139(优先级最低),分别对应nice value的-20 ~ 19。
了解了静态优先级之后,我们一起来看看动态优先级(保存在进程描述符的prio成员中)。鉴于在实际调度的时候使用的是动态优先级,我们必须要保证它是单调的(静态优先级未能保持单调,rt的99和普通进程的100都是静态优先级的最高点,也就是说在静态优先级数轴上,rt段是单调上升,而在普通进程段是单调下降的)。为了解决这个问题,在计算实时进程动态优先级的时候进行了一个简单的映射:
|
p->prio = MAX_USER_RT_PRIO-1 - p->rt_priority; |
通过这样的转换,rt的动态优先级在数轴上也是单调下降的了。普通进程的动态优先级计算没有那么简单,除了静态优先级,还需要考虑进程的平均睡眠时间(保存在进程描述符的sleep_avg成员中),并根据该值对进程进行奖惩。具体代码可以参考effective_prio函数,这里不再详述,最终普通进程的动态优先级是100(优先级最高)~139(优先级最低),和静态优先级的取值范围是一致的。
在本小节的最后,我们一起来对比普通进程在O(1)和O(n)调度器的动态优先级算法。这个两个调度器的基本思路是一致的:考虑静态优先级,辅以对该进程的“用户交互指数”的评估,用户交互指数高的,调升其动态优先级,反之则降低。不过在评估用户交互指数上,O(1)显然做的更好。O(n)调度器仅仅考虑了睡眠进程的剩余时间片,而O(1)的“平均睡眠时间”算法显然考虑更多的因素:在cpu上的执行时间、在runqueue中的等待时间、睡眠时间、睡眠时候的进程状态(是否可被信号打断),什么上下文唤醒(中断上下文唤醒还是在进程上下文中唤醒)……因此O(1)调度器更好的判断了进程是属于interactive process还是batch process,从而精准的为interactive process打call。
6、时间片处理
缺省时间片的计算是通过task_timeslice完成的,在O(1)调度器中,缺省时间片已经和HZ无关了,无论如何设置HZ,静态优先级为[ -20 ... 0 ... 19 ]的普通进程其缺省时间片为[800ms ... 100ms ... 5ms]。
在tick到来的时候,当前task的时间片会递减(--p->time_slice),当时间片等于0的时候,会将该task从active优先级列表中摘下,设定resched标记,并且重置时间片,代码如下:
|
dequeue_task(p, rq->active); set_tsk_need_resched(p); p->time_slice = task_timeslice(p); |
task_timeslice函数就是用来计算进程时间片的配额的。对于O(1)调度器,时间片的重新赋值是分散处理的,在各个task耗尽其时间片之后立刻进行的。这样的改动也修正了O(n)调度器一次性的遍历系统所有进程,重新为时间片赋值的过程。
6、识别用户交互式进程
一般而言,时间片耗尽之后,该task会被挂入到expired优先级队列,这时候如果想要被调度只能等到下次active和expired切换了。不过,有些特殊的场景需要特殊处理:
|
if (!TASK_INTERACTIVE(p) || EXPIRED_STARVING(rq)) { enqueue_task(p, rq->expired); if (p->static_prio < rq->best_expired_prio) rq->best_expired_prio = p->static_prio; } else enqueue_task(p, rq->active); |
这里TASK_INTERACTIVE是用来判断一个进程是否是一个用户交互式进程(也是和平均睡眠时间相关,由此可见,平均睡眠时间不仅用于计算动态优先级,还用来决定一个进程是否回插入active队列),如果是的话,说明该进程对用户响应比较敏感,这时候不能粗暴的挂入expired队列,而是重新挂入active队列,继续有机会获取调度执行的机会。由此可见,O(1)调度器真是对用户交互式进程非常的照顾,一旦被判断是用户交互型进程,那么它将获取连续执行的机会。当然,调度器也不能太过分,如果用户交互型进程持续占用CPU,那么在expired队列中苦苦等待进程怎么办?这时候就要看看expired队列中的进程的饥饿状态了,这也就是EXPIRED_STARVING这个宏定义的功能。如果expired队列中的进程等待了太长的时间,那么说明调度器已经出现严重不公平的现象,因此这时候即便是判断当前耗尽时间片的进程是用户交互型进程,也把它挂入expired队列,尽快的完成本次调度周期,让active和expired发生切换。
O(1)调度器使用非常复杂的算法来判断进程的用户交互指数以及进程是否是交互式进程,hardcode了很多的不知其所以然的常数,估计也是通过各种大量的实验场景总结出来的。这部分的设计概念我是在是没有勇气去探索,因此这里就略过了。但是无论如何,它总是比仅仅考虑睡眠时间的O(n)调度器性能要好。
7、抢占式内核
2.4时代,大部分的Linux应用都集中在服务器领域,因此非抢占式内核的设计选择也无可厚非。不过随着Linux在桌面和嵌入式上的渗透,系统响应慢慢的称为用户投诉的主要方面,因此,在2.5的开发过程中,Linux引入了抢占式内核的概念(CONFIG_PREEMPT),如果没有配置该选项,那么一切和2.4内核保持一致,如果配置了该选项,那么不需要在返回用户空间的时候才苦苦等到调度点,大部分的内核执行路径都是可以被抢占的。同样的,限于篇幅,这里不再展开描述。
五、公平调度思想的引入
1、传统调度器时间片悖论
在O(n)和O(1)调度器中,时间片是固定分配的,静态优先级高的进程获取更大的time slice。例如nice value等于20的进程获取的default timeslice是5ms,而nice value等于0的进程获取的是100ms。直观上,这样的策略没有毛病(高优先级的获取更多的执行时间),但是,这样的设定潜台词就是:高优先级的进程会获得更多的连续执行的机会,这是CPU-bound进程期望的,但是实际上,CPU-bound进程往往在后台执行,其优先级都是比较低的。
因此,假设我们调度策略就是根据进程静态优先级确定一个固定大小的时间片,这时候我们在如何分配时间片上会遇到两难的状况:想要给用户交互型进程设定高优先级,以便它能有更好的用户体验,但是分配一个大的时间片是毫无意义的,因为这种进程多半是处于阻塞态,等待用户的输入。而后台进程的优先级一般不高,但是根据其优先级分配一个较小的时间片往往会影响其性能,这种类型的进程最好是趁着cache hot的时候狂奔。
怎么办?或者传统调度器固定分配时间片这个设计概念就是错误的。
2、传统调度器的卡顿问题
在Linux 2.5版本的开发过程中,Ingo Molnar设计的O(1)调度器替换掉了原始的、简陋的O(n)调度器,从而解决了扩展性很差,性能不佳的问题。在大部分的场景中,该调度器都获得了满意的性能,在商用的Linux 2.4发行版中,O(1)调度器被很多厂商反向移植到Linux 2.4中,由此可见O(1)调度器性能还是优异的。
然而O(1)并非完美,在实际的使用过程中,还是有不少的桌面用户在抱怨用户交互性比较差。当一个相当消耗CPU资源的进程启动的时候,现存的那些用户交互程序(例如你在通过浏览器查看网页)都可以感觉到明显的延迟。针对这些issue,很多天才工程师试图通过对用户交互指数算法的的修改来解决问题,这里面就包括公平调度思想的提出者Con Kolivas。不过无论如何调整算法,总是有点拆东墙补西墙的感觉,一个场景的issue修复了,另外一个场景又冒出来交互性不好的issue,刁钻的客户总是能够在边边角角的场景中找到让用户感觉到的响应延迟。
在反反复复修复用户卡顿issue的过程中,工程师最容易烦躁,而往往这时候最需要冷静的思考。Con Kolivas仔细的检视了调度器代码,他发现出问题的是评估进程用户交互指数的代码。为何调度器要根据进程的行为猜测其对交互性的需求?这根本是一项不可能完成的任务,因为你总是不会100%全部猜中,就好像你去猜测你喜欢的女孩子的心事一样,你细心的收集了关于这个女孩子的性格特点,业余爱好,做事风格,逻辑思维水平,星座……甚至生理周期,并期望着能总是正确的猜中其心中所想,坦率的讲这是不可能的。在进程调度这件事情上为何不能根据实实在在确定的东西来调度呢?一个进程的静态优先级已经完成的说明了其调度需求了,这就足够了,不需要猜测进程对交互性的需求,只要维持公平就OK了,而所谓的公平就是进程获取和其静态优先级匹配的CPU执行时间。在这样的思想指导下,Con Kolivas提出了RSDL(Rotating Staircase Deadline)调度器。
3、RSDL调度器
RSDL调度器仍然沿用了O(1)调度的数据结构和软件结构,当然删除了那些令人毛骨悚然的评估进程交互指数的代码。我们这一小节不可能详细描述RSDL算法,不过只要讲清楚Rotating、Staircase和Deadline这三个基本概念,大家就应该对RSDL有基本的了解了。
首先看Staircase概念,它更详细表述应该是priority staircase,即在进程调度过程中,其优先级会象下楼梯那样一点点的降低。在传统的调度概念中,一个进程有一个和其静态优先级相匹配的时间片,在RSDL中,同样也存在这样的时间片,但是时间片是散布在很多优先级中。例如如果一个进程的优先级是120,那么整个时间片散布在120~139的优先级中,在一个调度周期,进程开始是挂入120的优先级队列,并在其上运行6ms(这是一个可调参数,我们假设每个优先级的时间配额是6ms),一旦在120级别的时间配额使用完毕之后,该进程会转入121的队列中(优先级降低一个level),发生一次Rotating,更准确的说是Priority minor rotating。之后,该进程沿阶而下,直到139的优先级,在这个优先级上如果耗尽了6ms的时间片,这时候,该进程所有的时间片就都耗尽了,就会被挂入到expired队列中去等待下一个调度周期。这次rotating被称为major rotating。当然,这时候该进程会挂入其静态优先级对应的expired队列,即一切又回到了调度的起点。
Deadline是指在RSDL算法中,任何一个进程可以准确的预估其调度延迟。一个简单的例子,假设runqueue中有两个task,静态优先级分别是130的A进程和139的B进程。对于A进程,只有在进程沿着优先级楼梯从130走到139的时候,B进程才有机会执行,其调度延迟是9 x 6ms = 54ms。
多么简洁的算法,只需要维持公平,没有对进程睡眠/运行时间的统计,没有对用户交互指数的计算,没有那些奇奇怪怪的常数……调度,就是这么简单。
六、CFS调度器
Con Kolivas的RSDL调度器始终没有能够进入kernel mainline,取而代之的是同样基于公平调度思想的CFS调度器,在CFS调度器并入主线的同时,仍然提供了模块化的设计,为RSDL或者其他的调度器可以进入内核提供了方便。然而Con Kolivas带着对内核开发模式的不满永远的退出了社区,正所谓有人的地方就有江湖,其中的是非留给后人评说吧。
CFS的设计理念就是一句话:在真实的硬件上实现理想的、精准、完全公平的多任务调度。当然,这样的调度器不存在,在实际设计和实现的时候还是需要做一些折衷。其实CFS调度器的所有的设计思想在上一章都已经非常明晰,本章我们唯一需要描述的是Ingo Molnar如何把完全公平调度的理想照进现实。
1、模块化思想的引入
从2.6.23内核开始,调度器采用了模块化设计的思想,从而把进程调度的软件分成了两个层次,一个是core scheduler layer,另外一个是specific scheduler layer:

从功能层面上看,进程调度仍然分成两个部分,第一个部分是通过负载均衡模块将各个runnable task根据负载情况平均分配到各个CPU runqueue上去。第二部分的功能是在各个CPU的Main scheduler和Tick scheduler的驱动下进行单个CPU上的调度。调度器处理的task各不相同,有RT task,有normal task,有Deal line task,但是无论哪一种task,它们都有共同的逻辑,这部分被抽象成Core scheduler layer,同时各种特定类型的调度器定义自己的sched_class,并以链表的形式加入到系统中。这样的模块化设计可以方便用户根据自己的场景定义specific scheduler,而不需要改动Core scheduler layer的逻辑。
2、关于公平
和RSDL调度器一样,CFS调度器追求的公平是CPU资源分配的公平,即CPU的运算资源被精准的平均分配给在其上运行的task。例如:如果有2个静态优先级一样的task运行在某一个CPU上,那么每一个task都消耗50%的CPU计算资源。如果静态优先级不一样,那么,CPU资源是根据其静态优先级来具体分配。具体如何根据优先级来分配CPU资源呢?这里就需要引入一个load weight的概念。
在CFS中,我们是通过一个常量数组(sched_prio_to_weight)可以把进程静态优先级映射成进程权重,而所谓的权重就是进程应该占有cpu资源的比重。例如:系统中有3个runnable thread A、B和C,权重分别是a、b、c,那么A thread应该分配到的CPU资源是a/(a+b+c)。因此CFS调度器的公平就是保证所有的可运行状态的进程按照权重分配其CPU资源。
3、时间粒度
CPU资源分配是一个抽象的概念,最终在实现调度器的时候,我们需要把它具体化。一个最简单的方法就是把CPU资源的分配变成CPU时间片的分配。看到“时间片”这个术语,你可能本能的觉得CFS和O(1)也没有什么不同,不都是分配时间片吗?其实不然,Linux内核的CFS调度器已经摒弃了传统的固定时间片的概念了。O(1)调度器会为每一个进程分配一个缺省的时间片,当进程使用完自己的时间片之后就会被挂入expire队列,当系统中的所有进程都耗光了自己的时间片,那么一切从来,所有的进程又恢复了自己的时间片,进入active队列。CFS调度器没有传统的静态时间片的概念,她的时间片是动态的,和当前CPU的可运行状态的进程以及它们的优先级相关,因此CFS调度器中,时间片是动态变化的。
对于理想的完全公平调度算法,无论观察的时间段多么短,CPU的时间片都是公平分配的。以100ms的粒度来观察,那么两个可运行状态的进程A和B(静态优先级一样)各分50ms。当然,也不是一定是A执行50ms,切换到B,然后再执行50ms,在观察过程中,A和B可能切换了很多次,但是A进程总共占用CPU的时间和就是50ms,B进程亦然。如果用1ms的粒度来观察呢?是否A和B个运行500us?如果继续缩减观察时间,在一个微秒的时间段观察呢?显然,不太可能每个进程运行500ns,如果那样的话,CPU的时间大量的消耗在了进程切换上,真正做事情的CPU时间变得越来越少了。因此,CFS调度器是有一个时间粒度的定义,我们称之调度周期。也就是说,在一个调度周期内,CFS调度器可以保证所有的可运行状态的进程平均分配CPU时间。下一小节我们会详细描述调度周期的概念。
4、如何保证有界的调度延迟?
传统的调度器无法保证调度延迟,为了说明这个问题我们设想这样一个场景:CPU runqueue中有两个nice value等于0的runnable进程A和B,传统调度器会为每一个进程分配一个固定的时间片100ms,这时候A先运行,直到100ms的时间片耗尽,然后B运行。这两个进程会交替运行,调度延迟就是100ms。随着系统负荷的加重,例如又有两个两个nice value等于0的runnable进程C和D挂入runqueue,这时候,A、B、C、D交替运行,调度延迟就是300ms。因此,传统调度器的调度延迟是和系统负载相关的,当系统负载增加的时候,用户更容易观察到卡顿现象。
CFS调度器设计之初就确定了调度延迟的参数,我们称之targeted latency,这个概念类似传统调度器中的调度周期的概念,只不过在过去,一个调度周期中的时间片被固定分配给了runnable的进程,而在CFS中,调度器会不断的检查在一个targeted latency中,公平性是否得到了保证。下面的代码说明了targeted latency的计算过程:
|
static u64 __sched_period(unsigned long nr_running) { if (unlikely(nr_running > sched_nr_latency)) return nr_running * sysctl_sched_min_granularity; else return sysctl_sched_latency; } |
当runqueue中的runnable进程的数目小于sched_nr_latency(8个)的时候,targeted latency就是sysctl_sched_latency(6ms),当runqueue中的runnable进程的数目大于等于sched_nr_latency的时候,targeted latency等于runnable进程数目乘以sysctl_sched_min_granularity(0.75ms)。显然sysctl_sched_min_granularity这个参数就是一段一个进程被调度执行,它需要至少执行的时间片大小,设立这个参数是为了防止overscheduling而产生的性能下降。
CFS调度器保证了在一个targeted latency中,所有的runnable进程都会至少执行一次,从而保证了有界的、可预测的调度延迟。
5、为何引入虚拟时间?
虽然Con Kolivas提出了精采绝伦的设计思想,但是在具体实现的时候相对保守。CFS调度器则不然,它采用了相对激进的方法,把runqueue中管理task的优先级链表变成了红黑树结构。有了这样一颗runnable进程的红黑树,在插入操作的时候如何确定进程在红黑树中的位置?也就是说这棵树的“key”是什么?
CFS的红黑树使用vruntime(virtual runtime)作为key,为了理解vruntime,这里需要引入一个虚拟时间轴的概念。在上一章中,我们已经清楚的表述了公平的含义:按照进程的静态优先级来分配CPU资源,当然,CPU资源也就是CPU的时间片,因此在物理世界中,公平就是分配和静态优先级匹配的CPU时间片。但是红黑树需要一个单一数轴上的量进行比对,而这里有两个度量因素:静态优先级和物理时间片,因此我们需要把它们映射到一个虚拟的时间轴上,屏蔽掉静态优先级的影响,具体的计算公式如下:
Virtual runtime = (physical runtime) X (nice value 0的权重)/进程的权重
通过上面的公式,我们构造了一个虚拟的世界。二维的(load weight,physical runtime)物理世界变成了一维的virtual runtime的虚拟世界。在这个虚拟的世界中,各个进程的vruntime可以比较大小,以便确定其在红黑树中的位置,而CFS调度器的公平也就是维护虚拟世界vruntime的公平,即各个进程的vruntime是相等的。
根据上面的公式,我们可以看出:实际上对于静态优先级是120(即nice value等于0)的进程,其物理时间轴等于虚拟时间轴,而其他的静态优先级的虚拟时间都是根据其权重和nice 0的权重进行尺度缩放。对于更高优先级的进程,其虚拟时间轴过的比较慢,而对于优先级比较低的进程,其虚拟时间轴过的比较快。
我们可以举一个简单的例子来描述虚拟世界的公平性:例如在时间点a到b之间(虚拟时间轴),如果有两个可运行状态的进程A和B,那么从a到b这个时间段上去观察,CPU的时间是平均分配到每个一个进程上,也就是说A和B进程各自运行了(b-a)/2的时间,也就是各占50%的时间片。在b时间点,一个新的可运行状态的进程C产生了,直到c时间点。那么从b到c这个时间段上去观察,进程A、B和进程C都是执行了(c-b)/3的时间,也就是各占1/3的CPU资源。再强调一次,上面说的时间都是虚拟时间。
6、如何计算virtual runtime
想要计算时间我们必须有类似手表这样的计时工具,对于CFS调度器,这个“手表”保存在runqueue中(clock和clock_task成员)。Runqueue戴两块表,一块记录实际的物理时间,另外一块则是记录执行task的时间(clock_task)。之所以有clock_task是为了更准确的记录进程执行时间。实际上一个task执行过程中不免会遇到一些异步事件,例如中断。这时候,进程的执行被打断从而转入到对异步事件的处理过程。如果把这些时间也算入该进程的执行时间会有失偏颇,因此clock_task会把这些异步事件的处理时间去掉,只有在真正执行任务的时候,clock_task的counter才会不断累加计时。
有了clock进程计时变得比较简单了,当进程进入执行状态的时候,看一下clock_task这块“手表”,记录数值为A。在需要统计运行时间的时候,再次看一下clock_task这块“手表”,记录数值为B。B-A就是该进程已经运行的物理时间。当然,CFS关心的是虚拟时间,这时候还需要通过calc_delta_fair函数将这个物理时间转换成虚拟时间,然后累积的该进程的virtual runtime中(sched_entity中的vruntime),而这个vruntime就是红黑树的key。
7、CFS调度器的运作
对于CFS调度器,没有固定分配时间片的概念,只有一个固定权重的概念,是根据进程静态优先级计算出来的。CFS调度器一旦选择了一个进程进入执行状态,会立刻开启对其virtual runtime的跟踪过程,并且在tick到来时会更新这个virtual runtime。有了这个virtual runtime信息,调度器就可以不断的检查目前系统的公平性(而不是检查是否时间片用完),具体的方法是:根据当前系统的情况计算targeted latency(调度周期),在这个调度周期中计算当前进程应该获得的时间片(物理时间),然后计算当前进程已经累积执行的物理时间,如果大于当前应该获得的时间片,那么更新本进程的vruntime并标记need resched flag,并在最近的一个调度点发起调度。
在进行进程调度时候,调度器需要选择下一个占用CPU资源的那个next thread。对于CFS而言,其算法就是从红黑树中找到left most的那个task并调度其运行。这时候,失去CPU执行权的那个task会被重新插入红黑树,其在红黑树中的位置是由task的vruntime值决定的。
CFS调度器的更多相关文章
- CFS调度器(1)-基本原理
首先需要思考的问题是:什么是调度器(scheduler)?调度器的作用是什么?调度器是一个操作系统的核心部分.可以比作是CPU时间的管理员.调度器主要负责选择某些就绪的进程来执行.不同的调度器根据不同 ...
- Linux进程管理 (2)CFS调度器
关键词: 目录: Linux进程管理 (1)进程的诞生 Linux进程管理 (2)CFS调度器 Linux进程管理 (3)SMP负载均衡 Linux进程管理 (4)HMP调度器 Linux进程管理 ( ...
- CFS 调度器
CFS调度器的原理明白了但是有个地方,搜遍了整个网络也没找到一个合理的解释: if (delta > ideal_runtime) resched_task(rq_of(cfs_rq)-> ...
- Linux内核——进程管理之CFS调度器(基于版本4.x)
<奔跑吧linux内核>3.2笔记,不足之处还望大家批评指正 建议阅读博文https://www.cnblogs.com/openix/p/3262217.html理解linux cfs调 ...
- 【原创】(五)Linux进程调度-CFS调度器
背景 Read the fucking source code! --By 鲁迅 A picture is worth a thousand words. --By 高尔基 说明: Kernel版本: ...
- 从几个问题开始理解CFS调度器
本文转载自从几个问题开始理解CFS调度器 导语 CFS(完全公平调度器)是Linux内核2.6.23版本开始采用的进程调度器,它的基本原理是这样的:设定一个调度周期(sched_latency_ns) ...
- linux cfs调度器_模型实现
调度器真实模型的主要成员变量及与抽象模型的对应关系 I.cfs_rq结构体 a) struct sched_entity *curr 指向当前正在执行的可调度实体.调度器的调度单位 ...
- linux cfs调度器_理论模型
参考资料:<调度器笔记>Kevin.Liu <Linux kernel development> <深入Linux内核架构> version: 2.6.32.9 下 ...
- linux cfs调度器
在抽象模型中vruntime决定了进程被调度的先后顺序,在真实模型中决定被调度的先后顺序的参数是由函数entity_key决定的. static inline s64 entity_key(str ...
随机推荐
- Reverse Linked List II leetcode java
题目: Reverse a linked list from position m to n. Do it in-place and in one-pass. For example: Given 1 ...
- GO语言基础条件、跳转、Array和Slice
1. 判断语句if 1. 条件表达式没有括号(这点其他语言转过来的需要注意) 2. 支持一个初始化表达式(可以是并行方式,即:a, b, c := 1, 2, 3) 3. 左大括号必须和条件语句或 e ...
- WordPress后台的文章、分类,媒体,页面,评论,链接等所有信息中显示ID并将ID设置为第一列
WordPress后台默认是不显示文章.分类等信息ID的,查看起来非常不方便,不知道Wp团队出于什么原因默认不显示这个但可以使用Simply Show IDs插件来实现 不使用插件,其他网友的实现: ...
- RS错误RSV-VAL-0032之项目未在布局中引用的3种解决办法
如下图所示,我用RS新建了一个空白页面,拖入了一个列表,给该列表新建了一个条件样式 条件样式如下所示,表达式来自查询1 运行,报错如下图所示 原因就是条件样式使用到了查询1中的数据项1但是数据项1在报 ...
- 输入框提示文字跨浏览器的placeholder-jQuery版
<script type="text/javascript" src="jquery-1.7.2.min.js"></script> & ...
- 【Android 百度地图实战】1.构建一个基础的地图页面
虽然很简单,但是还是有些细节要注意的,小错误搞死人啊,具体步骤官网API已提供,地址在这. 效果图如下: 主要代码: package yc.example.yc_ebaidumap; import a ...
- 改进版高速排序(平均复杂度O(NlogN))
#include<iostream> using namespace std; #define MAXSIZE 21 typedef int SqList[MAXSIZE]; #defin ...
- Centering window on the screen
The following script shows how we can center a window on the desktop screen. #!/usr/bin/python # -*- ...
- How to set up OpenERP for various timezone kindly follow the following steps to select timezone in OpenERP
How to set up OpenERP for different Time Zones Click on the "Edit Preferences" wheel a ...
- 【安卓】给gallery内"控件"挂载事件,滑动后抬起手指时也触发事件(滑动时不应触发)的解决、!
思路: 1.gallery内控件挂载事件(如:onClickListener)的方法类似listview,可直接在baseAdapter.getView内给控件挂载(详细方法百度). 2.貌似没问题, ...