提取网页的markdown表格利器
在线Markdown表格转换器
markdown表格转换器,蛮好用的。偶然发现的开源工具,推荐一波。
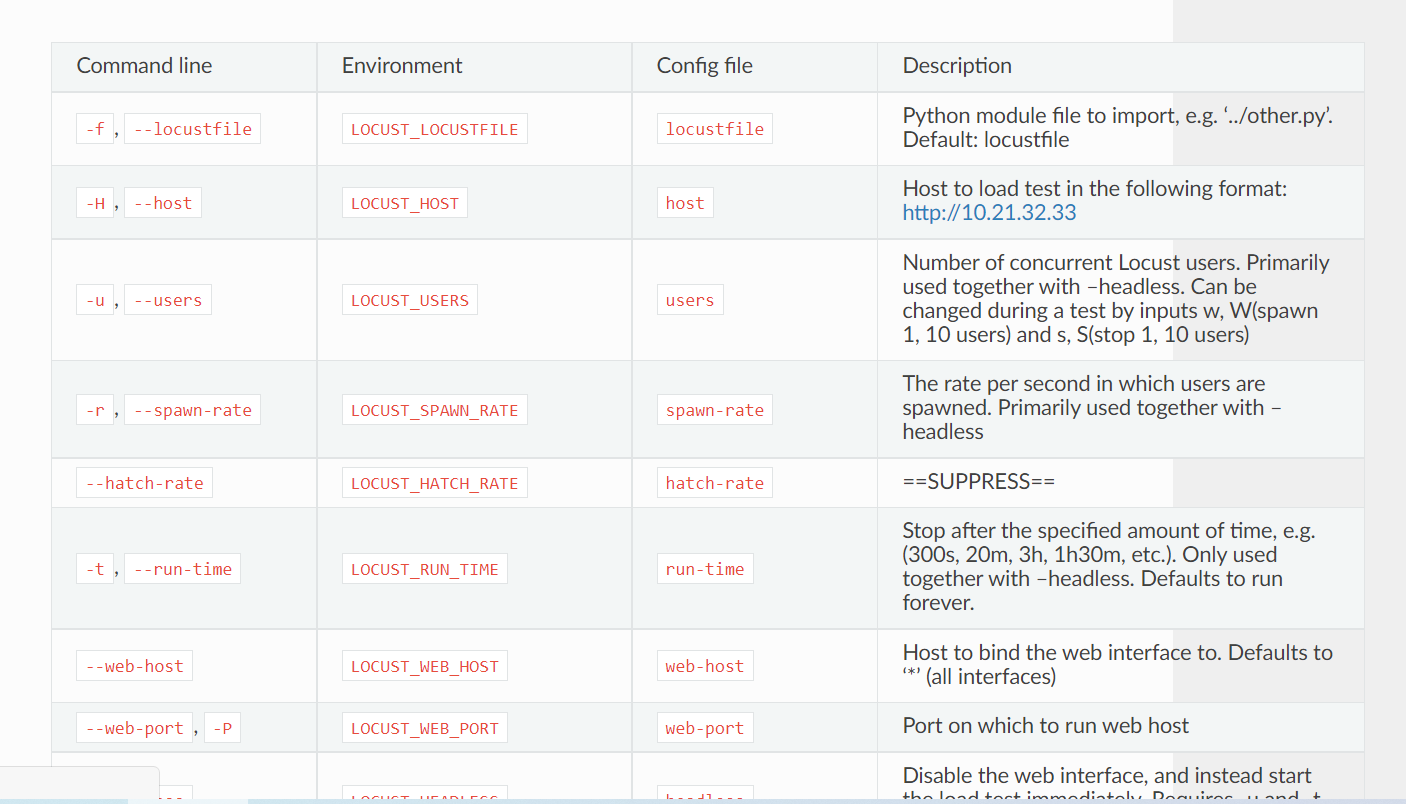
这是待提取table项
尝试1,直接通过html导入的功能
导入方法
import→URL→贴入复制的url→点击parse→往下拖动点击import data→把结果栏生成的结果copy到markdown
具体可见下面的GIF图嘞
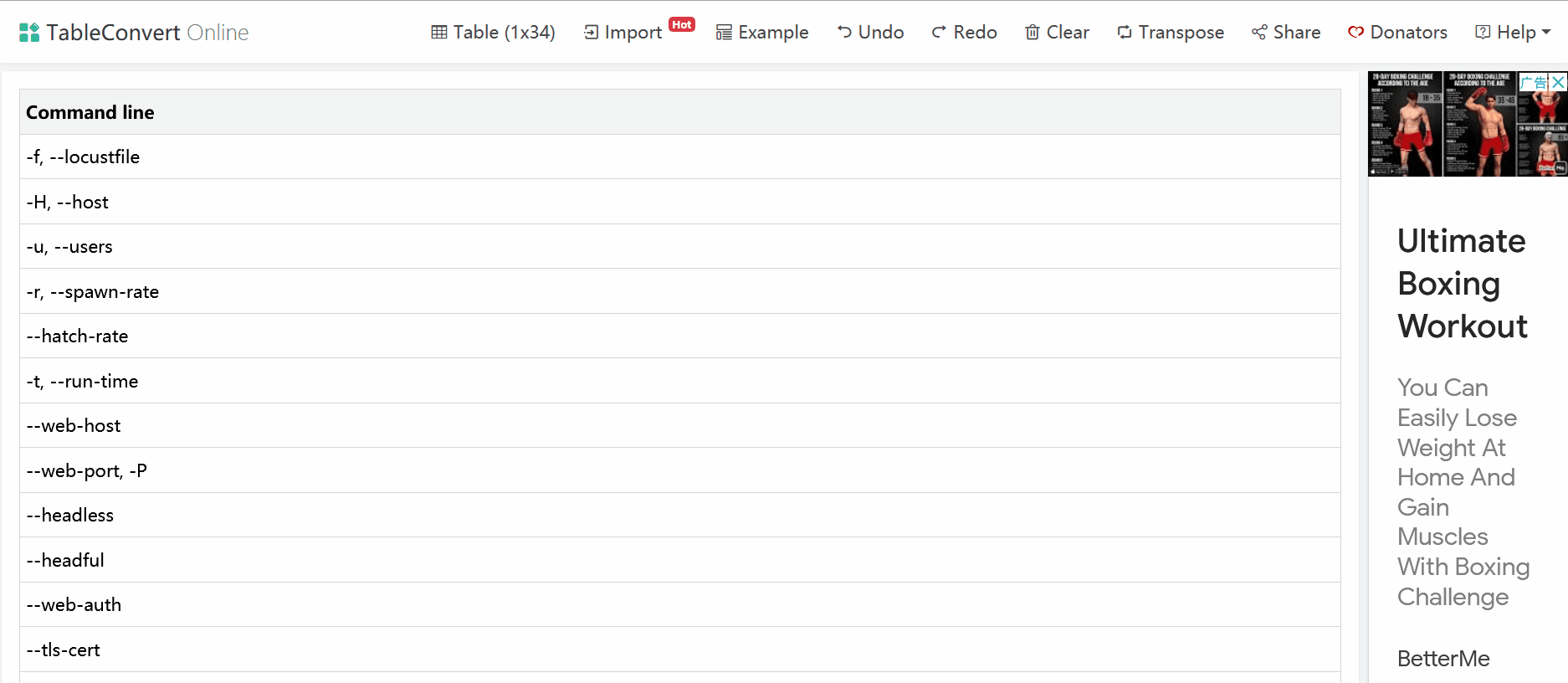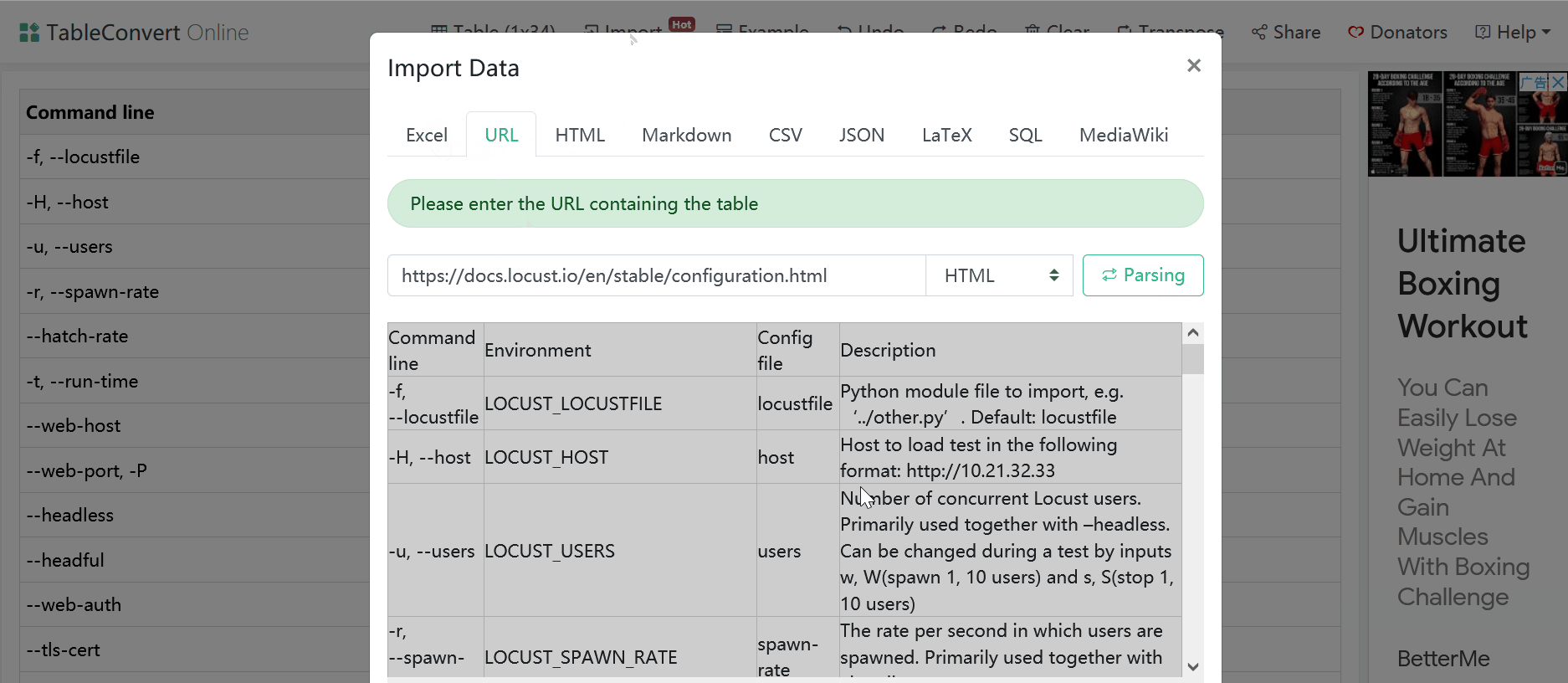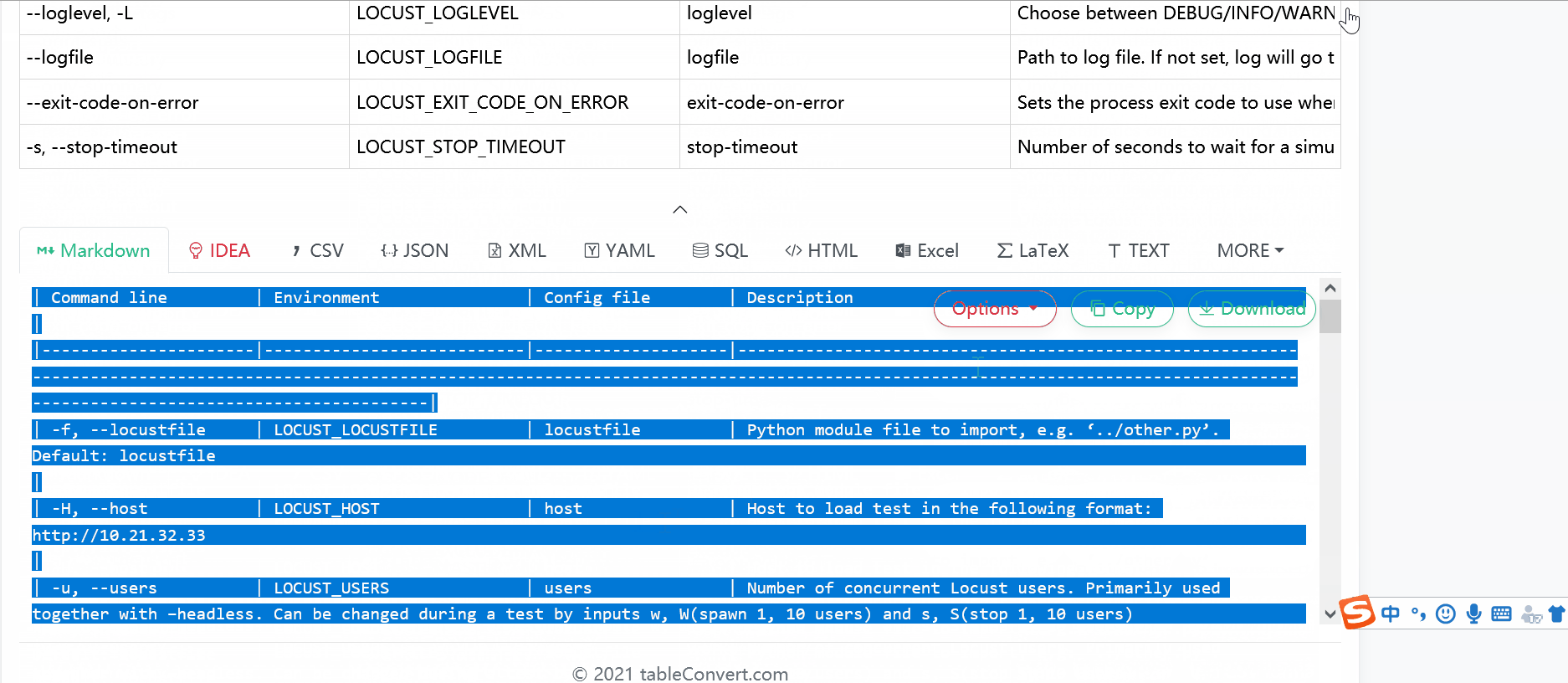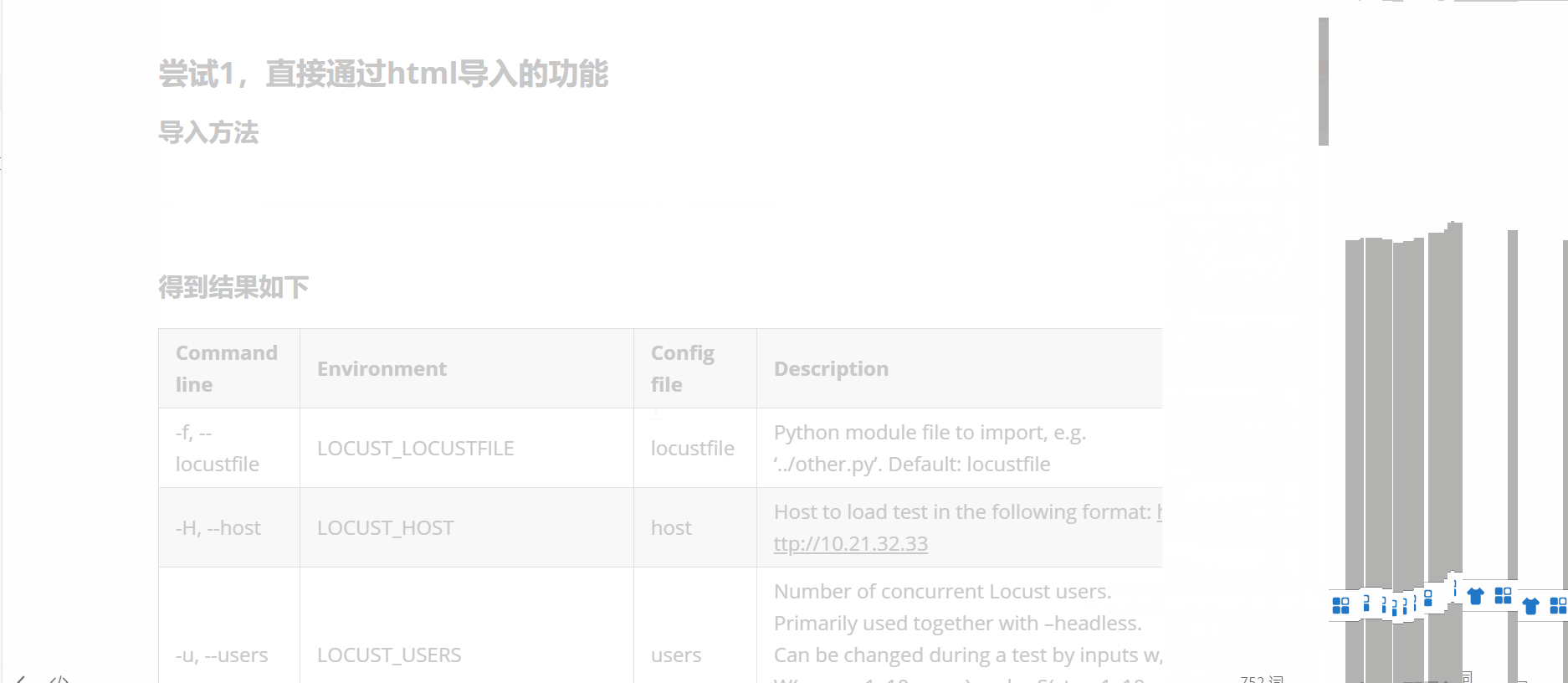
得到结果如下
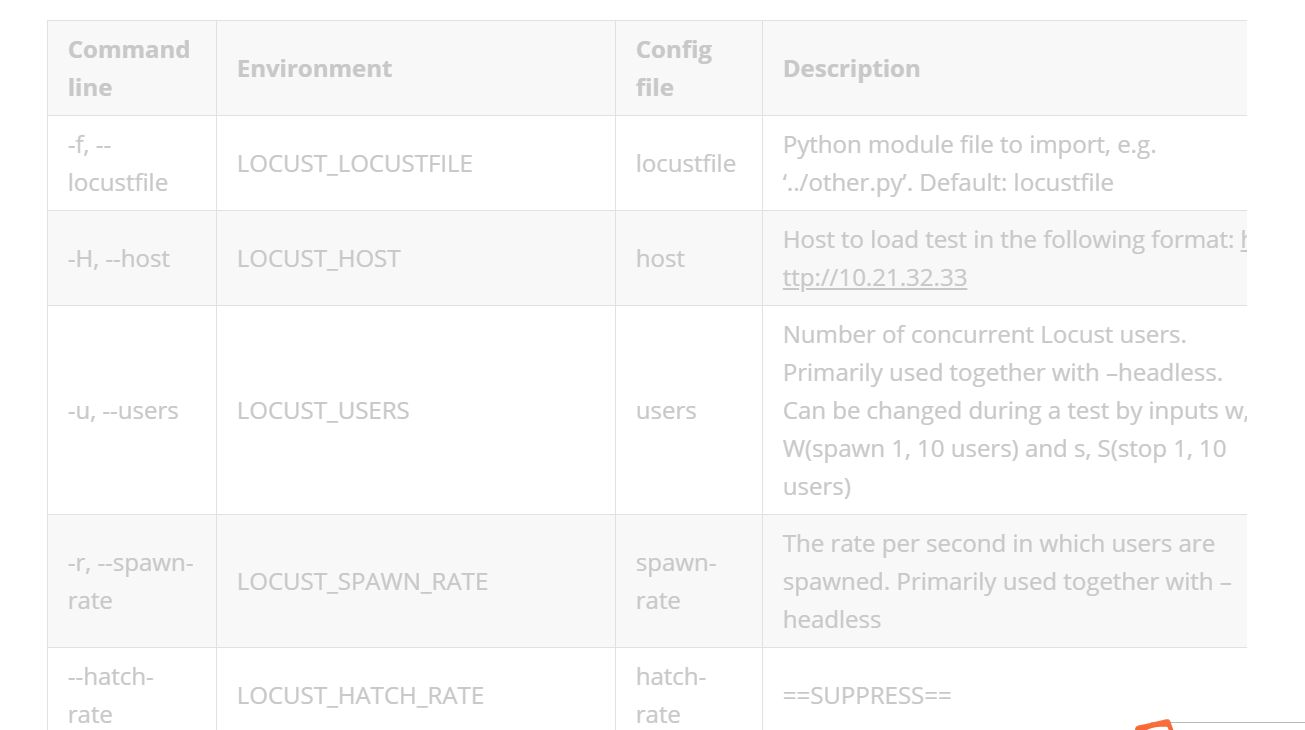
尝试2:通过源码导入
导入方法
首先点击目标网页,右键→检查→选择页面中的元素(选择到table对应的元素)→复制table对应的html内容
import→HTML→贴入上一步复制的→import data→把结果栏生成的结果copy到markdown
具体可见下面的GIF图嘞
 、
、
得到结果如下
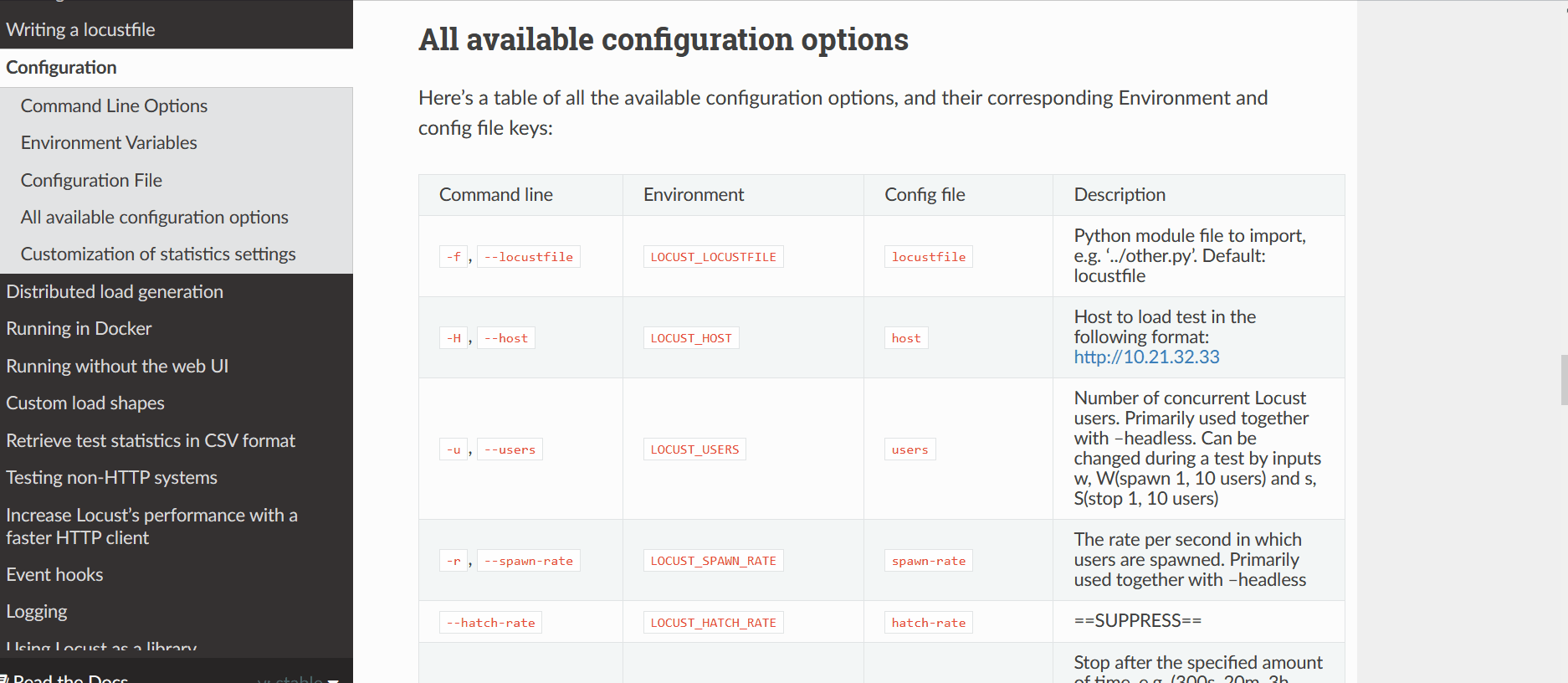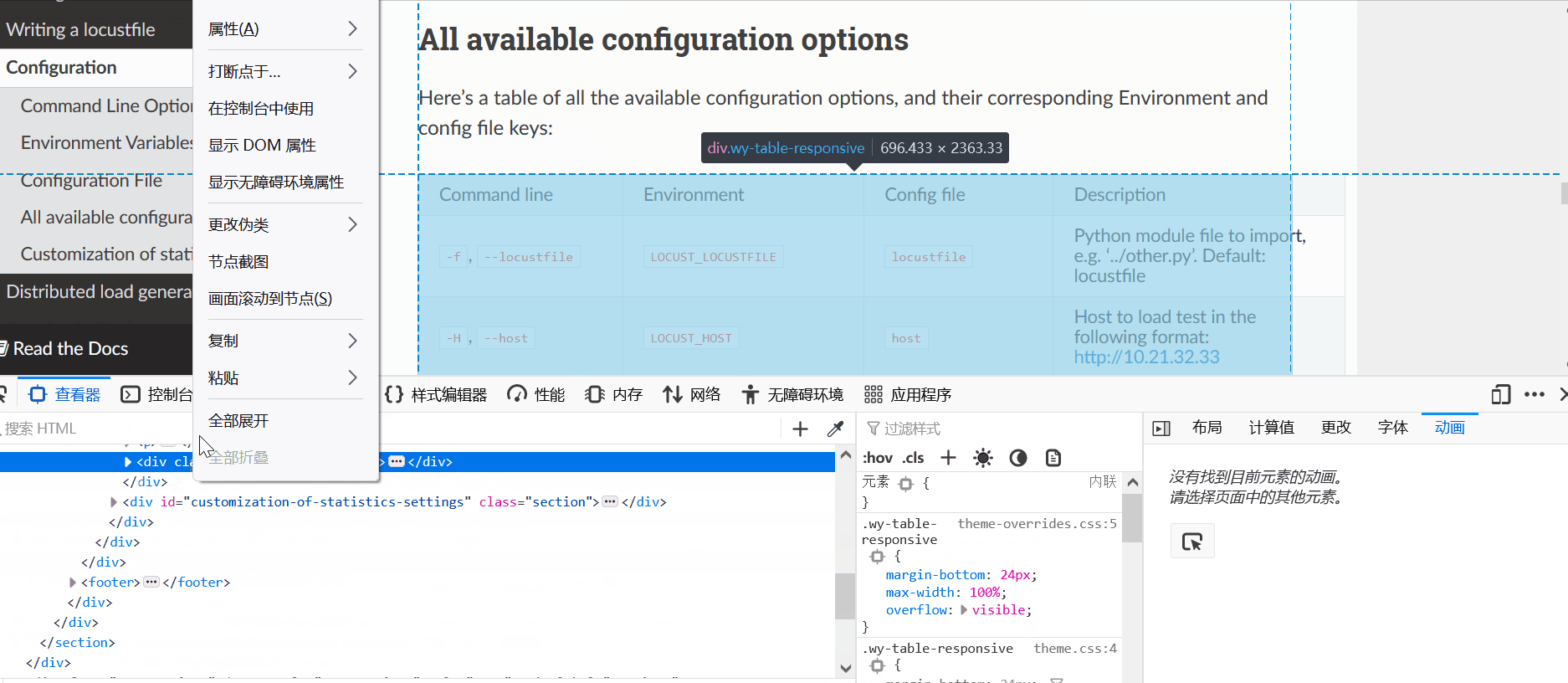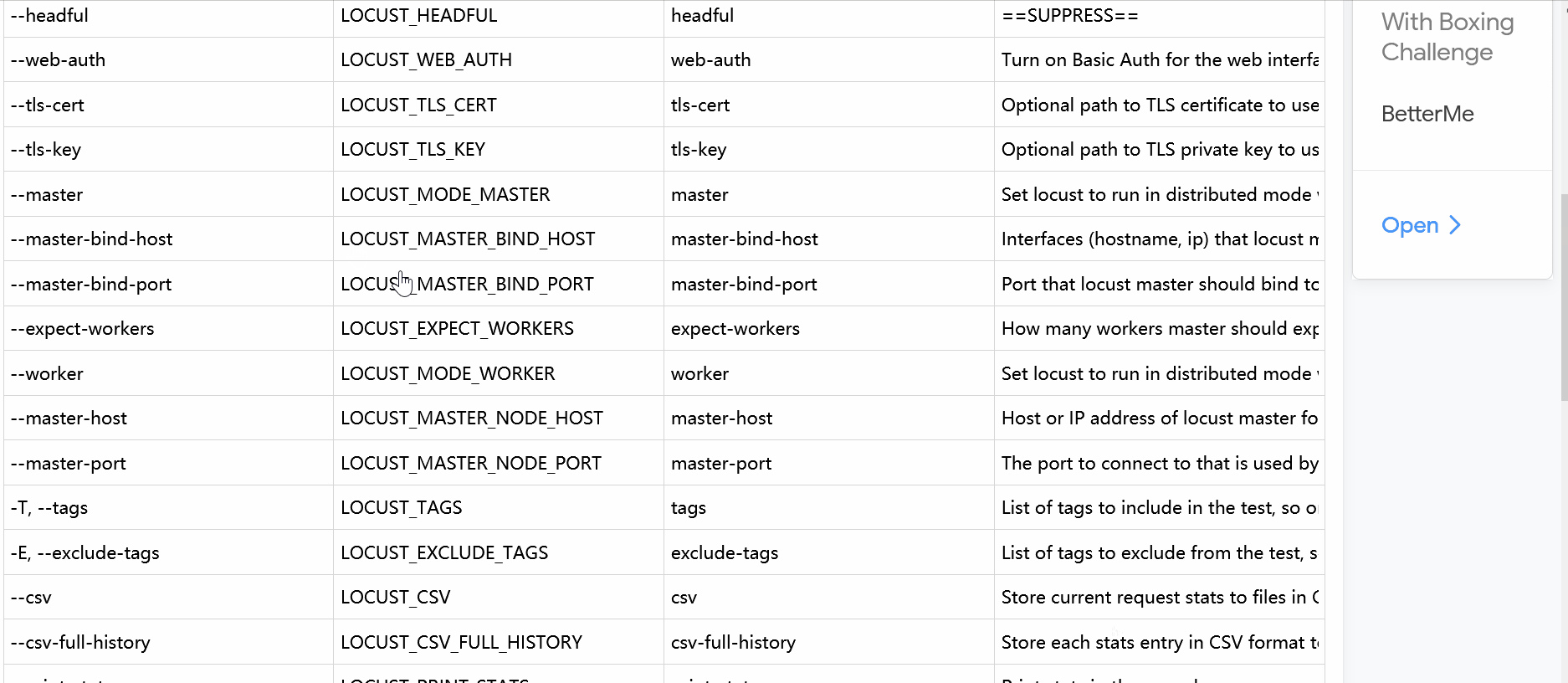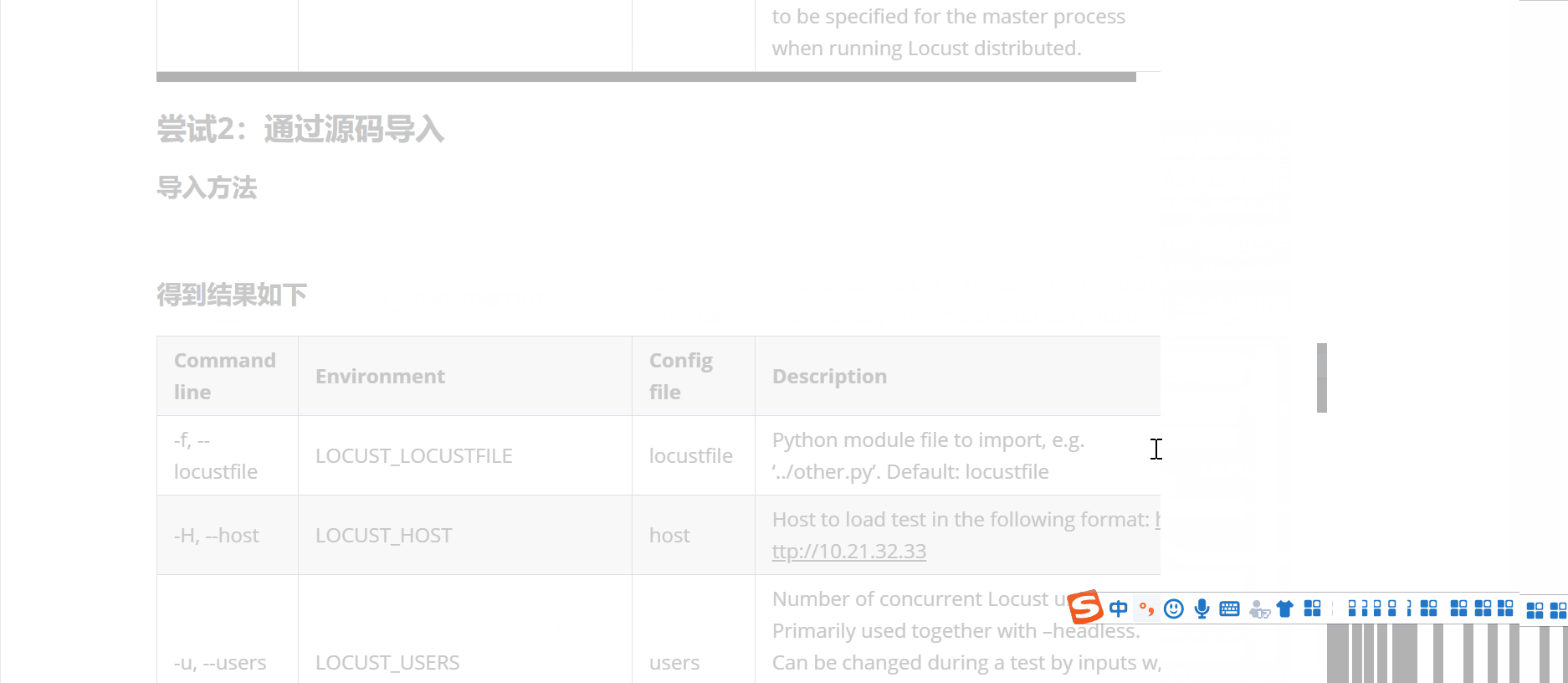
| Command line | Environment | Config file | Description |
|---|---|---|---|
| -f, --locustfile | LOCUST_LOCUSTFILE | locustfile | Python module file to import, e.g. ‘../other.py’. Default: locustfile |
| -H, --host | LOCUST_HOST | host | Host to load test in the following format: http://10.21.32.33 |
| -u, --users | LOCUST_USERS | users | Number of concurrent Locust users. Primarily used together with –headless. Can be changed during a test by inputs w, W(spawn 1, 10 users) and s, S(stop 1, 10 users) |
| -r, --spawn-rate | LOCUST_SPAWN_RATE | spawn-rate | The rate per second in which users are spawned. Primarily used together with –headless |
| --hatch-rate | LOCUST_HATCH_RATE | hatch-rate | ==SUPPRESS== |
| -t, --run-time | LOCUST_RUN_TIME | run-time | Stop after the specified amount of time, e.g. (300s, 20m, 3h, 1h30m, etc.). Only used together with –headless. Defaults to run forever. |
| --web-host | LOCUST_WEB_HOST | web-host | Host to bind the web interface to. Defaults to ‘*’ (all interfaces) |
| --web-port, -P | LOCUST_WEB_PORT | web-port | Port on which to run web host |
| --headless | LOCUST_HEADLESS | headless | Disable the web interface, and instead start the load test immediately. Requires -u and -t to be specified. |
| --headful | LOCUST_HEADFUL | headful | ==SUPPRESS== |
| --web-auth | LOCUST_WEB_AUTH | web-auth | Turn on Basic Auth for the web interface. Should be supplied in the following format: username:password |
| --tls-cert | LOCUST_TLS_CERT | tls-cert | Optional path to TLS certificate to use to serve over HTTPS |
| --tls-key | LOCUST_TLS_KEY | tls-key | Optional path to TLS private key to use to serve over HTTPS |
| --master | LOCUST_MODE_MASTER | master | Set locust to run in distributed mode with this process as master |
| --master-bind-host | LOCUST_MASTER_BIND_HOST | master-bind-host | Interfaces (hostname, ip) that locust master should bind to. Only used when running with –master. Defaults to * (all available interfaces). |
| --master-bind-port | LOCUST_MASTER_BIND_PORT | master-bind-port | Port that locust master should bind to. Only used when running with –master. Defaults to 5557. |
| --expect-workers | LOCUST_EXPECT_WORKERS | expect-workers | How many workers master should expect to connect before starting the test (only when –headless used). |
| --worker | LOCUST_MODE_WORKER | worker | Set locust to run in distributed mode with this process as worker |
| --master-host | LOCUST_MASTER_NODE_HOST | master-host | Host or IP address of locust master for distributed load testing. Only used when running with –worker. Defaults to 127.0.0.1. |
| --master-port | LOCUST_MASTER_NODE_PORT | master-port | The port to connect to that is used by the locust master for distributed load testing. Only used when running with –worker. Defaults to 5557. |
| -T, --tags | LOCUST_TAGS | tags | List of tags to include in the test, so only tasks with any matching tags will be executed |
| -E, --exclude-tags | LOCUST_EXCLUDE_TAGS | exclude-tags | List of tags to exclude from the test, so only tasks with no matching tags will be executed |
| --csv | LOCUST_CSV | csv | Store current request stats to files in CSV format. Setting this option will generate three files: [CSV_PREFIX]stats.csv, [CSV_PREFIX]stats_history.csv and [CSV_PREFIX]_failures.csv |
| --csv-full-history | LOCUST_CSV_FULL_HISTORY | csv-full-history | Store each stats entry in CSV format to _stats_history.csv file. You must also specify the ‘–csv’ argument to enable this. |
| --print-stats | LOCUST_PRINT_STATS | print-stats | Print stats in the console |
| --only-summary | LOCUST_ONLY_SUMMARY | only-summary | Only print the summary stats |
| --reset-stats | LOCUST_RESET_STATS | reset-stats | Reset statistics once spawning has been completed. Should be set on both master and workers when running in distributed mode |
| --html | LOCUST_HTML | html | Store HTML report file |
| --skip-log-setup | LOCUST_SKIP_LOG_SETUP | skip-log-setup | Disable Locust’s logging setup. Instead, the configuration is provided by the Locust test or Python defaults. |
| --loglevel, -L | LOCUST_LOGLEVEL | loglevel | Choose between DEBUG/INFO/WARNING/ERROR/CRITICAL. Default is INFO. |
| --logfile | LOCUST_LOGFILE | logfile | Path to log file. If not set, log will go to stdout/stderr |
| --exit-code-on-error | LOCUST_EXIT_CODE_ON_ERROR | exit-code-on-error | Sets the process exit code to use when a test result contain any failure or error |
| -s, --stop-timeout | LOCUST_STOP_TIMEOUT | stop-timeout | Number of seconds to wait for a simulated user to complete any executing task before exiting. Default is to terminate immediately. This parameter only needs to be specified for the master process when running Locust distributed. |
提取网页的markdown表格利器的更多相关文章
- 如何将Excel转换成Markdown表格[转]
在这篇文章中,我将告诉你如何快速的将Excel转换为markdown表格,以及如何将Google Docs,Numbers,网页中的表格或其他类似Excel的程序数据转换为Markdown表格 你可能 ...
- python笔记之提取网页中的超链接
python笔记之提取网页中的超链接 对于提取网页中的超链接,先把网页内容读取出来,然后用beautifulsoup来解析是比较方便的.但是我发现一个问题,如果直接提取a标签的href,就会包含jav ...
- markdown表格
markdown制作表格 一. 使用原生html表格标签制作 <table> <tr> <td>表头</td> </tr> <tr&g ...
- vim格式化markdown表格
title: vim格式化markdown表格 date: 2017-11-23 15:23:25 tags: vim categories: 开发工具 安装插件 https://github.com ...
- python学习笔记——爬虫中提取网页中的信息
1 数据类型 网页中的数据类型可分为结构化数据.半结构化数据.非结构化数据三种 1.1 结构化数据 常见的是MySQL,表现为二维形式的数据 1.2 半结构化数据 是结构化数据的一种形式,并不符合关系 ...
- 用 Excel 生成和管理 Markdown 表格--转载
Markdown 作为一种轻量级的标记语言,用来进行简单的文本排版,确实方便快捷.但 Markdown 标记语言的属性,也使得其在表格处理上略显繁琐且不直观.而 Excel 几乎就是表格的代名词,借助 ...
- chrome浏览器提取网页视频
http://blog.csdn.net/pipisorry/article/details/37728839 在我们平时上网看视频听音乐时都会产生缓存,可是我们非常难通过一些软件把当中的视频和音乐文 ...
- excel批量提取网页标题
最近时间比较忙,有时候很多网页需要临时保存,以便空闲的时候查看.单纯的保存网页链接会让人很枯燥,所以需要自动批量提取标题. 为了这个小功能去写个小程序有点不划算,所以就利用excel实现了这个功能. ...
- Markdown表格宽度调整
Markdown 表格默认宽度是根据内容来的,如果某一列内容很长的话会将其他列的宽度占用导致显示样式很丑.我们可以在表格前增加 CSS 样式来限制列的宽度: <style> table t ...
随机推荐
- Maven:Maven的project标签报错红线
作者在外网完成demo项目,把Maven的本地库打成压缩包放进内网时,Maven的project标签报错红线,且别的依赖不报错,同时Maven不引入本地仓库的依赖包. 解决方法: 进入自己的Maven ...
- sublime最全笔记
sublime骨架建立 1 <!DOCTYPE html> 2 <html> 3 <head> 4 <meta charset="utf-8&quo ...
- Ubuntu命令总结
sudo apt-get update 系统更新 shutdown -h now 关闭服务器 shutdown -r now 重启服务器 uname -a ubuntu中查看内核版本的命令 gedit ...
- 【分布式】CAP理论及其应用
CAP Theorem CAP 指的就是 "consistency 一致性","availability 可用性" "partition-tolera ...
- C语言:读写TXT
fopen() 改为: if((fp=fopen("1s.txt","w+"))==NULL) fputc(p,fp); 改为:fprintf(fp," ...
- python 得到字典的所有键 和值
a={} a={"a":1,"b":2,"c":3,"d":4} print(a) print(a.items()) p ...
- final修饰符(2)
final局部变量 系统不会对局部变量进行初始化,局部变量必须又程序员显示初始化,因此使用final修饰局部变量,可以在声明时指定默认值,也可以在后面的代码中对该final变量赋初始值,但只能赋值一次 ...
- 【转载】SpringMVC学习笔记
转载于:SpringMVC笔记 SpringMVC 1.SpringMVC概述 MVC: Model(模型): 数据模型,提供要展示的数据,:Value Object(数据Dao) 和 服务层(行为S ...
- Appium -- adb monkey操作(一)
1.Monkey简介在Android的官方自动化测试领域有一只非常著名的"猴子"叫Monkey,这只"猴子"一旦启动,就会让被测的Android应用程序像猴子一 ...
- 货币兑换问题(贪心法)——Python实现
# 贪心算法求解货币兑换问题 # 货币系统有 n 种硬币,面值为 v1,v2,v3...vn,其中 v1=1,使用总值money与之兑换,求如何使硬币的数目最少,即 x1,x2,x3...xn 之 ...