『无为则无心』Python序列 — 24、Python序列的推导式
推导式comprehensions(又称解析式),是Python的一种独有特性。
推导式是可以从一个数据序列构建另一个新的数据序列(的一种结构体)。
Python中共有三种推导,在Python2和3中都有支持:
- 列表推导式
- 字典推导式
- 集合推导式
1、列表推导式
作用:用一个表达式创建一个有规律的列表或控制一个有规律列表。
列表推导式又叫列表生成式。
(1)快速体验
需求:创建一个0-10的列表。
while循环实现# 1. 准备一个空列表
list1 = [] # 2. 书写循环,依次追加数字到空列表list1中
i = 0
while i < 10:
list1.append(i)
i += 1 # 结果:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(list1)
for循环实现list1 = []
for i in range(10):
list1.append(i)
# 结果:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(list1)
- 列表推导式实现
"""
因为是列表推导式,所以等号右边的表达式要用[]括起来
因为最终要返回一个列表。 在推导式中,读与写都从for循环开始,
for的左侧是一个返回值,一次for循环返回的数值。
for每一次遍历,都向列表中添加一个i变量。
"""
# 结果:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
list1 = [i for i in range(10)]
print(list1)
列表推导式就是化简代码,创建或控制有规律的列表。
(2)带if的列表推导式
需求:创建0-10的偶数列表
- 方法一:通过
range()步长实现# 结果:[0, 2, 4, 6, 8]
list1 = [i for i in range(0, 10, 2)]
print(list1)
- 方法二:通过
if实现# 1. for循环加if 创建有规律的列表
list2 = []
for i in range(10):
if i % 2 == 0:
list2.append(i)
# 结果:[0, 2, 4, 6, 8]
print(list2) # 2.把for循环配合if的代码 改写 带if的列表推导式
list1 = [i for i in range(10) if i % 2 == 0]
# 结果:[0, 2, 4, 6, 8]
print(list1)
(3)多个for循环实现列表推导式
需求,创建列表如下:
[(1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)]
代码如下:
list1 = [(i, j) for i in range(1, 3) for j in range(3)]
print(list1)
# 推导过程如下
# 多for的列表推导式等同于for循环嵌套
# [(1, 0), (1, 1), (1, 2), (2, 0), (2, 1), (2, 2)]
# 数据1 : 1 和 2 range(1,3)
# 数据2 :0 1 2 range(3)
list1 = []
for i in range(1, 3):
for j in range(3):
# 列表里面追加元组: 循环前准备一个空列表,
# 然后这里追加元组数据到列表
list1.append((i, j))
print(list1)
# 多个for实现列表推导式
list2 = [(i, j) for i in range(1, 3) for j in range(3)]
print(list2)
2、字典推导式
思考:如果有如下两个列表:
list1 = ['name', 'age', 'gender']
list2 = ['Tom', 20, 'man']
如何快速合并为一个字典?
答:用for循环拼接可以实现,但是我们可以通过改写for循环,变成一个字典推导式。
字典推导式作用:快速合并列表为字典或提取字典中目标数据。
通过下面示例快速体验字典推导式。
(1)创建一个字典
字典key是1-5数字,value是这个数字的2次方。
# dict1 = {k: v for i in range(1, 5)}
dict1 = {i: i**2 for i in range(1, 5)}
print(dict1) # {1: 1, 2: 4, 3: 9, 4: 16}
{i:i**2}表示的是一个字典,key是i,value是i**2。
最后要返回一个字典,所以右边表达式的最外层是一个大括号。
(2)将两个列表合并为一个字典
list1 = ['name', 'age', 'gender']
list2 = ['Tom', 20, 'man']
dict1 = {list1[i]: list2[i] for i in range(len(list1))}
print(dict1)
# 结果:{'name': 'Tom', 'age': 20, 'gender': 'man'}
总结:
- 如果两个列表数据个数相同,
len统计任何一个列表的长度都可以。- 如果两个列表数据个数不同,
len统计数据多的列表数据个数会报错;len统计数据少的列表数据个数不会报错。(这点一定要注意)
(3)提取字典中目标数据
counts = {'MBP': 268, 'HP': 125, 'DELL': 201, 'Lenovo': 199, 'acer': 99}
# 需求:提取上述电脑数量大于等于200的字典数据
count1 = {key: value for key, value in counts.items() if value >= 200}
print(count1) # {'MBP': 268, 'DELL': 201}
3、集合推导式
集合推导式比上面两个推导式使用的频率要少很多。
需求:创建一个集合,数据为下方列表的2次方。
list1 = [1, 1, 2]
代码如下:
list1 = [1, 1, 2]
set1 = {i ** 2 for i in list1}
print(set1) # {1, 4}
注意:集合有数据去重功能。
4、补充提示
我们如何查看Python中关于序列的相关文档:
- 打开文件找到序列部分文档
[The Python Standard Library(Python标准库)] —> 右边页面[Sequence Type]
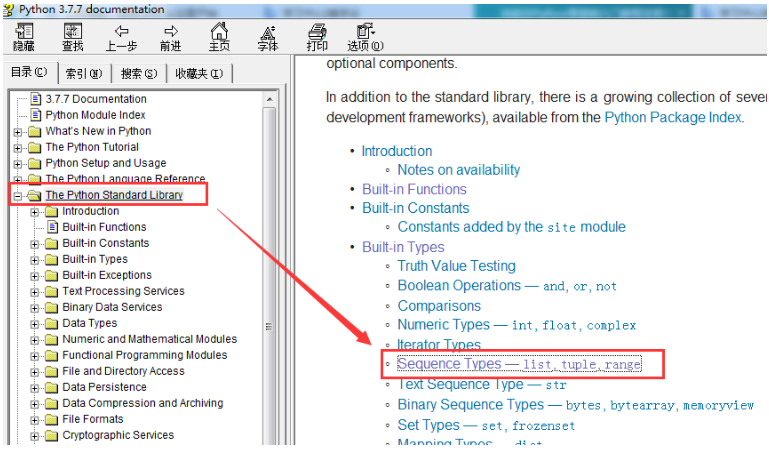
Common Sequence Operations下的列表为序列的通用操作。
就是可变序列和不可变序列都可以用的方法或者函数。Mutable Sequence Types下的列表为可变序列可以用的方法或者函数。
『无为则无心』Python序列 — 24、Python序列的推导式的更多相关文章
- 『无为则无心』Python基础 — 16、Python序列之字符串的下标和切片
目录 1.序列的概念 2.字符串的下标说明 3.字符串的切片说明 1.序列的概念 序列sequence是Python中最基本的数据结构.指的是一块可存放多个值的连续内存空间,这些值按一定顺序排列,可通 ...
- 『无为则无心』Python序列 — 20、Python元组的介绍与使用
目录 1.元组的应用场景 2.定义元组 3.元组的常见操作 @1.按下标查找数据 @2.index()方法 @3.count()方法 @4.len()方法 4.元祖中的列表元素 5.扩展:序列封包和序 ...
- 『无为则无心』Python基础 — 12、Python运算符详细介绍
目录 1.表达式介绍 2.运算符 (1)运算符的分类 (2)算数运算符 (3)赋值运算符 (4)复合赋值运算符 (5)比较运算符 3.逻辑运算符 拓展1:数字之间的逻辑运算 拓展2:Python中逻辑 ...
- 『无为则无心』Python基础 — 61、Python中的迭代器
目录 1.迭代的概念 2.迭代器的概念 3.可迭代的对象(Iterable) 4.迭代器对象(Iterator) 5.迭代器的使用体验 (1)基本用法 (2)实际应用 1.迭代的概念 (1)什么是迭代 ...
- 『无为则无心』Python基础 — 62、Python中自定义迭代器
目录 1.迭代器对象的创建 2.实际应用案例 3.总结: 1.迭代器对象的创建 迭代器是一种可以被遍历的对象,并且能够作用于next()函数,迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问 ...
- 『无为则无心』Python基础 — 63、Python中的生成器
目录 1.为什么要有生成器 2.创建生成器 (1)简单创建生成器 (2)生成器的使用 3.yield关键词 (1)yield关键词说明 (2)send()方法说明 4.使用yield实现斐波那契数列 ...
- 『无为则无心』Python基础 — 4、Python代码常用调试工具
目录 1.Python的交互模式 2.IDLE工具使用说明 3.Sublime3工具的安装与配置 (1)Sublime3的安装 (2)Sublime3的配置 4.使用Sublime编写并调试Pytho ...
- 『无为则无心』Python基础 — 6、Python的注释
目录 1.注释的作用 2.注释的分类 单行注释 多行注释 3.注释的注意事项 4.什么时候需要使用注释 5.总结 提示:完成了前面的准备工作,之后的文章开始介绍Python的基本语法了. Python ...
- 『无为则无心』Python基础 — 7、Python的变量
目录 1.变量的定义 2.Python变量说明 3.Python中定义变量 (1)定义语法 (2)标识符定义规则 (3)内置关键字 (4)标识符命名习惯 4.使用变量 1.变量的定义 程序中,数据都是 ...
随机推荐
- 使用 dd 命令进行硬盘 I/O 性能检测
使用 dd 命令进行硬盘 I/O 性能检测 作者: Vivek Gite 译者: LCTT DongShuaike | 2015-08-28 07:30 评论: 1 收藏: 6 如何使用dd命令测 ...
- VIM 三种模式和常用命令
引言 大数据开发工作中,周围的同事不是用 VIM 就是 Emacs,你要是用 UltraEdit 或 notepad++ 都不好意思跟人家打招呼...什么插件呀.语法高亮呀.拼写检查呀,能给它开的都给 ...
- scrapy奇技淫巧1
Request传递值到callback回调函数 def parse(self, response): request = scrapy.Request('http://www.example.com/ ...
- 基于 BDD 理论的 Nebula 集成测试框架重构(上篇)
本文首发于 Nebula Graph 公众号 NebulaGraphCommunity,Follow 看大厂图数据库技术实践. 测试框架的演进 截止目前为止,在 Nebula Graph 的开发过程中 ...
- C 语言通用模板队列
前言 嵌入式开发过程中,各个模块之间,各个设备之间进行交互时,都会存在数据的输入输出,由于处理的方式不同,数据不会立即同步处理,因此通常在设计时都会设计缓冲区进行数据的处理,方式数据丢失等问题:一个项 ...
- Go语言网络通信---string与int互转,int64与[]byte互转,int直接互转,string与[]byte互转
string与int互转 #string到int int,err:=strconv.Atoi(string) #string到int64 int64, err := strconv.ParseInt( ...
- 七、Numpy高效数据处理
Numpy的主要作用是进行矩阵运算 在使用时首先要导入包 import numpy as np np.version.version 用来查看版本信息 # 构建一维数组 n1=np.array([1, ...
- 第四代自动泊车从APA到AVP技术
第四代自动泊车从APA到AVP技术 前言 自动泊车是指汽车自动泊车入位不需要人工控制,系统能够自动帮你将车辆停入车位,在倒车入库中可谓是驾驶者的一项利器.当我们找到一个理想的停车地点,只需轻轻启动按钮 ...
- NVIDIA Nsight Systems CUDA 跟踪
NVIDIA Nsight Systems CUDA 跟踪 CUDA跟踪 NVIDIA Nsight Systems能够捕获有关在概要过程中执行CUDA的信息. 可以在报告的时间轴上收集和呈现以下信息 ...
- 转置卷积Transposed Convolution
转置卷积Transposed Convolution 我们为卷积神经网络引入的层,包括卷积层和池层,通常会减小输入的宽度和高度,或者保持不变.然而,语义分割和生成对抗网络等应用程序需要预测每个像素的值 ...