day10--协成\异步IO\缓存
协成(Gevent)
协程,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程。CPU只认识线程。
协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此:
协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态,换种说法:进入上一次离开时所处逻辑流的位置。
协程的好处:
1.无需线程上下文切换的开销;
2.无需原子操作锁定及同步的开销;
"原子操作(atomic operation)是不需要synchronized",所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch (切换到另一个线程)。原子操作可以是一个步骤,也可以是多个操作步骤,但是其顺序是不可以被打乱,或者切割掉只执行部分。视作整体是原子性的核心。改变量即可称为简单原子操作。协成是在单线程里面实现的。同一时间只有一个线程。
3.方便切换控制流,简化编程模型;
4.高并发+高扩展性+低成本:一个CPU支持上万的协程都不是问题。所以很适合用于高并发处理。
缺点:
1.无法利用多核资源:协程的本质是个单线程,它不能同时将单个CPU的多个核用上,协程需要和进程配合才能运行在多CPU上.当然我们日常所编写的绝大部分应用都没有这个必要,除非是cpu密集型应用;Ngix只有一个进程,一个进程里面只有一个线程。
2.进行阻塞(Blocking)操作(如IO时)会阻塞掉整个程序;
使用yield实现协程操作例子
import time
import queue def consumer(name):
print("--->starting eating baozi...")
while True:
new_baozi = yield
print("[%s] is eating baozi %s" % (name, new_baozi))
# time.sleep() def producer():
r = con.__next__()
r = con2.__next__()
n =
while n < :
n +=
con.send(n)
con2.send(n)
print("\033[32;1m[producer]\033[0m is making baozi %s" % n) if __name__ == '__main__':
con = consumer("c1")
con2 = consumer("c2")
p = producer()
看楼上的例子,我问你这算不算做是协程呢?你说,我他妈哪知道呀,你前面说了一堆废话,但是并没告诉我协程的标准形态呀,我腚眼一想,觉得你说也对,那好,我们先给协程一个标准定义,即符合什么条件就能称之为协程:
1.必须在只有一个单线程里实现并发;
2.修改共享数据不需加锁;
3.用户程序自己保存多个控制流的上下文栈;
4.一个协成遇到IO操作自动切换到其它协成。
基于上面这4点定义,我们刚才用yield实现的程并不能算是合格的线程,因为它有一点功能没实现,哪一点呢?
Greenlet
greenlet是一个用C实现的协程模块,相比与python自带的yield,它可以使你在任意函数之间随意切换,而不需把这个函数先声明为generator
from greenlet import greenlet def test1():
print()
gr2.switch()
print()
gr2.switch() def test2():
print()
gr1.switch()
print() gr1 = greenlet(test1) #启动一个协成
gr2 = greenlet(test2)
gr1.switch() #切换,手动切换
上面代码执行结果如下:
上面代码中,greenlet模块,greenlet类中,主要实现不同方法之间的切换,让程序能上下文进行切换,switch()转换。gr1.switch()。
协成是遇到IO操作进行切换。做事需要花费时间过长,比如从数据库获取数据等等。协成也是串行的,只是在IO操作之间进行切换。来回在IO操作之间切换。
Gevent是自动切换,封装了greenlet,greenlet还是手动切换,通过switch()手动切换。而Gevent就是自动切换。
Gevent
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
下面我们来看一个协成的实例,如下:
'''协成:微线程,主要作用是遇到IO操作就切换,程序本身就串行的,主要是在各个IO直接来回切换,节省时间'''
import gevent def fun():
print("In the function fun!!!\n") #(1)
gevent.sleep() #IO阻塞,也可以是具体执行一个操作,这里直接等待
print("\033[31mCome back to the function of fun again!\033[0m\n") #(6) def inner():
'''定义一个函数,包含IO阻塞'''
print("Running in the function of inner!!!\n") #(2)
gevent.sleep() #触发切换,遇到gevent.sleep()触发切换,执行后面代码。
print("\033[32mRunning back to the function of inner\033[0m\n") #(5) def outer():
'''定义一个函数,也包含IO阻塞'''
print("周末去搞基把,带上%s\n" %"alex") #(3)
gevent.sleep(0.5)
print("不好吧,%s是人妖,不好那口,还是带上配齐把!!!" %"alex") #(4) gevent.joinall([
gevent.spawn(fun),
gevent.spawn(inner),
gevent.spawn(outer),
])
上面代码执行结果如下:
In the function fun!!! Running in the function of inner!!! 周末去搞基把,带上alex 不好吧,alex是人妖,不好那口,还是带上配齐把!!!
Running back to the function of inner Come back to the function of fun again!
上面程序中,使用的是协成,我们可以看出,协成遇到IO操作是阻塞的,协成是在串行情况下实现了多并发或异步的效果,整个程序串行执行的话需要至少花费3.5秒,而使用协成花费:2.0312681198120117,可见如果有IO阻塞,协成能够有效降低程序运行的时间。
gevent.spawn(outer,"alex","wupeiqi"),gevent.spawn()里面加参数的情况,第一个是函数名,后面加引号是参数。让协成等待的方法是gevent.sleep(time),让协成等待,gevent.sleep(),而不是time.sleep(),如果是time.sleep()是不会切换的,gevent.sleep()才会切换。如果是time.sleep(2)秒,是不会切换的,程序将变成串行。执行最长的IO。
如何判断是IO操作,这个很重要,因为我在自己尝试的时候,time.sleep(2)是不算IO操作的。不会发生切换。
上面我们使用gevent.sleep()来判断IO操作切换,使用time.sleep()是不行的,程序还是串行的,如何让程序知道time.sleep()是IO操作呢?要打上一个补丁,from gevent import monkey 并且声明:monkey.patch_all(),这样程序就会自动检测IO操作,程序就变成串行的了,如下所示:
'''协成:微线程,主要作用是遇到IO操作就切换,程序本身就串行的,主要是在各个IO直接来回切换,节省时间'''
import gevent,time
from gevent import monkey monkey.patch_all() #把当前程序的所有的IO操作给单独的做上标记
def fun():
print("In the function fun!!!\n")
time.sleep() #IO阻塞,也可以是具体执行一个操作,这里直接等待
print("\033[31mCome back to the function of fun again!\033[0m\n") def inner():
'''定义一个函数,包含IO阻塞'''
print("Running in the function of inner!!!\n")
time.sleep()
print("\033[32mRunning back to the function of inner\033[0m\n") def outer(name,arg):
'''定义一个函数,也包含IO阻塞'''
print("周末去搞基把,带上%s\n" %name)
time.sleep(0.5)
print("不好吧,%s是人妖,不好那口,还是带上%s!!!" %(name,arg)) start_time = time.time()
gevent.joinall([
gevent.spawn(fun),
gevent.spawn(inner),
gevent.spawn(outer,"alex","wupeiqi"),
])
end_time = time.time()
print("花费时间:%s" %(end_time -start_time))
上面程序的执行结果如下:
In the function fun!!! Running in the function of inner!!! 周末去搞基把,带上alex 不好吧,alex是人妖,不好那口,还是带上wupeiqi!!!
Running back to the function of inner Come back to the function of fun again! 花费时间:2.0013585090637207
可见,打上补丁之后,from gevent import monkey,声明monkey.patch_all()就能让程序自动检测哪些是IO操作,不需要自己注明。
下面,我们用协成来简单爬取一下网页,如下:
import gevent,time
from urllib.request import urlopen
'''导入urllib模块中的urlopen用来打开网页''' def func(url):
print("\033[31m----------------------并发的爬取未网页---------------------------\033[0m")
resp = urlopen(url) #使用urlopen打开一个网址
data = resp.read() #读取网页里面的内容
with open("alex.html",'wb') as f:
f.write(data)
print("%s个字节被下载,从网页%s。" %(len(data),url)) # if __name__ == "__mian__":
start_time = time.time()
gevent.joinall([
gevent.spawn(func,"https://www.cnblogs.com/alex3714/articles/5248247.html"),
gevent.spawn(func,"https://www.python.org/"),
gevent.spawn(func,"https://www.jd.com/")
])
end_time = time.time()
cost_time = end_time - start_time
print("cost time:%s" %cost_time)
执行结果如下:
----------------------并发的爬取未网页---------------------------
91829个字节被下载,从网页https://www.cnblogs.com/alex3714/articles/5248247.html。
----------------------并发的爬取未网页---------------------------
48721个字节被下载,从网页https://www.python.org/。
----------------------并发的爬取未网页---------------------------
124072个字节被下载,从网页https://www.jd.com/。
cost time:18.932090044021606
从上面结果可以看出,程序肯定是串行执行的,因为是先爬取第一个网页,爬取完了才爬取第二个网页,异步肯定不是这样,为什么会这样呢?因为urllib是被检测不到进行了urllib的,要想gevent检测到urllib,必须进行声明,让gevent能够自动检测到IO操作,from gevent import monkey,mokdey.patch_all()(把当前程序的所有的IO操作给我单独的做上标记,让程序检测到所有有可能进行IO操作的,打一个标记)。下面我们来给上面程序加上标记:
遇到IO阻塞时会自动切换任务:
import gevent,time
from urllib.request import urlopen
from gevent import monkey
monkey.patch_all()
'''导入urllib模块中的urlopen用来打开网页''' def func(url):
print("\033[31m----------------------并发的爬取未网页---------------------------\033[0m")
resp = urlopen(url) #使用urlopen打开一个网址
data = resp.read() #读取网页里面的内容
with open("alex.html",'wb') as f:
f.write(data)
print("%s个字节被下载,从网页%s。" %(len(data),url)) # if __name__ == "__mian__":
start_time = time.time()
gevent.joinall([
gevent.spawn(func,"https://www.cnblogs.com/alex3714/articles/5248247.html"),
gevent.spawn(func,"https://www.python.org/"),
gevent.spawn(func,"https://www.jd.com/")
])
end_time = time.time()
cost_time = end_time - start_time
print("cost time:%s" %cost_time)
代码执行结果如下:
----------------------并发的爬取未网页---------------------------
----------------------并发的爬取未网页---------------------------
----------------------并发的爬取未网页---------------------------
124072个字节被下载,从网页https://www.jd.com/。
91829个字节被下载,从网页https://www.cnblogs.com/alex3714/articles/5248247.html。
48721个字节被下载,从网页https://www.python.org/。
cost time:1.7704188823699951
可以看出,给程序加上能够自动识别IO操作的标记之后,爬虫的时间少了很多,串行需要18秒,现在只需不到2秒,节约了很多时间,这就是异步的效率。
通过gevent实现单线程下的多socket并发
下面我们用协成来写一个socket多并发的实例,如下:
server
import sys
import socket
import time
import gevent from gevent import socket,monkey
monkey.patch_all() def server(port):
s = socket.socket()
s.bind(('0.0.0.0', port))
s.listen()
while True:
cli, addr = s.accept()
gevent.spawn(handle_request, cli) #在连接之后启动一个协成,socket中启动的是一个线程。 def handle_request(conn):
try:
while True:
data = conn.recv()
print("recv:", data)
conn.send(data)
if not data:
conn.shutdown(socket.SHUT_WR) except Exception as ex:
print(ex)
finally:
conn.close()
if __name__ == '__main__':
server()
Client
import socket HOST = 'localhost' # The remote host
PORT = # The same port as used by the server
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((HOST, PORT))
while True:
msg = bytes(input(">>:"),encoding="utf8")
s.sendall(msg)
data = s.recv()
#print(data) print('Received', repr(data))
s.close()
其实使用协成就能实现异步的操作,在socket中,正常要想使用多并发,要使用socketserver,但是这里我们使用协成就能实现多并发的情况,gevent.spawn(function,parameter)
协成是如何切换会IO操作之前的位置。
论事件驱动与异步IO
通常,我们写服务器处理模型的程序时,有以下几种模型:
(1)每收到一个请求,创建一个新的进程,来处理该请求;
(2)每收到一个请求,创建一个新的线程,来处理该请求;
(3)每收到一个请求,放入一个事件列表,让主进程通过非阻塞I/O方式来处理请求;(以事件驱动的模式)
上面的几种方式,各有千秋,
第(1)中方法,由于创建新的进程的开销比较大,所以,会导致服务器性能比较差,但实现比较简单。
第(2)种方式,由于要涉及到线程的同步,有可能会面临死锁等问题。
第(3)种方式,在写应用程序代码时,逻辑比前面两种都复杂。
综合考虑各方面因素,一般普遍认为第(3)种方式是大多数网络服务器采用的方式
看图说话讲事件驱动模型
在UI编程中,常常要对鼠标点击进行相应,首先如何获得鼠标点击呢?
方式一:创建一个线程,该线程一直循环检测是否有鼠标点击,那么这个方式有以下几个缺点:
1. CPU资源浪费,可能鼠标点击的频率非常小,但是扫描线程还是会一直循环检测,这会造成很多的CPU资源浪费;如果扫描鼠标点击的接口是阻塞的呢?
2. 如果是堵塞的,又会出现下面这样的问题,如果我们不但要扫描鼠标点击,还要扫描键盘是否按下,由于扫描鼠标时被堵塞了,那么可能永远不会去扫描键盘;
3. 如果一个循环需要扫描的设备非常多,这又会引来响应时间的问题;
所以,该方式是非常不好的。
方式二:就是事件驱动模型
目前大部分的UI编程都是事件驱动模型,如很多UI平台都会提供onClick()事件,这个事件就代表鼠标按下事件。事件驱动模型大体思路如下:
1. 有一个事件(消息)队列;
2. 鼠标按下时,往这个队列中增加一个点击事件(消息);
3. 有个循环,不断从队列取出事件,根据不同的事件,调用不同的函数,如onClick()、onKeyDown()等;
4. 事件(消息)一般都各自保存各自的处理函数指针,这样,每个消息都有独立的处理函数;
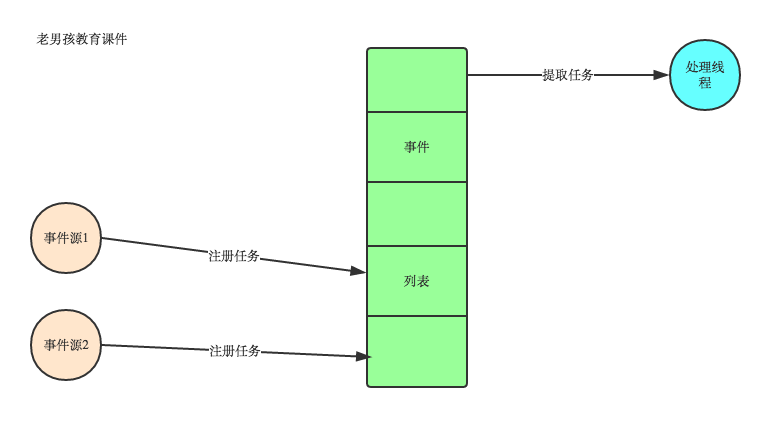
事件驱动编程是一种编程范式,这里程序的执行流由外部事件来决定。它的特点是包含一个事件循环,当外部事件发生时使用回调机制来触发相应的处理。另外另种常见编程范式是(单线程)同步以及多线程编程。
让我们用例子来比较和对比一下单线程、多线程以及事件驱动编程模型。下图展示了随着时间的推移,这三种模式下程序所做的工作。这个程序有3个任务需要完成,每个任务都在等待I/O操作时阻塞自身。阻塞在I/O操作上所花费的时间已经用灰色框标示出来了。

上图中,灰色部分是IO阻塞。
在单线程同步模型中,任务按照顺序执行。如果某个任务因为I/O而阻塞,其他所有的任务都必须等待,直到它完成之后它们才能依次执行。这种明确的执行顺序和串行化处理的行为是很容易推断得出的。如果任务之间并没有互相依赖的关系,但仍然需要互相等待的话这就使得程序不必要的降低了运行速度。
在多线程版本中,这3个任务分别在独立的线程中执行。这些线程由操作系统来管理,在多处理器系统上可以并行处理,或者在单处理器系统上交错执行。这使得当某个线程阻塞在某个资源的同时其他线程得以继续执行。与完成类似功能的同步程序相比,这种方式更有效率,但程序员必须写代码来保护共享资源,防止其被多个线程同时访问。多线程程序更加难以推断,因为这类程序不得不通过线程同步机制如锁、可重入函数、线程局部存储或者其他机制来处理线程安全问题,如果实现不当就会导致出现微妙且令人痛不欲生的bug。
在事件驱动版本的程序中,3个任务交错执行,但仍然在一个单独的线程控制中。当处理I/O或者其他昂贵的操作时,注册一个回调到事件循环中,然后当I/O操作完成时继续执行。回调描述了该如何处理某个事件。事件循环轮询所有的事件,当事件到来时将它们分配给等待处理事件的回调函数。这种方式让程序尽可能的得以执行而不需要用到额外的线程。事件驱动型程序比多线程程序更容易推断出行为,因为程序员不需要关心线程安全问题。
IO操作识别是通过事件驱动来实现的,一遇到IO操作。
当我们面对如下的环境时,事件驱动模型通常是一个好的选择:
- 程序中有许多任务,而且…
- 任务之间高度独立(因此它们不需要互相通信,或者等待彼此)而且…
- 在等待事件到来时,某些任务会阻塞。
当应用程序需要在任务间共享可变的数据时,这也是一个不错的选择,因为这里不需要采用同步处理。
网络应用程序通常都有上述这些特点,这使得它们能够很好的契合事件驱动编程模型。
此处要提出一个问题,就是,上面的事件驱动模型中,只要一遇到IO就注册一个事件,然后主程序就可以继续干其它的事情了,只到io处理完毕后,继续恢复之前中断的任务,这本质上是怎么实现的呢?哈哈,下面我们就来一起揭开这神秘的面纱。。。。
Select\Poll\Epoll异步IO
http://www.cnblogs.com/alex3714/p/4372426.html
番外篇 http://www.cnblogs.com/alex3714/articles/5876749.html
IO切换实在内核里面进行。必须要copy()一下。
二 IO模式
刚才说了,对于一次IO访问(以read举例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以说,当一个read操作发生时,它会经历两个阶段:
1. 等待数据准备 (Waiting for the data to be ready)
2. 将数据从内核拷贝到进程中 (Copying the data from the kernel to the process)
正式因为这两个阶段,linux系统产生了下面五种网络模式的方案。
- 阻塞 I/O(blocking IO)
- 非阻塞 I/O(nonblocking IO)
- I/O 多路复用( IO multiplexing)
- 信号驱动 I/O( signal driven IO)
- 异步 I/O(asynchronous IO)
注:由于signal driven IO在实际中并不常用,所以我这只提及剩下的四种IO Model。
非阻塞(nonblocking IO)的特点是用户进程需要不断的主动询问kernel数据好了没有。
I/O 多路复用(IO multiplexing)就是我们说的select,poll,epoll,有些地方也称这种IO方式为event driven IO。select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。
server.setblocking(0)是设置socket非阻塞,默认是server.setblocking(True)阻塞状态。select.select(inputs,outputs,inputs)用来监听链接。select.select()用来监听,可以监听自己。inputs=[server,];readable,writeable,exceptional = select.select(inputs,outputs,inputs);
select写的多并发:
Server
'''用select写客户端和socket是差不多的,只是select用的非阻塞的IO多路复用,要设置为非阻塞状态'''
import socket,select
#select是用来监听那个链接处于活跃状态,如果是Server说明是需要建立一个新的连接,如果是conn,说明conn链接处于活动状态,可以收发数据 server = socket.socket() #设置为非阻塞状态
IP,PORT = "0.0.0.0",
server.bind((IP,PORT))
server.listen()
server.setblocking(False)
inputs = [server,] #定义一个列表,用来放置内核检测的链接
#inputs=[server,conn]有新的链接来了就放进去,让select来监测
outputs = []
'''如果有链接进来,会返回三个数据'''
flag = True
while flag: #死循环,让程序一直监听是否有新的链接过来,如果有活动
readable,writeable,exceptional = select.select(inputs,outputs,inputs) #内核用来监听连接,没有监听内容就报错,监听server
'''outputs,exceptional是放置断的链接,监听那些连接失效了,没有链接就监听自己,当活动的时候就代表有新的连接进来了'''
print(readable,writeable,exceptional)
'''[<socket.socket fd=3, family=AddressFamily.AF_INET, type=2049, proto=0, laddr=('0.0.0.0', 9998)>] [] []链接后的结果'''
'''连接上来之后,客户端就挂断了'''
for r in readable:
if r is server: #如果来了一个新连接,需要创建新链接
conn,addr = server.accept() #没有链接进来不要accept()因为是非阻塞的
print(conn,addr)
inputs.append(conn) #因为这个新建立的连接还没有发数据过来,现在就接收的话程序就报错了
'''所以要想实现这个客户端发数据来时server端能知道,就需要让select在监测这个conn,生成一个连接select就监测'''
else:
data = r.recv()
if not data:
flag = False
print("收到数据",data.decode("utf-8"))
r.send(data.upper())
Client(客户端)
import socket
client = socket.socket()
ip,port = 'localhost',
client.connect((ip,port))
while True:
mess = input(">>:").encode("utf-8").strip()
if len(mess) == :
print("发送消息不能为空!!!")
continue
client.send(mess)
data = client.recv()
print("客户端接收返回数据:%s" %data.decode("utf-8"))
select能够实现多并发的原因是select是用来监听线程的活跃状态,如果有活跃的线程,select能够监测到,那个线程处于活跃状态,就会监测那个线程,并进行数据的交换。
readable,writeable,exceptional = select.select(inputs,outputs,inputs)用来生成几种状态,监听的连接放在Inputs中。
for e in exceptional:
inputs.remove(e)
上面程序中,如果客户端断开,则会发生死循环,如何解决呢?就在select.select()中的exceptional,我们要删除活跃的链接,inputs.remove(3),就是删除活跃的链接。
selectors模块
This module allows high-level and efficient I/O multiplexing, built upon the select module primitives. Users are encouraged to use this module instead, unless they want precise control over the OS-level primitives used.
selectors模块默认是使用epoll(),如果系统不支持(Windows)则使用select()方法。
import selectors
import socket sel = selectors.DefaultSelector() def accept(sock, mask):
conn, addr = sock.accept() # Should be ready
print('accepted', conn, 'from', addr)
conn.setblocking(False)
sel.register(conn, selectors.EVENT_READ, read) def read(conn, mask):
data = conn.recv() # Should be ready
if data:
print('echoing', repr(data), 'to', conn)
conn.send(data) # Hope it won't block
else:
print('closing', conn)
sel.unregister(conn)
conn.close() sock = socket.socket()
sock.bind(('localhost', ))
sock.listen()
sock.setblocking(False)
sel.register(sock, selectors.EVENT_READ, accept) while True:
events = sel.select()
for key, mask in events:
callback = key.data
callback(key.fileobj, mask)
使用selectors模块编写的语句,epoll()方法。
day10--协成\异步IO\缓存的更多相关文章
- python 多协程异步IO爬取网页加速3倍。
from urllib import request import gevent,time from gevent import monkey#该模块让当前程序所有io操作单独标记,进行异步操作. m ...
- Python全栈开发-Day10-进程/协程/异步IO/IO多路复用
本节内容 多进程multiprocessing 进程间的通讯 协程 论事件驱动与异步IO Select\Poll\Epoll——IO多路复用 1.多进程multiprocessing Python ...
- Python 8 协程/异步IO
协程 协程,又称微线程,纤程.英文名Coroutine.一句话说明什么是线程:协程是一种用户态的轻量级线程. 协程拥有自己的寄存器上下文和栈.协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来 ...
- Python 协程/异步IO/Select\Poll\Epoll异步IO与事件驱动
1 Gevent 协程 协程,又称微线程,纤程.英文名Coroutine.一句话说明什么是线程:协程是一种用户态的轻量级线程. 协程拥有自己的寄存器上下文和栈.协程调度切换时,将寄存器上下文和栈保存到 ...
- 12.python进程\协程\异步IO
进程 创建进程 from multiprocessing import Process import time def func(name): time.sleep(2) print('hello', ...
- 线程、进程、协程 异步io
https://www.cnblogs.com/wupeiqi/articles/6229292.html
- python笔记-10(socket提升、paramiko、线程、进程、协程、同步IO、异步IO)
一.socket提升 1.熟悉socket.socket()中的省略部分 socket.socket(AF.INET,socket.SOCK_STREAM) 2.send与recv发送大文件时对于黏包 ...
- 进程&线程(三):外部子进程subprocess、异步IO、协程、分布式进程
1.外部子进程subprocess python之subprocess模块详解--小白博客 - 夜风2019 - 博客园 python subprocess模块 - lincappu - 博客园 之前 ...
- [译]Python中的异步IO:一个完整的演练
原文:Async IO in Python: A Complete Walkthrough 原文作者: Brad Solomon 原文发布时间:2019年1月16日 翻译:Tacey Wong 翻译时 ...
随机推荐
- (转)DATATABLE(DATASET)与实体类之间的互转.
转自:http://www.cnblogs.com/zzyyll2/archive/2010/07/20/1781649.html dataset和实体类 之间的转换 //dataset转实体类 代 ...
- 【BZOJ1434】[ZJOI2009]染色游戏(博弈论)
[BZOJ1434][ZJOI2009]染色游戏(博弈论) 题面 BZOJ 洛谷 题解 翻硬币的游戏我似乎原来在博客里面提到过,对于这类问题,当前局面的\(SG\)函数就是所有反面朝上的硬币单一存在时 ...
- 【POJ2631】Roads in the North 树的直径
题目大意:给定一棵 N 个节点的边权无根树,求树的直径. 代码如下 #include <cstdio> #include <algorithm> using namespace ...
- plsql批量导入sql文件
背景:有时候在两个数据库之间导入导出数据,不可避免的需要进行sql文件的批量导入,一个个导入效率太低,所以可以考虑批量导入的办法进行导入. 操作步骤 1.假设有三个sql脚本,分别为aa.sql,bb ...
- Css设置img属性让图片水平居中/居左/居右的写法
图片的居中显示css有很多方法,但在很多情况下有的方法无效,无意发现这个系统的官方处理图片居中,居左,居右的css写法,喜欢的朋友可以收藏下哦 图片的居中显示css有很多方法,但在很多情况下有的方法无 ...
- 借读:分布式锁和双写Redis
本帖最后由 howtodown 于 2016-10-3 16:01 编辑问题导读1.为什么会产生分布式锁?2.使用分布式锁的方法有哪些?3.本文创造的分布式锁的双写Redis框架都包含哪些内容? ...
- ActiveMQ基础教程----简单介绍与基础使用
概述 ActiveMQ是由Apache出品的,一款最流行的,能力强劲的开源消息总线.ActiveMQ是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现,它非常快速,支持多 ...
- spring+spring mvc+JdbcTemplate 入门小例子
大家使用这个入门时候 最好能够去 搜一下 spring mvc 的 原理,我放一张图到这里,自己琢磨下,后面去学习就容易了 给个链接 (网上一把,千万不能懒) https://www.cnblo ...
- python 基础 元组()
# 元组 应用场景 # 尽管 Python的列表中可以存储不同类型的数据 # 但是在开发中,更多的应用场景是 # 1.列表存储相同类型的数据 # 2.通过迭代遍历,在循环体内部,针对列表中的每一项元素 ...
- iOS-Socket编程体验
CHENYILONG Blog Socket编程体验 Socket编程体验 技术博客http://www.cnblogs.com/ChenYilong/新浪微博http://weibo.com/lu ...