Hadoop中的问题排查思路
一、概述:
在实际使用hadoop的过程中,由于涉及到多台服务器、每台机器上可能还有多个服务等。所以当集群环境出现问题时,快速定位到错误出现的地方尤为重要。
在排查错误的过程中,基本上就是通过既有的工具来检测集群的运行时环境、集群日志等来分析导致错误的原因。
二、Java heap:
hadoop需要运行在Java运行时环境之上。因此jvm中的内存分配是否处于合理的状态,就是需要检测的一个因素。Java虚拟机中分为多个区域,最值得关注的区域是heap区。heap区的大体划分如下:
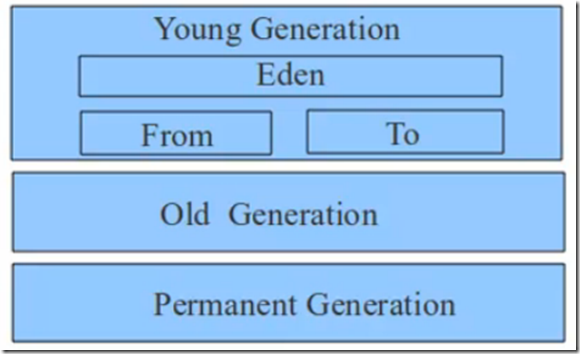
创建对象时,会首先在Eden区分配内存来创建。随着时间的推移,Eden会慢慢被填满,此时就会触发一次垃圾回收,将Eden区的对象复制到From区。当From区填满时,则又会触发一次垃圾回收,从From区复制到To区。
在复制的过程中,当某个对象复制的次数达到阈值时,就会从年轻代复制到old区域。
在young区域中,垃圾回收器主要是使用ParNew,它是基于复制的垃圾回收器。
在Old区域,可选择的垃圾回收器有:串行(serialOld),并发(ParallelOld),并行(CMS)等。
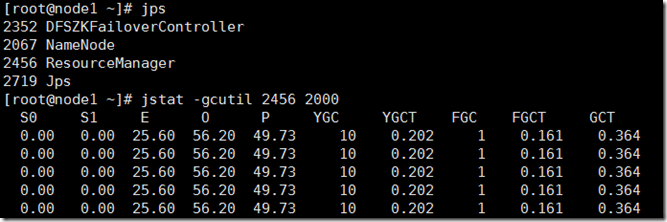
可以使用下述的命令来查看垃圾回收的相关信息:
[root@node1 ~]# jps
2352 DFSZKFailoverController
2067 NameNode
2456 ResourceManager
2719 Jps
[root@node1 ~]# jstat -gcutil 2456 2000
S0 S1 E O P YGC YGCT FGC FGCT GCT
0.00 0.00 25.60 56.20 49.73 10 0.202 1 0.161 0.364
0.00 0.00 25.60 56.20 49.73 10 0.202 1 0.161 0.364
0.00 0.00 25.60 56.20 49.73 10 0.202 1 0.161 0.364
0.00 0.00 25.60 56.20 49.73 10 0.202 1 0.161 0.364
0.00 0.00 25.60 56.20 49.73 10 0.202 1 0.161 0.364
三、通过浏览器界面查看:
hadoop集群中提供了很多基于web服务的界面。
namenode管理界面:http://hostname:50057
ResourceManager管理界面:http://hostname:8088
JobTracker管理界面(hadoop1.x):http://hostname:50030
四、查看日志:
通过tar包安装的hadoop日志一般位于<hadoop_home>/logs目录下。
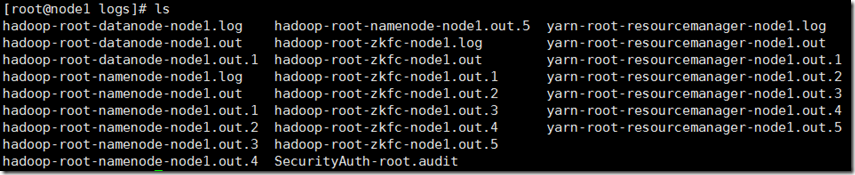
通过cdh安装的hadoop日志一般位于/var/log/hadoop目录下。
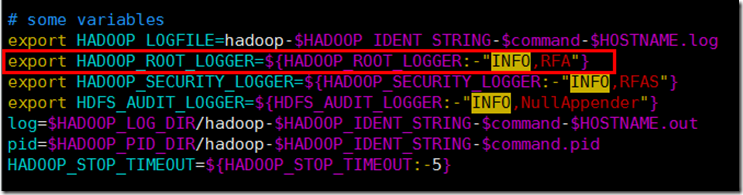
log的级别设置:在hadoop-daemon.sh中定义:
五、在线分析工具:
1、jstack:用于打印出给定的java进程ID或core file或远程调试服务的Java堆栈信息。
[root@node1 test]# jps
2352 DFSZKFailoverController
2067 NameNode
2456 ResourceManager
2819 Jps
[root@node1 test]# jstack 2456 > rm.dat
[root@node1 test]# ls
rm.dat
[root@node1 test]# vim rm.dat 2016-01-27 16:30:24
Full thread dump Java HotSpot(TM) 64-Bit Server VM (24.79-b02 mixed mode): "Attach Listener" daemon prio=10 tid=0x00007fed089fd000 nid=0xb1b runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE "2141196255@qtp-1207409333-7" daemon prio=10 tid=0x00007fecf4456800 nid=0xab8 in Object.wait() [0x00007fece4c2b000]
java.lang.Thread.State: TIMED_WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
- waiting on <0x00000000c222d760> (a org.mortbay.thread.QueuedThreadPool$PoolThread)
at org.mortbay.thread.QueuedThreadPool$PoolThread.run(QueuedThreadPool.java:626)
- locked <0x00000000c222d760> (a org.mortbay.thread.QueuedThreadPool$PoolThread) "ApplicationMaster Launcher" prio=10 tid=0x00007fed090e5000 nid=0xa9e waiting on condition [0x00007fece502f000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000c1c1b0e0> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:186)
at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2043)
"rm.dat" 2017L, 144689C
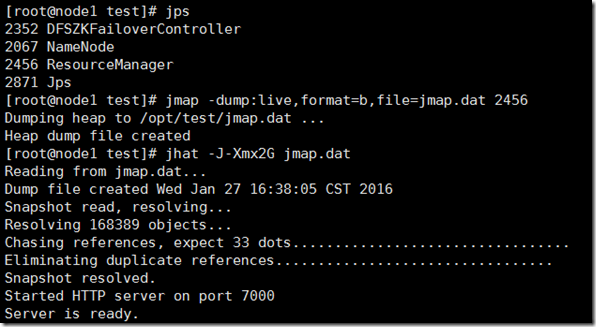
2、jmap+jhat分析:
A、首先用jps或者ps或许需要查询的进程id。
B、用jmap得到进程的进行时内存镜像,命令如下:
jmap -dump:live,format=b,file=jmap.dat ${PID}
C、用jhat进行内存分析:命令如下:
jhat -J-Xmx2G jmap.dat
D、jhat启动后会建立一个HTTP server,端口为7000,可以通过浏览器查看统计数据。
3、fsck检查文件系统是否有损坏的blocks。
4、使用dfsadmin命令。
六、其他工具:
1、strace:这是一个Linux工具。
2、iostat:查看磁盘是否出现瓶颈。
3、nload:监控当前的网络带宽。
4、iptraf。
5、netstat:查看端口占用。
6、tcpdump:抓包工具。示例如下:
tcpdump -nn -i etho -xX -s 0 tcp and port 2181
Hadoop中的问题排查思路的更多相关文章
- Springboot项目中使用@RestControllerAdvice注解不生效排查思路
说明: 在后端编写业务逻辑时,可能会遇到异常抛出处理的情况,后端通常会通过throw出一个异常,然后通过@RestControllerAdvice注解标注自定义类进行统一处理,前端再将接收到的结果解析 ...
- Flink on YARN(下):常见问题与排查思路
Flink 支持 Standalone 独立部署和 YARN.Kubernetes.Mesos 等集群部署模式,其中 YARN 集群部署模式在国内的应用越来越广泛.Flink 社区将推出 Flink ...
- Hadoop中的各种排序
本篇博客是金子在学习hadoop过程中的笔记的整理,不论看别人写的怎么好,还是自己边学边做笔记最好了. 1:shuffle阶段的排序(部分排序) shuffle阶段的排序可以理解成两部分,一个是对sp ...
- 深度分析如何在Hadoop中控制Map的数量
深度分析如何在Hadoop中控制Map的数量 guibin.beijing@gmail.com 很多文档中描述,Mapper的数量在默认情况下不可直接控制干预,因为Mapper的数量由输入的大小和个数 ...
- 系统运行缓慢,CPU 100%,以及Full GC次数过多问题的排查思路
前言 处理过线上问题的同学基本上都会遇到系统突然运行缓慢,CPU 100%,以及Full GC次数过多的问题.当然,这些问题的最终导致的直观现象就是系统运行缓慢,并且有大量的报警. 本文主要针对系统运 ...
- Java线上问题排查思路及Linux常用问题分析命令学习
前言 之前线上有过一两次OOM的问题,但是每次定位问题都有点手足无措的感觉,刚好利用星期天,以测试环境为模版来学习一下Linux常用的几个排查问题的命令. 也可以帮助自己在以后的工作中快速的排查线上问 ...
- windows应急响应入侵排查思路
0x00 前言 当企业发生黑客入侵.系统崩溃或其它影响业务正常运行的安全事件时,急需第一时间进行处理,使企业的网络信息系统在最短时间内恢复正常工作,进一步查找入侵来源,还原入侵事故过程,同时给出解 ...
- Linux应急响应入侵排查思路
0x00 前言 当企业发生黑客入侵.系统崩溃或其它影响业务正常运行的安全事件时,急需第一时间进行处理,使企业的网络信息系统在最短时间内恢复正常工作,进一步查找入侵来源,还原入侵事故过程,同时给出解 ...
- hadoop中map和reduce的数量设置
hadoop中map和reduce的数量设置,有以下几种方式来设置 一.mapred-default.xml 这个文件包含主要的你的站点定制的Hadoop.尽管文件名以mapred开头,通过它可以控制 ...
随机推荐
- ITShare
框架底层通过IBatis和XML实现ORM映射: 业务处理类似UI,通过Controller和JavaScript交互: 视图通过Castle与NVelocity实现,jquery.tmpl渲染: . ...
- Spring MVC学习笔记——文件上传
1.实现文件上传首先需要导入Apache的包,commons-fileupload-1.2.2.jar和commons-io-2.1.jar 实现上传就在add.jsp文件中修改表单 enctype= ...
- canvas.drawBitmap()频繁调用导致应用崩溃问题
因为opengl不熟,要在opengl上面贴文字 时间紧所以用到一个折中的办法 文字转bitmap 因为文字较多,对话形式 还要分行,分段,逻辑处理的比较复杂 运行中会有闪退发生,且不可 ...
- 记一次ss故障
本文主要参考: https://github.com/shadowsocks/shadowsocks shadowssocks 分为客户端和服务器端. 我们平时买的服务,使用是要用的是客户端. 如果你 ...
- web.config SetAttributes
<appSettings> <add key="DomainProxy" value="http://e3api.lcsyzx.cn/api/" ...
- 又一枚精彩的弹幕效果jQuery实现
精彩的弹幕效果分享给大家,具有一定的参考价值,感兴趣的朋友可以尝试制作弹幕,具体内容如下 简易弹幕效果:将发布的内容随机显示在弹幕右侧,逐渐左移最后消失. 涉及知识点:val().random ...
- 一个ListView怎么展示两种样式
private class MyBaseMsgAdapter extends BaseAdapter { //获取数据适配器中条目类型的总数,修改成两种(纯文本,输入+文字) @Override pu ...
- Java与各种数据库连接代码
6.MySQL数据库Class.forName("org.gjt.mm.mysql.Driver").newInstance();String url ="jdbc:my ...
- Android——SharedPreferences
SharedPreferences是一种轻型的Android数据存储方式,用来保存应用的一些常用配置. 实现SharedPreferences存储的步骤如下: 1.根据Context获取SharedP ...
- QMF滤波器组 理论
QMF滤波器组 经常被用来子带信号分解,降低信号带宽,使各个子带可顺利由通道处理. 2^M个通道,等宽 QMF 正交镜像滤波器 正交滤波器 A(W) 与 A(W+pi) 之间的关系 ...