SQL Server 2014,表变量上的非聚集索引
从Paul White的推特上看到,在SQL Server 2014里,对于表变量(Table Variables),它是支持非唯一聚集索引(Non-Unique Clustered Indexes)和非聚集索引(Non-Clustered Indexes)的。看到这个,我决定在自己的虚拟机里尝试下,因为这将是个卓越的功能。表变量很棒,因为用它可以避免过多的重编译(excessive recompilations)。当你创建它们时,它们是没有统计信息,你不会改变数据库架构。它们只是变量,但在TempDb里还是常驻的。
表变量的一个缺点是,你不能在上面创建非聚集索引,这个在处理大量数据集时是不好的。但SQL Server 2014 CTP1已经修正了这个缺点。来看下面的代码(点击工具栏的 显示包含实际的执行计划):
显示包含实际的执行计划):
DECLARE @tempTable TABLE
(
ID INT IDENTITY(1, 1) PRIMARY KEY,
FirstName CHAR(100) INDEX idx_FirstName,
LastName CHAR(100)
) INSERT INTO @TempTable (FirstName, LastName)
SELECT TOP 100000 name, name FROM master.dbo.syscolumns SELECT FirstName FROM @TempTable
WHERE FirstName = 'cid'
GO

我们来看下SELECT语句的执行计划,SQL Server执行了非聚集索引扫描运算符(Non-Clustered Index Seek operator)。也就是说,我们可以在表变量上定义额外的非聚集索引。每个创建的非聚集索引是没有统计信息。这个功能很酷哦,在常规数据库表的简单语法(easy syntax)也支持。我们来看下面的表定义:
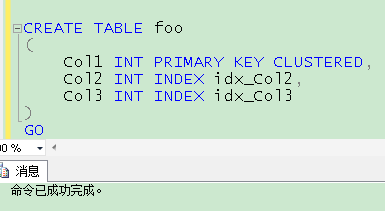
CREATE TABLE foo
(
Col1 INT PRIMARY KEY CLUSTERED,
Col2 INT INDEX idx_Col2,
Col3 INT INDEX idx_Col3
)
GO
这个在SQL Server 2008R2上会提示如下错误:

在SQL Server 2014上却能成功执行!
更进一步,我们还可以用新语法创建复合索引(composite indexes):
-- Inline creation of Indexes
CREATE TABLE foo2
(
Col1 INT PRIMARY KEY CLUSTERED,
Col2 INT INDEX idx_Col2 (Col2, Col3),
Col3 INT
)
GO
之前的版本(我这里是SQL Server 2008R2)只能如下出错提示:


真是酷炫叼炸天了,大家赶紧都去体验下!
参考文章:
SQL Server 2014,表变量上的非聚集索引的更多相关文章
- SQL Server性能优化(12)非聚集索引的组合索引存储结构
一,非聚集索引组合索引 用户可以在多个列上建立索引,这种索引叫做复合索引(组合索引).但复合索引在数据库操作期间所需的开销更小,可以代替多个单一索引.当表的行数远远大于索引键的数目时,使用这种方式可以 ...
- SQL Server性能优化(11)非聚集索引的覆盖索引存储结构
一,非聚集索引的include 非聚集索引的Include属性可以让非聚集索引包含其他列.如 CREATE NONCLUSTERED INDEX [NonIxUser] ON [dbo].[Users ...
- SQL Server性能优化(10)非聚集索引的存储结构
一,新建测试表 CREATE TABLE [dbo].[Users]( ,) NOT NULL, ) NOT NULL, [CreatTime] [datetime] NOT NULL ) ON [P ...
- 在SQL Server 2014里可更新的列存储索引 (Updateable Column Store Indexes)
传统的关系数据库服务引擎往往并不是对超大量数据进行分析计算的最佳平台,为此,SQL Server中开发了分析服务引擎去对大笔数据进行分析计算.当然,对于数据的存放平台SQL Server数据库引擎而言 ...
- SQL Server中的联合主键、聚集索引、非聚集索引、mysql 联合索引
我们都知道在一个表中当需要2列以上才能确定记录的唯一性的时候,就需要用到联合主键,当建立联合主键以后,在查询数据的时候性能就会有很大的提升,不过并不是对联合主键的任何列单独查询的时候性能都会提升,但我 ...
- SQL Server中的联合主键、聚集索引、非聚集索引
我们都知道在一个表中当需要2列以上才能确定记录的唯一性的时候,就需要用到联合主键,当建立联合主键以后,在查询数据的时候性能就会有很大的提升,不过并不是对联合主键的任何列单独查询的时候性能都会提升,但我 ...
- SQL Server 2008 表变量参数(表值参数)用法
表值参数是 SQL Server 2008 中的新参数类型.表值参数是使用用户定义的表类型来声明的.使用表值参数,可以不必创建临时表或许多参数,即可向 Transact-SQL 语句或例程(如存储过程 ...
- SQL Server 2008 表变量 临时表
最近做一个报表,其中 在报表中用到了存储过程,游标,cte表达式,临时表和表变量. 在游标中循环遍历cte中的数据,把对应的数据存放在变量里面,之后把变量插入到表变量中,游标结束后,想要根据存储过程的 ...
- SQL Server临界点游戏——为什么非聚集索引被忽略!
当我们进行SQL Server问题处理的时候,有时候会发现一个很有意思的现象:SQL Server完全忽略现有定义好的非聚集索引,直接使用表扫描来获取数据.我们来看看下面的表和索引定义: CREATE ...
随机推荐
- RUF MVC5 Repositories Framework Generator代码生成工具介绍和使用
RUF MVC5 Repositories Framework Generator代码生成工具介绍和使用 功能介绍 这个项目经过了大半年的持续更新到目前的阶段基本稳定 所有源代码都是开源的,在gith ...
- iOS:OC Lib:MagicalRecord
# MagicalRecord 2.1 ## 前言 CoreData是iOS开发中经常使用的数据持久化的技术.但其操作过程稍微繁琐,即使你只是实现简单的存取,不涉及请求优化,也要进行许多配置工作,代码 ...
- Tomcat 安全配置与性能优化
一.Tomcat内存优化 1.JAVA_OPTS参数说明 Tomcat内存优化主要是对 tomcat 启动参数优化,我们可以在 tomcat 的启动脚本 catalina.sh 中设置 JAVA_OP ...
- Android系列---JSON数据解析
您可以通过点击 右下角 的按钮 来对文章内容作出评价, 也可以通过左下方的 关注按钮 来关注我的博客的最新动态. 如果文章内容对您有帮助, 不要忘记点击右下角的 推荐按钮 来支持一下哦 如果您对文章内 ...
- PreparedStatement ResultSet
public int searchProblemDistinctCount() throws Exception { DBOperator dbo = getDBOperator(); try { P ...
- Test Tex
\begin{equation}\label{exampleone}r = r_F+ \beta (r_M - r_F) + \epsilon\end{equation}
- C# HttpWebRequest 绝技 根据URL地址获取网页信息
如果要使用中间的方法的话,可以访问我的帮助类完全免费开源:C# HttpHelper,帮助类,真正的Httprequest请求时无视编码,无视证书,无视Cookie,网页抓取 1.第一招,根据URL地 ...
- 高吞吐量的分布式发布订阅消息系统Kafka--spring-integration-kafka的应用
一.概述 Spring Integration Kafka 是基于 Apache Kafka 和Spring Integration来集成Kafka,对开发配置提供了方便. 二.配置 1.spring ...
- C# 向Http服务器送出 POST 请求
//向Http服务器送出 POST 请求 public string m_PostSubmit(string strUrl,string strParam) { string strResult = ...
- iOS 内存管理机制和循环引用处理方法
简述 ARC: 自动引用计数, Automatic Reference Counting MRC: Mannul Reference Counting ARC工作原理 1.当每次创建一个新实例时,AR ...