MobilNnet
一、参数数量和理论计算量
1、定义
- 参数数量(params):关系到模型大小,单位通常为M,通常参数用 float32 表示,也就是每个参数占4个字节,所以
模型大小是参数数量的 4 倍 - 理论计算量(FLOPs):
- 是 floating point operations 的缩写(注意 s 小写),可以用来
衡量算法/模型的复杂度,这关系到算法速度,大模型的单位通常为 G,小模型单位通常为 M 通常只考虑乘加操作(Multi-Adds)的数量,而且只考虑 CONV 和 FC 等参数层的计算量,忽略 BN 和PReLU 等等。一般情况,CONV 和 FC 层也会忽略仅纯加操作 的计算量,如 bias 偏置加和 shotcut 残差加等,目前技术有 BN 的 CNN 可以不加 bias
- 是 floating point operations 的缩写(注意 s 小写),可以用来
2、计算公式
假设卷积核大小为 Kh × Kw,输入通道数为 Cin x Cout,输出特征图的宽 W 和高 H,忽略偏置。
- CONV 标准卷积层:
- 参数量就是kernel*kernel*channel_input*channel_output,卷积核的大小x通道数量x卷积核的个数
 ,输入通道数等于一个卷积核的通道数,输出通道数=卷积核的个数
,输入通道数等于一个卷积核的通道数,输出通道数=卷积核的个数- 计算量:kernel*kernel*next_featuremap_height*next_featuremap_wight*channel_input*channel_output

- 参数量等于计算量,因为输入输出都不能使二维平面,而是向量
 ,C相当于一个一张图片展成一条线上的所有点,也就是所有的像素点
,C相当于一个一张图片展成一条线上的所有点,也就是所有的像素点
FC 全连接层(相当于 k=1,输入输出都不是二维图像,都是单个点):
参数量取决于显存大小,计算量要求芯片的floaps(gpu的运算能力)
二、MobileNetV1: Efficient Convolutional Neural Networks for Mobile Vision Applications
1、能够减少参数数量和计算量的原理
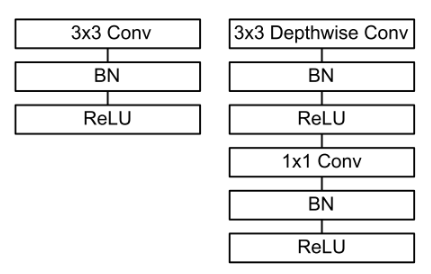
深度可分离卷积的使用
- 在进行 depthwise 卷积时只使用了
一种维度为in_channels的卷积核进行特征提取(没有进行特征组合) 在进行 pointwise 卷积时只使用了output_channels 种维度为in_channels 1*1 的卷积核进行特征组合,普通卷积不同 depth 层的权重是按照 1:1:1…:1的比例进行相加的,而在这里不同 depth 层的权重是按照**不同比例(可学习的参数)**进行相加的
- 参数数量由原来的
 --》p2 = F*F*in_channels*1 + 1*1*in_channels*output_channels参数量减小为原来的p2/p1,当F=3的时候,大概为1/9
--》p2 = F*F*in_channels*1 + 1*1*in_channels*output_channels参数量减小为原来的p2/p1,当F=3的时候,大概为1/9 - 深度卷积参数量=卷积核尺寸 x 卷积核通道数1 x 卷积核个数(就是输入通道数);
- 点卷积(普通卷积)参数量=卷积核尺寸1x1 x 卷积核通道数就是输入通道数 x 卷积核的个数(即输出通道数)
- Note: 原论文中对第一层没有用此卷积,深度可分离卷积中的每一个后面都跟 BN 和 RELU
- Global Average Pooling 的使用:这一层没有参数,计算量可以忽略不计
- 用
CONV/s2(步进2的卷积)代替MaxPool+CONV:使得参数数量不变,计算量变为原来的 1/4 左右,且省去了MaxPool 的计算量 Note:采用 depth-wise convolution 会有一个问题,就是导致 信息流通不畅 ,即输出的 feature map 仅包含输入的 feature map 的一部分,在这里,MobileNet 采用了 point-wise(1*1) convolution 帮助信息在通道之间流通
2、MobileNetV1 中引入的两个超参数
Width Multiplier(α \alphaα): Thinner Models
Resolution Multiplier(ρ \rhoρ): Reduced Representation
3、标准卷积和深度可分离卷积的区别


三、MobileNetV2:Inverted Residuals and Linear Bottlenecks
1、主要改进点
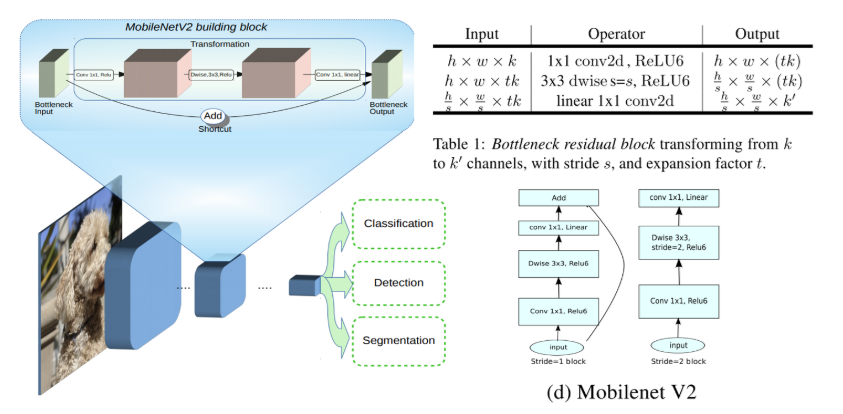
- 引入残差结构,先升维(先1x1卷积,输出特征图的通道数增加)再降维(再3x3和1x1),增强梯度的传播,显著减少推理期间所需的内存占用(
Inverted Residuals) - 去掉 Narrow layer(low dimension or depth) 后的 ReLU,保留特征多样性,增强网络的表达能力(
Linear Bottlenecks) - 网络为
全卷积的,使得模型可以适应不同尺寸的图像;使用RELU6(最高输出为 6)激活函数,使得模型在低精度计算下具有更强的鲁棒性
MobileNetV2 building block 如下所示,若需要下采样,可在 DWise 时采用步长为 2 的卷积;小网络使用小的扩张系数(expansion factor),大网络使用大一点的扩张系数(expansion factor),推荐是5~10,论文中 t=6 t = 6t=6
2、和 MobileNetV1 的区别

3、和 ResNet 的区别

MobilNnet的更多相关文章
随机推荐
- IE 11 浏览器兼容性视图设置
1.打开IE 浏览器. 2.选择“工具”---“兼容性视图设置”.3.在“在兼容性视图中显示所有网站”前面勾选住. 点击关闭就可以了. 开发人员工具 1.找到“工具”----“F12开发人员工具”.2 ...
- Zookeeper 使用
转自:https://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/ 安装和配置详解 本文介绍的 Zookeeper 是以 3.2. ...
- LINUX KERNEL启动参数
LINUX KERNEL启动参数 在Linux中,给kernel传递参数以控制其行为总共有三种方法: 1.build kernel之时的各个configuration选项. 2.当kernel启动之时 ...
- python之组合与继承的使用场景
1.什么时候使用类的组合?当类之间有显著的不同,并且较小的类是组成较大类所需要的组件,此时用类的组合较合理:场景:医院是由多个科室组成的,此时我们可以定义不同科室的类,这样医院的类我们可以直接使用各个 ...
- 指针FHQTreap
不太友好的代码 题面依旧是普通平衡树 //Writer : Hsz %WJMZBMR%tourist%hzwer #include <bits/stdc++.h> #define LL l ...
- 1、Ansible初识简要介绍及安装
1.Ansible简介 1.1 Ansible介绍 Ansible 是一个简单的自动化运维管理工具,基于Python开发,集合了众多运维工具(puppet.cfengine.chef.func.fab ...
- django迁移数据库报错解决
迁移数据库时提示之前的项目中模型未引入 如图 我在创建新的工程时,迁移数据模型时发现出错,错误提示关联模型未被解决,提示的模型是之前项目中定义的,本项目并没有用到.于是在不知道错误原因下,我重装dja ...
- Windows使用docker打开新窗口error解决办法
环境 win7 Error: error during connect: Get http://%2F%2F.%2Fpipe%2Fdocker_engine/v1.26/containers/json ...
- PHP面向对象(二)
7 多态 多态: 多种形态 多态分俩种: 方法重写和方法加载 7.1 方法重写 子类重写了父类的同名的方法 <?php class Person{ public function show(){ ...
- NYIST 119 士兵杀敌(三)
士兵杀敌(三)时间限制:2000 ms | 内存限制:65535 KB难度:5 描述南将军统率着N个士兵,士兵分别编号为1~N,南将军经常爱拿某一段编号内杀敌数最高的人与杀敌数最低的人进行比较,计算出 ...