Redis 源码简洁剖析 05 - ziplist 压缩列表
ziplist 是什么
压缩列表,内存紧凑的数据结构,占用一块连续的内存空间。一个 ziplist 可以包含多个节点(entry), 每个节点可以保存一个长度受限的字符数组(不以 \0 结尾的 char 数组)或者整数, 包括:
字符数组
- 长度小于等于
63(2^6-1)字节的字符数组 - 长度小于等于
16383(12^14-1) 字节的字符数组 - 长度小于等于
4294967295(2^32-1)字节的字符数组
- 长度小于等于
整数
4位长,介于0至12之间的无符号整数1字节长,有符号整数3字节长,有符号整数int16_t类型整数int32_t类型整数int64_t类型整数
Redis 哪些数据结构使用了 ziplist?
- 哈希键
- 列表键
- 有序集合键
ziplist 特点
优点
- 节省内存
缺点
- 不能保存过多的元素,否则访问性能会下降
- 不能保存过大的元素,否则容易导致内存重新分配,甚至引起连锁更新
ziplist 数据结构
啥都不说了,都在注释里。
// ziplist 中的元素,是 string 或者 integer
typedef struct {
// 如果元素是 string,slen 就表示长度
unsigned char *sval;
unsigned int slen;
// 如果是 integer,sval 是 NULL,lval 就是 integer 的值
long long lval;
} ziplistEntry;

为了方便地取出 ziplist 的各个域以及一些指针地址, ziplist 模块定义了以下宏:
// 取出 zlbytes 的值
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
// 取出 zltail 的值
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
// 取出 zllen 的值
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
// 返回 ziplist header 部分的长度,总是固定的 10 字节
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
// 返回 ziplist end 部分的长度,总是固定的 1 字节
#define ZIPLIST_END_SIZE (sizeof(uint8_t))
// 返回到达 ziplist 第一个节点(表头)的地址
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
// 返回到达 ziplist 最后一个节点(表尾)的地址
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
// 返回 ziplist 的末端,也即是 zlend 之前的地址
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
ziplist 节点
typedef struct zlentry {
// 前一个节点的长度,通过这个值,可以进行指针计算,从而跳转到上一个节点
unsigned int prevrawlen;
unsigned int prevrawlensize;
// entry 的编码方式
// 1. entry 是 string,可能是 1 2 5 个字节的 header
// 2. entry 是 integer,固定为 1 字节
unsigned int lensize;
// 实际 entry 的字节数
// 1. entry 是 string,则表示 string 的长度
// 2. entry 是 integer,则根据数值范围,可能是 1, 2, 3, 4, 8
unsigned int len;
// prevrawlensize + lensize
unsigned int headersize;
// ZIP_STR_* 或者 ZIP_INT_*
unsigned char encoding;
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;

pre_entry_length
记录前一个节点的长度。通过这个值,可以进行指针计算,从而跳转到上一个节点。
area |<---- previous entry --->|<--------------- current entry ---------------->|
size 5 bytes 1 byte ? ? ?
+-------------------------+-----------------------------+--------+---------+
component | ... | pre_entry_length | encoding | length | content |
| | | | | |
value | | 0000 0101 | ? | ? | ? |
+-------------------------+-----------------------------+--------+---------+
^ ^
address | |
p = e - 5 e
以上图为例,从当前节点的指针 e,减去 pre_entry_length 的值(0000 0101 的十进制值,5),就可以得到指向前一个节点的地址 p。
encoding 和 length
encoding 和 length 两部分一起决定了 content 部分所保存的数据的类型(以及长度)。
其中, encoding 域的长度为两个 bit , 它的值可以是 00 、 01 、 10 和 11 :
00、01和10表示content部分保存着字符数组。11表示content部分保存着整数。
以 00 、 01 和 10 开头的字符数组的编码方式如下:

表格中的下划线 _ 表示留空,而变量 b 、 x 等则代表实际的二进制数据。为了方便阅读,多个字节之间用空格隔开。
11 开头的整数编码如下:
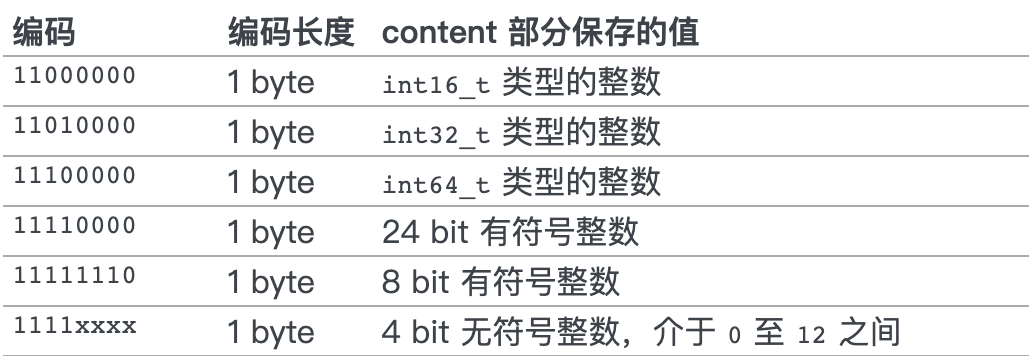
content
content 部分保存着节点的内容,类型和长度由 encoding 和 length 决定。
以下是一个保存着字符数组 hello world 的节点的例子:
area |<---------------------- entry ----------------------->|
size ? 2 bit 6 bit 11 byte
+------------------+----------+--------+---------------+
component | pre_entry_length | encoding | length | content |
| | | | |
value | ? | 00 | 001011 | hello world |
+------------------+----------+--------+---------------+
encoding 域的值 00 表示节点保存着一个长度小于等于 63 字节的字符数组, length 域给出了这个字符数组的准确长度 —— 11 字节(的二进制 001011), content 则保存着字符数组值 hello world 本身(为了方便表示, content 部分使用字符而不是二进制表示)。
以下是另一个节点,它保存着整数 10086 :
area |<---------------------- entry ----------------------->|
size ? 2 bit 6 bit 2 bytes
+------------------+----------+--------+---------------+
component | pre_entry_length | encoding | length | content |
| | | | |
value | ? | 11 | 000000 | 10086 |
+------------------+----------+--------+---------------+
encoding 域的值 11 表示节点保存的是一个整数; 而 length 域的值 000000 表示这个节点的值的类型为 int16_t ; 最后, content 保存着整数值 10086 本身(为了方便表示, content 部分用十进制而不是二进制表示)。
ziplist 基本操作
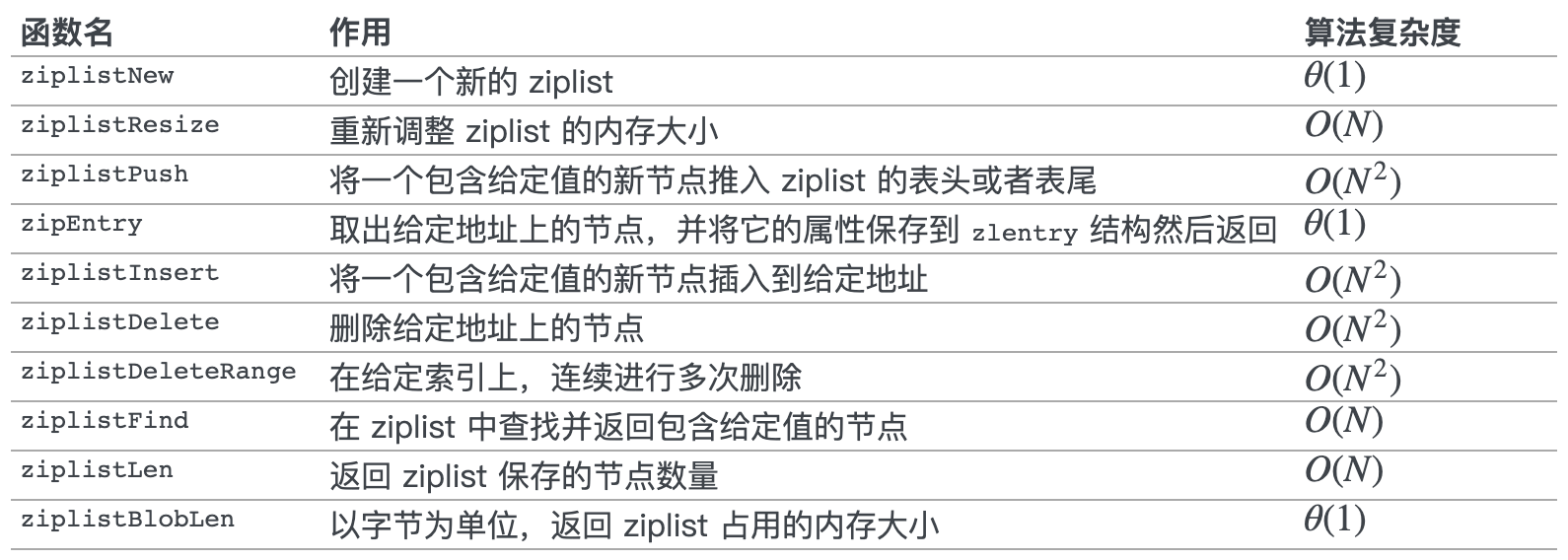
创建新 ziplist
创建一个新的 ziplist,时间复杂度是 O(1)。
/* Create a new empty ziplist. */
unsigned char *ziplistNew(void) {
// header 和 end 需要的字节数
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
// 分配 bytes 长度的内存
unsigned char *zl = zmalloc(bytes);
// 赋值 zlbytes
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
// 赋值 zltail
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
// 赋值 zllen
ZIPLIST_LENGTH(zl) = 0;
// 赋值 zlend
zl[bytes-1] = ZIP_END;
return zl;
}
area |<---- ziplist header ---->|<-- end -->|
size 4 bytes 4 bytes 2 bytes 1 byte
+---------+--------+-------+-----------+
component | zlbytes | zltail | zllen | zlend |
| | | | |
value | 1011 | 1010 | 0 | 1111 1111 |
+---------+--------+-------+-----------+
^
|
ZIPLIST_ENTRY_HEAD
&
address ZIPLIST_ENTRY_TAIL
&
ZIPLIST_ENTRY_END
空白 ziplist 的表头、表尾和末端处于同一地址。
创建了 ziplist 之后, 就可以往里面添加新节点了, 根据新节点添加位置的不同, 这个工作可以分为两类来进行:
- 将节点添加到 ziplist 末端:在这种情况下,新节点的后面没有任何节点。
- 将节点添加到某个/某些节点的前面:在这种情况下,新节点的后面有至少一个节点。
以下两个小节分别讨论这两种情况。
将节点添加到末端
将新节点添加到 ziplist 的末端需要执行以下三个步骤:
- 记录到达 ziplist 末端所需的偏移量(因为之后的内存重分配可能会改变 ziplist 的地址,因此记录偏移量而不是保存指针)
- 根据新节点要保存的值,计算出编码这个值所需的空间大小,以及编码它前一个节点的长度所需的空间大小,然后对 ziplist 进行内存重分配。
- 设置新节点的各项属性:
pre_entry_length、encoding、length和content。 - 更新 ziplist 的各项属性,比如记录空间占用的
zlbytes,到达表尾节点的偏移量zltail,以及记录节点数量的zllen。
举个例子,假设现在要将一个新节点添加到只含有一个节点的 ziplist 上,程序首先要执行步骤 1 ,定位 ziplist 的末端:
area |<---- ziplist header ---->|<--- entries -->|<-- end -->|
size 4 bytes 4 bytes 2 bytes 5 bytes 1 bytes
+---------+--------+-------+----------------+-----------+
component | zlbytes | zltail | zllen | entry 1 | zlend |
| | | | | |
value | 10000 | 1010 | 1 | ? | 1111 1111 |
+---------+--------+-------+----------------+-----------+
^ ^
| |
address ZIPLIST_ENTRY_HEAD ZIPLIST_ENTRY_END
&
ZIPLIST_ENTRY_TAIL
然后执行步骤 2 ,程序需要计算新节点所需的空间:
假设我们要添加到节点里的值为字符数组 hello world , 那么保存这个值共需要 12 字节的空间:
- 11 字节用于保存字符数组本身;
- 另外 1 字节中的 2 bit 用于保存类型编码
00, 而其余 6 bit 则保存字符数组长度11的二进制001011。
另外,节点还需要 1 字节, 用于保存前一个节点的长度 5 (二进制 101 )。
合算起来,为了添加新节点, ziplist 总共需要多分配 13 字节空间。 以下是分配完成之后, ziplist 的样子:
area |<---- ziplist header ---->|<------------ entries ------------>|<-- end -->|
size 4 bytes 4 bytes 2 bytes 5 bytes 13 bytes 1 bytes
+---------+--------+-------+----------------+------------------+-----------+
component | zlbytes | zltail | zllen | entry 1 | entry 2 | zlend |
| | | | | | |
value | 10000 | 1010 | 1 | ? | pre_entry_length | 1111 1111 |
| | | | | ? | |
| | | | | | |
| | | | | encoding | |
| | | | | ? | |
| | | | | | |
| | | | | length | |
| | | | | ? | |
| | | | | | |
| | | | | content | |
| | | | | ? | |
| | | | | | |
+---------+--------+-------+----------------+------------------+-----------+
^ ^
| |
address ZIPLIST_ENTRY_HEAD ZIPLIST_ENTRY_END
&
ZIPLIST_ENTRY_TAIL
步骤三,更新新节点的各项属性(为了方便表示, content 的内容使用字符而不是二进制来表示):
area |<---- ziplist header ---->|<------------ entries ------------>|<-- end -->|
size 4 bytes 4 bytes 2 bytes 5 bytes 13 bytes 1 bytes
+---------+--------+-------+----------------+------------------+-----------+
component | zlbytes | zltail | zllen | entry 1 | entry 2 | zlend |
| | | | | | |
value | 10000 | 1010 | 1 | ? | pre_entry_length | 1111 1111 |
| | | | | 101 | |
| | | | | | |
| | | | | encoding | |
| | | | | 00 | |
| | | | | | |
| | | | | length | |
| | | | | 001011 | |
| | | | | | |
| | | | | content | |
| | | | | hello world | |
| | | | | | |
+---------+--------+-------+----------------+------------------+-----------+
^ ^
| |
address ZIPLIST_ENTRY_HEAD ZIPLIST_ENTRY_END
&
ZIPLIST_ENTRY_TAIL
最后一步,更新 ziplist 的 zlbytes 、 zltail 和 zllen 属性:
area |<---- ziplist header ---->|<------------ entries ------------>|<-- end -->|
size 4 bytes 4 bytes 2 bytes 5 bytes 13 bytes 1 bytes
+---------+--------+-------+----------------+------------------+-----------+
component | zlbytes | zltail | zllen | entry 1 | entry 2 | zlend |
| | | | | | |
value | 11101 | 1111 | 10 | ? | pre_entry_length | 1111 1111 |
| | | | | 101 | |
| | | | | | |
| | | | | encoding | |
| | | | | 00 | |
| | | | | | |
| | | | | length | |
| | | | | 001011 | |
| | | | | | |
| | | | | content | |
| | | | | hello world | |
| | | | | | |
+---------+--------+-------+----------------+------------------+-----------+
^ ^ ^
| | |
address | ZIPLIST_ENTRY_TAIL ZIPLIST_ENTRY_END
|
ZIPLIST_ENTRY_HEAD
将节点添加到某个/某些节点的前面
比起将新节点添加到 ziplist 的末端, 将一个新节点添加到某个/某些节点的前面要复杂得多, 因为这种操作除了将新节点添加到 ziplist 以外, 还可能引起后续一系列节点的改变。
举个例子,假设我们要将一个新节点 new 添加到节点 prev 和 next 之间:
add new entry here
|
V
+----------+----------+----------+----------+----------+
| | | | | |
| prev | next | next + 1 | next + 2 | ... |
| | | | | |
+----------+----------+----------+----------+----------+
程序首先为新节点扩大 ziplist 的空间:
+----------+----------+----------+----------+----------+----------+
| | | | | | |
| prev | ??? | next | next + 1 | next + 2 | ... |
| | | | | | |
+----------+----------+----------+----------+----------+----------+
|<-------->|
expand
space
然后设置 new 节点的各项值 —— 到目前为止,一切都和前面介绍的添加操作一样:
set value,
property,
length,
etc.
|
v
+----------+----------+----------+----------+----------+----------+
| | | | | | |
| prev | new | next | next + 1 | next + 2 | ... |
| | | | | | |
+----------+----------+----------+----------+----------+----------+
现在,新的 new 节点取代原来的 prev 节点, 成为了 next 节点的新前驱节点, 不过, 因为这时 next 节点的 pre_entry_length 域编码的仍然是 prev 节点的长度, 所以程序需要将 new 节点的长度编码进 next 节点的 pre_entry_length 域里, 这里会出现三种可能:
next的pre_entry_length域的长度正好能够编码new的长度(都是 1 字节或者都是 5 字节)next的pre_entry_length只有 1 字节长,但编码new的长度需要 5 字节next的pre_entry_length有 5 字节长,但编码new的长度只需要 1 字节
对于情况 1 和 3 , 程序直接更新 next 的 pre_entry_length 域。
如果是第二种情况, 那么程序必须对 ziplist 进行内存重分配, 从而扩展 next 的空间。 然而,因为 next 的空间长度改变了, 所以程序又必须检查 next 的后继节点 —— next+1 , 看它的 pre_entry_length 能否编码 next 的新长度, 如果不能的话,程序又需要继续对 next+1 进行扩容。
这就是说, 在某个/某些节点的前面添加新节点之后, 程序必须沿着路径挨个检查后续的节点,是否满足新长度的编码要求, 直到遇到一个能满足要求的节点(如果有一个能满足,则这个节点之后的其他节点也满足), 或者到达 ziplist 的末端 zlend 为止。
删除节点
删除节点和添加操作的步骤类似。
- 定位目标节点,并计算节点的空间长度
target-size:
target start here
|
V
+----------+----------+----------+----------+----------+----------+
| | | | | | |
| prev | target | next | next + 1 | next + 2 | ... |
| | | | | | |
+----------+----------+----------+----------+----------+----------+
|<-------->|
target-size
- 进行内存移位,覆盖
target原本的数据,然后通过内存重分配,收缩多余空间:
target start here
|
V
+----------+----------+----------+----------+----------+
| | | | | |
| prev | next | next + 1 | next + 2 | ... |
| | | | | |
+----------+----------+----------+----------+----------+
| <------------------------------------------ memmove
- 检查
next、next+1等后续节点能否满足新前驱节点的编码。和添加操作一样,删除操作也可能会引起连锁更新。
参考链接
Redis 源码简洁剖析系列
Java 编程思想-最全思维导图-GitHub 下载链接,需要的小伙伴可以自取~
原创不易,希望大家转载时请先联系我,并标注原文链接。
Redis 源码简洁剖析 05 - ziplist 压缩列表的更多相关文章
- Redis 源码简洁剖析 06 - quicklist 和 listpack
quicklist 为什么要设计 quicklist 特点 数据结构 quicklistCreate quicklistDelIndex quicklistDelEntry quicklistInse ...
- Redis 源码简洁剖析 07 - main 函数启动
前言 问题 阶段 1:基本初始化 阶段 2:检查哨兵模式,执行 RDB 或 AOF 检测 阶段 3:运行参数解析 阶段 4:初始化 server 资源管理 初始化数据库 创建事件驱动框架 阶段 5:执 ...
- Redis 源码简洁剖析 04 - Sorted Set 有序集合
Sorted Set 是什么 Sorted Set 命令及实现方法 Sorted Set 数据结构 跳表(skiplist) 跳表节点的结构定义 跳表的定义 跳表节点查询 层数设置 跳表插入节点 zs ...
- Redis 源码简洁剖析 13 - RDB 文件
RDB 是什么 RDB 文件格式 Header Body DB Selector AUX Fields Key-Value Footer 编码算法说明 Length 编码 String 编码 Scor ...
- Redis 源码简洁剖析 02 - SDS 字符串
C 语言的字符串函数 C 语言 string 函数,在 C 语言中可以使用 char* 字符数组实现字符串,C 语言标准库 string.h 中也定义了多种字符串操作函数. 字符串使用广泛,需要满足: ...
- Redis 源码简洁剖析 03 - Dict Hash 基础
Redis Hash 源码 Redis Hash 数据结构 Redis rehash 原理 为什么要 rehash? Redis dict 数据结构 Redis rehash 过程 什么时候触发 re ...
- Redis 源码简洁剖析 09 - Reactor 模型
Reactor 模型 事件驱动框架 Redis 如何实现 Reactor 模型 事件的数据结构:aeFileEvent 主循环:aeMain 函数 事件捕获与分发:aeProcessEvents 函数 ...
- Redis 源码简洁剖析 10 - aeEventLoop 及事件
aeEventLoop IO 事件处理 IO 事件创建 读事件处理 写事件处理 时间事件处理 时间事件定义 时间事件创建 时间事件回调函数 时间事件的触发处理 参考链接 Redis 源码简洁剖析系列 ...
- Redis 源码简洁剖析 11 - 主 IO 线程及 Redis 6.0 多 IO 线程
Redis 到底是不是单线程的程序? 多 IO 线程的初始化 IO 线程运行函数 IOThreadMain 如何推迟客户端「读」操作? 如何推迟客户端「写」操作? 如何把待「读」客户端分配给 IO 线 ...
随机推荐
- GCD is Funny(hdu 5902)
GCD is Funny Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Tota ...
- 1298 - One Theorem, One Year
1298 - One Theorem, One Year PDF (English) Statistics Forum Time Limit: 2 second(s) Memory Limit: ...
- MySQL 批量插入,如何不插入重复数据
1.insert ignore into 当插入数据时,如出现错误时,如重复数据,将不返回错误,只以警告形式返回.所以使用ignore请确保语句本身没有问题,否则也会被忽略掉=======>IN ...
- Differential Evolution: A Survey of the State-of-the-Art
@ 目录 概 主要内容 DE/rand/1/bin DE/?/?/? DE/rand/1/exp DE/best/1 DE/best/2 DE/rand/2 超参数的选择 的选择 的选择 的选择 一些 ...
- matplotlib 进阶之Tight Layout guide
目录 简单的例子 Use with GridSpec Legend and Annotations Use with AxesGrid1 Colorbar 函数链接 matplotlib教程学习笔记 ...
- 基于Spring MVC + Spring + MyBatis的【超市会员管理系统】
资源下载: https://download.csdn.net/download/weixin_44893902/22035329 一. 语言和环境 实现语言:JAVA语言. 使用:MyEclipse ...
- 编写Java程序,通过给定可变参数方法,计算任意给定的多个int类型数据之和
返回本章节 返回作业目录 需求说明: 通过给定可变参数方法,计算任意给定的多个int类型数据之和. 实现思路: 定义可变形参方法,参数类型是int类型. 定义变量 sum 接受最终的和. 通过 for ...
- 使用 windows bat 脚本命令 一键启动MySQL服务
@echo off rem Copyright (c) 2019 Moses and/or its affiliates. rem Get Administrator Rights >nul 2 ...
- [Blue Prism] Data item 的使用
1.用于存储各种数据类型的变量,支持的数据类型如下: Binary - 用于存储二进制 blob,例如文本文件. Date - 用于存储日期. 此数据类型与 DateTime 类似,只是 Date ...
- 51 Nod 1006 最长公共子序列(LCS & DP)
原题链接:https://www.51nod.com/onlineJudge/questionCode.html#!problemId=1006 题目分析: 首先先知道LCS问题,这有两种: Long ...