Flink sql 之 join 与 StreamPhysicalJoinRule (源码解析)
源码分析基于flink1.14
Join是flink中最常用的操作之一,但是如果滥用的话会有很多的性能问题,了解一下Flink源码的实现原理是非常有必要的
本文的join主要是指flink sql的Regular join 也就是平时我们的双流join中普通的full join ,left join,right join
先找到calcite的relNode转换rule
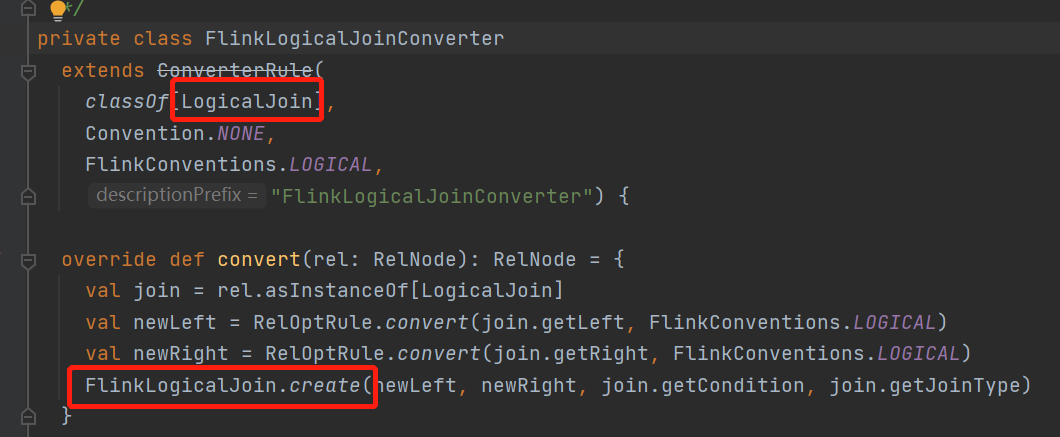
会将逻辑节点logiceJoin转换成flink的FlinkLogicalJoin
接着看下哪里Rule会转换这个FlinkLogicalJoin
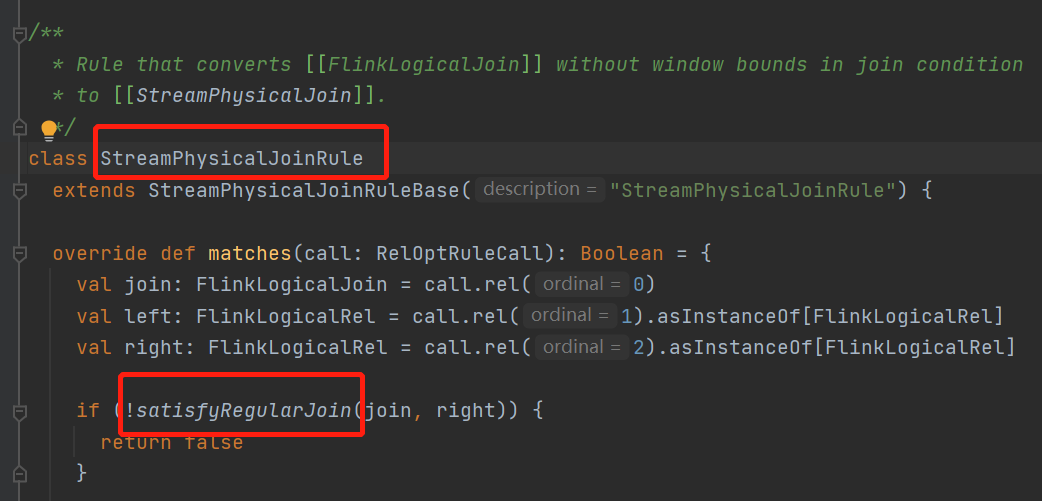
这里会将这种普通join也就是regularJoin给匹配上
条件是

不是这三种join,并且
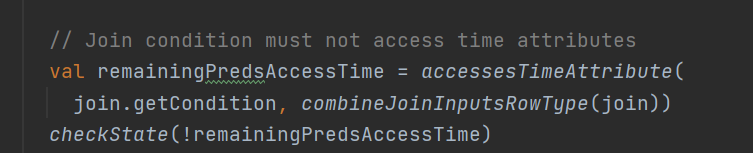
也不能join表达式包含时间属性
匹配上次rule以后,接着

返回了StreamPhysicalJoin这个StreamPhysicalRel是个物理节点
他的translateToExecNode方法会返回StreamExecJoin,这个类就是我们具体的逻辑了
来看一下
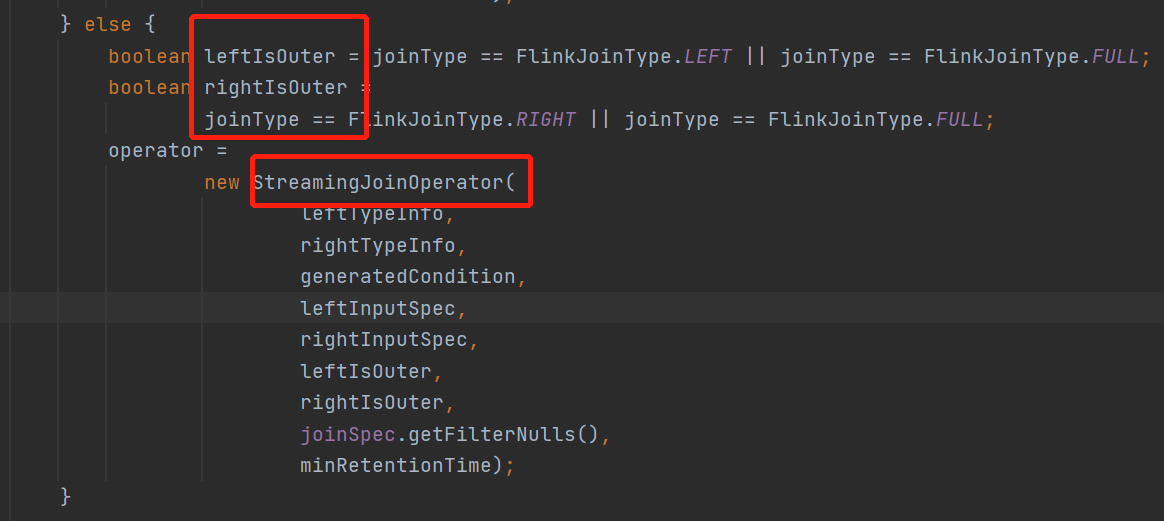
首先会根据会join的类型,确定两个流那个需要输出,如果是fulljoin两个流都会输出,left join就是左流需要outer,right join就是right流需要outer
之后创建了具体的Operator,来看下这个StreamingJoinOperator
先看一下这个类里面两个比较重要的状态

可以看到,左右流都会保存一个状态
看下状态包装类的描述
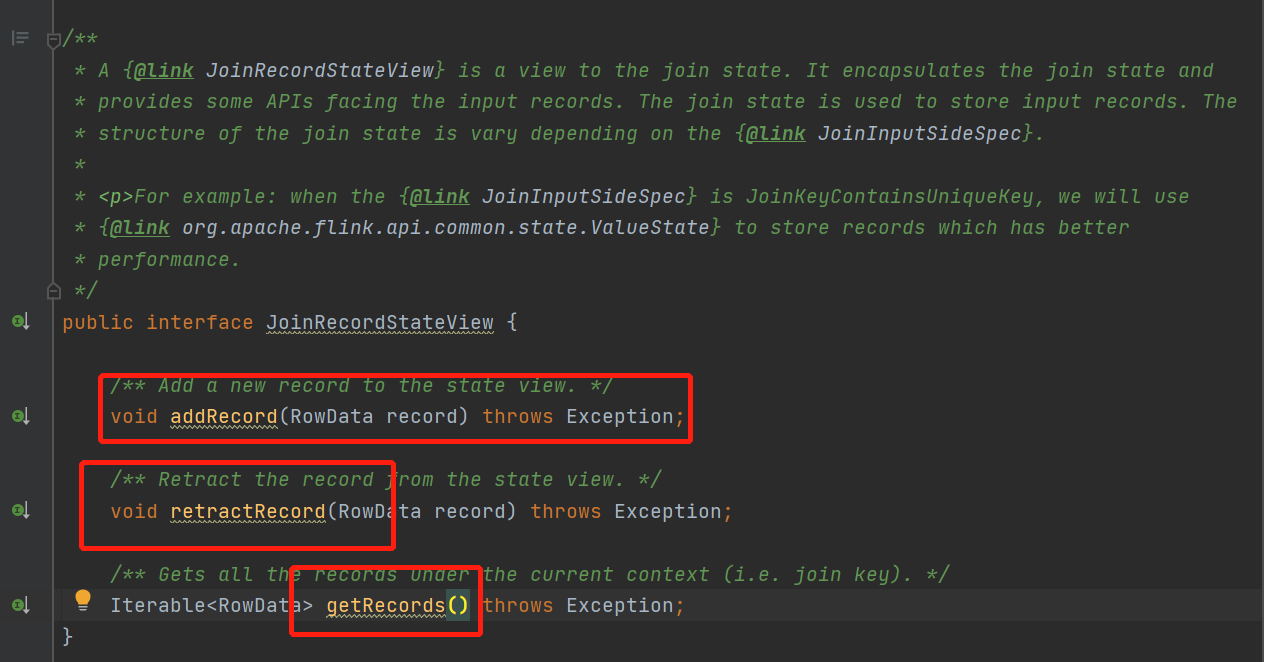
总共就三,方法,分别是加入数据,撤回数据,获取这个数据关联上的所有数据
在open方法里面会根据上面计算的左右流是否需要输出来初始化这个两个状态

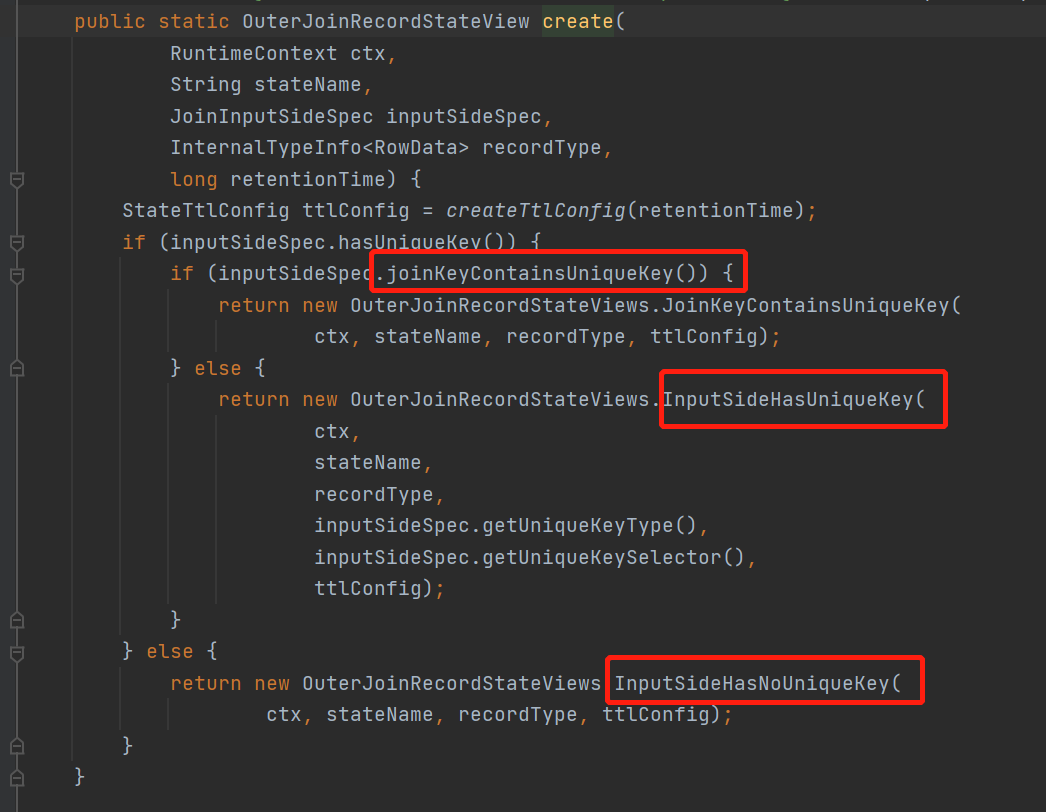
这里状态包装类的创建,将根据数据类型分为三种
1. 流带主键,且join条件包含了主键

这样数据唯一,就只用ValueState来存
2. 流带主键,但join条件没有包含主键

这里就用MapState来存了,每次根据主键更新
3. 流不带主键

就用map,直接把record当key存了
接着看processElement方法
这里详细的代码就不列出来了太复杂了,想看的直接看这个类
org.apache.flink.table.runtime.operators.join.stream.StreamingJoinOperator.processElement()
梳理逻辑我们还是来看下伪代码


主要分为两段
1. 如果是 +Insert / +Update 类型的数据
判断输入数据的流需不需要输出
如果需要输出
看下和另外一个流关联的上不
关联的上输出 +I[record+other]s
关联不上输出 +I[record+null]
将数据加入状态中
如果不需要输出
将数据加入状态中
如果与另外一个流的数据关联上了
如果另外一个流要outer, 输出 +I[record+other]s
如果另外一个流不用输出 ,输出 +I/+U[record+other]s
1. 如果是 -Delete / -Update 类型的数据
状态里面先撤回这条数据
如果与另外流没有匹配上,如果输入数据的流需要输出,则输出 -D[record+null]
如果与另外一条流匹配上了
当前流outer,发送 -D[record+other]s,如果是inner join发送-D/-U[record+other]s
最后的最后
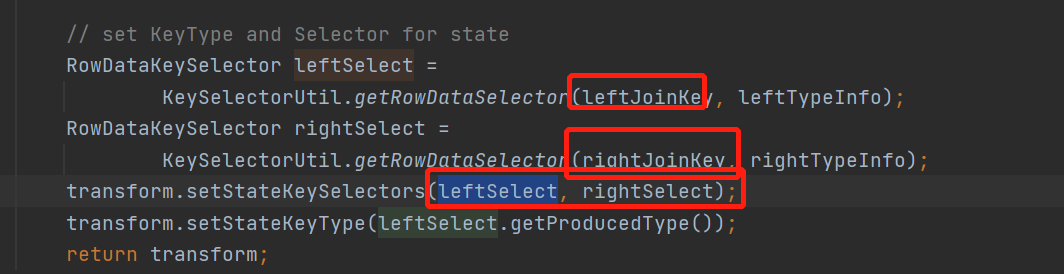
用两个流join的key作为状态的selecter来完成transform的构建就完成了
总结一下:
Flink会根据join的key作为状态分流的selecter,根据表是否有主键,join条件是否包含主键,来创建对应的state数据结构,来优化状态的读写
两条流会根据join类型,来设置此流需不需要输出outer
当数据进入,查询另一侧的流是否有数据可以关联上,以及两条流的outer类型,来确定向下游发送的撤回和新增的数据
Flink sql 之 join 与 StreamPhysicalJoinRule (源码解析)的更多相关文章
- Flink sql 之 TopN 与 StreamPhysicalRankRule (源码解析)
基于flink1.14的源码做解析 公司内有很多业务方都在使用我们Flink sql平台做TopN的计算,今天同事突然问到我,Flink sql 是怎么实现topN的 ? 蒙圈了,这块源码没看过啊 , ...
- [源码解析] GroupReduce,GroupCombine 和 Flink SQL group by
[源码解析] GroupReduce,GroupCombine和Flink SQL group by 目录 [源码解析] GroupReduce,GroupCombine和Flink SQL grou ...
- Flink 源码解析 —— 深度解析 Flink 是如何管理好内存的?
前言 如今,许多用于分析大型数据集的开源系统都是用 Java 或者是基于 JVM 的编程语言实现的.最着名的例子是 Apache Hadoop,还有较新的框架,如 Apache Spark.Apach ...
- [源码解析] 当 Java Stream 遇见 Flink
[源码解析] 当 Java Stream 遇见 Flink 目录 [源码解析] 当 Java Stream 遇见 Flink 0x00 摘要 0x01 领域 1.1 Flink 1.2 Java St ...
- Flink 源码解析 —— 源码编译运行
更新一篇知识星球里面的源码分析文章,去年写的,周末自己录了个视频,大家看下效果好吗?如果好的话,后面补录发在知识星球里面的其他源码解析文章. 前言 之前自己本地 clone 了 Flink 的源码,编 ...
- Flink 源码解析 —— 如何获取 ExecutionGraph ?
https://t.zsxq.com/UnA2jIi 博客 1.Flink 从0到1学习 -- Apache Flink 介绍 2.Flink 从0到1学习 -- Mac 上搭建 Flink 1.6. ...
- Flink 源码解析 —— 如何获取 JobGraph?
JobGraph https://t.zsxq.com/naaMf6y 博客 1.Flink 从0到1学习 -- Apache Flink 介绍 2.Flink 从0到1学习 -- Mac 上搭建 F ...
- Flink 源码解析 —— Flink JobManager 有什么作用?
JobManager 的作用 https://t.zsxq.com/2VRrbuf 博客 1.Flink 从0到1学习 -- Apache Flink 介绍 2.Flink 从0到1学习 -- Mac ...
- Flink 源码解析 —— JobManager 处理 SubmitJob 的过程
JobManager 处理 SubmitJob https://t.zsxq.com/3JQJMzZ 博客 1.Flink 从0到1学习 -- Apache Flink 介绍 2.Flink 从0到1 ...
随机推荐
- 安全测试工具(1)- Burp Suite Pro的安装教程
啥是Burp Suite 用于攻击web 应用程序的集成平台 程序员必备技能,不仅可以拿来做渗透测试.漏洞挖掘还能帮助程序员调试程序 Bug 它包含了许多Burp工具,这些不同的burp工具通过协同工 ...
- split文件切片
文件上传下载过程中经常会遇到网络不稳定,或者传输软件限制传输的文件大小之类的问题.在当今换没有出现很好的软件的时候,一个available方法是将大文件切片,也就是 切成小文件,然后通过其他方法put ...
- 查看elasticsearch版本的方法
查看elasticsearch版本的方法: 1.elasticsearch已经启动的情况下 使用curl -XGET localhost:9200命令查看: "version" : ...
- windows中对文件进行排序
右键->排序方式->更多->选择需要的项目
- Spirit带你彻底了解事件捕获和冒泡机制
Dom标准事件模型 在Dom标准事件模型中,事件是先进行捕获,达到目标阶段时,在进行冒泡的 捕获阶段==>目标阶段==>冒泡阶段 目标元素和非目标元素 在介绍事件捕获和事件冒泡前 我们先要 ...
- 动态规划精讲(一)LC 最长递增子序列的个数
最长递增子序列的个数 给定一个未排序的整数数组,找到最长递增子序列的个数. 示例 1: 输入: [1,3,5,4,7]输出: 2解释: 有两个最长递增子序列,分别是 [1, 3, 4, 7] 和[1, ...
- # Zombie Gunship Survival(僵尸炮艇生存)GG修改器修改教程
Zombie Gunship Survival(僵尸炮艇生存)GG修改器修改教程 1.修改伤害,打击范围,武器冷却时间,子弹容量 测试手机机型:华为畅享7 系统版本:Android7.0 是否ROOT ...
- html 表单input disabled属性提交后台无法获得数据
在input上加入disabled属性后, 点击提交会遗漏该值, 有两个办法: 一 可以考虑readonly属性,一样的不可修改操作,但是可以提交 二 在提交时 js 代码操作去除input上的dis ...
- Jmeter系列(17)- 常用断言之JSON断言
模块分析 Assert JSON Path exists:需要断言的 JSON 表达式 Additionally assert value:如果要根据值去断言,请勾选 Match as regular ...
- AVS 端能力之蓝牙模块
该类为蓝牙端能力处理类,主要负责蓝牙设备配对和蓝牙音频播放功能. 功能简介 实现蓝牙设备的启动发现模式.扫描蓝牙设备.建立蓝牙连接功能 实现蓝牙设备音频播放.停止.上一首.下一首功能 其它细节参考&l ...