自然语言处理3.3——使用Unicode进行文字处理
全世界有多种语言,经常需要应用程序处理不同的语言和字符集。下面将介绍如何利用Unicode处理使用非ASCII字符集文字。
1.什么是Unicode
Unicode支持一百万种以上的字符,每一个字符分配一个编号,称为编码点。在Python中编码点写作\uXXXX,其中XXXX是四位十六进制数。
在一段程序中,可以像普通字符串那样操纵Unicode字符串。然而,当Unicode字符被存储在文件里或者终端上显示时候,必须编码为字节流。由于一些编码的每个编码点都使用单字节,所以他们只需要支持Unicode中的一个小子集就足够一种语言使用了,但是其他编码(UTF-8)使用多个字节,可以表示全部的Unicode字符。
注意:将文本翻译成Unicode叫做解码,相对的,将Unicode转化为合适的编码称为编码。如下图:
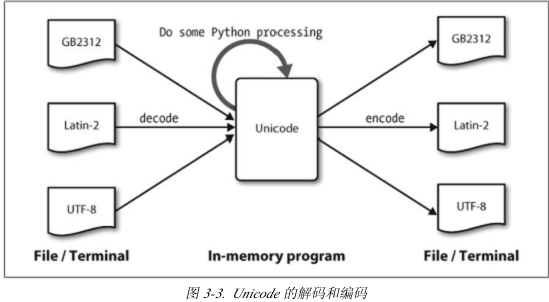
2,从文件中提取已经编码文本。
假设有一个小的文本文件,并且知道他是怎么编码的,例如:polish-lat2.txt是波兰语的文本片段。为Latin-2编码。下面首先使用nltk.data.find()函数定位文件
path=nltk.data.find('corpora/unicode_samples/polish-lat2.txt')
Python的codecs模块提供了将编码数据读入为Unicode字符串和将Unicode字符串以编码的形式输出的函数。codecs.open()函数有一个encoding参数来制定被读取或者写入的文件的编码。我们导入codecs模块,以‘Latin-2’为encoding的参数,打开制定的波兰语文件
>>>import codecs
>>>f=codecs.open(path,encoding='latin2')
从文件对象f读出的文本将会以Unicode返回。为了能在终端上查看这个文本我们需要使用合适的编码对它进行编码。Python特定的unicode_escape是一个虚拟的编码,他把所有的非ASCII字符转换成\uXXXX形式。编码点在ASCII码0~127的范围以外但是低于256的,使用两位数字的形式表示。
>>>for line in f:
line=line.strip()
print(line.encode('unicode_escape'))
b'Pruska Biblioteka Pa\\u0144stwowa. Jej dawne zbiory znane pod nazw\\u0105'
b'"Berlinka" to skarb kultury i sztuki niemieckiej. Przewiezione przez'
b'Niemc\\xf3w pod koniec II wojny \\u015bwiatowej na Dolny \\u015al\\u0105sk, zosta\\u0142y'
b'odnalezione po 1945 r. na terytorium Polski. Trafi\\u0142y do Biblioteki'
b'Jagiello\\u0144skiej w Krakowie, obejmuj\\u0105 ponad 500 tys. zabytkowych'
b'archiwali\\xf3w, m.in. manuskrypty Goethego, Mozarta, Beethovena, Bacha.'
可以看到在输出文本的第一行有一个以\u转义字符串开始的Unicode转义字符串。即\u0144。
在Python中,一个Unicode字符串常量可以通过在字符串前面加一个u也就是例如u‘hello’来制定。
>>>print(u'\u0061')
a
>>>nacute=u'\u0144'
>>>print(nacute)
ń
Python在指定print使用repr()转化字符串,repr()输出UTF-8转义字符,而不是试图显示字形。
>>>nacute_utf=nacute.encode('utf-8')
>>>print(repr(nacute_utf))
b'\xc5\x84'
unicodedata模块使我们可以检查Unicode字符的属性。
>>> import unicodedata
>>> unicodedata.lookup('LEFT CURLY BRACKET')
'{'
>>> unicodedata.name('/')
'SOLIDUS'
>>> unicodedata.decimal('9')
9
>>> unicodedata.decimal('a')
Traceback (most recent call last):
File "<stdin>", line 1, in ?
ValueError: not a decimal
>>> unicodedata.category('A') # 'L'etter, 'u'ppercase
'Lu'
>>> unicodedata.bidirectional('\u0660') # 'A'rabic, 'N'umber
'AN'
自然语言处理3.3——使用Unicode进行文字处理的更多相关文章
- 文字编码和Unicode
文字编码和Unicode 说明文字: https://blog.csdn.net/fengzhishang2019/article/details/7859064 Java 程序: https://w ...
- 《Python自然语言处理》
<Python自然语言处理> 基本信息 作者: (美)Steven Bird Ewan Klein Edward Loper 出版社:人民邮电出版社 ISBN:97871153 ...
- 【NLP】Python NLTK处理原始文本
Python NLTK 处理原始文本 作者:白宁超 2016年11月8日22:45:44 摘要:NLTK是由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集的大量公开 ...
- OpenCascade Chinese Text Rendering
OpenCascade Chinese Text Rendering eryar@163.com Abstract. OpenCascade uses advanced text rendering ...
- ASP 编码转换(乱码问题解决)
ASP 编码转换(乱码问题解决) 输出前先调用Conversion函数进行编码转换,可以解决乱码问题. 注,“&参数&”为ASP的连接符,这里面很多是直接调用的数据库表字段,实际使用请 ...
- 字符流和字节流(FileReader类和FileWriter类)
字符流主要用于支持Unicode的文字内容,绝大多数在字节流中所提供的类,都可在此找到对应的类.其中,输入流Reader抽象类帮助用户在Unicode流内获得字符数据,而Writer类则实现了输出.可 ...
- python 处理中文文件时的编码问题,尤其是utf-8和gbk
python代码文件的编码 py文件默认是ASCII编码,中文在显示时会做一个ASCII到系统默认编码的转换,这时就会出错:SyntaxError: Non-ASCII character.需要在代码 ...
- python 读写文件和设置文件的字符编码
一. python打开文件代码如下: f = open("d:\test.txt", "w") 说明:第一个参数是文件名称,包括路径:第二个参数是打开的模式mo ...
- C++历史(The History of C++)
C++历史 早期C++ •1979: 首次实现引入类的C(C with Classes first implemented) 1.新特性:类.成员函数.继承类.独立编译.公共和私有访问控制.友元.函数 ...
随机推荐
- 安全增强 Linux (SELinux) 剖析
架构和实现 Linux® 一直被认为是最安全的操作系统之一,但是通过引入安全增强 Linux(Security-Enhanced Linux,SELinux),National Security Ag ...
- libbspatch.so
http://www.zhihu.com/question/21154099 http://blog.csdn.net/hmg25/article/details/8100896 91助手和Googl ...
- N个元素组成二叉树的种类
<算法>中的二叉查找树一节的一道习题. N个元素组成的二叉树固定一个根节点,这个根节点的左右子树组合数为(0,n-1),(1,n-2),(2,n-3)...(n-1,0),假设N个元素组成 ...
- [转]Table-Driven and Data Driven Programming
What is Table-Driven and Data-Driven Programming? Data/Table-Driven programming is the technique of ...
- MINIX3 导读分析
一个操作系统的分析是属于一个非常庞大的工程,操作系统就像是一个人造的 人,每一个模块想完全发挥功效,很有可能需要很多模块的支持才能够实现.所 以在分析 MINIX3 时,我认为同时看多个模块对于理解 ...
- Qt之JSON生成与解析
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式.它基于JavaScript(Standard ECMA-262 3rd Edition - December ...
- C++学习笔记36:类模板
类模板的目的 设计通用的类型式,以适应广泛的成员数据型式 类模板的定义格式 template<模板形式参数列表>class 类名称{...}; 原型:template<typenam ...
- R编程感悟
虽然大学阶段曾经学过C++, matlab等编程,但是真的几乎完全还给了老师- 所以,我一直将R 作为自己真正学习的第一门语言.我从2012年初在来美国的第二个rotation中开始接触到了R.当时不 ...
- 编程工具系列之一------使用GDB的堆栈跟踪功能
在调试程序的过程中,查看程序的函数调用堆栈是一项最基本的任务,几乎所有的图形调试器都支持这项特性. GDB调试器当然也支持这一特性,但是功能更加灵活和丰富. GDB将当前函数的栈帧编号为0,为外层函数 ...
- Conference Search不错的学术会议日程提示网站
一个不错的学术会议日程提示网站 http://www.confsearch.org,还可以通过内嵌框架(embedded iframe)集成到自己的网页上. http://www.confsearch ...