(二)基于商品属性的相似商品推荐算法——Flink SQL实时计算实现商品的隐式评分
系列随笔:
(二)基于商品属性的相似商品推荐算法——Flink SQL实时计算实现商品的隐式评分
(三)基于商品属性的相似商品推荐算法——批量处理商品属性,得到属性前缀及完整属性字符串
(四)基于商品属性的相似商品推荐算法——推荐与评分高的商品属性相似的商品
2020.04.15 补充:协同过滤推荐算法.pptx
提取码:4tds
注:如果你没有使用日志埋点和实时计算(接口直接累计也是可行的),你可以直接跳到这一节~
Flink SQL实时计算实现商品的隐匿评分
一、导入log service日志源表

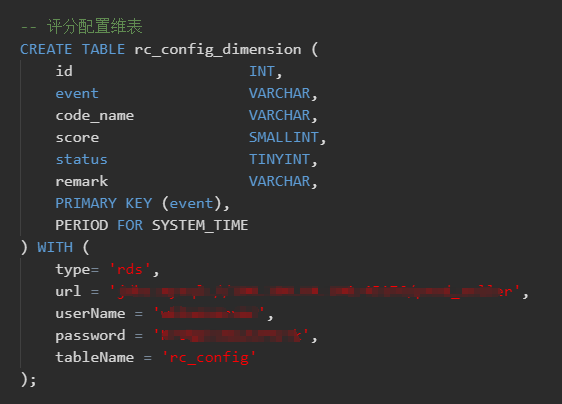
二、导入评分配置维度表(用户行为的评分配置)
三、导入用户商品评分维表

四、用户评分结果表

四、预处理日志数据
-- 处理日志数据
CREATE VIEW probe_log0_view AS
SELECT
t1.cid,
CAST(memberCode as INT) as memberCode,
t1.event,
t1.eventApp,
TO_TIMESTAMP(CAST(CAST(__timestamp__ as DOUBLE) as BIGINT)*1000) as eventTime,
CAST(IF (SUBSTRING(t1.eventProps,0,1)='%', REGEXP_EXTRACT(t1.eventProps, concat(t2.code_name,'\\%22:(\\d+),'), 1), JSON_VALUE (t1.eventProps, concat('$.',t2.code_name))) as INT) as goodsCode,
t2.score
FROM
probe_log0 t1
LEFT JOIN rc_config_dimension FOR SYSTEM_TIME AS OF PROCTIME() AS t2
ON t1.event=t2.event AND t2.status=1
WHERE
t1.event IN ('viewGoods','shareGoods','collectGoods','addToCart');
注:eventProps为埋点的扩展json数据,因为小程序的埋点不太规范,所以加了额外的判断;正常来说,直接使用 JSON_VALUE 函数即可
五、写入结果表
-- 入库
INSERT INTO rc_member_goods
(member_code,
cid,
goods_code,
score,
update_time)
SELECT
t1.memberCode,
t1.cid,
t1.goodsCode,
CAST(IF(t2.score IS NOT NULL, t2.score, 0) + SUM(t1.score) as INT) AS score,
MAX(t1.eventTime) as update_time
FROM
probe_log0_view t1
LEFT JOIN rc_member_goods_dimension FOR SYSTEM_TIME AS OF PROCTIME() AS t2
ON t1.memberCode=t2.member_code AND t1.cid=t2.cid AND t1.goodsCode=t2.goods_code
WHERE
t1.goodsCode IS NOT NULL
AND (t1.eventTime > t2.update_time OR t2.update_time IS NULL)
GROUP BY
t1.memberCode,
t1.cid,
t1.goodsCode,
t2.score;
注:这里的难点在于 CAST(IF(t2.score IS NOT NULL, t2.score, 0) + SUM(t1.score) as INT) AS score 和 AND (t1.eventTime > t2.update_time OR t2.update_time IS NULL)
意思是:如果rc_member_goods表中没有记录的,就直接加入;如果 rc_member_goods 中有记录的,则判断 eventTime 是否大于 上前的更新时间(防止重复更新),最后累计上当前的日志分
PS:如果没有 t2.update_time IS NULL 则左连接会变成 left outer join
上一节:(一)基于商品属性的相似商品推荐算法——整体框架及处理流程
下一节:(三)基于商品属性的相似商品推荐算法——批量处理商品属性,得到属性前缀及完整属性字符串
(二)基于商品属性的相似商品推荐算法——Flink SQL实时计算实现商品的隐式评分的更多相关文章
- 美团网基于机器学习方法的POI品类推荐算法
美团网基于机器学习方法的POI品类推荐算法 前言 在美团商家数据中心(MDC),有超过100w的已校准审核的POI数据(我们一般将商家标示为POI,POI基础信息包括:门店名称.品类.电话.地址.坐标 ...
- mysql颠覆实战笔记(六)--商品系统设计(三):商品属性设计之固定属性
今天我们来讲一下商品属性 我们知道,不同类别的商品属性是不同的. 我们先建一个表prod_class_attr:
- SparkMLlib—协同过滤推荐算法,电影推荐系统,物品喜好推荐
SparkMLlib-协同过滤推荐算法,电影推荐系统,物品喜好推荐 一.协同过滤 1.1 显示vs隐式反馈 1.2 实例介绍 1.2.1 数据说明 评分数据说明(ratings.data) 用户信息( ...
- [推荐]ORACLE PL/SQL编程之四:把游标说透(不怕做不到,只怕想不到)
原文:[推荐]ORACLE PL/SQL编程之四:把游标说透(不怕做不到,只怕想不到) [推荐]ORACLE PL/SQL编程之四: 把游标说透(不怕做不到,只怕想不到) 继上两篇:ORACLE PL ...
- 基于Kafka的实时计算引擎如何选择?Flink or Spark?
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
- 基于Kafka的实时计算引擎如何选择?(转载)
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
- SQL自连接(源于推荐算法中的反查表问题)
”基于用户的协同过滤算法“是推荐算法的一种,这类算法强调的是:把和你有相似爱好的其他的用户的物品推荐给你. 要实现该推荐算法,就需要计算和你有交集的用户,这就要用到物品到用户的反查表. 先举个例子说明 ...
- SimRank协同过滤推荐算法
在协同过滤推荐算法总结中,我们讲到了用图模型做协同过滤的方法,包括SimRank系列算法和马尔科夫链系列算法.现在我们就对SimRank算法在推荐系统的应用做一个总结. 1. SimRank推荐算法的 ...
- 用Spark学习矩阵分解推荐算法
在矩阵分解在协同过滤推荐算法中的应用中,我们对矩阵分解在推荐算法中的应用原理做了总结,这里我们就从实践的角度来用Spark学习矩阵分解推荐算法. 1. Spark推荐算法概述 在Spark MLlib ...
随机推荐
- alipay 小程序开发教程
alipay 小程序开发教程 https://opendocs.alipay.com/mini/00ccmd 或访问开放平台:https://opendocs.alipay.com/mini/00cc ...
- css grid layout in practice
css grid layout in practice https://caniuse.com/#search=grid subgrid https://caniuse.com/#search=cal ...
- lms微服务框架介绍
lms 框架简介 Lms是一个旨在通过.net平台快速构建微服务开发的框架.具有稳定.安全.高性能.易扩展.使用方便的特点.lms内部通过dotnetty实现高性能的rpc通信,使用zookeeper ...
- 按键显示器(判断键盘监听器获得的值为普通Key还中modifiers)
1 import sys 2 from PyQt5 import QtWidgets,QtCore 3 from PyQt5.QtCore import Qt 4 from PyQt5.uic.pro ...
- Django Admin后台管理功能使用+二次开发
一 使用环境 开发系统: windows IDE: pycharm 数据库: msyql,navicat 编程语言: python3.7 (Windows x86-64 executable in ...
- SpringBoot2.1整合Mybatis-Generator以及tk.mybatis
1:添加依赖 <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http ...
- JAVA基础(零)—— 踩坑与错误(常更)
JAVA基础(零)-- 踩坑与错误(常更) 1 坑 考虑输入为null的情况 自动转换 x/Math.pow(10,i)*Math.pow(10,i) //由于math.pow()返回double类型 ...
- JavaScript 模拟 sleep
用 JS 实现沉睡几秒后再执行,有好几种方式,但都不完美,以下是我感觉比较好的一种方式 function sleep(time) { return new Promise((resolve) => ...
- 在Arch上使用Fcitx5
目录 卸载Fcitx4 安装Fcitx5 配置 修改环境变量 系统登陆后默认启动Fcitx5输入法 配置主题 最终使用效果 参考文档 我是一个Arch+KDE的用户,所以下面的方法可能不适合所有的Li ...
- SpringCloud-服务与注册
SpringCloud- Eureka服务注册与发现 1.概述 springcloud是一个非常优秀的微服务框架,要管理众多的服务,就需要对这些服务进行治理,管理每个服务与每个服务之间的依赖关系,可以 ...