HBase原理和架构
HBase是什么

HBase在生态体系中的位置
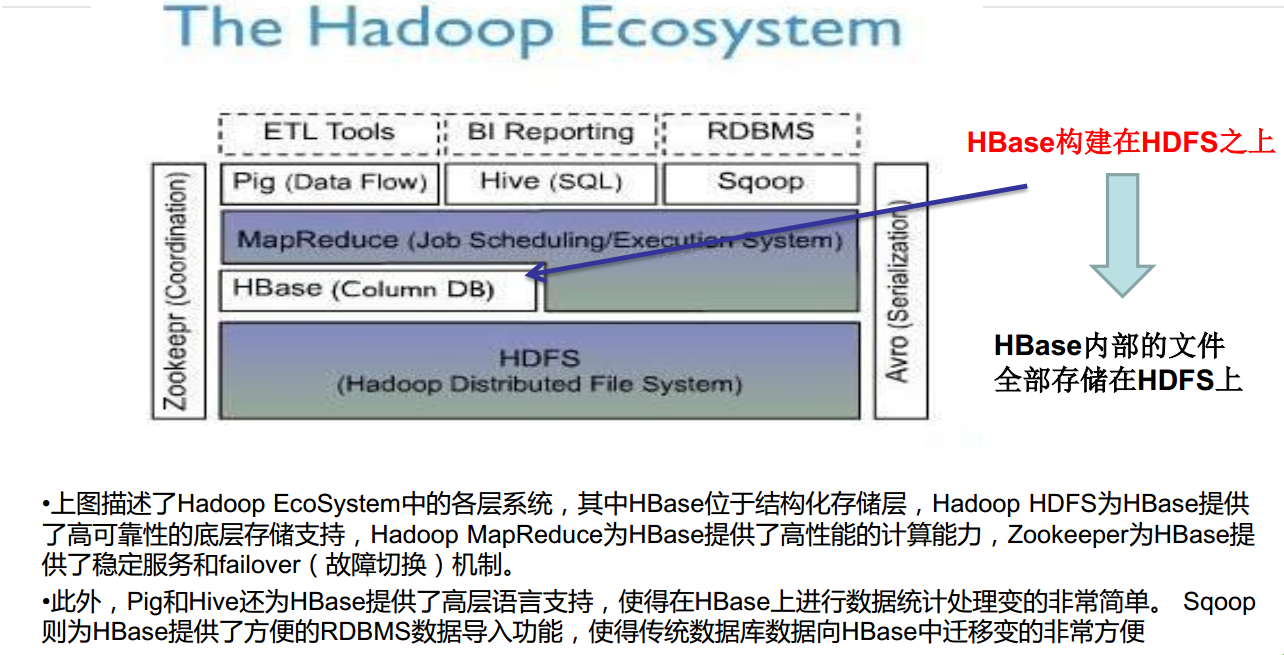
HBase vs HDFS

HBase表的特点

HBase是真正的分布式存储,存储级别达到TB级别,而才传统数据库就不是真正的分布式了,传统数据库在底层,虽然的存储能力很强,一旦达到上亿条数据。读取性能下降得很快。
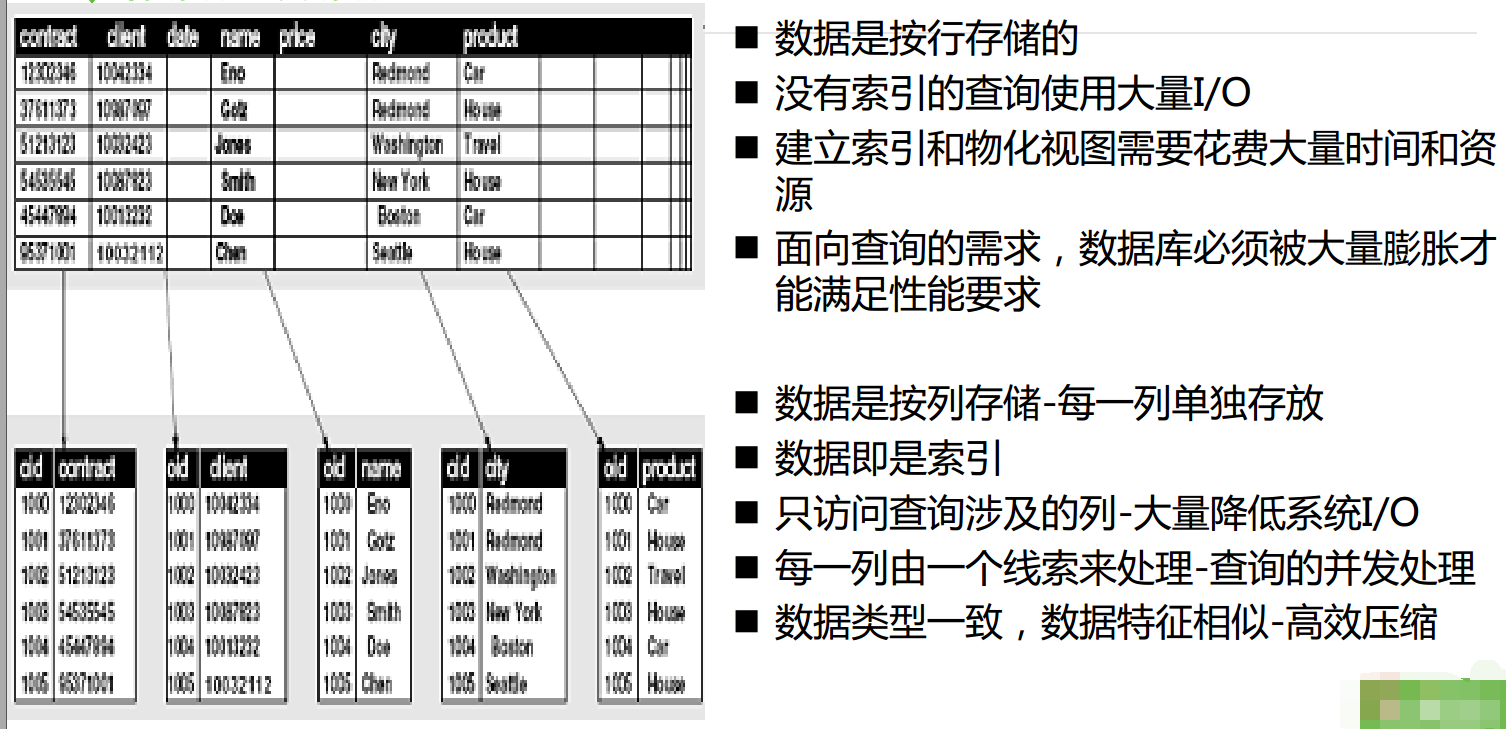
传统数据库按行存储,如果列过多的话,一行数据会非常大,HBase按列簇存储,每个列簇都存储一个文件,如果只读取某一些字段的话,只需读取对应的文件就可以了,其他的不用扫描,节省了IO。
HBase的存储每一行的内容可以不同,空出来的列不占用空间。
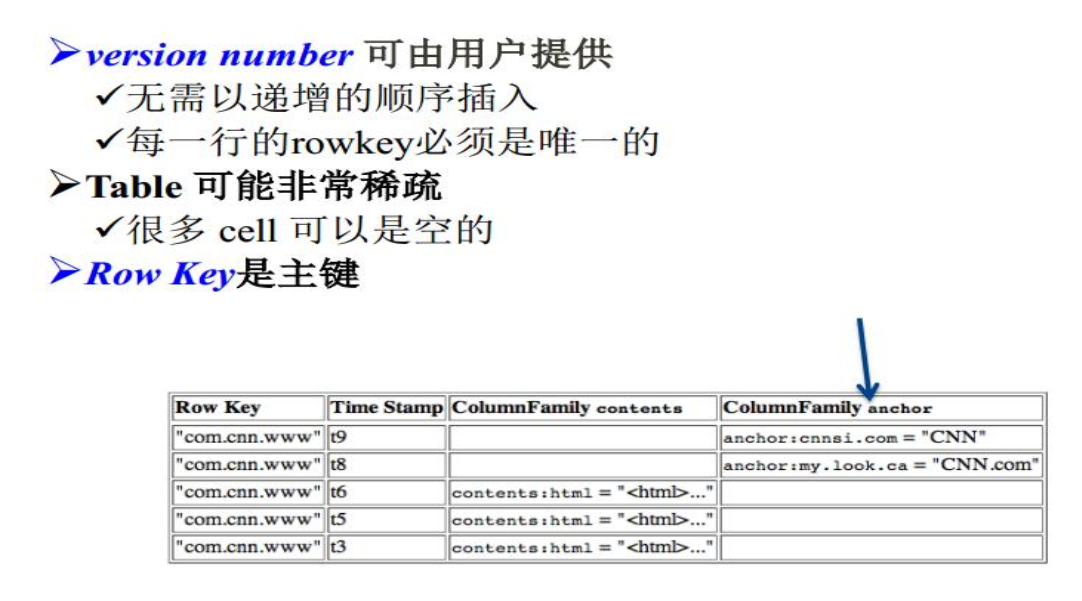
多版本,怎么理解呢,就比如说相同id的行重新插入数据不会覆盖掉,而是按照插入的时间戳分类。
行存储和列存储
02 HBase数据模型
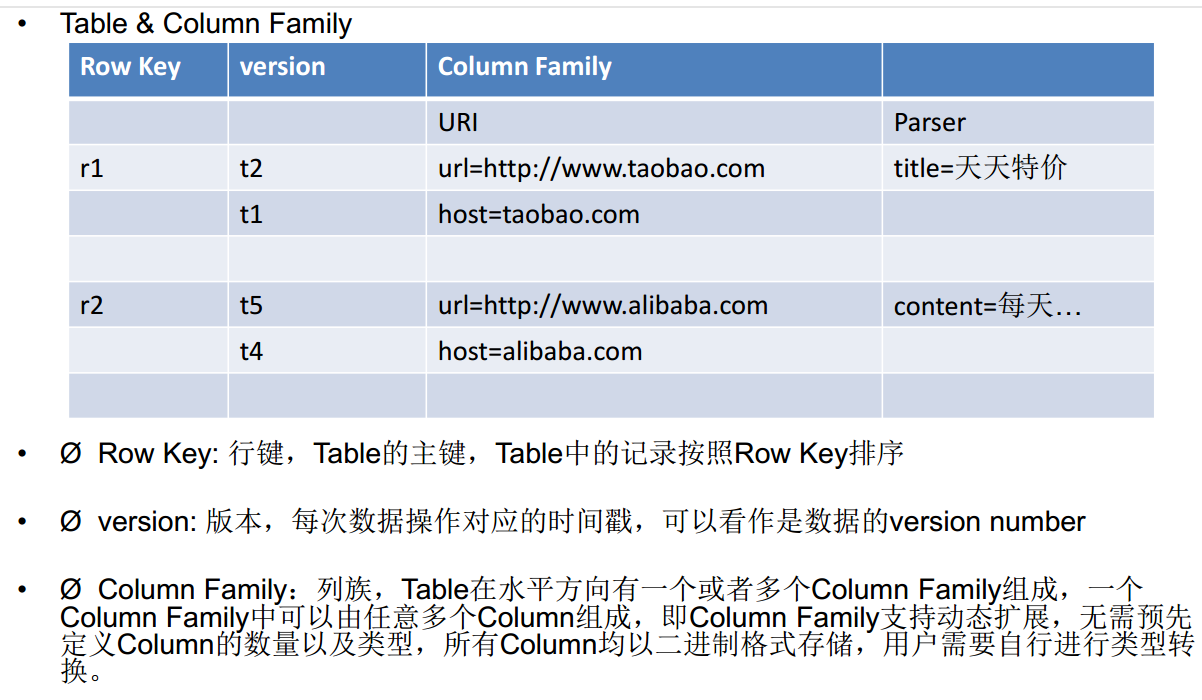
HBase逻辑视图
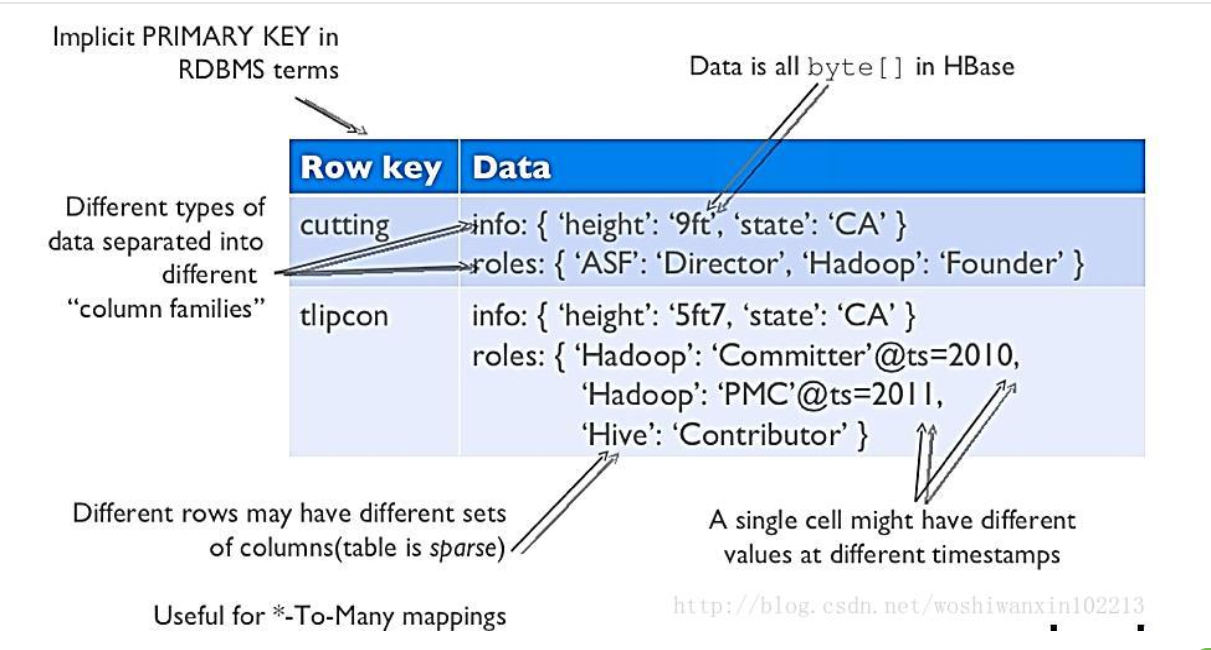
Rowkey和Column Family
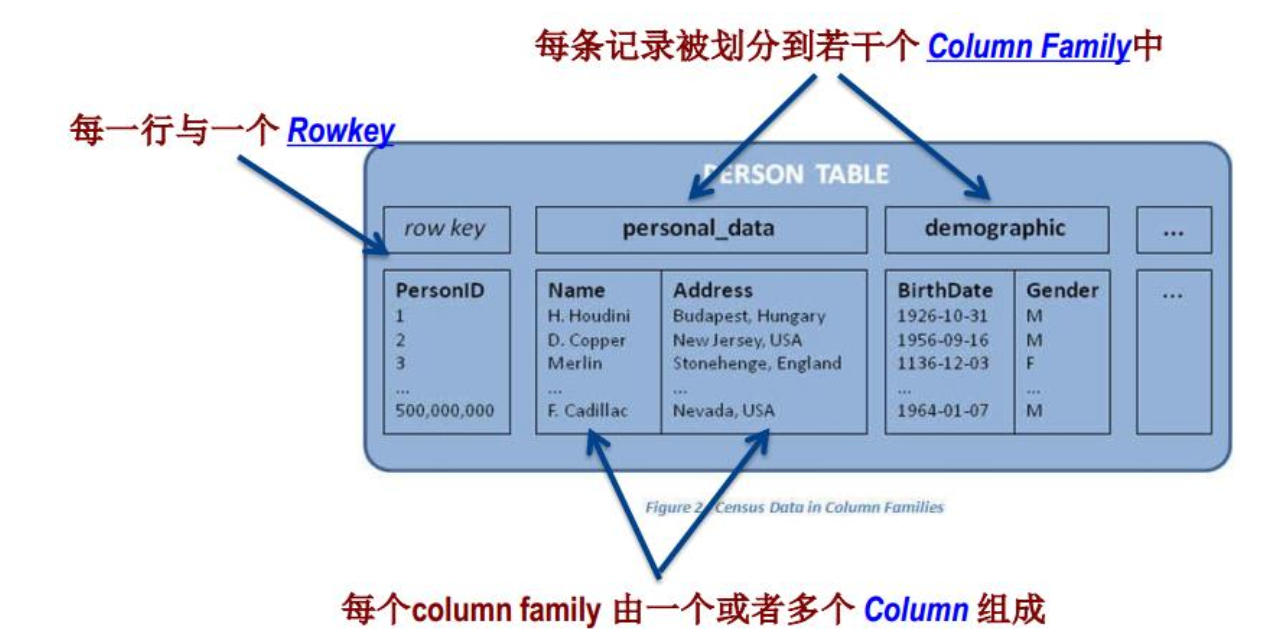
HBase数据模型

HBase支持的操作

03 HBase物理模型

传统数据库和HBase的存储的不同


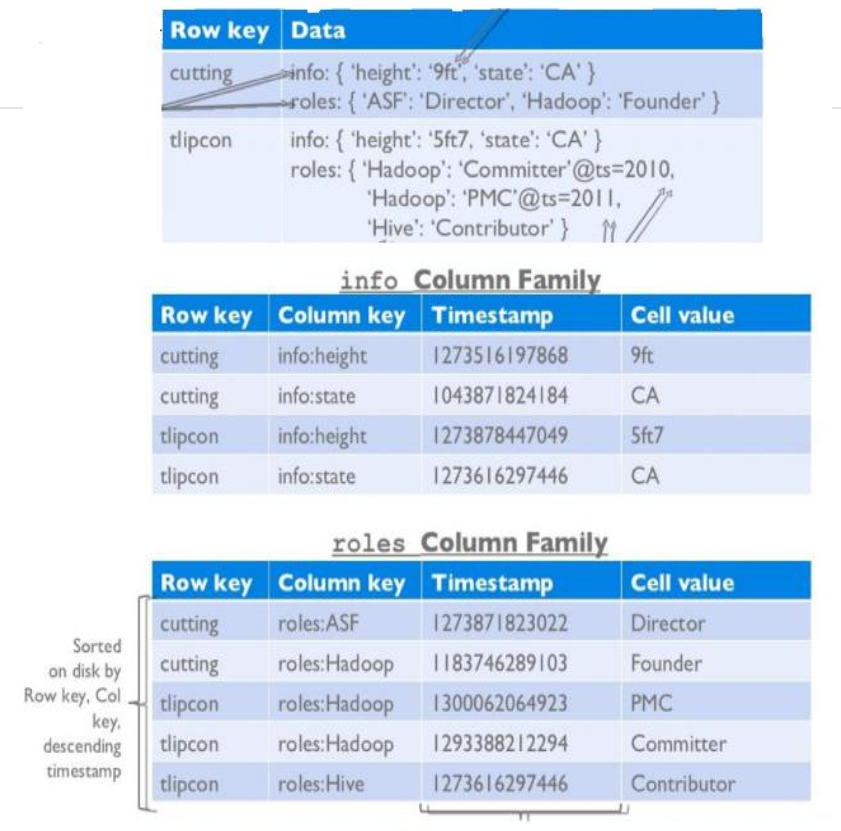
物理存储
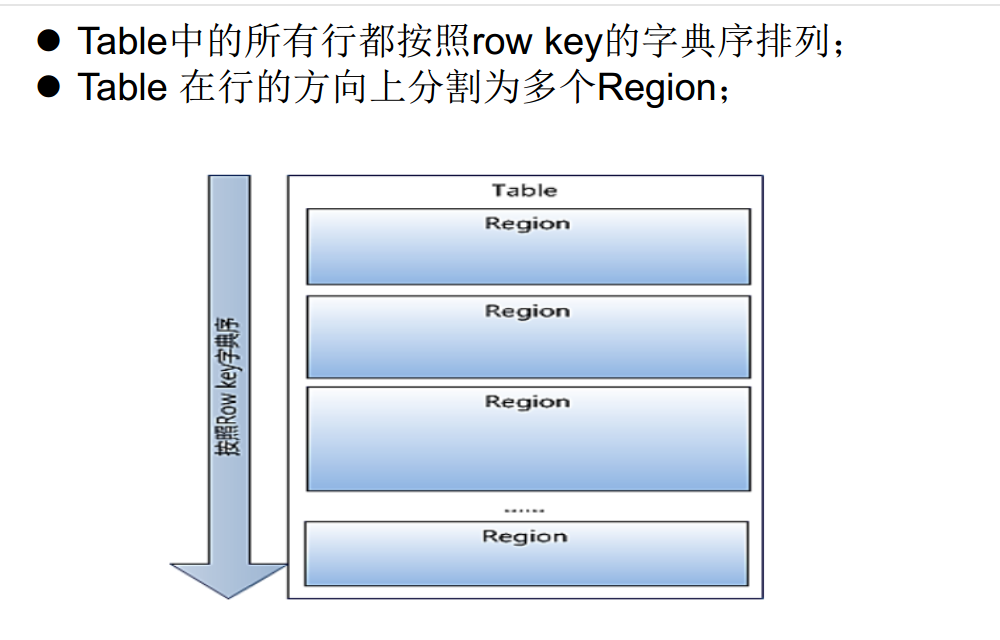
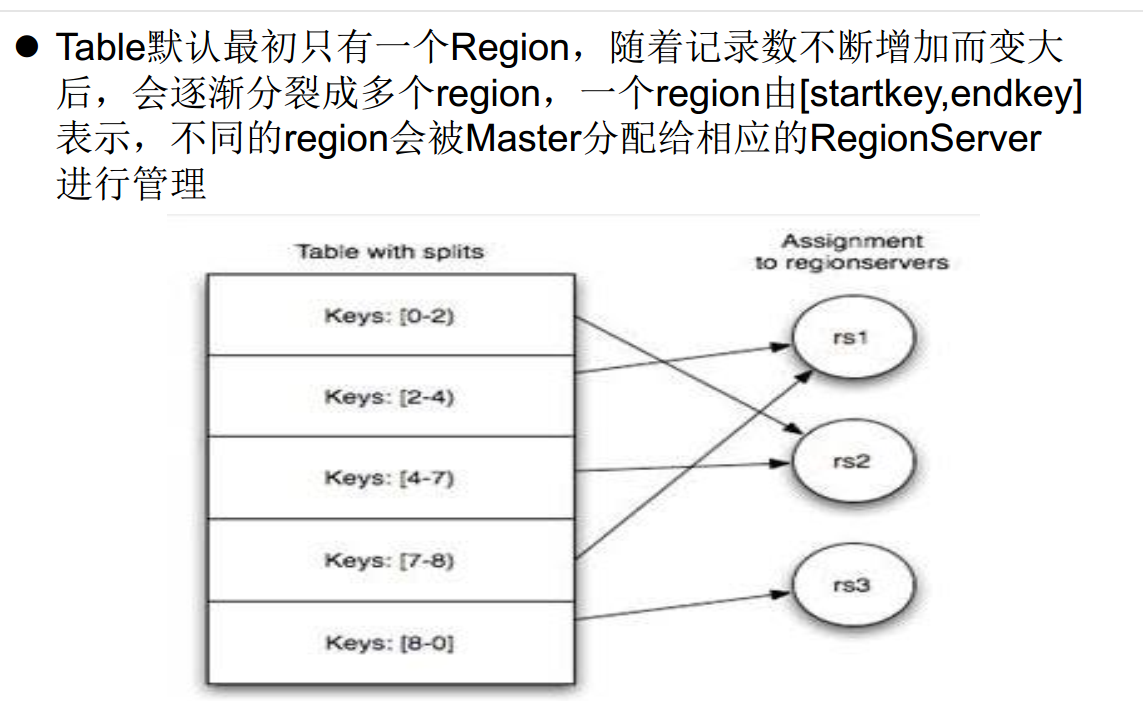
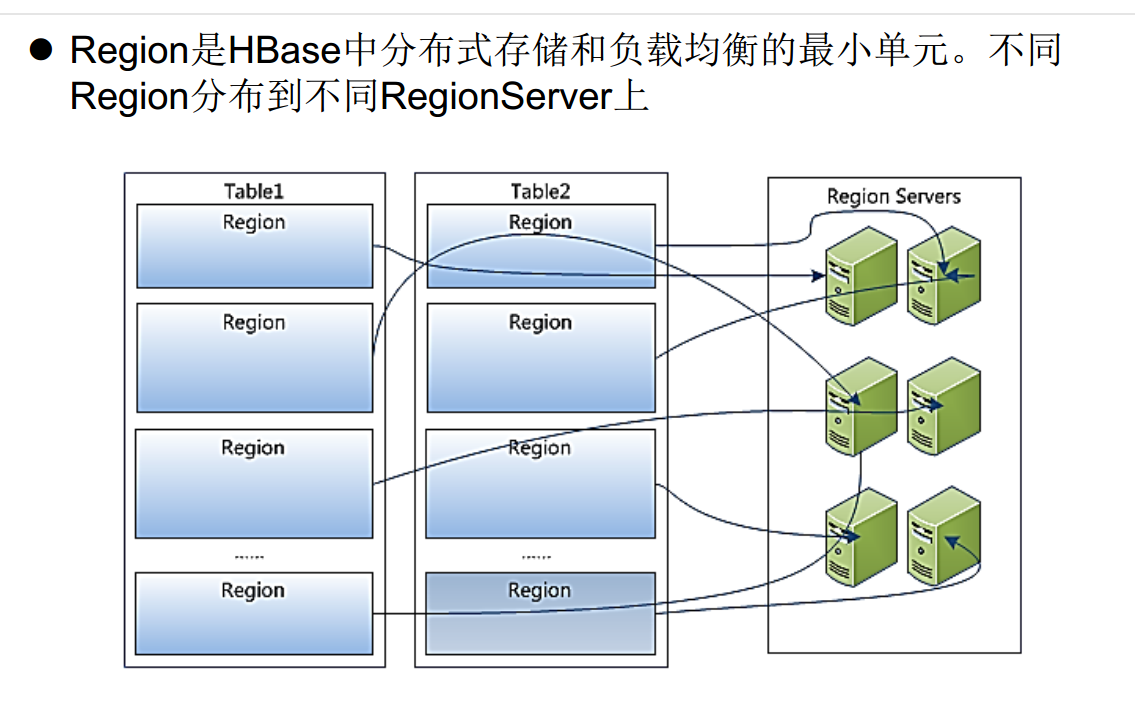
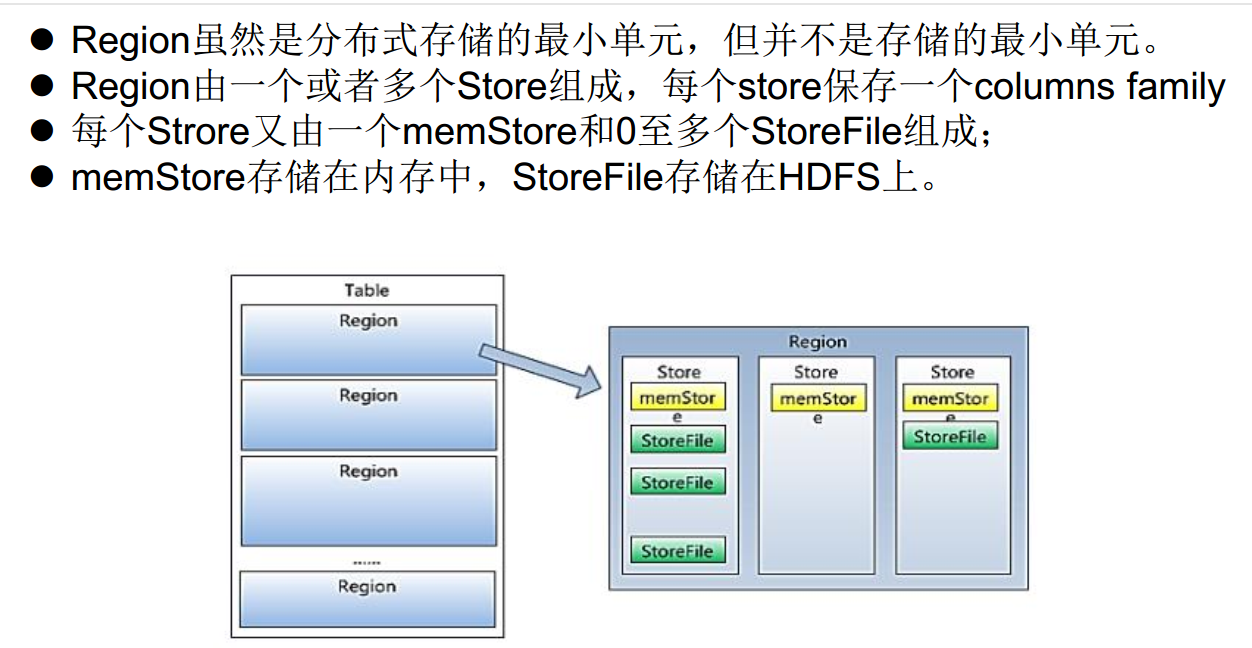
Table vs Region
04 HBase系统架构
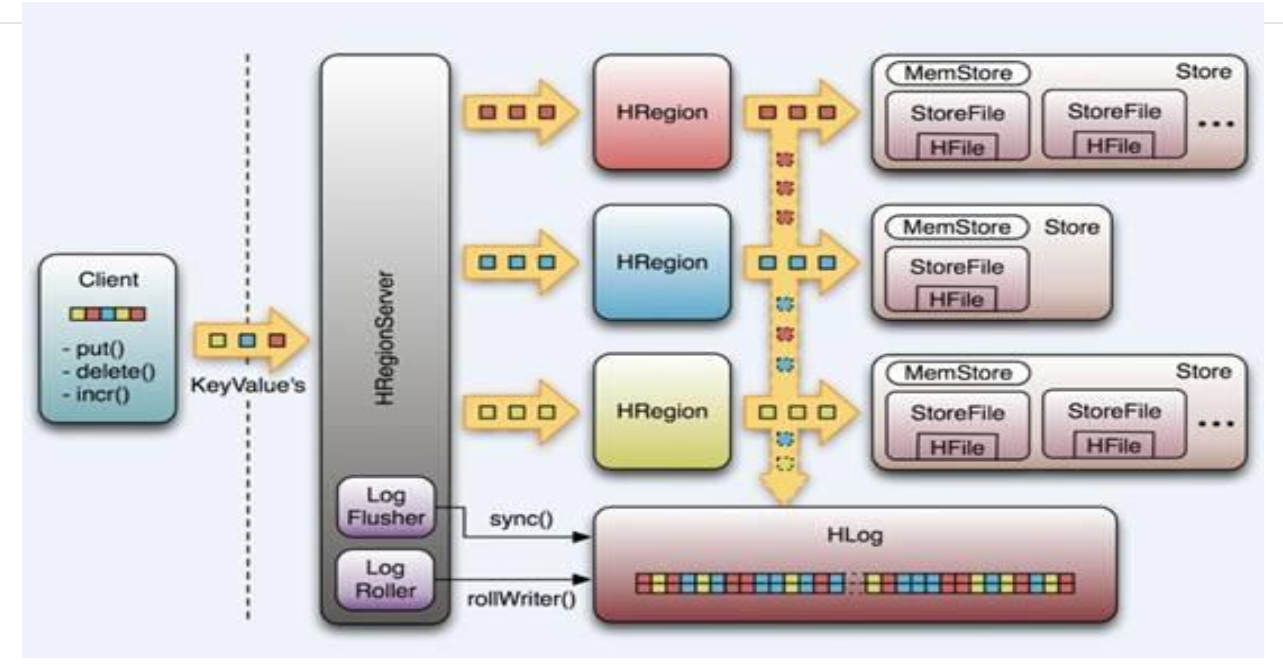
架构图
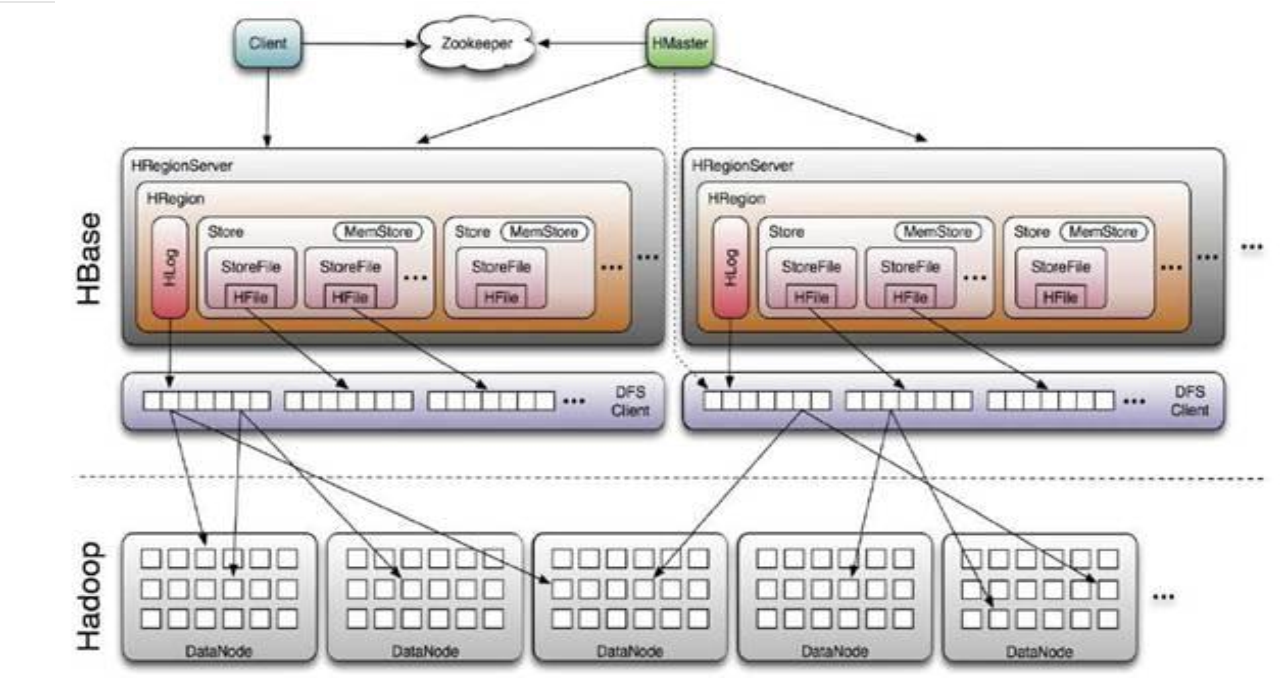
HBase基本组件

HBase工作流程

Hbase Write-Ahead-Log(预先写日志)
Regionserver结构

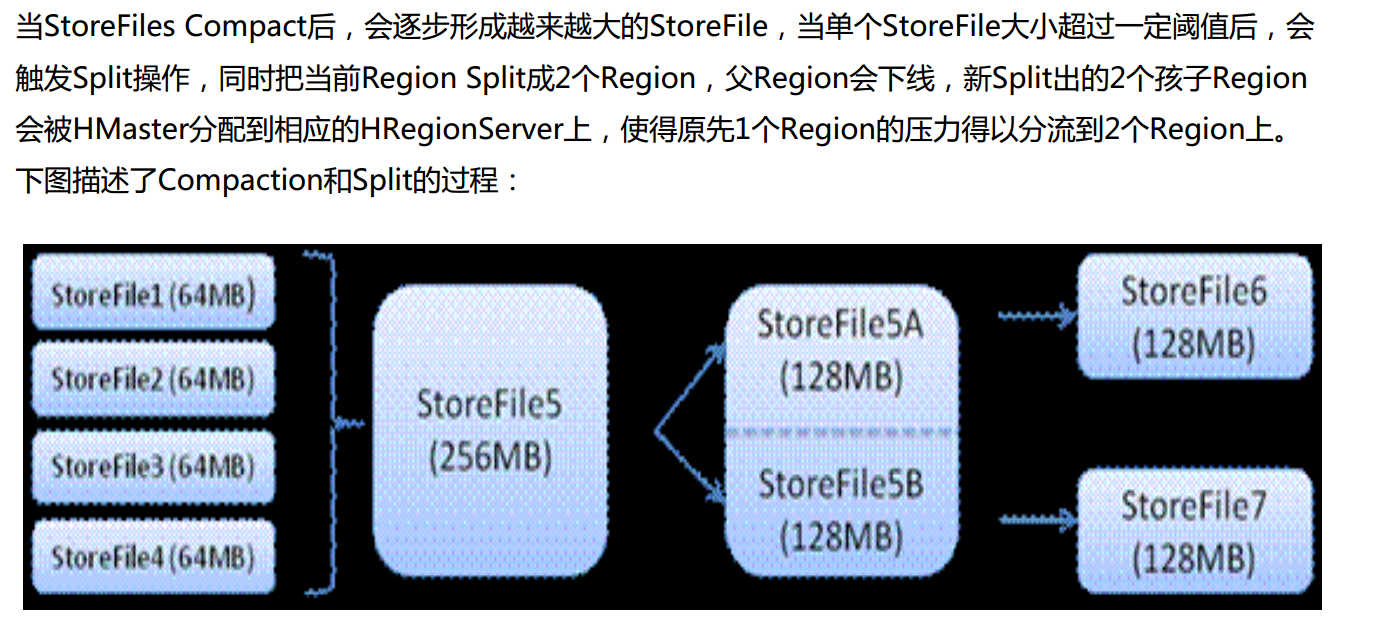
HBase Compact && Split
HLog Replay

Hfile存储格式
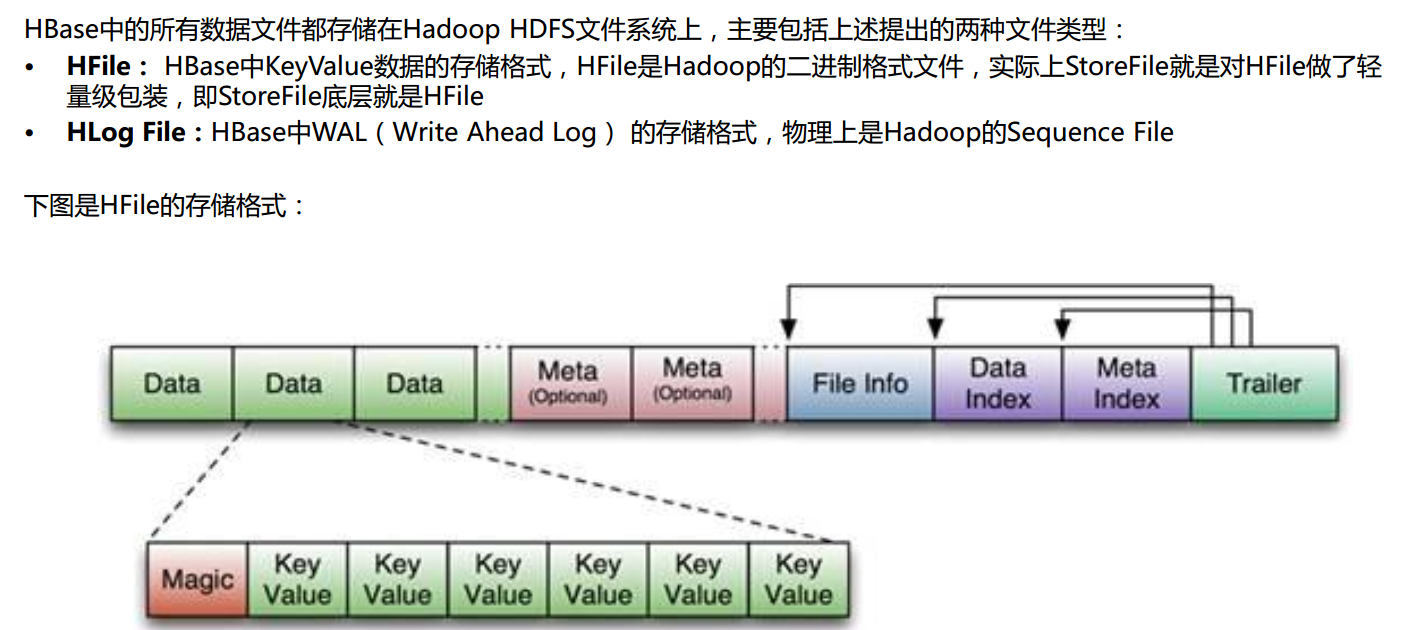
Hfile存储格式(续)

Keyvalue格式

Hlog存储格式
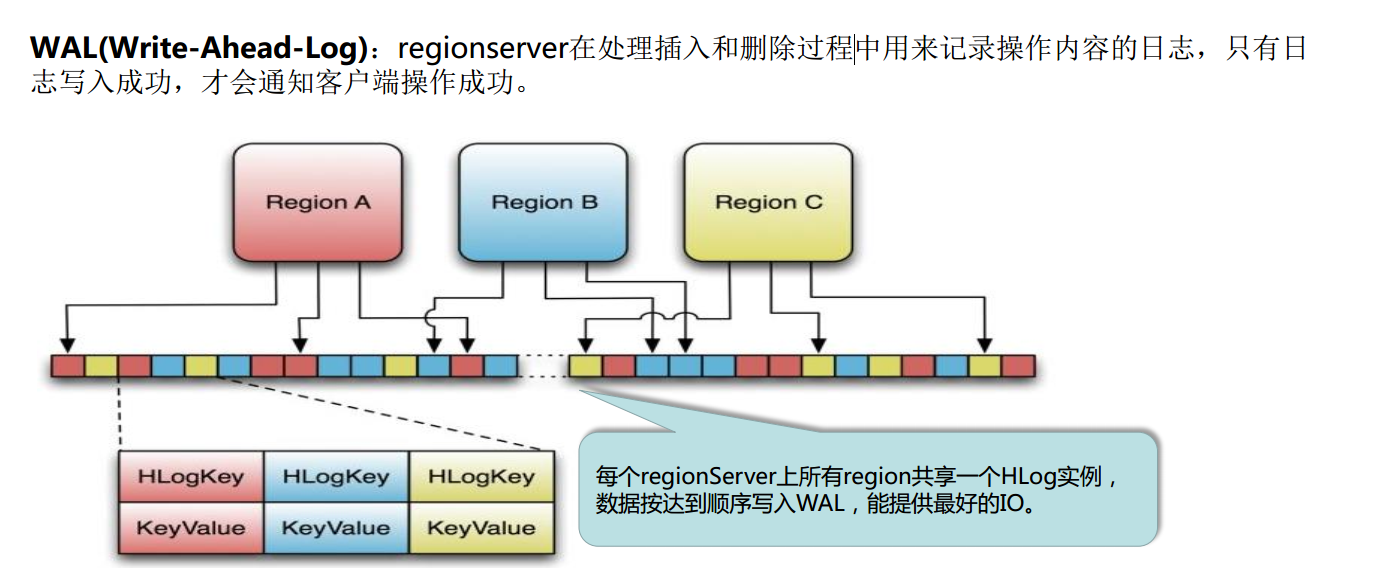
HLog存储格式(续)

HBase高可用
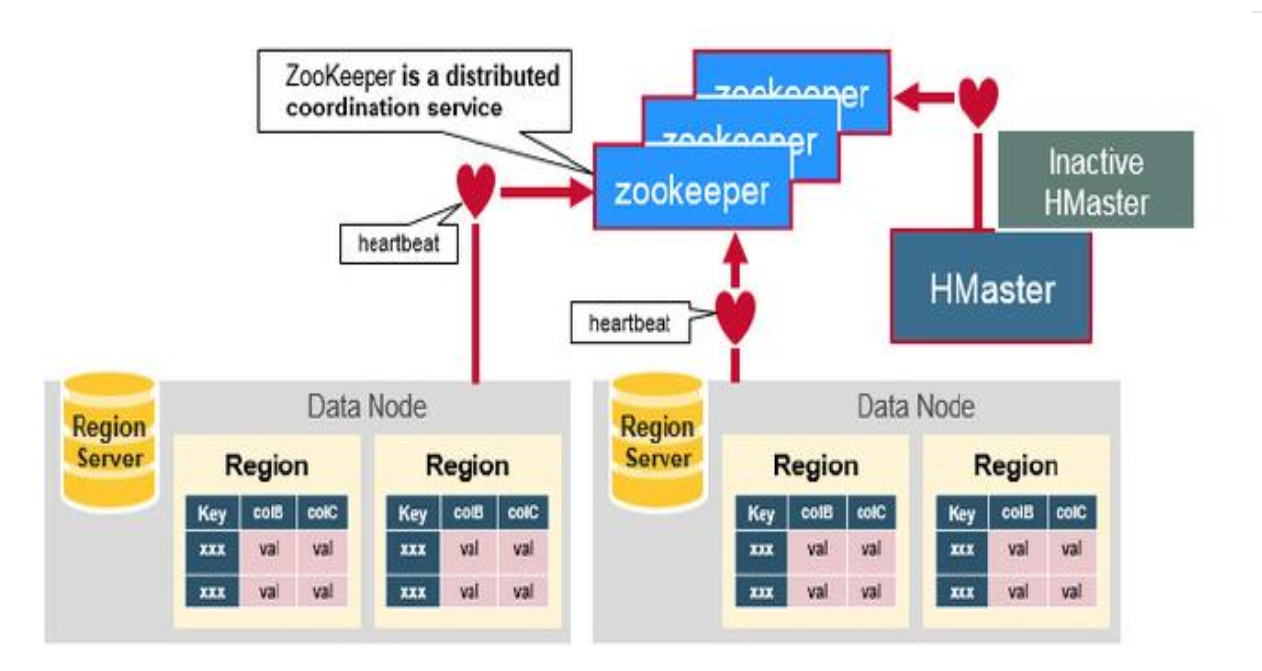
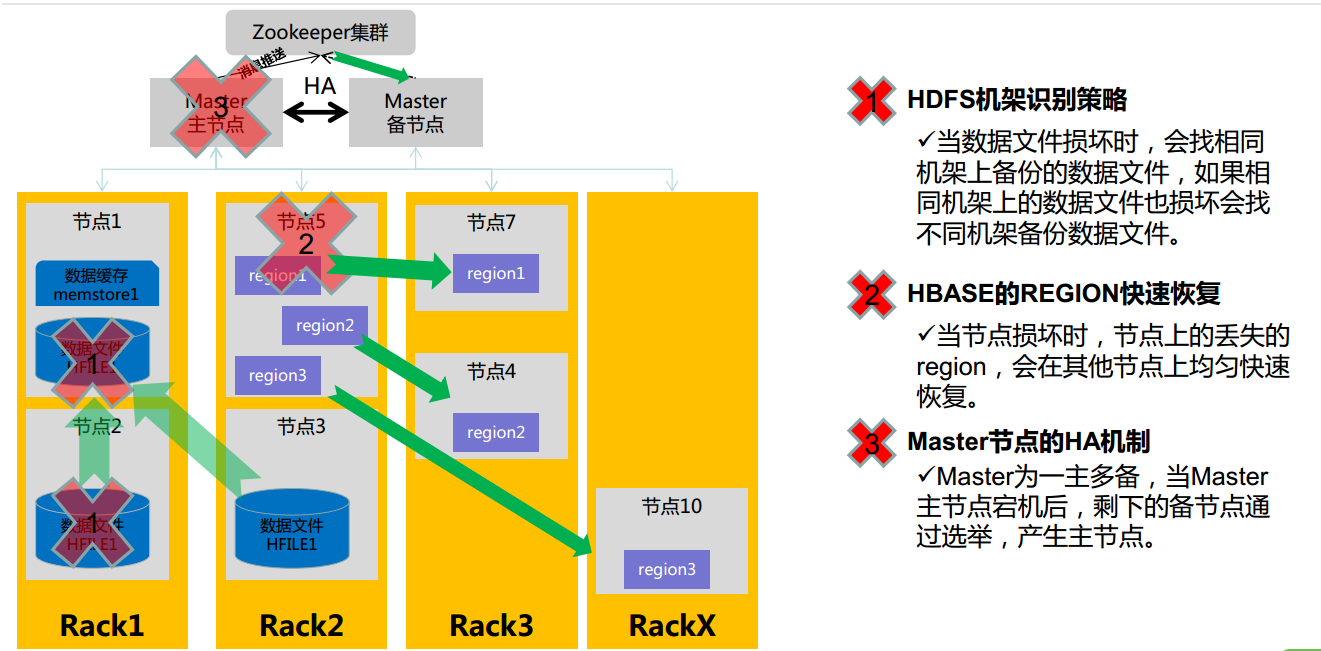
HBase容错性

Region定位

先访问zookeeper,找到root表的位置,root表记录了meta表的位置,在meta表里面查找对应的rowkey查找所在的region,并获取用户region的位置
-ROOT-和.META.表结构

如果是root表,表名就是.meta。如果是meta表,表名就是用户的id 订单等等。
-ROOT-表和.META


Hbase 读流程
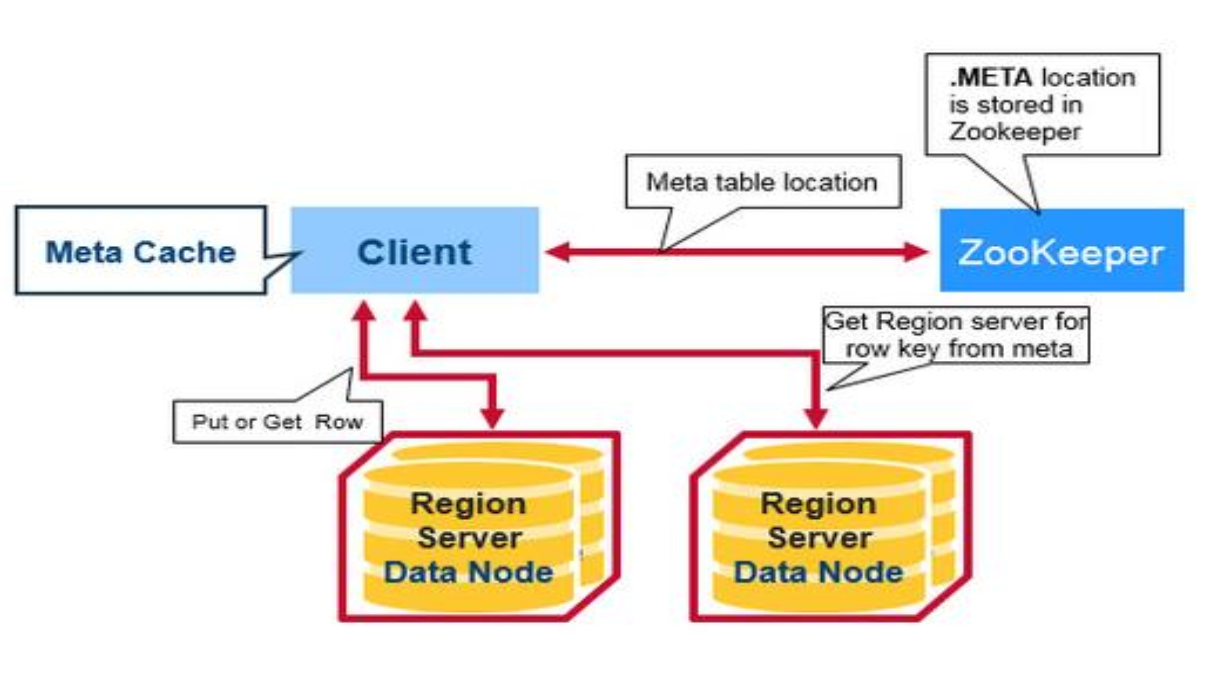
Client客户端先找到zookeeper拿到meta表,meta表根据rowkey拿到相应的region信息,找到对应的regionsever
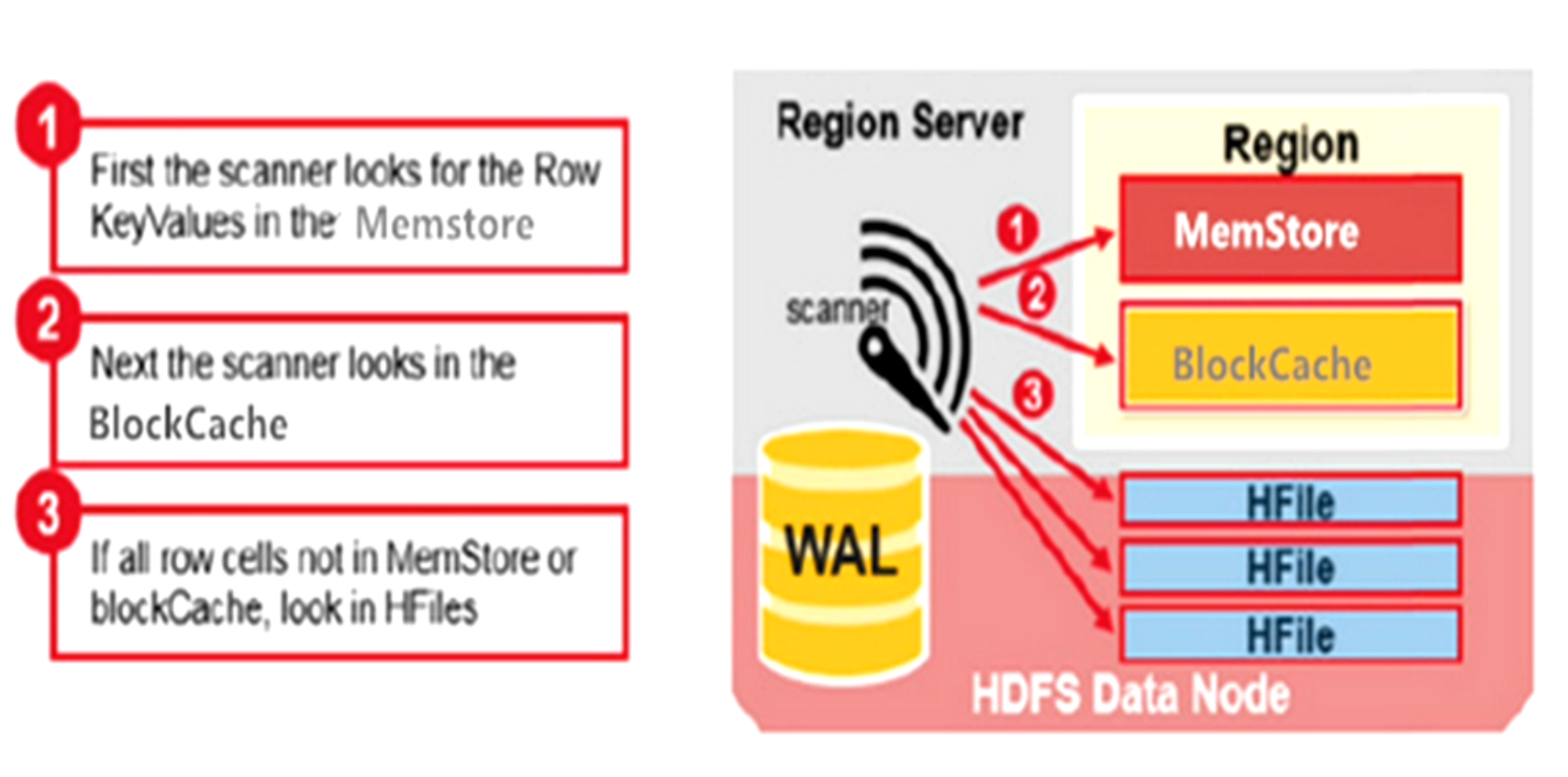
1.memstore是写缓存,blockcache是读缓存。
2.读数据的时候先到写缓存memstore去读,这样能提高读的效率,当memstore没有了,才到读缓存blockcache读数据。如果上面两个缓存(属于内存)都没有的情况下,就到磁盘去读。
3.在读到磁盘的时候去查找相应的数据,在没找到之前把前面的hfile放到blockcache读缓存里面,因为blockcache的空间也是有限的,如果blockcache读满了还没有找到需要查询的数据,blockcache就会淘汰一部分数据。
HBase put写流程
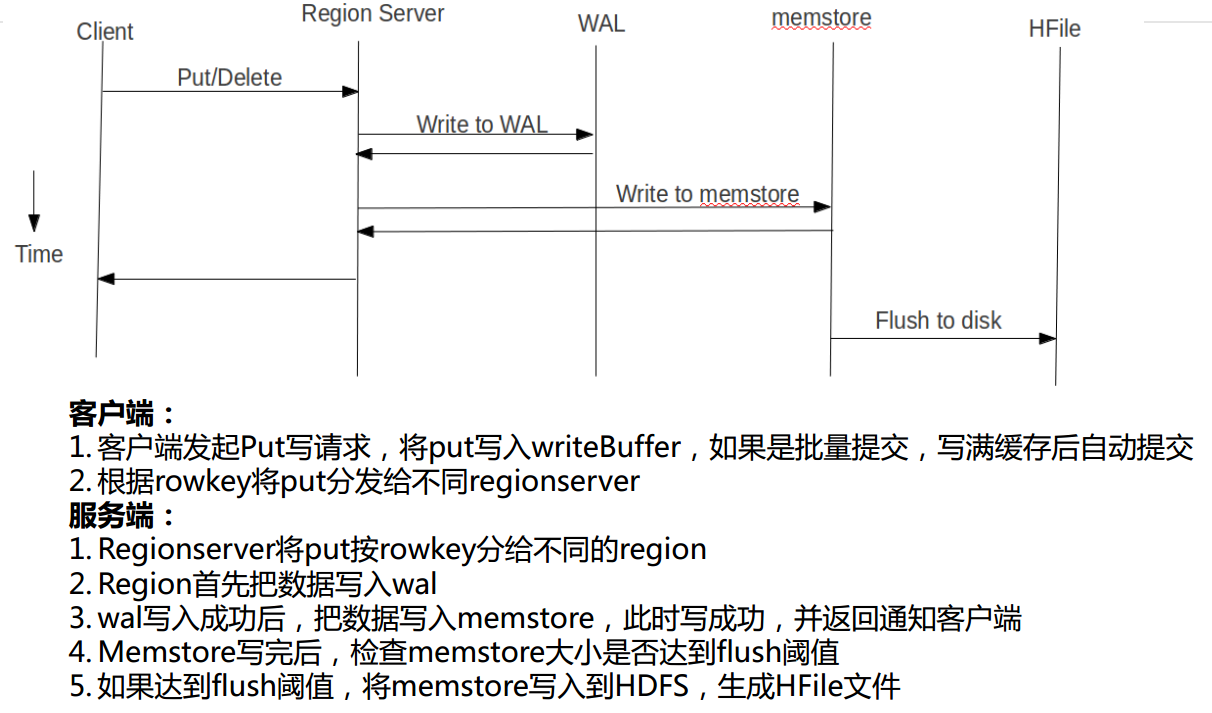
Hbase VS 关系型数据库
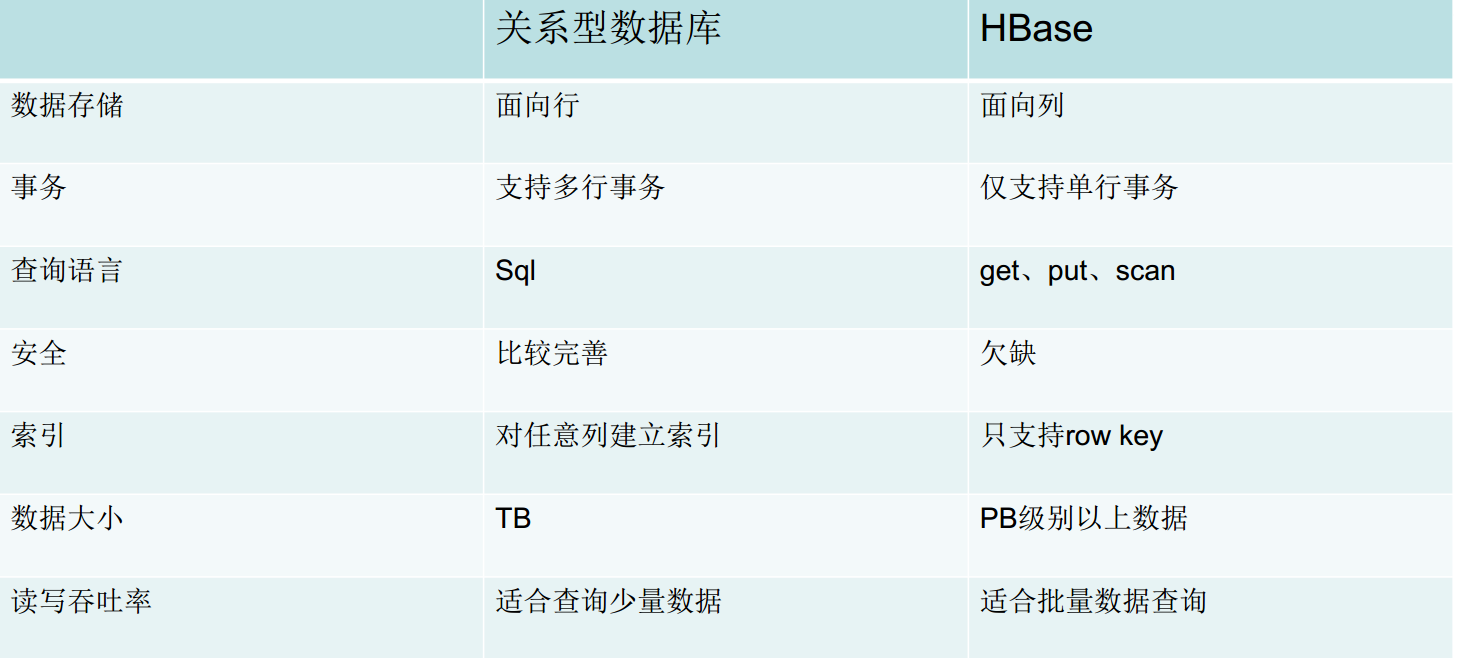
Hbase VS Hive

HBase原理和架构的更多相关文章
- HBase的基本架构及其原理介绍
1.概述:最近,有一些工程师问我有关HBase的基本架构的问题,其实这个问题仅仅说架构是非常简单,但是需要理解.在这里,我觉得可以用HDFS的架构作为借鉴.(其实像Hadoop生态系统中的大部分组建的 ...
- Zookeeper概论(对zookeeper的概论、原理、架构等的理解)
Zookeeper概论(对zookeeper的概论.原理.架构等的理解) 一.概论 Zookeeper是一个分布式的.开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是h ...
- 【转】HBase原理和设计
简介 HBase —— Hadoop Database的简称,Google BigTable的另一种开源实现方式,从问世之初,就为了解决用大量廉价的机器高速存取海量数据.实现数据分布式存储提供可靠的方 ...
- Hbase原理
Hbase原理 概述 HBase是一个构建在HDFS上的分布式列存储系统:HBase是基于Google BigTable模型开发的,典型的key/value系统:HBase是Apache Hadoop ...
- HBase原理和设计
转载 2016年1月10日:http://www.sysdb.cn/index.php/2016/01/10/hbase_principle/ 简介 架构 数据组织 原理 RS定位 region写入 ...
- HBase原理、设计与优化实践
转自:http://www.open-open.com/lib/view/open1449891885004.html 1.HBase 简介 HBase —— Hadoop Database的简称,G ...
- 大数据技术之_11_HBase学习_01_HBase 简介+HBase 安装+HBase Shell 操作+HBase 数据结构+HBase 原理
第1章 HBase 简介1.1 什么是 HBase1.2 HBase 特点1.3 HBase 架构1.3 HBase 中的角色1.3.1 HMaster1.3.2 RegionServer1.3.3 ...
- HBase之一:HBase原理和设计
一.简介 HBase —— Hadoop Database的简称,Google BigTable的另一种开源实现方式,从问世之初,就为了解决用大量廉价的机器高速存取海量数据.实现数据分布式存储提供可靠 ...
- 1、Hbase原理分析
一.Hbase介绍 1.1.对Hbase的认识 HBase作为面向列的数据库运行在HDFS之上,HDFS缺乏随机读写操作,HBase正是为此而出现. HBase参考 Google 的 Bigtable ...
随机推荐
- Webpack4 的 Tree Shaking:babel-loader设置modules: false,还是设置"sideEffects": false,待确定
Webpack4 的 Tree Shaking:babel-loader设置modules: false,还是设置"sideEffects": false,待确定 babel-lo ...
- "remote:error:refusing to update checked out branch:refs/heads/master"的解决办法(转)
https://blog.csdn.net/jacolin/article/details/44014775 在使用Git Push代码到数据仓库时,提示如下错误: [remote rejected] ...
- [转]You Could Become an AI Master Before You Know It. Here’s How.
转自:https://www.technologyreview.com/s/608921/ai-algorithms-are-starting-to-teach-ai-algorithms/# You ...
- gcc系强制链接静态库(同时有.so和.a)
1. 坑多的办法 -static 如果需要链接成不依赖任何so文件的程序,用ldd查看显示为"not a dynamic executable",但是这个选项时不推荐的. 即使像这 ...
- CentOS6.5 安装+ Tengine + PHP + MySQL
简介: Tengine是由淘宝网发起的Web服务器项目.它在Nginx的基础上,针对大访问量网站的需求,添加了很多高级功能和特性.Tengine的性能和稳定性已经在大型的网站如淘宝网,天猫商城等得到了 ...
- 【java】函数概述
函数也叫方法,是具有一定功能的小程序. 函数格式: 修饰符 返回值类型 函数名(参数类型 形式参数:参数类型 形式参数) { 执行语句: return 返回值; } 返回值类型:函数运行后结果的数据类 ...
- 将mongo设置为windows的服务
原文链接 https://mp.weixin.qq.com/s/rmWcvjZFJb3z_5M8UPWAPQ PHP的mongo扩展: 首先 下载一个PHP的mongo扩展, 地址:http://do ...
- Linux LVM 简单操作
查看当前磁盘分区情况fdisk -l 磁盘分区fdisk /dev/sdb# 可能用到的Type :# 8e Linux LVM# fd Linux raid auto 创建PVpvcreate /d ...
- 【springmvc】之使用jQuery接收前端传入List对象
前端代码: <form id="person_add" method="post" action="user"> <tab ...
- virtualBox NAT模式,设置虚拟机可上网,宿主机可访问虚拟机的方法
环境描述: 宿主机:windows Server 2008 64bit,IPV4地址,有网络. 宿主机上的主要软件环境: virtualBox 5.0.24 virtualBox中安装了CentOS ...