B树和B+树原理图文解析
B树与B+树不同的地方在于插入是从底向上进行(当然查找与二叉树相同,都是从上往下)
二者都通常用于数据库和操作系统的文件系统中,非关系型数据库索引如mongoDB用的B树,大部分关系型数据库索引使用的是B+树。
一、B树(也叫B-树,注意并不是读B减树哦)
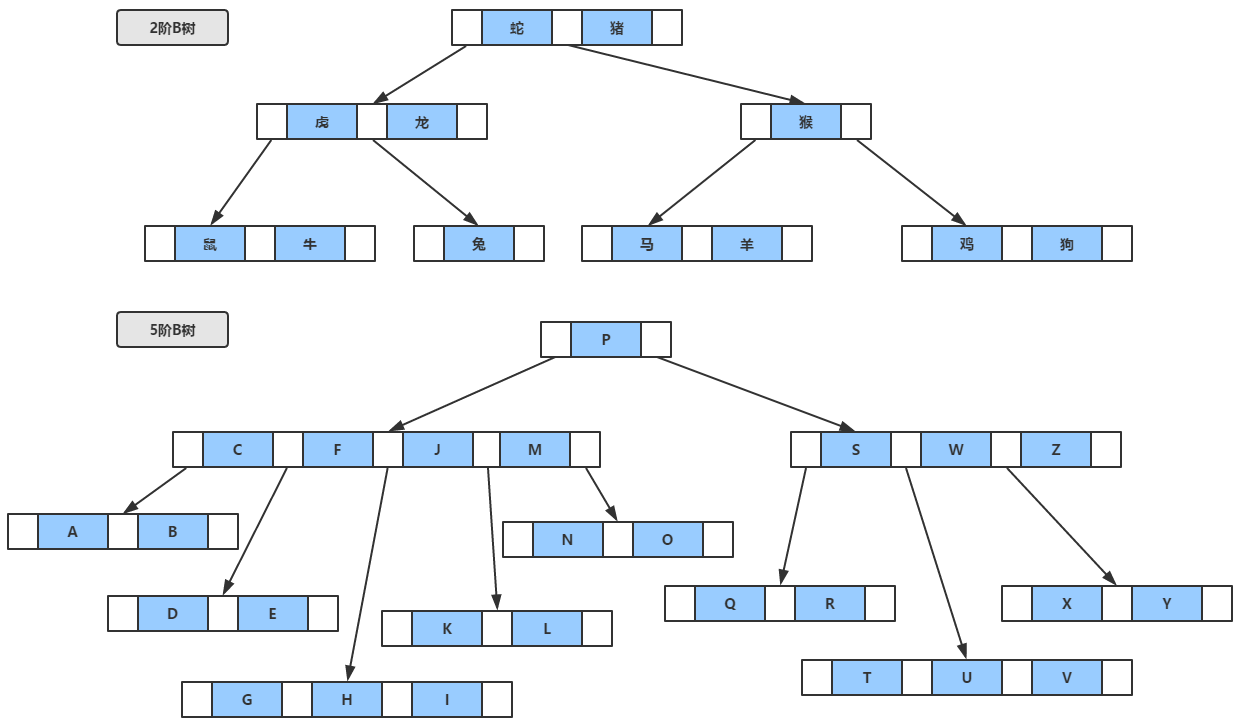
m阶B树需满足以下要求:
1、m阶B树:m阶指的是分叉的个数最多为m个。即一个非叶子节点最多可以有m个子节点。
2、子节点:一个叉连接的表示一个子节点,如果所示CFJM 表示一个子节点,其中CFJM表示4个元素。一个非叶子节点可以表示为[A0 k1 A1 k2 A2……kn An],其中ceil(m/2) -1 <= k <= m-1个,因此ceil(m/2) <= A <= m,A表示指向子节点的指针。
3、根节点至少有两个子节点。
4、所有的叶子在同一层。
上图所示并未画出叶子节点,因为叶子结点不包含元素,所以可以把叶子结点看成在树里实际上并不存在外部结点,指向这些外部结点的指针为空,叶子结点的数目正好等于树中所包含的元素总个数加1。下图画出了叶子节点。
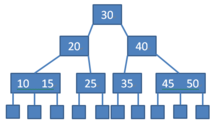
B树的特点可以总结为如下:
- 元素集合分布在整颗树中。
- 任何一个元素出现且只出现在一个节点中。
- 搜索有可能在非叶子节点结束。
- 因为每个节点中的元素和子树都是有序的,其搜索性能等价于在元素集合内做一次二分查找。
- B树在插入删除新的数据记录会破坏B-Tree的性质,因为在插入删除时,需要对树进行一个分裂、合并、转移等操作以保持B-Tree性质。
为什么要使用B-树作为数据库索引而不是使用二叉树?
二叉树的搜索效率是十分高的,可以达到logN,但是由于数据量巨大时,索引的大小甚至可以达到G级别,所以索引是存储在磁盘中的,每次查找只能逐一将索引树的节点加载至内存中,如果使用二叉树则I/O操作将会非常频繁,I/O次数取决于二叉树的深度。这样索引速度非常慢,因此采用B树这种多路二叉搜索树大大减少I/O次数。其中多路指的是一个节点有多个子树,并且由于所有叶子节点都在同一层,因此是平衡树。
磁盘页:查询索引时,逐一加载磁盘页,这里的磁盘页对应索引树的节点,对于m阶B树,m的大小取决于磁盘页的大小。
B+树
m阶B树具有以下几个特征:
1、有k个子树的中间节点包含有k个元素(B树中是k-1个),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点中。
2、所有的叶子结点中包含了全部元素的信息,叶子节点本身根据元素的大小顺序链接。
3、所有的中间节点元素都同时存在子节点,在子节点元素中是最大(或最小)元素。
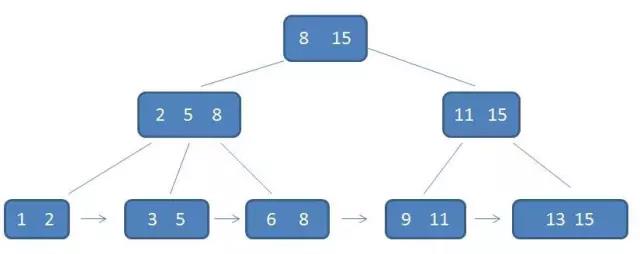
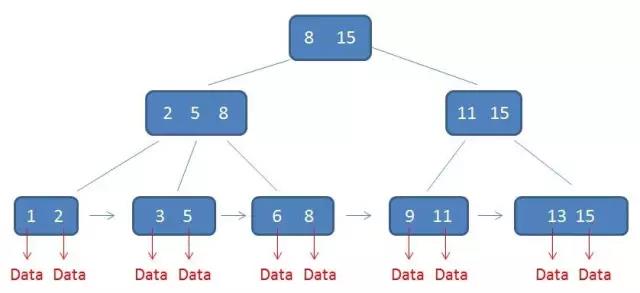
对于根节点中的8,在其子节点中 2 5 8中是最大元素,根节点的最大元素15也是整棵树的最大元素。
什么是卫星数据?
索引元素所指向的数据记录,比如数据库中的某一行。
在B树中无论是中间节点还是叶子节点都带有卫星数据,但是在B+树中只有叶子节点带有卫星数据,中间节点仅仅是索引。左图是B树,右图是B+树。
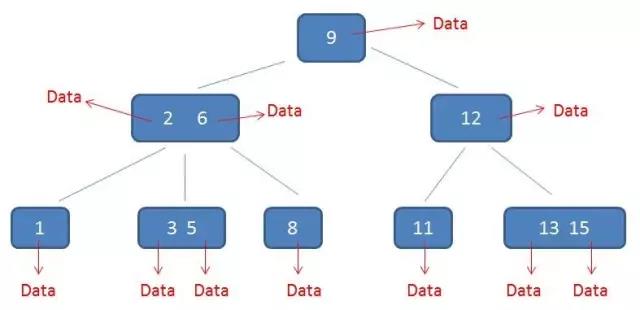
相比B树B+树有以下几点优点:
(1)由于B+树的中间节点没有卫星数据,因此同样大小的磁盘页可以容纳更多的节点元素,即B+树相比B树更加矮胖,因此查询时的I/O次数更少。
(2)由于B树在查找时最好情况是根节点,最差情况是叶子节点;B+树都是查找到叶子节点,所以B+树的查找更加稳定。
(3)对于范围查找,例如查找3-11之间的所有数据,对于B树,查找下限3,然后中序遍历;对于B+树只需要在叶节点链表上遍历即可,范围查找的效率更高。
数据库中的聚集索引中,叶子节点直接包含卫星数据,在非聚集索引中,叶子节点带有指向卫星数据的指针。
B树和B+树原理图文解析的更多相关文章
- 数据结构图文解析之:AVL树详解及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- 伸展树(一)之 图文解析 和 C语言的实现
概要 本章介绍伸展树.它和"二叉查找树"和"AVL树"一样,都是特殊的二叉树.在了解了"二叉查找树"和"AVL树"之后, ...
- 数据结构图文解析之:哈夫曼树与哈夫曼编码详解及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- 数据结构图文解析之:树的简介及二叉排序树C++模板实现.
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- AVL树(一)之 图文解析 和 C语言的实现
概要 本章介绍AVL树.和前面介绍"二叉查找树"的流程一样,本章先对AVL树的理论知识进行简单介绍,然后给出C语言的实现.本篇实现的二叉查找树是C语言版的,后面章节再分别给出C++ ...
- 标准Trie字典树学习一:原理解析
特别声明: 博文主要是学习过程中的知识整理,以便之后的查阅回顾.部分内容来源于网络(如有摘录未标注请指出).内容如有差错,也欢迎指正! 系列文章: 1. 字典树Trie学习一:原理解析 2.字典树Tr ...
- 深入解析浏览器的幕后工作原理(三) 呈现树和 DOM 树的关系
呈现树和 DOM 树的关系 呈现器是和 DOM 元素相对应的,但并非一一对应.非可视化的 DOM 元素不会插入呈现树中,例如"head"元素.如果元素的 display 属性值为& ...
- 【浏览器渲染原理】渲染树构建之渲染树和DOM树的关系(转载 学习中。。。)
在DOM树构建的同时,浏览器会构建渲染树(render tree).渲染树的节点(渲染器),在Gecko中称为frame,而在webkit中称为renderer.渲染器是在文档解析和创建DOM节点后创 ...
- B树和B+树的插入、删除图文详解(good)
B树和B+树的插入.删除图文详解 1. B树 1. B树的定义 B树也称B-树,它是一颗多路平衡查找树.我们描述一颗B树时需要指定它的阶数,阶数表示了一个结点最多有多少个孩子结点,一般用字母m表示阶数 ...
随机推荐
- es date_histogram强制补零
es补零 GET /cars/transactions/_search { "size" : 0, "aggs": { "sales": { ...
- IDEA中三种注释方式的快捷键
三种注释方式 行注释.块注释.方法或类说明注释. 一.快捷键:Ctrl + / 使用Ctrl+ /, 添加行注释,再次使用,去掉行注释 二.演示代码 if (hallSites != null ...
- MySQL统计总数就用count(*),别花里胡哨的《死磕MySQL系列 十》
有一个问题是这样的统计数据总数用count(*).count(主键ID).count(字段).count(1)那个效率高. 先说结论,不用那么花里胡哨遇到统计总数全部使用count(*). 但是有很多 ...
- java自定义序列化
自定义序列化 1.问题引出 在某些情况下,我们可能不想对于一个对象的所有field进行序列化,例如我们银行信息中的设计账户信息的field,我们不需要进行序列化,或者有些field本省就没有实现Ser ...
- pytest框架+conftest.py配置公共数据的准备和清理
1.pytest介绍:1.自动发现测试模块和测试方法 2.断言使用 assert+表达式即可 3.可以设置会话级.模块级.类级.函数级的fixture 数据准备+清理工作 4.丰富的插件库,==all ...
- 安装mysql会出现start service错误
安装MySQL时无法启动服务(could not start the service MYSQL .Error:0)安装mysql会出现start service错误安装mysql时 配置到start ...
- [bzoj4003]城市攻占
倍增,对于每一个点计算他走到$2^i$次祖先所需要的攻击力以及最终会变成什么(一个一次函数),简单处理即可(然而这样是错的,因为他只保证了骑士的攻击力可以存,并没有保证这个一次函数的系数可以存)(其实 ...
- [luogu6860]象棋与马
根据扩欧$(a,b)=1$必须要满足,同时,若$a+b$为偶数则格子的"奇偶性"不变,因此$a+b$必须为奇数 反过来,容易证明满足$(a,b)=1$且$a+b$为奇数则一定可行( ...
- 学习 DDD 之消化知识!
接触到DDD到现在已经有8个月份了,目前所维护的项目也是基于DDD的思想开发的,从一开始的无从下手,到现在游刃有余,学到不少东西,但是都是一些关键字和零散的知识,同时我也感受到了是因为我对项目越来越熟 ...
- FESTUNG — 3. 采用 HDG 方法求解对流问题
FESTUNG - 3. 采用 HDG 方法求解对流问题[1] 1. 控制方程 线性对流问题控制方程为 \[\begin{array}{ll} \partial_t c + \nabla \cdot ...