SQL SERVER中关于OR会导致索引扫描或全表扫描的浅析 (转载)
在SQL SERVER的查询语句中使用OR是否会导致不走索引查找(Index Seek)或索引失效(堆表走全表扫描 (Table Scan)、聚集索引表走聚集索引扫描(Clustered Index Scan))呢?是否所有情况都是如此?又该如何优化呢? 下面我们通过一些简单的例子来分析理解这些现象。下面的实验环境为SQL SERVER 2008,如果在不同版本有所区别,欢迎指正。
堆表单索引
首先我们构建我们测试需要实验环境,具体情况如下所示:
DROP TABLE TEST CREATE TABLE TEST (OBJECT_ID INT, NAME VARCHAR(32)); CREATE INDEX PK_TEST ON TEST(OBJECT_ID) DECLARE @Index INT =0; WHILE @Index < 500000
BEGIN
INSERT INTO TEST
SELECT @Index, 'kerry'+CAST(@Index AS VARCHAR(6)); SET @Index = @Index +1;
END UPDATE STATISTICS TEST WITH FULLSCAN
场景1:如下所示,并不是所有的OR条件都会导致SQL走全表扫描。具体情况具体分析,不要套用教条。
SELECT * FROM TEST WHERE (OBJECT_ID =5 OR OBJECT_ID = 105)
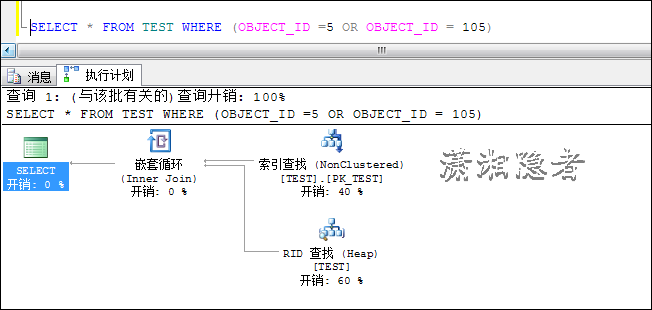
场景2:加 了条件1=1后,执行计划从索引查找(Index Seek)变为全表扫描(Table Scan),为什么会如此呢?个人理解为优化器将OR运算拆分为两个子集处理,由于一些原因,1=1这个条件导致优化器认定需要全表扫描才能完成1=1条 件子集的计算处理(为了理解这个,煞费苦心,鉴于理论薄弱,如有错误或不足,敬请指出)。所以优化器在权衡代价后生成的执行计划最终选择了全表扫描 (Table Scan)
SELECT * FROM TEST WHERE (1=1 OR OBJECT_ID =105);

场景3: 下面场景比较好理解,因为下面需要从500000条记录中取出499700条记录,而全表扫描(Table Scan)肯定是最优的选择,代价(Cost)最低。
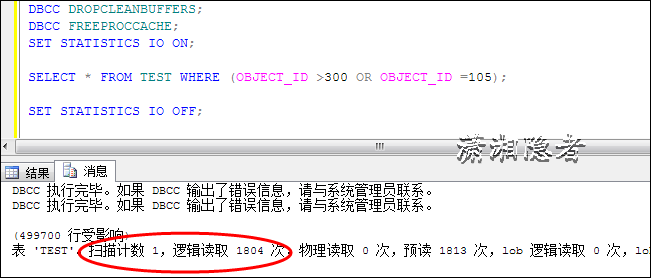
SELECT * FROM TEST WHERE (OBJECT_ID >300 OR OBJECT_ID =105);
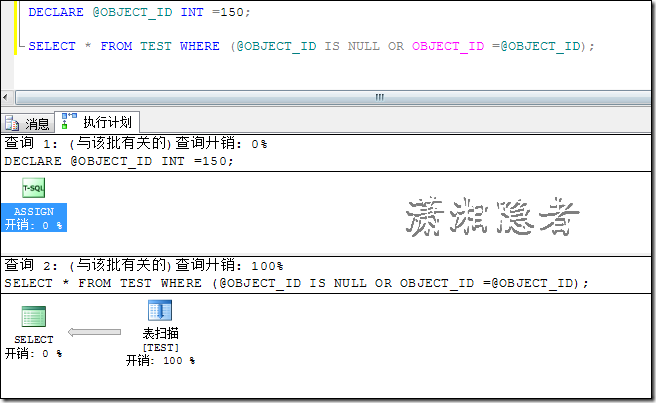
场景4:这种场景跟场景2的情况本质是一样的。所以在此略过。其实类似这种写法也是实际情况中最常出现的情况,还在迷糊的同学,赶紧抛弃这种写法吧
DECLARE @OBJECT_ID INT =150; SELECT * FROM TEST WHERE (@OBJECT_ID IS NULL OR OBJECT_ID =@OBJECT_ID);
聚集索引表单索引
在聚集索引表中,我们也依葫芦画瓢,准备实验测试的数据环境。
DROP TABLE TEST CREATE TABLE TEST (OBJECT_ID INT, NAME VARCHAR(32)); CREATE CLUSTERED INDEX PK_TEST ON TEST(OBJECT_ID) DECLARE @Index INT =0; WHILE @Index < 500000
BEGIN
INSERT INTO TEST
SELECT @Index, 'kerry'+CAST(@Index AS VARCHAR(6)); SET @Index = @Index +1;
END UPDATE STATISTICS TEST WITH FULLSCAN
场景1 :索引查找(Index Seek)
SELECT * FROM TEST WHERE (OBJECT_ID =5 OR OBJECT_ID = 105)
场景2:聚集索引扫描(Clustered Index Scan)

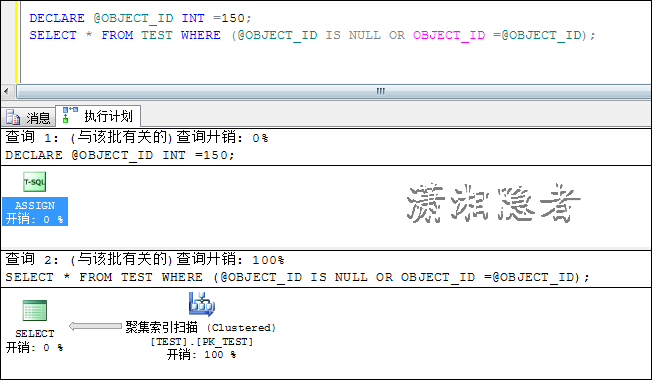
场景3:似乎与堆表有所不同。聚集索引表居然还是走聚集索引查找。

场景4:OR导致聚集索引扫描
如果堆表或聚集索引表上建立有联合索引,情况也大致如此,在此不做过多案例讲解。下面仅仅讲述一两个案例场景。
DROP TABLE test1; CREATE TABLE test1
(
a INT,
b INT,
c INT,
d INT,
e INT
) DECLARE @Index INT =0; WHILE @Index < 10000
BEGIN
INSERT INTO test1
SELECT @Index,
@Index,
@Index,
@Index,
@Index SET @Index = @Index + 1;
END CREATE INDEX idx_test_n1
ON test1(a, b, c, d) UPDATE STATISTICS test1 WITH fullscan;
SELECT * FROM TEST1 WHERE A=12 OR B> 500 OR C >100000
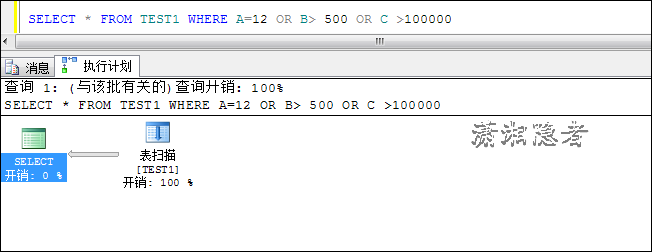
因为结果集是几个条件的并集,最多只能在查找A=12的数据时用索引,其它几个条件都需要表扫描,那优化器就会选择直接走一遍表扫描,以最低的代价COST完成,所以索引就失效了。
那么如何优化查询语句含有的OR的SQL语句呢?方法无外乎有三种:
1:通过索引覆盖,使包含OR的SQL走索引查找(Index Seek)。但是这个只能满足部分场景,并不能解决所有这类SQL。这个Solution具有一定的局限性。
SELECT * FROM TEST1 WHERE A=12 OR B=500
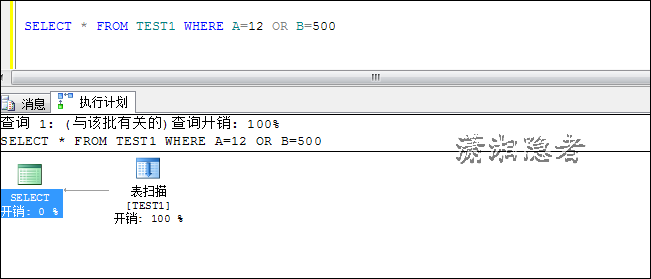
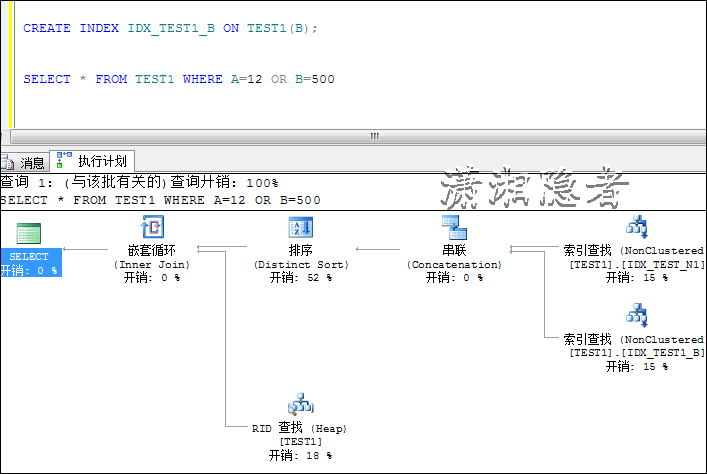
如果我们通过索引覆盖,在字段B上面也建立索引,那么下面OR查询也会走索引查
CREATE INDEX IDX_TEST1_B ON TEST1(B); SELECT * FROM TEST1 WHERE A=12 OR B=500
2:使用IN替换OR。 但是这个Solution也有很多局限性。在此不做过多阐述。
3: 一般将OR的字句分解成多个查询,并且通过UNION ALL 或UNION连接起来。在联合索引或有索引覆盖的场景下。大部分情况下,UNION ALL的效率更高。但是并不是所有的UNION ALL都会比OR的SQL的代价(COST),特殊的情况或特殊的数据分布也会出现UNION ALL比OR代价要高的情况。例如,上面特殊的要求,从全表中取两条记录,如下所示
SELECT * FROM TEST1 WHERE A=12 UNION ALL SELECT * FROM TEST1 WHERE B=500
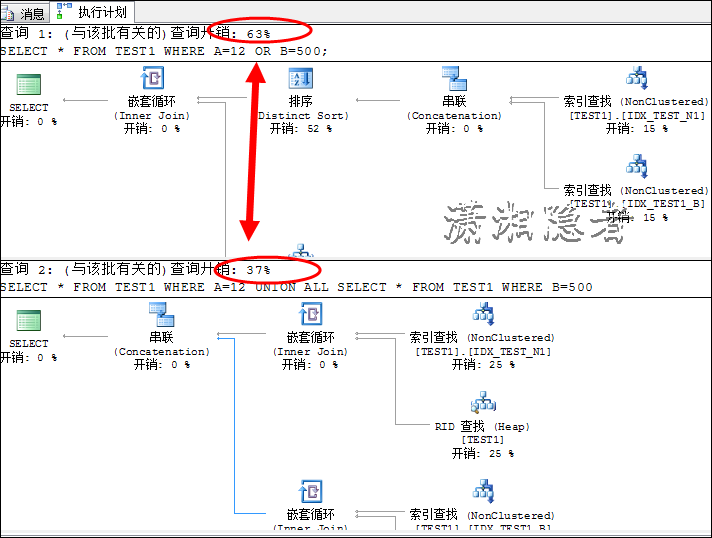
UNON ALL语句的代价(Cost)要高与OR是因为它做了两次索引查找(Index Seek),而OR语句只做一次索引查找(Index Seek)就完成了。开销明显小一些,但是实际情况这类特殊情况比较少,实际情况的取数条件、数据都比这个简单案例要复杂得多。所以在大部分情况下,拆分 为UNION ALL语句的效率要高于OR语句
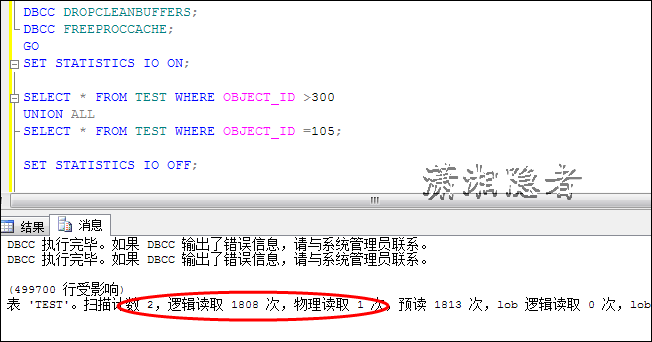
另外一个案例,就是最上面实验的堆表TEST, 在字段OBJECT_ID上建有索引
SELECT * FROM TEST WHERE (OBJECT_ID >300 OR OBJECT_ID =105); SELECT * FROM TEST WHERE OBJECT_ID >300 UNION ALL SELECT * FROM TEST WHERE OBJECT_ID =105;

可以从下面看出两者开销不同的地方在于IO方面,两者开销之所以有区别,是因为第二个SQL多了一次扫描(索引查找)
总结:
在实际开发环境中,OR这种写法确实会带来很多不确定性,尽量使用UNION 或IN替换OR。我们需要遵循一些规则,但是也不能认为它就是一成不变的,永为真理。具体场景、具体环境具体分析。要知其然知其所以然。在微软亚太区数据库技术支持组的官方博客中就有一个案例SQL Server性能问题案例解析 (3)也是OR引起的性能案例。 博客中有个观点,我觉得挺赞的:”需要注意的是,对于OR或UNION,并没有确定的孰优孰劣,使用时要进行测试才能确定。“ 。
SQL SERVER中关于OR会导致索引扫描或全表扫描的浅析 (转载)的更多相关文章
- SQL SERVER中关于OR会导致索引扫描或全表扫描的浅析
在SQL SERVER的查询语句中使用OR是否会导致不走索引查找(Index Seek)或索引失效(堆表走全表扫描 (Table Scan).聚集索引表走聚集索引扫描(Clustered Index ...
- SQL SERVER中什么情况会导致索引查找变成索引扫描
SQL Server 中什么情况会导致其执行计划从索引查找(Index Seek)变成索引扫描(Index Scan)呢? 下面从几个方面结合上下文具体场景做了下测试.总结.归纳. 1:隐式转换会导致 ...
- SQL Server中TOP子句可能导致的问题以及解决办法
简介 在SQL Server中,针对复杂查询使用TOP子句可能会出现对性能的影响,这种影响可能是好的影响,也可能是坏的影响,针对不同的情况有不同的可能性. 关系数据库中SQL语句只 ...
- SQL Server中VARCHAR(MAX)和NVARCHAR(MAX)使用时要注意的问题(转载)
在Microsoft SQLServer2005及以上的版本中,对于varchar(n).nvarchar(n)和varbinary(n)有了max的扩展.可以使用如:varchar(max).nva ...
- SQL Server中通过设置非聚集索引(Non-Clustered index)来达到性能优化的目的
首先我们一下,在SQL Server 2014 Management Studio中,如何为一张表设置Non-Clustered index 具体可以参考 https://docs.microsof ...
- 【转发】在SQL Server中通过字段值查询存储该字段的表
-- Copyright © 2002 Narayana Vyas Kondreddi. All rights reserved. -- Purpose: To search all colu ...
- SQL Server 中SELECT INTO 和 INSERT INTO SELECT 两种表复制语句
1.INSERT INTO SELECT语句 语句形式为:Insert into Table2(field1,field2,...) select value1,value2,... from Tab ...
- mysql in 中使用子查询,会不使用索引而走全表扫描
所以可以将 in 条件中 子查询转换成一张子表,从而通过 join 的形式进行条件限制.
- SQL Server临界点游戏——为什么非聚集索引被忽略!
当我们进行SQL Server问题处理的时候,有时候会发现一个很有意思的现象:SQL Server完全忽略现有定义好的非聚集索引,直接使用表扫描来获取数据.我们来看看下面的表和索引定义: CREATE ...
随机推荐
- DTCMS部署错误
1.添加如下节点 <system.webServer> <validation validateIntegratedModeConfiguration="false&quo ...
- 什么是编程语言,什么是Python解释器
转自白月黑羽python在线教程:http://www.python3.vip/doc/blog/python/2018071401/ 0基础学Python之1:什么是编程语言,什么是Python解释 ...
- JNI的又一替代者—使用JNR访问Java外部函数接口(jnr-ffi)
1. JNR简单介绍 继上文“JNI的替代者—使用JNA访问Java外部函数接口”,我们知道JNI越来越不受欢迎,JNI是编写Java本地方法以及将Java虚拟机嵌入本地应用程序的标准编程接口.它管理 ...
- 玩转mongodb(七):索引,速度的引领(全文索引、地理空间索引)
本篇博文主要介绍MongoDB中一些常用的特殊索引类型,主要包括: 用于简单字符串搜索的全文本索引: 用于球体空间(2dsphere)和二维平面(2d)的地理空间索引. 一.全文索引 MongoDB有 ...
- python采用pika库使用rabbitmq总结,多篇笔记和示例
这一段时间学习了下rabbitmq,在学习的过程中,发现国内关于python采用pika库使用rabbitmq的资料很少,官网有这方面的资料,不过是都英文的.于是笔者结合自己的理解,就这方面内容写了一 ...
- 简单聊聊SOA和微服务
转自:https://juejin.im/post/592f87feb123db0064e5ef7c (2017-06) 简单聊聊SOA和微服务 架构设计中的朴素主义 前两天和一个朋友聊天,他向我咨 ...
- 【学习笔记】浅析Promise函数
一.Promise是什么? 在JavaScript中,所有的代码都是单线程执行,所以javaScript的所有网络操作(“GET”/"POST"/"PUT"/& ...
- Java面试——你必须知道的122题
1.Java面向对象中所有类的最终基类是什么? 参考答案 object,所有类都默认最终继承object,object是所有类的基类 2.什么是Java虚拟机?为什么Java被称作是“平台无关的编程语 ...
- MVC初级知识之——View与Controller的讲解
Controller是MVC中比较重要的一部分.几乎所有的业务逻辑都是在这里进行处理的,并且从Model中取出数据.在ASP.NET MVC Preview5中,将原来的Controller类一分为二 ...
- ABP的依赖注入
目录 说说ABP的依赖注入 代码追踪 说说ABP的依赖注入 上篇abp运行机制分析分析了ABP在启动时,都做了那些事:这篇我们来说说ABP的最核心的一部分:依赖注入(DependencyInjecti ...