Spark(二): 内存管理
Spark 作为一个以擅长内存计算为优势的计算引擎,内存管理方案是其非常重要的模块; Spark的内存可以大体归为两类:execution和storage,前者包括shuffles、joins、sorts和aggregations所需内存,后者包括cache和节点间数据传输所需内存;在Spark 1.5和之前版本里,两者是静态配置的,不支持借用,spark1.6 对内存管理模块进行了优化,通过内存空间的融合,消除以上限制,提供更好的性能。官方网站只是要求内存在8GB之上即可(Impala推荐要求机器配置在128GB), 但spark job运行效率主要取决于:数据量大小,内存消耗,内核数(确定并发运行的task数量)
目录:
- 基础知识
- spark1.5- 内存管理
- spark1.6 内存管理
基本知识:
- on-heap memory:Java中分配的非空对象都是由Java虚拟机的垃圾收集器管理的,也称为堆内内存。虚拟机会定期对垃圾内存进行回收,在某些特定的时间点,它会进行一次彻底的回收(full gc)。彻底回收时,垃圾收集器会对所有分配的堆内内存进行完整的扫描,这意味着一个重要的事实——这样一次垃圾收集对Java应用造成的影响,跟堆的大小是成正比的。过大的堆会影响Java应用的性能
- off-heap memory:堆外内存意味着把内存对象分配在Java虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机)。这样做的结果就是能保持一个较小的堆,以减少垃圾收集对应用的影响
- LRU Cache(Least Recently Used):LRU可以说是一种算法,也可以算是一种原则,用来判断如何从Cache中清除对象,而LRU就是“近期最少使用”原则,当Cache溢出时,最近最少使用的对象将被从Cache中清除
- spark 源码: https://github.com/apache/spark/releases
- scale ide for Intellij : http://plugins.jetbrains.com/plugin/?id=1347
Spark1.5- 内存管理:
- 1.6 版本引入了新的内存管理方案,配置参数: spark.memory.useLegacyMode 默认 false 表示使用新方案,true 表示使用旧方案, SparkEnv.scala 源码 如下图:


- 在staticMemoryManager.scala 类中查看构造类及内存获取定义


- 通过代码推断,若设置了 spark.testing.memory 则以该配置的值作为 systemMaxMemory,否则使用 JVM 最大内存作为 systemMaxMemory。
- spark.testing.memory 仅用于测试,一般不设置,所以这里我们认为 systemMaxMemory 的值就是 executor 的最大可用内存
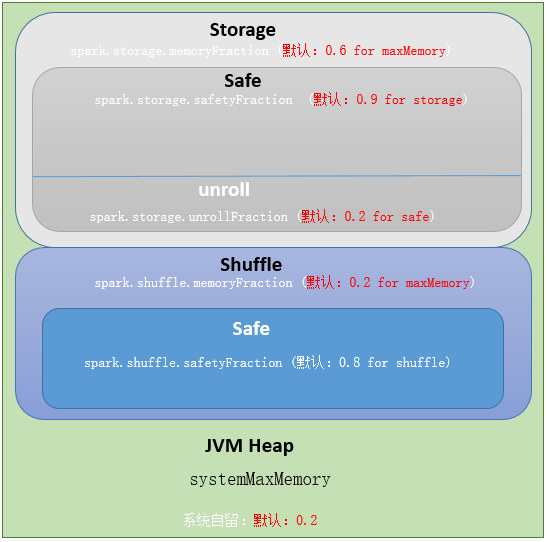
- Execution:用于缓存shuffle、join、sort和aggregation的临时数据,通过spark.shuffle.memoryFraction配置
- spark.shuffle.memoryFraction:shuffle 期间占 executor 运行时内存的百分比,用小数表示。在任何时候,用于 shuffle 的内存总 size 不得超过这个限制,超出部分会 spill 到磁盘。如果经常 spill,考虑调大参数值
- spark.shuffle.safetyFraction:为防止 OOM,不能把 systemMaxMemory * spark.shuffle.memoryFraction 全用了,需要有个安全百分比
- 最终用于 execution 的内存量为:executor 最大可用内存* spark.shuffle.memoryFraction*spark.shuffle.safetyFraction,默认为 executor 最大可用内存 * 0.16
- execution内存被分配给JVM里的多个task线程。
- task间的execution内存分配是动态的,如果没有其他tasks存在,Spark允许一个task占用所有可用execution内存
- storage内存分配分析过程与 Execution 一致,由上面的代码得出,用于storage 的内存量为: executor 最大可用内存 * spark.storage.memoryFraction * spark.storage.safetyFraction,默认为 executor 最大可用内存 * 0.54
- 在 storage 中,有一部分内存是给 unroll 使用的,unroll 即反序列化 block,该部分占比由 spark.storage.unrollFraction 控制,默认为0.2
- 通过代码分析,storage 和 execution 总共使用了 80% 的内存,剩余 20% 内存被系统保留了,用来存储运行中产生的对象,该类型内存不可控.
小结:
- 这种内存管理方式的缺陷,即 execution 和 storage 内存表态分配,即使在一方内存不够用而另一方内存空闲的情况下也不能共享,造成内存浪费,为解决这一问题,spark1.6 启用新的内存管理方案UnifiedMemoryManager
- staticMemoryManager- jvm 堆内存分配图如下
Spark1.6 内存管理:
从spark1.6开始,引入了新的内存管理方式-----统一内存管理(UnifiedMemoryManager),在统一内存管理下,spark一个executor中的jvm heap内存被划分成如下图:
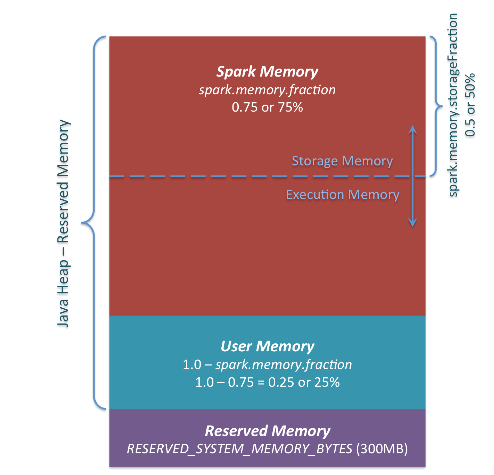
- Reserved Memory,这一部分的内存是我们无法使用的部分,spark内部保留内存,会存储一些spark的内部对象等内容。
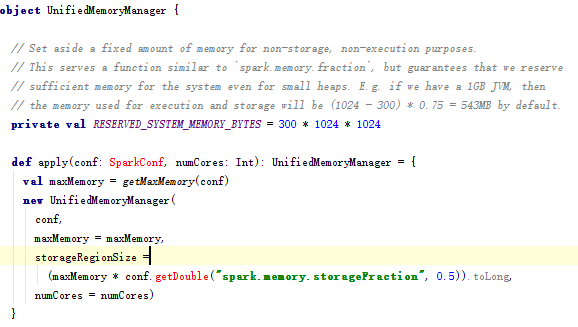
- spark1.6默认的Reserved Memory大小是300MB。这部分大小是不允许我们使用者改变的。简单点说就是我们在为executor申请内存后,有300MB是我们无法使用的。并且如果我们申请的executor的大小小于1.5 * Reserved Memory 即 < 450MB,spark会报错:
- User Memory:用户在程序中创建的对象存储等一系列非spark管理的内存开销都占用这一部分内存
- Spark Memory:该部分大小为 (JVM Heap Size - Reserved Memory) * spark.memory.fraction,其中的spark.memory.fraction可以是我们配置的(默认0.75),如下图:

- 如果spark.memory.fraction配小了,我们的spark task在执行时产生数据时,包括我们在做cache时就很可能出现经常因为这部分内存不足的情况而产生spill到disk的情况,影响效率。采用官方推荐默认配置
- Spark Memory这一块有被分成了两个部分,Execution Memory 和 Storage Memory,这通过spark.memory.storageFraction来配置两块各占的大小(默认0.5,一边一半),如图:
- Storage Memory主要用来存储我们cache的数据和临时空间序列化时unroll的数据,以及broadcast变量cache级别存储的内容
- Execution Memory则是spark Task执行时使用的内存(比如shuffle时排序就需要大量的内存)
- 为了提高内存利用率,spark针对Storage Memory 和 Execution Memory有如下策略:
- 一方空闲,一方内存不足情况下,内存不足一方可以向空闲一方借用内存
- 只有Execution Memory可以强制拿回Storage Memory在Execution Memory空闲时,借用的Execution Memory的部分内存(如果因强制取回,而Storage Memory数据丢失,重新计算即可)
- 如果Storage Memory只能等待Execution Memory主动释放占用的Storage Memory空闲时的内存。(这里不强制取回,因为如果task执行,数据丢失就会导致task 失败)
Spark(二): 内存管理的更多相关文章
- Spark 静态内存管理
作者编辑:杜晓蝶,王玮,任泽 Spark 静态内存管理详解 一. 内容简介 spark从1.6开始引入了动态内存管理模式,即执行内存和存储内存之间可以互相抢占.spark提供两种内存分配模式,即:静态 ...
- Android笔记--Bitmap(二)内存管理
Bitmap(二) 内存管理 1.使用内存缓存保证流畅性 这种使用方式在ListView等这种滚动条的展示方式中使用最为广泛, 使用内存缓存 内存缓存位图可以提供最快的展示.但代价就是占用一定的内存空 ...
- cocos2d-x游戏引擎核心之二——内存管理
(一) cocos2d-x 内存管理 cocos2d里面管理内存采用了引用计数的方式,具体来说就是CCObject里面有个成员变量m_uReference(计数); 1, m_uReference的变 ...
- Spark内核-内存管理
Spark 集群会启动 Driver 和 Executor 两种 JVM 进程 我们只关注Executor的内存. 分为堆内内存和堆外内存 内存分为 存储内存 : 存储数据用的. 执行内存: 执行sh ...
- Spark 动态(统一)内存管理模型
作者编辑:王玮,胡玉林 一.回顾 在前面的一篇文章中我们介绍了spark静态内存管理模式以及相关知识https://blog.csdn.net/anitinaj/article/details/809 ...
- Spark 1.6以后的内存管理机制
Spark 内部管理机制 Spark的内存管理自从1.6开始改变.老的内存管理实现自自staticMemoryManager类,然而现在它被称之为"legacy". " ...
- Apache Spark 内存管理详解(转载)
Spark 作为一个基于内存的分布式计算引擎,其内存管理模块在整个系统中扮演着非常重要的角色.理解 Spark 内存管理的基本原理,有助于更好地开发 Spark 应用程序和进行性能调优.本文旨在梳理出 ...
- spark的内存分配管理
SPARK的内存管理器 StaticMemoryManager,UnifiedMemoryManager 1.6以后默认是UnifiedMemoryManager. 这个内存管理器在sparkCont ...
- spark 源码分析之十五 -- Spark内存管理剖析
本篇文章主要剖析Spark的内存管理体系. 在上篇文章 spark 源码分析之十四 -- broadcast 是如何实现的?中对存储相关的内容没有做过多的剖析,下面计划先剖析Spark的内存机制,进而 ...
随机推荐
- 第二个sprint第六天
讨论地点:qq 讨论成员:邵家文.李新.朱浩龙.陈俊金 今天完成:统计功能前期工作已经完成,暂时对它进行搁置. 开发感悟:今天回了乡下吃了一顿饭,发现还是乡下环境好,比较适合在那种环境下 ...
- iOS开发环境C语言基础 数组 函数
1 求数组元素的最大值 1.1 问题 创建程序,实现查询数组中最大值的功能,需求为:创建一个长度为10的数组,数组内放置10个0~99之间(包含0,包含99)的随机数作为数组内容,要求查询出数组中的最 ...
- js实现对比百分比
<script> for(var i=1;i<=3;i++){ for(var j=2;j<=4;j++){ var hid="w_"+4+j+" ...
- phpcms站---去除域名绑定目录中的HTML
原网址:http://www.xker.com/page/e2014/1207/148536.html 打开 \install_package 打开 \caches\configs 目录下的 syst ...
- PHP 中安装memcache扩展文件下载对应地址。
PHP 5.5.1版本下载了很多,安装都不成功.终于找到一个适合版本. http://windows.php.net/downloads/pecl/releases/memcache/3.0.8/ ...
- JAVA 打印指定月份日历
package learnExercise; import java.util.Scanner; public class PrintCalender { /** * @param args */ p ...
- codevs 1299 线段树 区间更新查询
1299 切水果 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 大师 Master 题解 查看运行结果 题目描述 Description 简单的说,一共N个水果排成 ...
- 使用isInEditMode解决可视化编辑器无法识别自定义控件的问题
如果在自定义控件的构造函数或者其他绘制相关地方使用系统依赖的代码, 会导致可视化编辑器无法报错并提示:Use View.isInEditMode() in your custom views to s ...
- python--切片--6
原创博文,转载请标明出处--周学伟http://www.cnblogs.com/zxouxuewei/ 一.对list进行切片 取一个list的部分元素是非常常见的操作.比如,一个list如下: &g ...
- URAL 1320 Graph Decomposition(并查集)
1320. Graph Decomposition Time limit: 0.5 secondMemory limit: 64 MB There is a simple graph with an ...