Django框架深入了解_04(DRF之url控制、解析器、响应器、版本控制、分页)
一、url控制
基本路由写法:最常用
from django.conf.urls import url
from django.contrib import admin
from app01 import views urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^books/', views.Books.as_view()),
url(r'^book/', views.Book.as_view()),
url(r'^login/', views.Login.as_view()),
]
第二种写法:继承ModelViewSet
基于mixins来封装的视图就是使用了继承ModelViewSet,然后改写路由:
from django.conf.urls import url
from app01 import views
urlpatterns = [
url(r'^publish/$', views.PublishView.as_view({'get':'list','post':'create'})),
url(r'^publish/(?P<pk>\d+)/$', views.PublishView.as_view({'get':'retrieve','put':'update','delete':'destroy'})),
]
第三种写法:(自动生成路由,必须继承ModelViewSet)
# SimpleRouter 自动生成两条路由
实现过程:
tips:使用python的manage.py的shell环境进行快速添加数据用于测试:
pycharm>>Terminal:

python3 manage.py shell
>>> from app01 import models
>>> models.Publish.objects.create(name='北方出版社',addr='北京')
<Publish: Publish object>
>>> models.Publish.objects.create(name='长江出版社',addr='湖北')
<Publish: Publish object>
>>> models.Publish.objects.create(name='东方出版社',addr='唐朝')
<Publish: Publish object>
from django.shortcuts import render
from rest_framework.response import Response # Create your views here.
from app01 import models
from app01.MySer import PublishSer
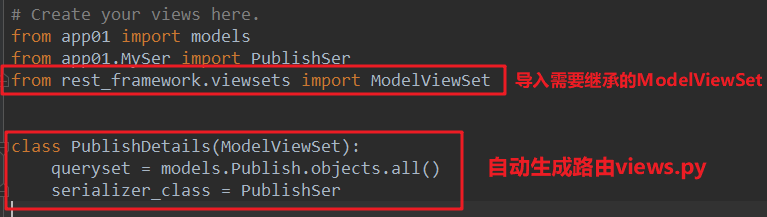
from rest_framework.viewsets import ModelViewSet class PublishDetails(ModelViewSet):
queryset = models.Publish.objects.all()
serializer_class = PublishSer
views.py代码
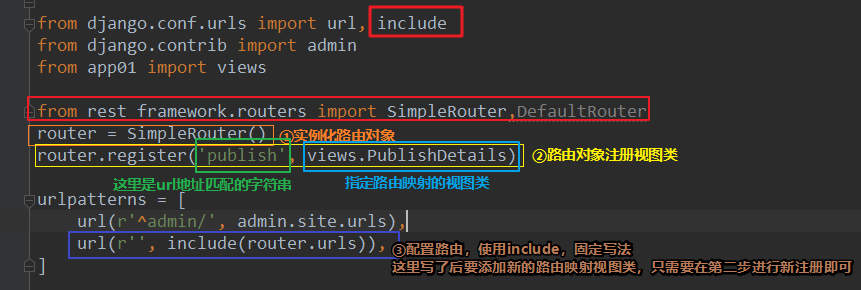
from django.conf.urls import url, include
from django.contrib import admin
from app01 import views from rest_framework.routers import SimpleRouter,DefaultRouter
router = SimpleRouter()
router.register('publish', views.PublishDetails) urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'', include(router.urls)),
]
urls.py代码
from rest_framework import serializers
from app01 import models
class PublishSer(serializers.ModelSerializer):
class Meta:
model = models.Publish
fields = "__all__"
MySer序列化类文件
from django.db import models # Create your models here.
class Publish(models.Model):
name = models.CharField(max_length=32)
addr = models.CharField(max_length=64)
models.py文件
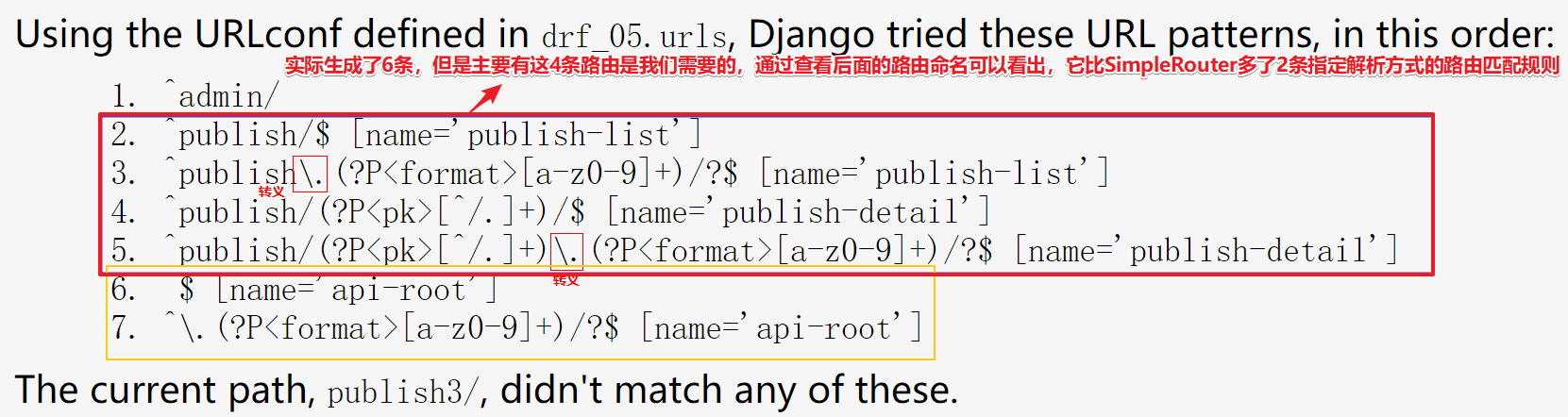
测试,输入一个错误的路由,查看自动生成2条路由: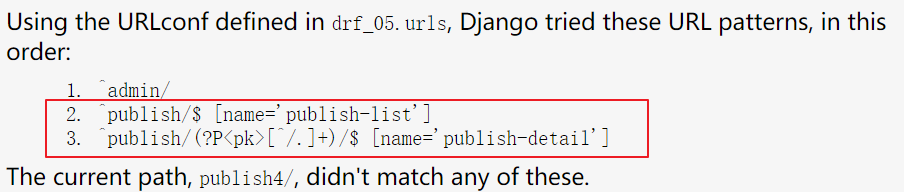
# DefaultRouter 自动生成四条路由
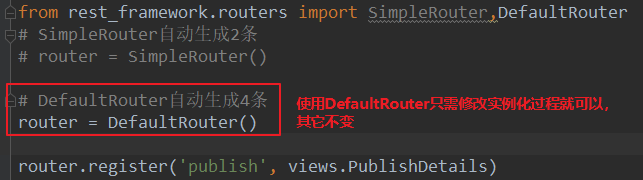
二、解析器
前端不同的数据格式请求,后端解析得到的结果:
json格式:
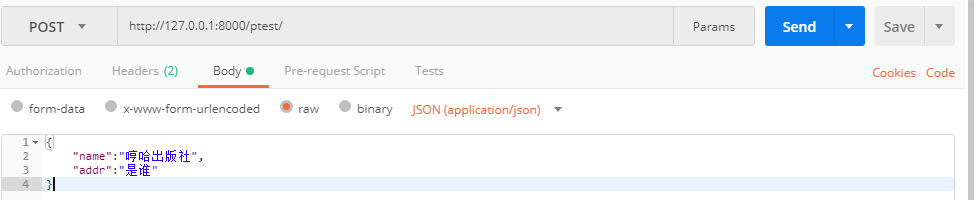
前端:(使用postman发送请求,json格式)
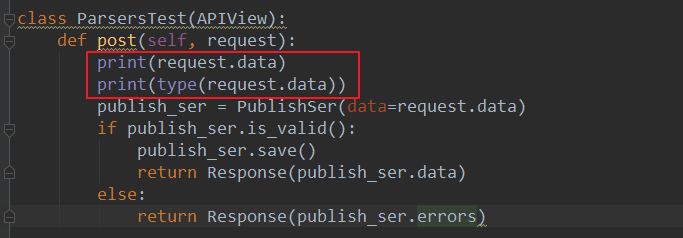
后端:(打印request.data数据)

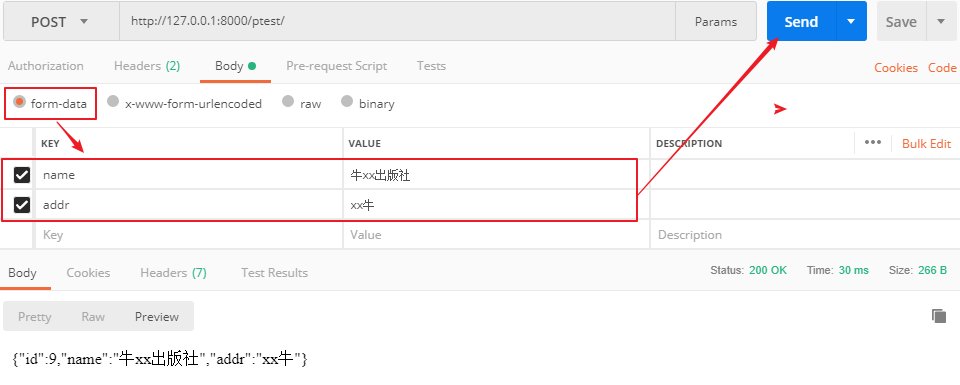
form-data格式:

urlencoded格式:
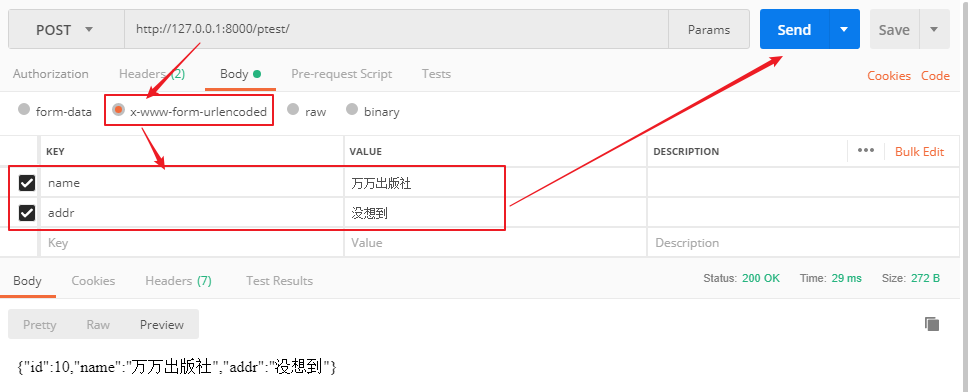

小结:可以看出
json格式数据发送,后端解析出来的数据为:<class 'dict'>
form-data和urlencoded格式数据发送,后端解析出来的数据为:QueryDict对象,<class 'django.http.request.QueryDict'>
解析器介绍:
所谓解析器,就是前端传过来的数据,后端可以解析,从request.data中取出来,默认的解析器配置是三种编码格式都可以取
解析器的作用:
根据请求头(content-type)选择对应的解析器对请求体内容进行处理,有application/json,x-www-form-urlencoded,form-data等格式
设置解析器就可以控制前端传过来的数据类型进行限制,比如说我只能解析json格式的数据,那么前端必须给我传json数据我才能拿到
三种编码格式:urlencoded,formdata,json
-urlencoded:在body体中的格式是:name=xxx&age=18&wife=liyitong
-formdata:在body体中的格式数据部分跟文件部分有区分
-json格式:在body体中就是json格式
解析器的使用:
(实际就是通过配置解析器,让后端只接收某一种格式的请求数据类型,这样后端只能解析该类型数据,其它类型的请求都会无效,当然设置一种也可以设置多种)
局部使用:
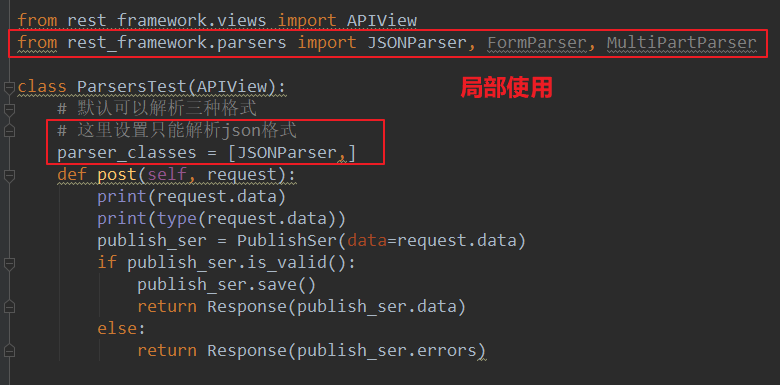
测试:
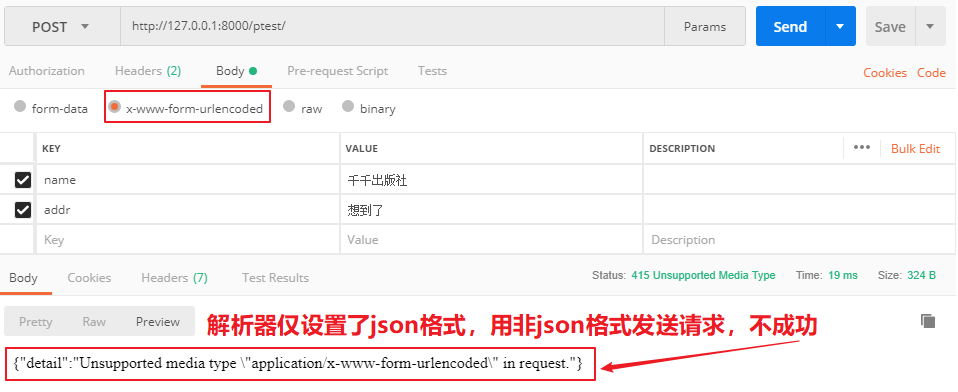
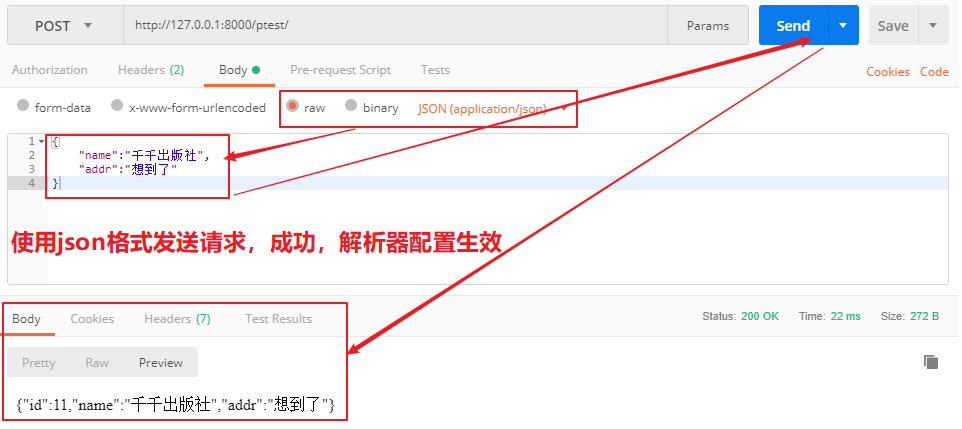
全局使用:
先了解一下默认解析三种格式的设置代码:

全局设置:
在setting中配置:
REST_FRAMEWORK = {
"DEFAULT_PARSER_CLASSES":[
'rest_framework.parsers.JSONParser',
]
}
三、响应器:
响应器的作用:
根据用户请求URL 或 用户可接受的类型,筛选出合适的 渲染组件。
响应器的使用:
-from rest_framework.renderers import JSONRenderer,BrowsableAPIRenderer
-不用动,就用全局配置即可
-全局使用:
-在setting中配置
'DEFAULT_RENDERER_CLASSES': [
'rest_framework.renderers.JSONRenderer',
]
-局部使用:
-在视图类中配置:
renderer_classes = [JSONRenderer, BrowsableAPIRenderer]
响应器的内置渲染器:
显示json格式:JSONRenderer
访问URL: http://127.0.0.1:8000/test/?format=json
http://127.0.0.1:8000/test.json
http://127.0.0.1:8000/test/
默认显示格式:BrowsableAPIRenderer(可以修改它的html文件)
访问URL: http://127.0.0.1:8000/test/?format=api
http://127.0.0.1:8000/test.api
http://127.0.0.1:8000/test/
表格方式:AdminRenderer
访问URL: http://127.0.0.1:8000/test/?format=admin
http://127.0.0.1:8000/test.admin
http://127.0.0.1:8000/test/
form表单方式:HTMLFormRenderer
访问URL: http://127.0.0.1:8000/test/?format=form
http://127.0.0.1:8000/test.form
http://127.0.0.1:8000/test/
四、版本控制
restful规范里,提出过版本的概念,也就是说版本控制就是相对于接口而言,它有多个版本,就好像应用程序、手机app都会更新版本一样,会修改更新接口文件,这时候就不能在原接口进行修改更新,应该另起一个接口作为版本2(假设为v2)来提供给用户使用,原来的版本可能是v1,那么v1和v2版本提供给外界的控制,就是版本控制。
通过路由拼接版本号或者放入请求头中的途径来获取对应版本号的接口,进行请求。
from rest_framework.versioning import QueryParameterVersioning,AcceptHeaderVersioning,NamespaceVersioning,URLPathVersioning #基于url的get传参方式:QueryParameterVersioning------>如:/users?version=v1
#基于url的正则方式:URLPathVersioning------>/v1/users/
#基于 accept 请求头方式:AcceptHeaderVersioning------>Accept: application/json; version=1.0
#基于主机名方法:HostNameVersioning------>v1.example.com
#基于django路由系统的namespace:NamespaceVersioning------>example.com/v1/users/
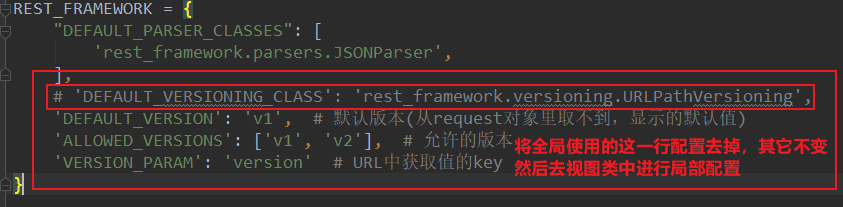
全局使用:
-在setting中配置:
'DEFAULT_VERSIONING_CLASS':'rest_framework.versioning.URLPathVersioning',
'DEFAULT_VERSION': 'v1', # 默认版本(从request对象里取不到,显示的默认值)
'ALLOWED_VERSIONS': ['v1', 'v2'], # 允许的版本
'VERSION_PARAM': 'version' # URL中获取值的key
-路由需要修改
-url(r'^(?P<version>[v1|v2]+)/test/', views.Test.as_view()),
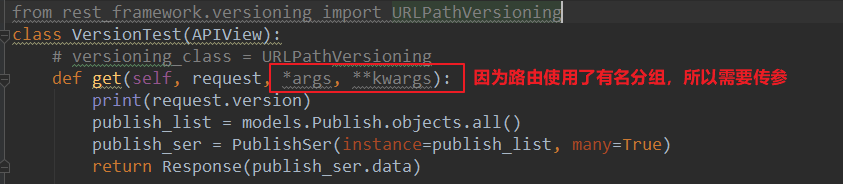
局部使用:
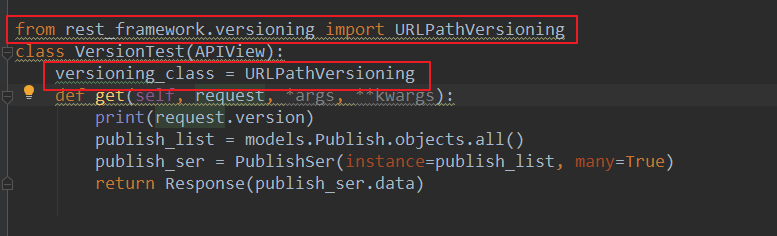
在视图类中就可以通过:request.version取出当前访问哪个版本,相应的取执行相应版本的代码
五、DRF分页器
前戏:批量创建多条数据用于测试分页:
url(r'^pagetest/', views.PaginationTest.as_view()),
# views.py
class PaginationTest(APIView):
# 批量创建publish记录,用于测试分页
def post(self,request):
pub_l = []
for i in range(1000):
pub_l.append(models.Publish(name='出版社[%s]' % (i+1), addr='地址[%s]' % (i+1)))
models.Publish.objects.bulk_create(pub_l)
return Response('批量创建成功')
常规分页
url(r'^pagetest/', views.PaginationTest.as_view()),
# 视图类 from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination,CursorPagination
from app01.MySer import PublishSer class PaginationTest(APIView):
# 批量创建publish记录,用于测试分页
def post(self,request):
pub_l = []
for i in range(1000):
pub_l.append(models.Publish(name='出版社[%s]' % (i+1), addr='地址[%s]' % (i+1)))
models.Publish.objects.bulk_create(pub_l)
return Response('批量创建成功') def get(self, request, *args, **kwargs):
# 拿到所有数据
publish_list = models.Publish.objects.all()
# 实例化出page对象
page = PageNumberPagination()
# ================ page相关参数配置开始 ================ #
# # 每页显示10条,也可以在settings.py中添加全局配置('PAGE_SIZE': 10 )
page.page_size = 10
# # 设置每页条数的拼接key(默认为size)
page.page_size_query_param = 'size0'
# # 控制每页最大显示条数:(这个控制仅限制于路径后拼接设置size0=1000后,对其进行限制)
page.max_page_size = 30
# # 设置定位的页数的拼接key(默认是page)
page.page_query_param = 'page0'
# ================ page相关参数配置结束 ================ #
# 对数据进行分页处理:
ret_page = page.paginate_queryset(publish_list, request, self)
# 序列化
pub_ser = PublishSer(instance=ret_page, many=True) return Response(pub_ser.data)
也可以在全局配置每页显示条数:

测试:




偏移分页
偏移分页与普通分页使用基本相同,类不同,配置的参数名称不同
# 偏移分页:
def get(self, request, *args, **kwargs):
# 拿到所有数据
publish_list = models.Publish.objects.all()
# 实例化出page对象
page = LimitOffsetPagination()
# ================ page相关参数进行配置开始 ================ #
# # 从标杆位置往后取几个,比如指定取10个
page.default_limit = 10
# # 拼接key值自定义
# 拿几条记录的key值自定义
page.limit_query_param = 'limit0'
# 标杆值(起始位置),从设置的offset0值那个位置往后拿limit0值的记录
page.offset_query_param = 'offset0'
# # 设置最大取10条
page.max_limit = 20
# ================ page相关参数进行配置结束 ================ #
# 对数据进行分页处理:
ret_page = page.paginate_queryset(publish_list, request, self)
# 序列化
pub_ser = PublishSer(instance=ret_page, many=True) return Response(pub_ser.data)
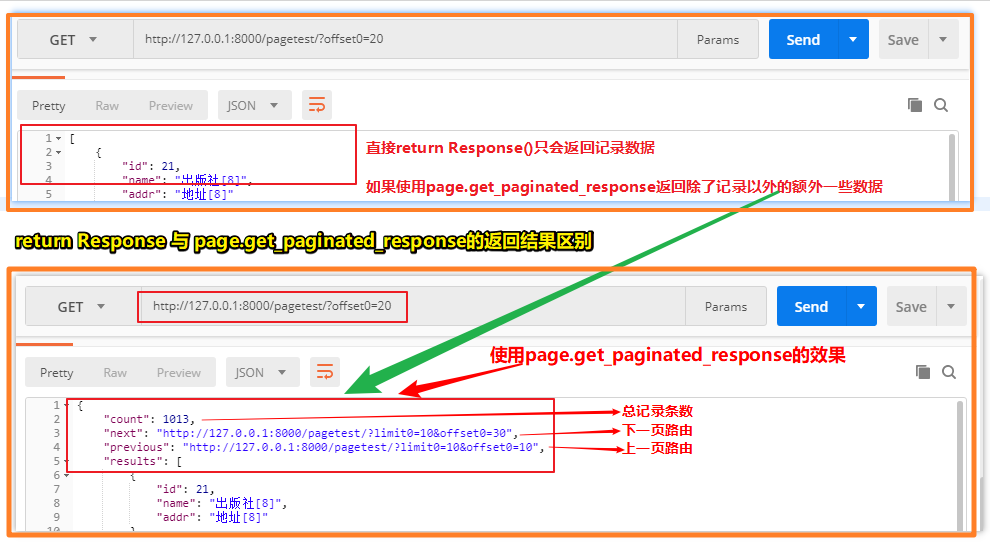
补充:get_paginated_response的使用
将return Response(pub_ser.data) 替换成 return page.get_paginated_response(pub_ser.data)
作用测试图:(此方法主要用于游标分页中,因为游标分页并不能指定第几页第几页,只有上一页和下一页)
cursor游标分页
# 游标分页:
def get(self, request, *args, **kwargs):
# 拿到所有数据
publish_list = models.Publish.objects.all()
# 实例化出page对象
page = CursorPagination()
# ================ page相关参数进行配置开始 ================ #
# # 每页显示条数
page.page_size = 5
# # 查询的key值自定义,默认是cursor,无需更改
page.cursor_query_param = 'cursor'
# 游标分页会将记录进行排序,然后根据排序的记录进行分页显示,设置排序依据
page.ordering = 'id'
# ================ page相关参数进行配置结束 ================ #
# 对数据进行分页处理:
ret_page = page.paginate_queryset(publish_list, request, self)
# 序列化
pub_ser = PublishSer(instance=ret_page, many=True)
# 如果使用Response返回数据,就不知道怎么定位上一页和下一页了
# return Response(pub_ser.data)
# 使用get_paginated_response,返回结果
return page.get_paginated_response(pub_ser.data)
游标分页的cursor后面的值我们是不知道的,所以拼不出来:
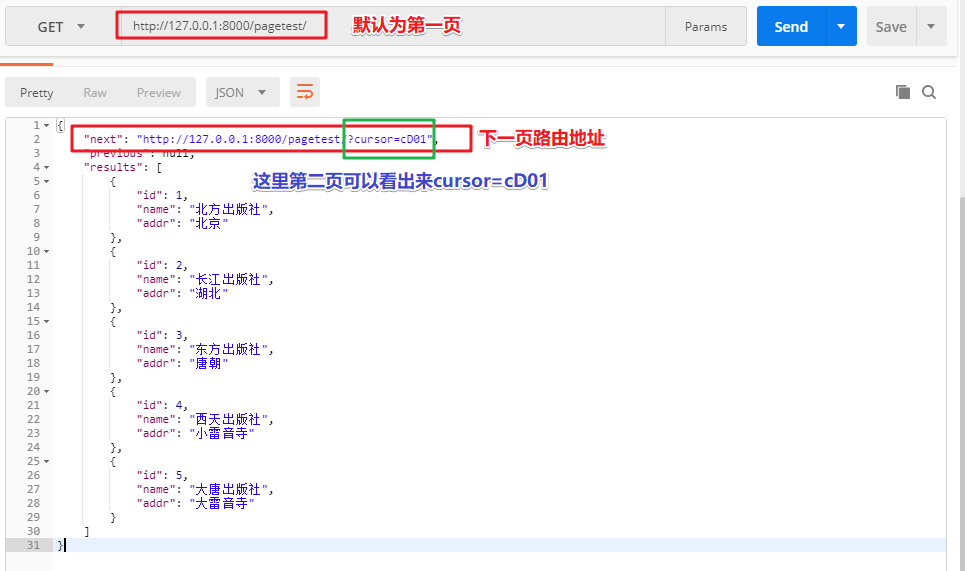

游标分页特点:它是一种加密分页,只能看上一页和下一页,速度快
Django框架深入了解_04(DRF之url控制、解析器、响应器、版本控制、分页)的更多相关文章
- DRF url控制 解析器 响应器 版本控制 分页(常规分页,偏移分页,cursor游标分页)
url控制 第二种写法(只要继承了ViewSetMixin) url(r'^pub/$',views.Pub.as_view({'get':'list','post':'create'})), #获取 ...
- DRF 的 版本,解析器,与序列化
DRF 的 版本,解析器,与序列化 补充 配置文件中的 类的调用: (字符串) v1 = ["view.xx.apth.Role","view.xx.apth.Role& ...
- drf 解析器,响应器,路由控制
解析器 作用: 根据请求头 content-type 选择对应的解析器对请求体内容进行处理. 有application/json,x-www-form-urlencoded,form-data等格式 ...
- drf的组件和解析器
drf的序列化组件: 1. 用途: 把python中的对象,转成json格式字符串 2. 使用步骤1: 写一个类继承Serializer或者ModelSerializer 举例(类中选取字段进行序列化 ...
- Django框架深入了解_03(DRF之认证组件、权限组件、频率组件、token)
一.认证组件 使用方法: ①写一个认证类,新建文件:my_examine.py # 导入需要继承的基类BaseAuthentication from rest_framework.authentica ...
- Django框架深入了解_02(DRF之序列化、反序列化)
序列化:将Python对象准换成json格式的字符串,反之即为反序列化 DRF的序列化使用过程: 使用drf的序列化组件 -1 新建一个序列化类继承Serializer -2 在类中写要序列化的字段 ...
- Django框架 之 admin管理工具(源码解析)
浏览目录 单例模式 admin执行流程 admin源码解析 单例模式 单例模式(Singleton Pattern)是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在.当你希望在 ...
- Django框架rest_framework中APIView的as_view()源码解析、认证、权限、频率控制
在上篇我们对Django原生View源码进行了局部解析:https://www.cnblogs.com/dongxixi/p/11130976.html 在前后端分离项目中前面我们也提到了各种认证需要 ...
- django框架介绍
主要内容 1. Django框架发展 2. Django架构,MTV模式 3. 开发流程 4. 开发实例——Poll python下各种框架 一 ...
随机推荐
- Loj刷题记录
又是一年云参营. 所以一起刷省选题吧. LOJ2028 「SHOI2016」随机序列 题目链接. 简要社论 发现+和-可以互相抵消,于是有贡献的时候一段前缀的乘积.设\(s[i]=\prod_{j=1 ...
- Android Studio一直显示Building“project name”Gradle project info问题详解
关注我,每天都有优质技术文章推送,工作,学习累了的时候放松一下自己. 本篇文章同步微信公众号 欢迎大家关注我的微信公众号:「醉翁猫咪」 Android Studio一直显示 Building&quo ...
- 【03NOIP普及组】栈(信息学奥赛一本通 1924)(洛谷 1044)
#include<bits/stdc++.h> using namespace std; int n,ans,m,k,ans2; ],f[],d[][],num[][],tmp[],s[] ...
- 关于SkyApm测试部署。
这个是skyapm的github : https://github.com/SkyAPM/SkyAPM-dotnet 它依赖于skywalking . 我是用docker去部署的.因为这样我的系统会干 ...
- css3学习之--transition属性(过渡)
一.理解transition属性 W3C标准中对CSS3的transition是这样描述的: CSS的transition允许CSS的属性值在一定的时间区间内平滑地过渡.这种效果可以在鼠标单击,获得焦 ...
- `ll/sc` 指令在`linux`中的软件实现
load-link与store-conditional (LL/SC)是一对用于并发同步访问内存的CPU指令.Load-link返回内存位置处的当前值,随后的store-conditional在该内存 ...
- Servlet相关的几种乱码
1. 页面中文显示乱码 原因: response中的内容会先输入到response缓冲区,然后再输入到传给浏览器,所以要将缓冲区和浏览器的编码都设置成utf-8 1)未使用jsp,而是在servlet ...
- 压测引起的 nginx报错 502 no live upstreams while connecting to upstream解决
对系统的某个接口进行极限压测,随着并发量上升,nginx开始出现502 no live upstreams while connecting to upstream的报错,维持最大并发量一段时间,发现 ...
- 函数式接口, Collection等
Lambda 函数式接口 lambda 表达式的使用需要借助于 函数式接口, 也就是说只有函数式接口才可以将其用 lambda 表达式进行简化. 函数式接口定义为仅含有一个抽象方法的接口. 按照这个定 ...
- EasyDSS高性能RTMP、HLS(m3u8)、HTTP-FLV、RTSP流媒体服务器的视频直播录像、检索、回放方案
需求背景: 近期遇到客户反馈对于直播摄像机录像功能是有一定的需求点的,其实EasyDarwin团队早就研发出对应功能,只是用户对于产品没有足够了解,因此本篇将对录像功能来做一次介绍. 首先,录像就是对 ...