浅谈unicode编码和utf-8编码的关系
字符串编码在Python里边是经常会遇到的问题,特别是写文件以及网络传输的过程中,当调用某些函数的时候经常会遇到一些字符串编码提示错误,所以有必要弄清楚这些编码到底在搞什么鬼。

我们都知道计算机只能处理数字,文本转换为数字才能处理。计算机中8个bit作为一个字节,所以一个字节能表示最大的数字就是255。计算机是美国人发明的,而英文中涉及的编码并不多,一个字节可以表示所有字符了,所以ASCII(American national Standard Code for Information Interchange,美国国家标准信息交换码)编码就成为美国人的标准编码。但是我们都知道中文的字符肯定不止255个汉字,使用ASCII编码来处理中文显然是不够的,所以中国制定了GB2312编码,用两个字节表示一个汉字,碰到及其特殊的情况,还会用三个字节来表示一个汉字。GB2312还把ASCII包含进去了。同理,日文,韩文等上百个国家为了解决这个问题发展了一套自己的编码,于是乎标准越来越多,如果出现多种语言混合显示就一定会出现乱码。那么针对这种编码“乱象”,Unicode便应运而生了,其将所有语言统一到一套编码规则里。

Unicode有许多种编码,比如说可以通过16个bit或者32个bit来把所有语言统一到一套编码里。举个栗子,字母A用ASCII编码的十进制为65,二进制为0100 0001;汉字“中”已经超出了ASCII编码的范围,用unicode编码是20013,二进制是01001110 00101101;A用unicode编码只需要前面补0,二进制是00000000 0100 0001。可以看出,unicode不仅解决了ASCII码本身的编码问题,还解决了超出ASCII编码范围之外的其他国家字符编码的统一问题。
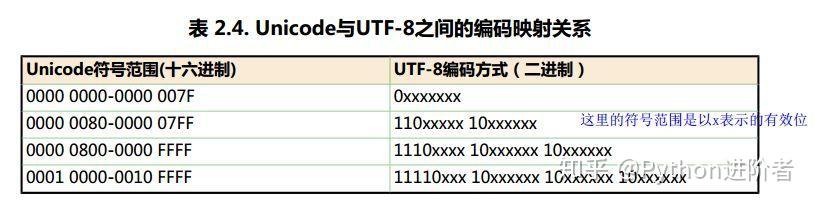
虽然unicode编码能做到将不同国家的字符进行统一,使得乱码问题得以解决,但是如果内容全是英文unicode编码比ASCII编码需要多一倍的存储空间,同时如果传输需要多一倍的传输。当传输文件比较小的时候,内存资源和网络带宽尚能承受,当文件传输达到上TB的时候,如果 “硬”传,则需要消耗的资源就不可小觑了。为了解决这个问题,一种可变长的编码“utf-8”就应运而生了,把英文变长1个字节,汉字3个字节,特别生僻的变成4-6个字节,如果传输大量的英文,utf8的作用就很明显了。

不过正是因为utf-8编码的可变长,一会儿一个字符串是占用一个字节,一会儿一个字符串占用两个字节,还有的占用三个及以上的字节,导致在内存中或者程序中变得不好琢磨。unicode编码虽然占用内存空间,但是在编程过程中或者在内存处理的时候会比utf-8编码更为简单,因为它始终保持一样的长度,一样的长度对于内存和代码来说,它的处理就会变得更加简单。所以utf-8编码在做网络传输和文件保存的时候,将unicode编码转换成utf-8编码,才能更好的发挥其作用;当从文件中读取数据到内存中的时候,将utf-8编码转换为unicode编码,亦为良策。
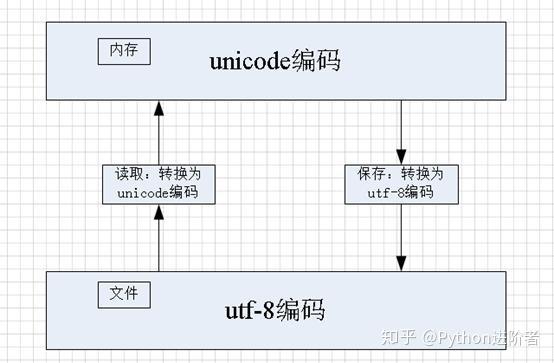
如上图所示,当需要在内存中读取文件的时候,此时将utf-8编码的内存转换为unicode编码,在内存中进行统一处理;当需要保存文件的时候,出于空间和传输效率的考虑,此时将unicode编码转换为utf-8编码。在Python中进行读取和保存文件的时候,必须要显示的指定文件编码,其余的事情就交给Python的相关库去处理就可以了。
小伙伴们,了解了这些基础知识之后,接下来对Python中的字符串编码问题的理解就轻松的多了。
浅谈unicode编码和utf-8编码的关系的更多相关文章
- 浅谈Unicode编码
目录 1.概述 2.ASCII编码 3.历史问题 4.Unicode 4-1.Unicode 编码方案 4-2.关于bom 5.UTF-8 6.UTF-16 1.概述 对于ASCII编码,相信同学们都 ...
- 浅谈 Data URI 与 BASE 64 编码
前言(废话):鼓捣 Stylish 的时候发现了这么个奇怪的代码行: Data:image/gif;BASE64,R0lGODlhEAAQAKEAAEKF9NPi/AAAAAAAACH5BAEAAAI ...
- 浅谈CPU、内存、硬盘之间的关系
计算机,大家都知道的,就是我们日常用的电脑,不管台式的还是笔记本都是计算机.那么这个看着很复杂的机器由哪些组成的呢,今天就简单的来了解一下. 先放图: 图上展示的就是计算机的基本组成啦. 首先是输入设 ...
- 浅谈编码Base64、Hex、UTF-8、Unicode、GBK等
网络上大多精彩的回答,该随笔用作自我总结: 首先计算机只认得二进制,0和1,所以我们现在看到的字都是经过二进制数据编码后的:计算机能针对0和1的组合做很多事情,这些规则都是人定义的:然后有了字节的概念 ...
- 从Java String实例来理解ANSI、Unicode、BMP、UTF等编码概念
转(http://www.codeceo.com/article/java-string-ansi-unicode-bmp-utf.html#0-tsina-1-10971-397232819ff9a ...
- 浅谈Android编码规范及命名规范
前言: 目前工作负责两个医疗APP项目的开发,同时使用LeanCloud进行云端配合开发,完全单挑. 现大框架已经完成,正在进行细节模块上的开发 抽空总结一下Android项目的开发规范:1.编码规范 ...
- Android安全开发之浅谈密钥硬编码
Android安全开发之浅谈密钥硬编码 作者:伊樵.呆狐@阿里聚安全 1 简介 在阿里聚安全的漏洞扫描器中和人工APP安全审计中,经常发现有开发者将密钥硬编码在Java代码.文件中,这样做会引起很大风 ...
- 趣谈unicode,ansi,utf-8,unicode big endian这些编码有什么区别(转载)
从头讲讲编码的故事.那么就让我们找个草堆坐下,先抽口烟,看看夜晚天空上的银河,然后想一想要从哪里开始讲起.嗯,也许这样开始比较好…… 很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同 ...
- 浅谈URLEncoder编码算法
一.为什么要用URLEncoder 客户端在进行网页请求的时候,网址中可能会包含非ASCII码形式的内容,比如中文. 而直接把中文放到网址中请求是不允许的,所以需要用URLEncoder编码地址, 将 ...
随机推荐
- nginx proxy_set_header设置,自定义header
在实际应用中,我们可能需要获取用户的ip地址,比如做异地登陆的判断,或者统计ip访问次数等,通常情况下我们使用request.getRemoteAddr()就可以获取到客户端ip,但是当我们使用了ng ...
- ZOJ 2702 Unrhymable Rhymes
Unrhymable Rhymes Time Limit:10000MS Memory Limit:32768KB 64bit IO Format:%lld & %llu De ...
- wget 升级
漏洞描述: Wget是GNU计划开发的一套用于在网络上进行下载的自由软件,是Unix/Linux系统最常用的下载工具,支持通过HTTP.HTTPS以及FTP这三个最常见的TCP/IP协议下载. Wge ...
- 洛谷 P2818 天使的起誓
P2818 天使的起誓 题目描述 Tenshi非常幸运地被选为掌管智慧之匙的天使.在正式任职之前,她必须和其他新当选的天使一样要宣誓.宣誓仪式是每位天使各自表述自己的使命,他们的发言稿放在n个呈圆形排 ...
- vjudge A - Beautiful numbers
A - Beautiful numbers Volodya is an odd boy and his taste is strange as well. It seems to him that a ...
- Implement Stack using Queues 用队列实现栈
Implement the following operations of a stack using queues. push(x) -- Push element x onto stack. po ...
- poj2280--Amphiphilic Carbon Molecules(扫描线+极角排序+转换坐标)
题目链接:id=2280">点击打开链接 题目大意:给出n个点的坐标.每一个点有一个值0或者1,如今有一个隔板(无限长)去分开着n个点,一側统计0的个数,一側统计1的个数,假设点在板上 ...
- 检测浏览器是否支持range
昨天的滑块建立在Input range这个基础上 这是IOS5.0及以后才支持的,而且在android2.3以下表现也不对 昨天的检测方式 var input = document.createEl ...
- nyoj-673-悟空的难题(数组标记)
悟空的难题 时间限制:1000 ms | 内存限制:65535 KB 难度:2 描写叙述 自从悟空当上了齐天大圣.花果山上的猴子猴孙们便也能够尝到天上的各种仙果神酒,所以猴子猴孙们的体质也得到了非 ...
- js控制textarea输入字符串的个数,鼠标按下抬起推断输入字符数
[Html代码] <table> <tr> <td width="150">短信内容:</td> <td> <te ...