python爬虫2
学习任务
获取去哪儿网的出发地列表
获取旅游景点列表
获取景点产品列表
存储数据
1 获取出发地站点
(1)访问touch.qunar.com
(2)按F12,单击自由行,在自由行页面点击搜索框


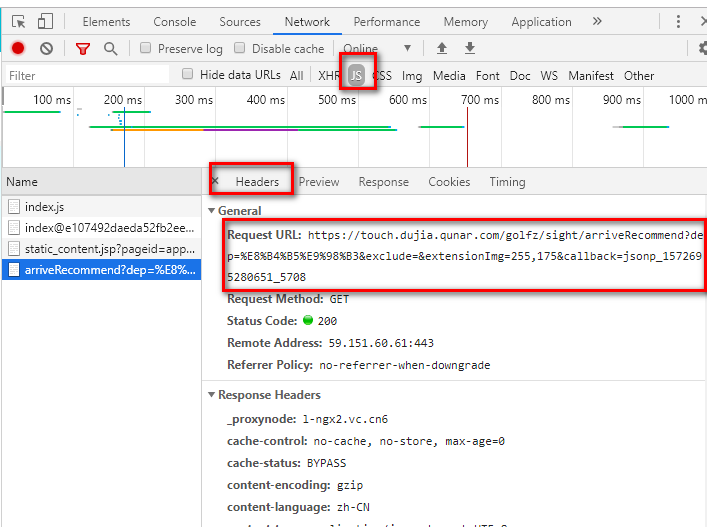
(3)单击任意一个城市,切换到headers,查看request URL如下所示。但是需要工具还原编码咋们才能知道这是啥(dep参数表示出发地,query表示目的地)。推荐网站http://www.jsons.cn/urlencode/,解码效果下面图2
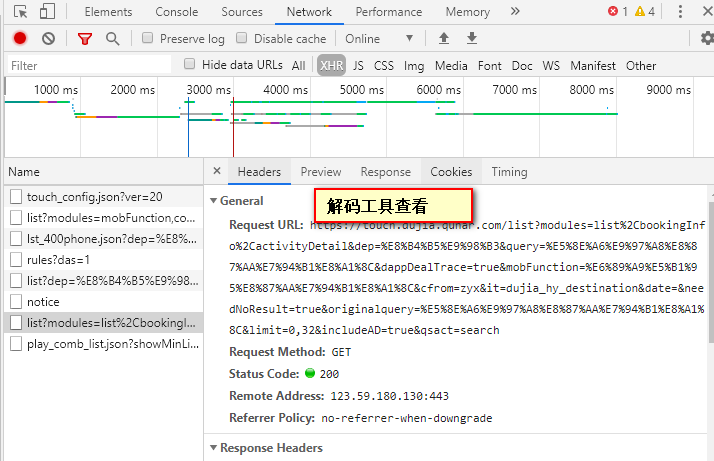

3 实现
(1)首先获得出发地站点,因为最终需要获得整个自由行的产品列表。
自由行首页中点击左侧的出发点站点,然后获取目标URL如图二

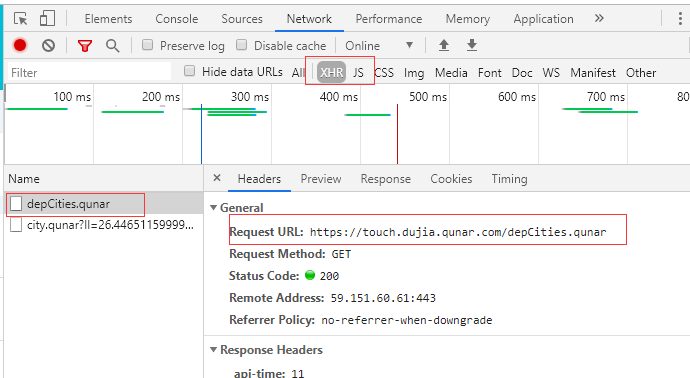
import requests
url="https://touch.dujia.qunar.com/depCities.qunar" strhtml=requests.get(url)
print(strhtml)
dep_dict=strhtml.json()
print(dep_dict)
for dep_item in dep_dict['data']:
for dep in dep_dict['data'][dep_item]:
print(dep)
(2)获得目的地。根据上面的分析,json工具解码以后通过拼接可得URL。
url = 'https://m.dujia.qunar.com/golfz/sight/arriveRecommend?dep={}&exclude=&extensionImg=255,175'.format(urllib.request.quote(dep))
(3)总源码
import requests
import urllib
import time
#import pymongo # client=pymongo.MongoClient('localhost',27017)
# book_qunar=client['qunar']
# sheet_qunar_zyx=book_qunar['qunar_zyx'] #获取产品列表
def get_list(dep,item):
url = 'https://touch.dujia.qunar.com/list?modules=list,bookingInfo&dep={}&query={}&mtype=all&ddt=false&mobFunction=%E6%89%A9%E5%B1%95%E8%87%AA%E7%94%B1%E8%A1%8C&cfrom=zyx&it=FreetripTouchin&et=FreetripTouch&date=&configDepNew=&needNoResult=true&originalquery={}&limit=0,20&includeAD=true&qsact=search'.format(
urllib.request.quote(dep), urllib.request.quote(item), urllib.request.quote(item))
strhtml = get_json(url)
try:
routeCount = int(strhtml['data']['limit']['routeCount'])
except:
return
for limit in range(0, routeCount, 20):
url = 'https://touch.dujia.qunar.com/list?modules=list,bookingInfo&dep={}&query={}&mtype=all&ddt=false&mobFunction=%E6%89%A9%E5%B1%95%E8%87%AA%E7%94%B1%E8%A1%8C&cfrom=zyx&it=FreetripTouchin&et=FreetripTouch&date=&configDepNew=&needNoResult=true&originalquery={}&limit={},20&includeAD=true&qsact=search'.format(
urllib.request.quote(dep), urllib.request.quote(item),
urllib.request.quote(item), limit)
strhtml = get_json(url)
result = {
'date': time.strftime('%Y-%m-%d', time.localtime(time.time())),
'dep': dep,
'arrive': item,
'limit': limit,
'result': strhtml
}
#sheet_qunar_zyx.insert_one(result)
print(result) # def connect_mongo():
# client=pymongo.MongoClient('localhost',27017)
# book_qunar=client['qunar']
# return book_qunar['qunar_zyx'] def get_json(url):
strhtml=requests.get(url)
time.sleep(1)
return strhtml.json() if __name__ == "__main__": url='https://touch.dujia.qunar.com/depCities.qunar'
dep_dict=get_json(url)
#这里是json格式 dep_dict中内嵌勒一层
for dep_item in dep_dict['data']:
for dep in dep_dict['data'][dep_item]:
a = []#目的地去重
#经过解码工具可以得到dep表示出发地 query和originalquery表示目的地
url = 'https://m.dujia.qunar.com/golfz/sight/arriveRecommend?dep={}&exclude=&extensionImg=255,175'.format(urllib.request.quote(dep))
arrive_dict = get_json(url)
for arr_item in arrive_dict['data']:
for arr_item_1 in arr_item['subModules']:
for query in arr_item_1['items']:
if query['query'] not in a:
a.append(query['query'])
for item in a:
get_list(dep,item)
python爬虫2的更多相关文章
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
- python爬虫学习(6) —— 神器 Requests
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库.用 Python 编写,真正的为人类着想. Python 标准库中的 urllib2 模块提供了你所需要的大多数 H ...
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
- python 爬虫(二)
python 爬虫 Advanced HTML Parsing 1. 通过属性查找标签:基本上在每一个网站上都有stylesheets,针对于不同的标签会有不同的css类于之向对应在我们看到的标签可能 ...
- Python 爬虫1——爬虫简述
Python除了可以用来开发Python Web之后,其实还可以用来编写一些爬虫小工具,可能还有人不知道什么是爬虫的. 一.爬虫的定义: 爬虫——网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- [python]爬虫学习(一)
要学习Python爬虫,我们要学习的共有以下几点(python2): Python基础知识 Python中urllib和urllib2库的用法 Python正则表达式 Python爬虫框架Scrapy ...
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
随机推荐
- WebService(一)
最近一段时间研究webservice,一般来说,开发java的Webservice经常使用axis2和cxf这两个比较流行的框架 先使用cxf,开发一个完整示例,方便对webservice有一个整体的 ...
- Spark-源码分析03-SubmitTask
1.Rdd rdd中 reduce.fold.aggregate.collect.count这些方法 都会调用 sparkContext.runJob ,这些方法称之为Action 触发提交Job d ...
- 如何把上传图片时候的文件对象转换为图片的url !
getObjectURL(file) { var url = null; if (window.createObjectURL != undefined) { url = window.createO ...
- 利用Xilinx ROM仿真时注意包括.mif文件
利用Xilinx ROM仿真时,注意包括.mif文件.一般是将.v文件和.mif文件放在同一个目录下,以便.v文件读取.mif数据.如不注意,就不会读出有效数据.
- 【03NOIP普及组】麦森数(信息学奥赛一本通 1925)(洛谷 1045)
[题目描述] 形如2P-1的素数称为麦森数,这时P一定也是个素数.但反过来不一定,即如果P是个素数,2P-1不一定也是素数.到1998年底,人们已找到了37个麦森数.最大的一个是P=3021377,它 ...
- mysql5.7 之 sql_mode=only_full_group_by问题
在使用查询时,使用到了group by 分组查询,报如下错误: ERROR (): In aggregated query without GROUP BY, expression # of SELE ...
- RocketMq重复消费问题排查
前情 出现了重复消费的问题,同一个消息被重复消费了多次,导致了用户端收到了多条重复的消息,最终排查发现,是因为消费者在处理消息的方法onMessage中有异常没有捕获到,导致异常上抛,被consume ...
- 集合类 collection接口 ArrayList
数组: 存储同一种数据类型的集合容器.数组的特点:1. 只能存储同一种数据类型的数据.2. 一旦初始化,长度固定. 3. 数组中的元素与元素之间的内存地址是连续的. : Object类型的数组可以存储 ...
- ·分布式文件系统HDFS 练习
作业要求来源于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3292 1.目录操作 在HDFS中为hadoop用户创建一个用户目录( ...
- 3ds Max学习日记(十一)——如何给模型上贴图
参考链接:https://jingyan.baidu.com/article/e4511cf38a810b2b845eaf1f.html 之前一直都不知道怎么在3dsMax里给模型上材质和贴图,被 ...