java基础系列(三)---HashMap
java基础解析系列(三)---HashMap
java基础解析系列
- java基础解析系列(一)---String、StringBuffer、StringBuilder
- java基础解析系列(二)---Integer
- java基础解析系列(三)---HashMap
- 这是我的博客目录,欢迎阅读
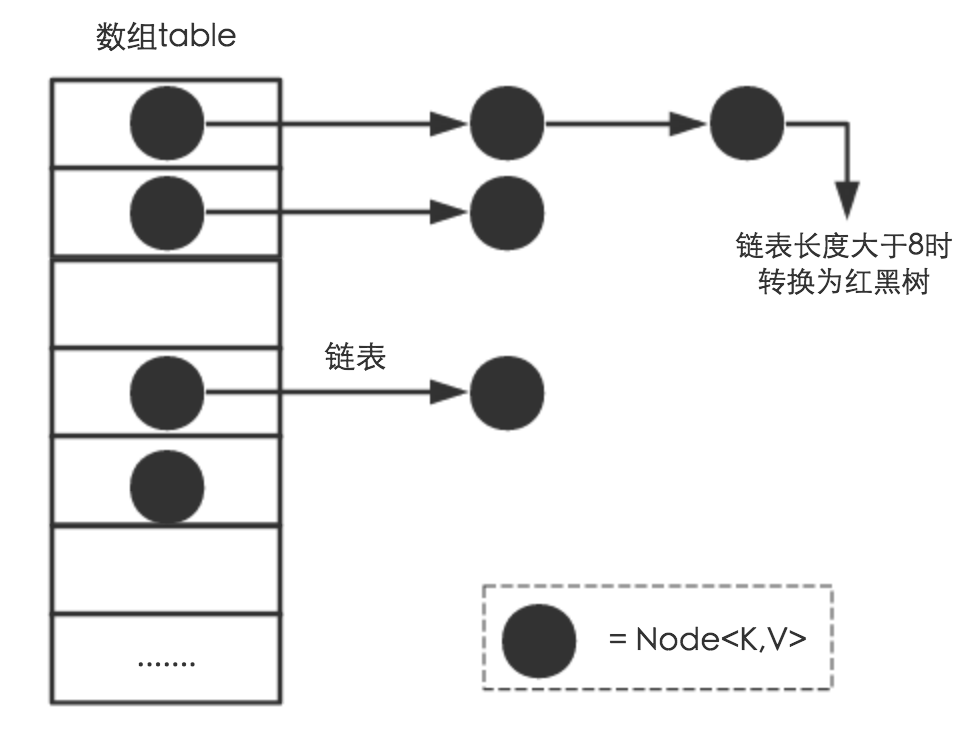
基本概念
- 节点:
Node<Key,Value>,存放key和value
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
}
- 键值对数组:
Node<K,V>[] table - 加载因子
- 容量 :Node数组的长度
- 大小:hashmap存放的Node的数目
- 阈值:容量*加载因子
工作原理
- 创建一个长度为2的次幂的node数组
- put的时候,计算key的hash值,将hash值与长度-1进行与运算
- 如果数组该下标的位置为空,直接存放,如果不为空,判断节点是否为树节点,如果是的话按红黑树的方式存入,否则按照链表的形式存入
- 当hashmap的节点数目大于阈值的时候,将会重新构造hashmap,而这种操作是费时的操作,所以建议初始化一个合适的容量
域
- 默认容量,2的四次方
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
- 默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
- node 数组
transient Node<K,V>[] table;
- 键值对数目,不是table的长度
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
- 阈值
/**
* The next size value at which to resize (capacity * load factor).
*
* @serial
*/
//阈值
int threshold;
- 加载因子
/**
* The load factor for the hash table.
*
* @serial
*/
//加载因子
final float loadFactor;
构造方法
- 传入初始容量和加载因子
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
- 传入初始容量,使用默认的加载因子
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
- 无参数,默认容量和加载因子
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
)
- 容量必须是2的n次方,当你传入的参数不符合条件,会有方法找到一个大于这个参数的最小的2的n次方数(比如大于6的最小2的n次幂是8),
put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
- 直接用伪代码表示
put()
{
index=[hash(key)&(captity-1)]----下标的最大值为captity-1,进行与运算后最终的结果小于等于最大下标
if(table[index])==null)
直接添加node
else
{
if(p是treenode)
{
直接将节点添加到红黑树
}
else
{
如果不是红黑树是链表
if(p的键值==key)
覆盖value
else
{
遍历链表:
{
if(有对应的key)
{
覆盖value
break;
}
}
遍历完成后没有发现对应的key
{
添加到链表
if(链表长度>8)
{
将链表转化为红黑树
}
}
}
}
if(大小大于阈值)
{
容量加倍,重新构造
}
}
}
get方法
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//如果链表的第一个节点是的键和要查找的键相等,那么返回该node
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//如果不是的,看该节点是不是树节点,是的话,用树的方法查找节点,如果不是的按链表的方式查找
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
为什么长度设置为2的n次方
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
- 存放node到table数组的时候,他的下标是通过(n-1)&hash计算出来的(数组长度-1 和 key的hash的值相与,最后结果小于等于长度-1),n为table的长度。
- 当长度为2的n次幂的时候,(n-1)&hash==hash%n,而前者是位运算,速度会快很多
负载因子
- 负载因子较大,说明阈值较大,也就意味着可能发生更多的冲突
- 负载因子较小,说明阈值较小,也就意味着可能会更少的冲突
- 发生冲突的时候,会降低hashmap的查找速度,所以当要求更少的内存的时候可以增加负载因子,当要求更高的查找速度的时候,可以减少负载因子。
- 默认的参数是平衡的选择,所以不建议修改
我觉得分享是一种精神,分享是我的乐趣所在,不是说我觉得我讲得一定是对的,我讲得可能很多是不对的,但是我希望我讲的东西是我人生的体验和思考,是给很多人反思,也许给你一秒钟、半秒钟,哪怕说一句话有点道理,引发自己内心的感触,这就是我最大的价值。(这是我喜欢的一句话,也是我写博客的初衷)
作者:jiajun 出处: http://www.cnblogs.com/-new/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。如果觉得还有帮助的话,可以点一下右下角的【推荐】,希望能够持续的为大家带来好的技术文章!想跟我一起进步么?那就【关注】我吧。
java基础系列(三)---HashMap的更多相关文章
- java‘小秘密’系列(三)---HashMap
java'小秘密'系列(三)---HashMap java基础系列 java'小秘密'系列(一)---String.StringBuffer.StringBuilder java'小秘密'系列(二)- ...
- java基础回顾(三)——HashMap与HashTable
public class Hashtable extends Dictionary implements Map, Cloneable, java.io.Serializable public cla ...
- java基础解析系列(三)---HashMap
java基础解析系列(三)---HashMap java基础解析系列 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析系列(二)-- ...
- Java基础系列--HashMap(JDK1.8)
原创作品,可以转载,但是请标注出处地址:https://www.cnblogs.com/V1haoge/p/10022092.html Java基础系列-HashMap 1.8 概述 HashMap是 ...
- Java基础系列-Collector和Collectors
原创作品,可以转载,但是请标注出处地址:https://www.cnblogs.com/V1haoge/p/10748925.html 一.概述 Collector是专门用来作为Stream的coll ...
- 夯实Java基础系列1:Java面向对象三大特性(基础篇)
本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 [https://github.com/h2pl/Java-Tutorial](https: ...
- Java基础系列-ArrayList
原创文章,转载请标注出处:<Java基础系列-ArrayList> 一.概述 ArrayList底层使用的是数组.是List的可变数组实现,这里的可变是针对List而言,而不是底层数组. ...
- Java基础系列-二进制操作
原创文章,转载请标注出处:<Java基础系列-二进制操作> 概述 Java源码中涉及到大量的二进制操作,非常的复杂,但非常的快速. Java二进制表示法 首先了解下二进制,二进制是相对十进 ...
- Java基础系列-equals方法和hashCode方法
原创文章,转载请标注出处:<Java基础系列-equals方法和hashCode方法> 概述 equals方法和hashCode方法都是有Object类定义的. publi ...
随机推荐
- matlab图片清晰度调整
打开.fig文件后: 1.首先设置窗口中的文字大小和相关的图例 2.然后将窗口缩小到要在word中或者ppt中展示图片的大小(避免图片缩小减少清晰度) 3.调整横纵坐标说明,使得布局合理 4.点击Ei ...
- 【jquery】获取元素高度
1. $("#div_id").height(); // 获得的是该div本身的高度, (不包含padding,margin,border)2. $("#div_id&q ...
- 网关(Gatesvr) 设计(1)
Gate解决的问题: 1.用户在服务端的实例可以在不同的进程中,也可以移动到同一个进程中.2.用户只需要与服务端建立有限条连接,即可以访问到任意服务进程.这个连接的数量不会随服务进程的数量增长而线性增 ...
- Java curator操作zookeeper获取kafka
Java curator操作zookeeper获取kafka Curator是Netflix公司开源的一个Zookeeper客户端,与Zookeeper提供的原生客户端相比,Curator的抽象层次更 ...
- jsp页面中某个src,如某个iframe的src,应该填写什么?可以是html、jsp、servlet、action吗?是如何加载的?
jsp页面中某个src,如某个iframe的src,应该填写什么?可以是html.jsp.servlet.action吗?是如何加载的? 如有个test工程,其某个jsp中有个iframe,代码如下: ...
- Spring @Transactional 使用
Spring @Transactional是Spring提供的一个声明式事务,对代码的侵入性比较小,只需考虑业务逻辑,不需要把事务和业务搞混在一起. @Transactional 可以注解在inter ...
- swift UITextField光标聚焦以及光标颜色修改
光标聚焦闪烁: nick_textField.becomeFirstResponder() 光标颜色修改 nick_textField.tintColor = UIColor.red 备份:http: ...
- NYOJ--19--next_permutation()--擅长排列的小明
/* Name: NYOJ--19--擅长排列的小明 Date: 20/04/17 11:06 Description: 这道题可以DFS,然而用next_permutation更简单些 主要是全排列 ...
- javaWeb学习之tomcat服务器
一.web a) web结构 b) 常见的服务器 WebLogic: orcale公司的产品,支持JAVAEE规范,收费 WebsphereAS: IBM公司的产品 ,支持 ...
- SqQueue(环状队列(顺序表结构))
template<typename ElemType> class SqQueue { protected: int count; int front,rear; int maxSize; ...