基于百度地图SDK和Elasticsearch GEO查询的地理围栏分析系统(1)
本文描述了一个系统,功能是评价和抽象地理围栏(Geo-fencing),以及监控和分析核心地理围栏中业务的表现。
技术栈:Spring-JQuery-百度地图WEB SDK
存储:Hive-Elasticsearch-MySQL-Redis
什么是地理围栏?
LBS系统中,地理围栏指的是虚拟边界围成的部分。
tips:这只是一个demo,支撑实习生的本科毕设,不代表生产环境,而且数据已经做了脱密处理,为了安全还是隐去了所有数据。
功能描述
1、地理围栏的圈选
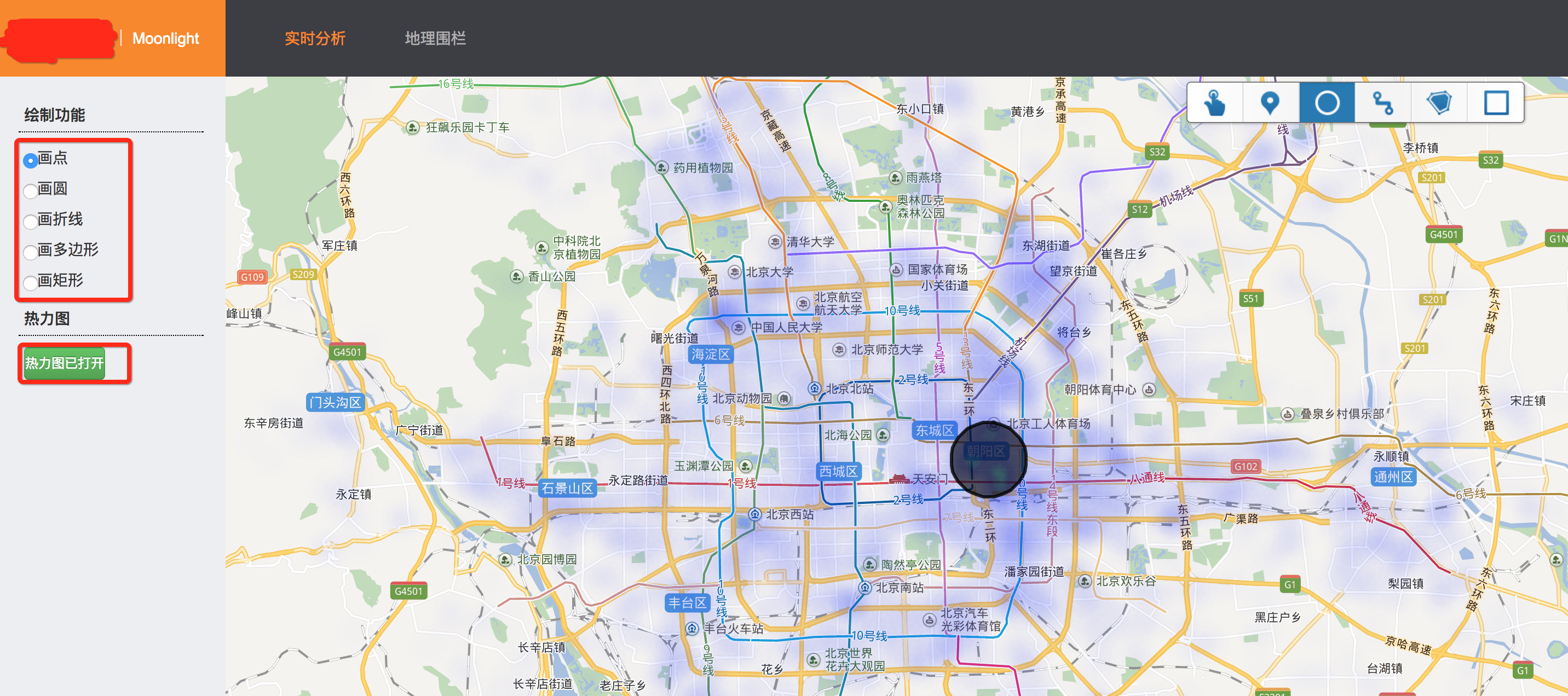
(1)热力图
热力图展示的是,北京市最近一天的业务密度(这里是T+1数据,在实际工作场景中往往是通过实时流采集分析实时的数据)
(2)圈选地理围栏
系统提供了圆形(距中心点距离)、矩形、多边形三种类型的图形圈选,并通过百度地图SDK采集图形的信息。
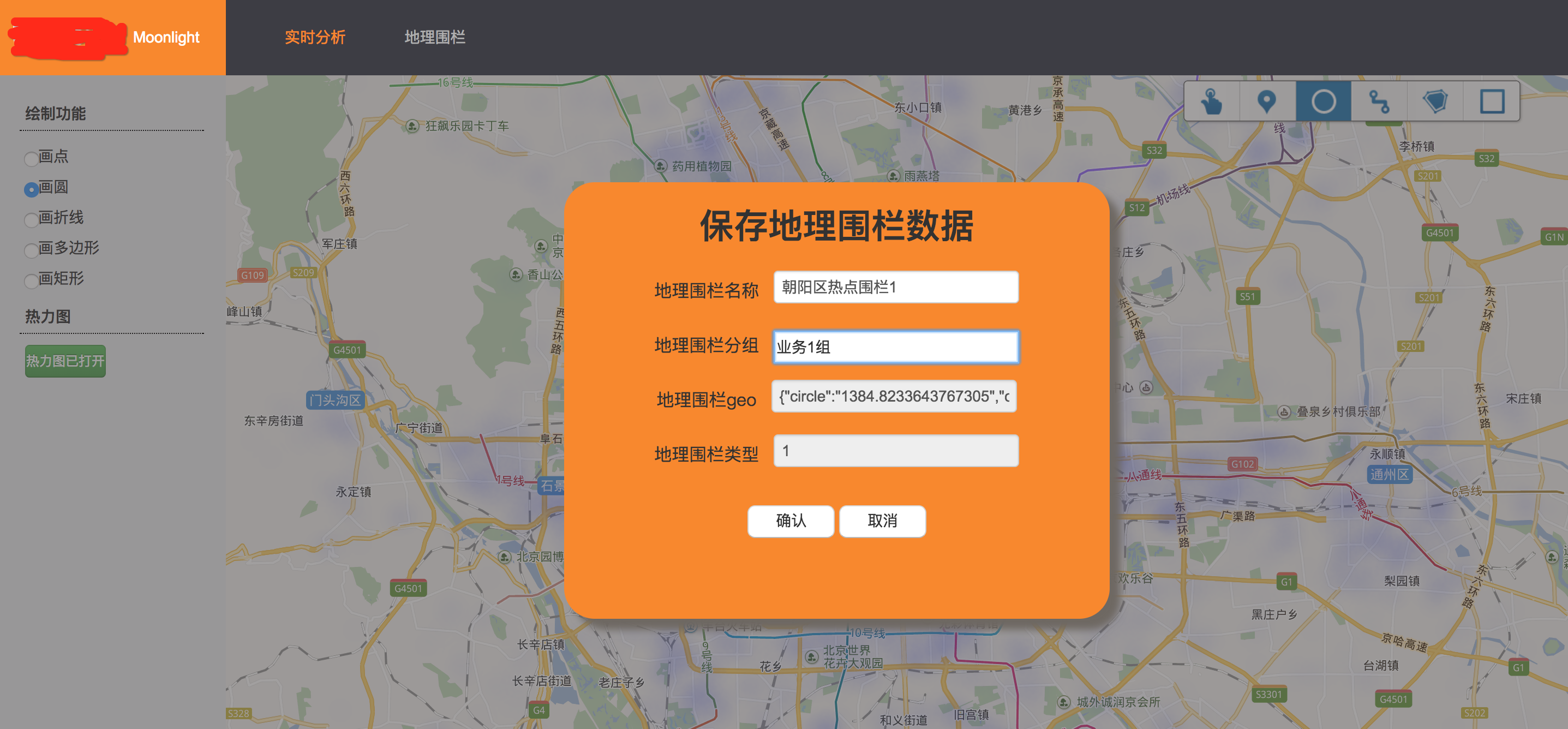
2、地理围栏的持久化
(1)提供地理围栏的持久化功能
(2)地理围栏列表
下面是持久化的地理围栏列表,可以看到类型和围栏信息。

当圈选完成,可以选择持久化地理围栏,这个围栏将会沉淀下来,供后续业务分析和监控。
3、聚合分析
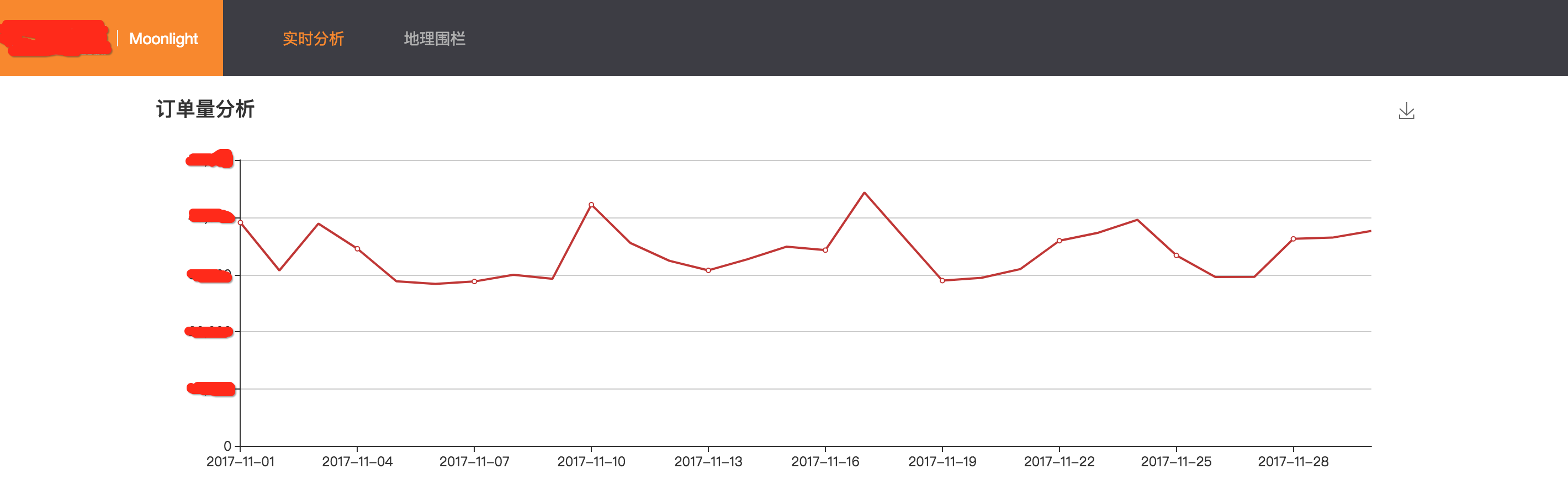
(1)提供日订单量,日盈利和日取消率的聚合分析
例如下图是在某个地理围栏区域内,11月这30天内,订单量的变化。
(2)详细列表
提供每一天数据的详细信息,对异常点可以标红和预警

上面基本就是系统的全部核心功能。下面进入实现部分。
实现 - 数据准备
1、数据源
数据源应该是业务的数据库(例如订单库)以及客户端埋点日志(端动作),公司的离线采集和ETL团队经过了漫长的工作,将数据处理好存入了Hive中。
对于本文系统来说,数据源就是Hive中的order表。要做的是将Hive中的数据导入到Elasticsearch中,使用Elasticsearch强大的GEO Query支持进行分析。
2、数据导入
数据的导入使用的是一段Java的Spark脚本。
(1)先解决依赖
spark-core是必备依赖。引入spark-hive来处理Hive中的数据。引入elasticsearch-hadoop来搞定Hive到ES的写入。
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.10</artifactId>
<version>1.6.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-hadoop</artifactId>
<version>2.3.4</version>
</dependency>
(2)编写spark脚本
先上代码
public class ToES implements Serializable {
transient private JavaSparkContext javaSparkContext;
transient private HiveContext hiveContext;
private String num;
/*
* 初始化Load
* 创建sparkContext, hiveContext
* */
public ToES(String num) {
this.num = num;
initSparckContext();
initHiveContext();
}
/*
* 创建sparkContext
* */
private void initSparckContext() {
SparkConf sparkConf;
String warehouseLocation = System.getProperty("user.dir");
sparkConf = new SparkConf()
.setAppName("to-es")
.set("spark.sql.warehouse.dir", warehouseLocation)
.setMaster("yarn-client")
.set("es.nodes", "10.93.21.21,10.93.18.34,10.93.18.35,100.90.62.33,100.90.61.14")
.set("es.port", "8049").set("pushdown", "true").set("es.index.auto.create", "true");
javaSparkContext = new JavaSparkContext(sparkConf);
}
/*
* 创建hiveContext
* 用于读取Hive中的数据
* */
private void initHiveContext() {
hiveContext = new HiveContext(javaSparkContext);
}
/*
* 使用spark-sql从hive中读取数据, 然后写入es.
* */
public void hive2es() {
String query = String.format("select * from kangaroo.order where concat_ws('-', year, month, day) = '%s' and product_id in (3,4) and area = 1",
transTimeToFormat(System.currentTimeMillis() - Integer.parseInt(num)*24*60*60*1000L, "yyyy-MM-dd"));
DataFrame rows = hiveContext.sql(query)
.select("order_id", "starting_lng", "starting_lat", "order_status", "tip", "bouns",
"pre_total_fee", "dynamic_price", "product_id", "starting_name", "dest_name", "type");
JavaRDD<Map<String, Object>> rdd = rows.toJavaRDD().map(new Function<Row, Map<String, Object>>() {
/*
* 转换成Map, 解决字段类型不匹配问题
* */
@Override
public Map<String, Object> call(Row row) throws Exception {
Map<String, Object> map = new HashMap<String, Object>();
Map<String, Object> location = new HashMap<String, Object>();
for (int i=0; i<row.size(); i++) {
String key = row.schema().fields()[i].name();
Object value = row.get(i);
map.put(key, value);
}
location.put("lat", Double.parseDouble(map.get("starting_lat").toString()));
location.put("lon", Double.parseDouble(map.get("starting_lng").toString()));
map.remove("starting_lat");
map.remove("starting_lng");
map.put("location", location);
map.put("date", transTimeToFormat(System.currentTimeMillis() - Integer.parseInt(num)*24*60*60*1000L, "yyyy-MM-dd"));
return map;
}
});
Map<String, String> map = new HashMap<String, String>();
map.put("es.mapping.id", "order_id");
JavaEsSpark.saveToEs(rdd, "moon/bj", map);
}
public String transTimeToFormat(long currentTime, String formatStr) {
String formatTime = null;
try {
SimpleDateFormat format = new SimpleDateFormat(formatStr);
formatTime = format.format(currentTime);
} catch (Exception e) {
}
return formatTime;
}
public static void main(String[] args) {
String num = args[0];
ToES toES = new ToES(num);
toES.hive2es();
}
}
SparkContext和HiveContext的初始化,请自行参考代码。
ES的集群配置是在sparkConf中加载进去的,加载方式请自己参照代码。
1)数据过滤
hive-sql
select * from kangaroo.order where concat_ws('-', year, month, day) = '%s' and product_id in (3,4) and area = 1
说明:
a)Hive的order表实现为一个外部表,year/month/day是分区字段,也就是说数据是按照天为粒度挂载的。
b)product_id是业务编号,这里过滤出了目标业务的订单。
c)area为城市编号,这里只过滤出北京。
2)列的裁剪
Elasticsearch有个弊端是由于索引的建立,当数据导入Elasticsearch数据量会膨胀,所以一定要进行维度的裁剪。
我们的订单Hive表姑且就叫它order吧,这个表有40+个字段,我们导入到ES中,只选用了其中的12个字段。
在代码中是,通过DataFrame的select实现的裁剪
DataFrame rows = hiveContext.sql(query)
.select("order_id", "starting_lng", "starting_lat", "order_status", "tip", "bouns",
"pre_total_fee", "dynamic_price", "product_id", "starting_name", "dest_name", "type");
可能会有这样的好奇,这样做在hive-sql中把所有字段全拿到然后在裁剪?为什么不直接在sql语句中进行裁剪?简单解释一下,由于spark的惰性求值,应该是没有区别的。
3)map转换操作
下面将dataFrame转换成rdd,执行map操作,将每一条记录进行处理,处理的核心逻辑,是将starting_lng、starting_lat压成一个HashMap的location字段。
为什么要这样做呢?
因为在Elasticsearch中要这样存储点的经纬度,并且将location字段声明为geo_point类型,才能使用空间索引查询。
然后我们顺便生成了一个date字段,表示订单是哪一天的,方便后面的以天为粒度进行聚合查询。
4)批量存入ES
Map<String, String> map = new HashMap<String, String>();
map.put("es.mapping.id", "order_id");
JavaEsSpark.saveToEs(rdd, "moon/bj", map);
这样就将rdd中的数据批量存入到ES中了,存入的索引是index=moon,type=bj,这里映射了order_id为ES文档的document_id。我们下面马上就会说如何建立moon/bj的mapping
5)ES索引建立
再将数据导入到ES之前,要建立index和mapping。
创建index=moon
curl -XPOST "http://10.93.21.21:8049/moon?pretty"
创建type=bj的mapping
curl -XPOST "http://10.93.21.21:8049/moon/bj/_mapping?pretty" -d '
{
"bj": {
"properties": {
"order_id": {"type": "long"},
"order_status": {"type": "long"},
"tip": {"type": "long"},
"bouns": {"type": "long"},
"pre_total_fee": {"type": "long"},
"dynamic_price": {"type": "long"},
"product_id": {"type": "long"},
"type": {"type": "long"},
"dest_name": {"index": "not_analyzed","type": "string"},
"starting_name": {"index": "not_analyzed","type": "string"},
"departure_time": {"index": "not_analyzed","type": "string"},
"location": {"type" : "geo_point"},
"date": {"index": "not_analyzed", "type" : "string"}
}
}
}'
这里要注意的是,location字段的类型-geo_point。
6)打包编译spark程序
以yarn队列形式运行
spark-submit --queue=root.*** to-es-1.0-SNAPSHOT-jar-with-dependencies.jar
然后在ES的head中可以看到数据已经加载进去了
至此,数据已经准备好了。
今天先到这,后面的博客会描述如何搞定百度地图前端和Elasticsearch GEO查询。
基于百度地图SDK和Elasticsearch GEO查询的地理围栏分析系统(1)的更多相关文章
- 基于百度地图SDK和Elasticsearch GEO查询的地理围栏分析系统(2)-查询实现
在上一篇博客中,我们准备好了数据.现在数据已经以我们需要的格式,存放在Elasticsearch中了. 本文讲述如何在Elasticsearch中进行空间GEO查询和聚合查询,以及如何准备ajax接口 ...
- 基于百度地图SDK和Elasticsearch GEO查询的地理围栏分析系统(3)-前端实现
转载自:http://www.cnblogs.com/Auyuer/p/8086975.html MoonLight可视化订单需求区域分析系统实现功能: 在现实生活中,计算机和互联网迅速发展,人们越来 ...
- AndroidBDMap学习01:基于百度地图SDK的配置以及利用API实现一个简单的地图应用
(一)注册并获取AK码: step1:找到keytool工具,并转移到.android目录下.(前提是已经安装了java jre/jdk) 为避免有些情况,在控制台无法找到keytool,可以把与k ...
- Android学习-- 基于位置的服务 LBS(基于百度地图Android SDK)--定位SDK
原文:Android学习-- 基于位置的服务 LBS(基于百度地图Android SDK)--定位SDK 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.ne ...
- Android 百度地图 SDK v3.0.0 (四) 引入离线地图功能
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/37758097 一直觉得地图应用支持离线地图很重要啊,我等移动2G屌丝,流量不易, ...
- 基于百度地图api + AngularJS 的入门地图
转载请注明地址:http://www.cnblogs.com/enzozo/p/4368081.html 简介: 此入门地图为简易的“广州大学城”公交寻路地图,采用很少量的AngularJS进行inp ...
- Android定位&地图&导航——基于百度地图实现的定位功能
一.问题描述 LBS位置服务是android应用中重要的功能,应用越来越广泛,下面我们逐步学习和实现lbs相关的应用如定位.地图.导航等,首先我们看如何基于百度地图实现定位功能 二.配置环境 1.注册 ...
- 百度地图SDK for Android【检索服务】
1搜索服务 百度地图SDK集成搜索服务包括:位置检索.周边检索.范围检索.公交检索.驾乘检索.步行检索,通过初始化MKSearch类,注册搜索结果的监听对象MKSearchListener,实现异步搜 ...
- Android 百度地图 SDK v3.0.0 (四) 离线地图功能介绍
转载请注明出处:http://blog.csdn.net/lmj623565791/article/details/37758097 一直认为地图应用支持离线地图非常重要啊.我等移动2G屌丝,流量不易 ...
随机推荐
- struts2(五)之struts2拦截器与自定义拦截器
前言 前面介绍了struts2的输入验证,如果让我自己选的话,肯定是选择xml配置校验的方法,因为,能使用struts2中的一些校验规则,就无需自己编写了, 不过到后面应该都有其他更方便的校验方法,而 ...
- 使用SimpleXML解析xml文件数据
最近工作要求从一个XML文档中批量读取APK应用数据,自然想到用SimpleXML.经过一段时间摸索,终于成功解析,现在将思路以及代码做下记录: xml文件格式大致如下: <?xml versi ...
- Toxophily
Problem Description The recreation center of WHU ACM Team has indoor billiards, Ping Pang, chess and ...
- 谈谈HTTP/2对前端的影响【转载】
原文:http://www.peep-squirrel.com/itcontent-2500617.html 随着 HTTP/2 规范的确认,以及主流浏览器(Chrome.Firefox.IE11)对 ...
- BOM对象
每一个frames都有自己的window对象,也就是每个frames都有自己的全局对象,它们之前是相互独立的,包括各自独立的本地对象,top.Object !== top.frames[0].Obje ...
- linux-mv
linux-mv 主要用于文件或者目录的移动或者改动, 命令参数 -i:ruguo目标文件或者目录存在,提示是否覆盖目标文件或目录 -f:无论目标文件是否存在,直接覆盖,不提示, 有好多参数,自己可以 ...
- JS模块化开发----require.js
前言 前端开发中,起初只要在script标签中嵌入几十上百行代码就能实现一些基本的交互效果,后来js得到重视,应用也广泛起来了,jQuery,Ajax,Node.Js,MVC,MVVM等的助力也使得前 ...
- HTML+CSS+js常见知识点
一.HTML.CSS常见知识点 1.垂直居中盒子 /* 方法一 */ html, body { width: 100%; height: 100%; padding: 0; margin: 0; } ...
- python3基础视频教程
随着目前Python行业的薪资水平越来越高,很多人想加入该行业拿高薪.有没有想通过视频教程入门的同学们?这份Python教程全集等你来学习啦! python3基础视频教程:http://pan.bai ...
- SSO单点登录一:cas单点登录防止登出退出后刷新后退ticket失效报500错,也有退出后直接重新登录报票根验证错误
问题1: 我登录了client2,又登录了client3,现在我把client2退出了,在client3里面我F5刷新了一下,结果页面报错: 未能够识别出目标 'ST-41-2VcnVMguCDWJX ...