浅析Java源码之LinkedList
可以骂人吗???辛辛苦苦写了2个多小时搞到凌晨2点,点击保存草稿退回到了登录页面???登录成功草稿没了???喵喵喵???智障!!气!
很厉害,隔了30分钟,我的登录又失效了,草稿再次回滚,不客气了,***!
仔细想想,自动保存功能也挺可疑的,根据我半年的资深前端经验判断,内部实现大概是这样:
var id;
// *core event*
window.addEventListener('keyup',function(){
if(id){clearTimout(id);}
id = setTimeout(function(){
// user would be relieved to see this...
$('#...').html('本地自动保存于' + (new Date()).toLocaleTimeString() + ',<a href="javascript:void(0);">查看</a>')
},1000*Math.random());
});
如此智能的功能只能用这样优雅的代码实现了吧,社会社会!
重写。
上篇讲完了ArrayList,这篇继续补完LinkedList的内容。
首先上一张图来整体看一眼链表的结构(还好图在):
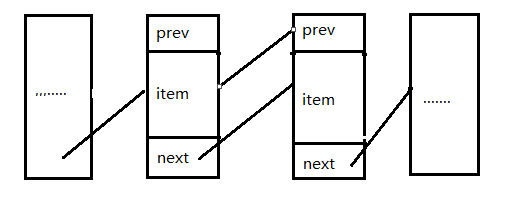
每一个大方块代表一个节点(Node),内部包含3部分内容:
1、前指针:指向上一个节点,头部元素指向null
2、数据:保存的数据内容
3、后指针:指向下一个节点,尾部元素指向null
Node是一个类,而且是一个私有+静态+内部类,buff齐全,看一眼实现:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
非常简单暴力,3个变量,一个构造函数,没啥解释的。
老规矩,首先从变量开始看起。
变量
public class LinkedList<E> extends AbstractSequentialList<E> implements
List<E>, Deque<E>, Cloneable, java.io.Serializable { transient int size = 0;
transient Node<E> first;
transient Node<E> last;
}
3个变量,size代表当前链表长度,first与last分别指向头部与尾部节点。
构造函数
有两个构造函数:
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
其中无参构造函数啥事也不做,另外一个构造函数允许以指定集合初始化链表。
这里的addAll只是一个重载版本
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
指向真正的addAll,在指定的位置插入链表,初始化的话size为0
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
直接看addAll的源码:
public boolean addAll(int index, Collection<? extends E> c) {
checkPositionIndex(index);
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
Node<E> pred, succ;
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
函数比较长,主要分为4步:
1、索引合法性检测
2、将集合拆分为数组并检测长度,如果为0不做操作直接返回false
3、根据插入位置分情况做插入
4、插入操作
首先第一步,比较简单:
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
判断插入索引是否在允许范围内,抛异常。
第二步的插入分两种:
1、尾部插入
2、其他
先看尾部插入的情况,即size==index:
succ = null;
pred = last;for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
在for循环中,每次都会生成一个新的Node,前指针指向pred(第一个为链表尾元素),数据为类型转换后的集合元素。
然后将pred的尾指针指向新生成的节点,最后将pred置为该节点。
依次插入集合元素后,由于是尾部插入,所以last应该是最后插入的元素,即last=pred。
第二种情况是中间插入,详细过程就不写了,心情有点糟糕。
方法
有了addAll,其他的方法就很简单了。
getFirst/Last
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
两个get方法分别返回链表的头部与尾部元素,判断是否存在并返回对应的item。
remove
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
两个删除方法也分别移除头部与尾部元素,方法就看一下unlinkFirst够了。
private E unlinkFirst(Node<E> f) {
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
这里将头部数据先缓存起来,然后将头部元素移除,将首元素设置为第二个节点,将第二个节点的prev置null。
如果第二个节点为null,说明链表中没有元素了,于是last也置null。
getIndex
最后看一下获取指定索引的数据
Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
这里不是单纯的从头遍历,而是做了一个小判断,如果索引在前半截,则从头往后遍历,否则相反。这样就将时间复杂度降低到o(n/2),但是只有双向链表才有。
剩余的方法都没有什么营养,有兴趣的可以自行研究,画画图简单的很。
最后总结一下ArrayList与LinkedList。
1、两者都是基本的容器,可以按顺序存储元素而且不用担心容器大小
2、搜索上ArrayList由于底层是数组,所以时间复杂度为o(1),而LinkedList为o(2/n)
3、插入元素时,ArrayList需要考虑扩容、变动索引后面元素,而链表最多只需要变动2个节点
4、虽然总体看起来ArrayList更弱,但是链表Node本身的复杂度也不容忽视,如果只为了读取还是尽量用ArrayList。
浅析Java源码之LinkedList的更多相关文章
- 浅析Java源码之ArrayList
面试题经常会问到LinkedList与ArrayList的区别,与其背网上的废话,不如直接撸源码! 文章源码来源于JRE1.8,java.util.ArrayList 既然是浅析,就主要针对该数据结构 ...
- 【数据结构】7.java源码关于LinkedList
关于LinkedList的源码关注点 1.从底层数据结构,扩容策略2.LinkedList的增删改查3.特殊处理重点关注4.遍历的速度,随机访问和iterator访问效率对比 1.从底层数据结构,扩容 ...
- 浅析Java源码之HttpServlet
纯粹是闲的,在慕课网看了几集的Servlet入门,刚写了1个小demo,就想看看源码,好在也不难 主要是介绍一下里面的主要方法,真的没什么内容啊~ 源码来源于apache-tomcat-7.0.52, ...
- 浅析Java源码之HashMap
写这篇文章还是下了一定决心的,因为这个源码看的头疼得很. 老规矩,源码来源于JRE1.8,java.util.HashMap,不讨论I/O及序列化相关内容. 该数据结构简介:使用了散列码来进行快速搜索 ...
- 浅析Java源码之Math.random()
从零自学java消遣一下,看书有点脑阔疼,不如看看源码!(๑╹◡╹)ノ""" JS中Math调用的都是本地方法,底层全是用C++写的,所以完全无法观察实现过程,Jav ...
- Java源码-集合-LinkedList
基于JDK1.8.0_191 介绍 LinkedList是以节点来保存数据的,不像数组在创建的时候需要申请一段连续的空间,LinkedList里的数据是可以存放在不同的空间当中,然后以内存地址作为 ...
- 浅析Java源码之HashMap外传-红黑树Treenode(已鸽)
(这篇文章暂时鸽了,有点理解不能,点进来的小伙伴可以撤了) 刚开始准备在HashMap中直接把红黑树也过了的,结果发现这个类不是一般的麻烦,所以单独开一篇. 由于红黑树之前完全没接触过,所以这篇博客相 ...
- java源码阅读LinkedList
1类签名与注释 public class LinkedList<E> extends AbstractSequentialList<E> implements List< ...
- 如何阅读Java源码 阅读java的真实体会
刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动. 源码阅读,我觉得最核心有三点:技术基础+强烈的求知欲+耐心. 说到技术基础,我打个比 ...
随机推荐
- mybatis-mapper文件介绍
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-/ ...
- Dstl Satellite Imagery Feature Detection-Data Processing Tutorial
如何读取WKT格式文件 我们找到了这些有用的包: Python - shapely.loads() R - rgeos 如何读取geojson格式文件 我们找到了这些有用的包: Python - j ...
- Java开发规范总结(两周至少看一次)
Service / DAO 层方法命名规约: 1 ) 获取单个对象的方法用 get 做前缀.2 ) 获取多个对象的方法用 list 做前缀.3 ) 获取统计值的方法用 count 做前缀.4 ) 插 ...
- django的admin或者应用中使用KindEditor富文本编辑器
由于django后台管理没有富文本编辑器,看着好丑,展示出来的页面不美观,无法做到所见即所得的编辑方式,所以我们需要引入第三方富文本编辑器. 之前找了好多文档已经博客才把这个功能做出来,有些博客虽然写 ...
- [原创]MinHook测试与分析(x64下 E9,EB,CALL指令测试,且逆推测试微软热补丁)
依稀记得第一次接触Hook的概念是在周伟民先生的书中-><<多任务下的数据结构与算法>>,当时觉得Hook很奇妙,有机会要学习到,正好近段日子找来了MiniHook,就一 ...
- 【转】开源中国上看到的一个vim的自动配置的好东西,分享下
https://www.oschina.net/p/onekey-to-vim-ide 变量有高亮,竖行上有直线定位,对python的支持效果更佳,从事C/C++开发的程序员使用也不错.
- Codevs1380没有上司的舞会_KEY
没有上司的舞会 1380 没有上司的舞会 时间限制: 1 s 空间限制: 128000 KB 题目描述 Description Ural大学有N个职员,编号为1~N.他们有从属关系,也就是说他们的关系 ...
- 进入css3动画世界(二)
进入css3动画世界(二) 今天主要来讲transition和transform入门,以后会用这两种属性配合做一些动效. 注:本文面向前端css3动画入门人员,我对这个也了解不深,如本文写的有纰漏请指 ...
- 《深入理解Java虚拟机》读书笔记-垃圾收集器与内存分配策略
在堆里存放着java世界中几乎所有的对象实例,垃圾收集器在对堆进行回收前需要知道哪些对象还存活,哪些对象已经死去.那怎么样去判断对象是否存活呢? 一.判断对象是否存活算法 1.引用计数法 实现思路:给 ...
- 使用javaAPI操作hdfs
欢迎到https://github.com/huabingood/everyDayLanguagePractise查看源码. 一.构建环境 在hadoop的安装包中的share目录中有hadoop所有 ...