搭建基于 Anaconda 管理的多用户 JupyterHub 平台
搭建基于 Anaconda 管理的多用户 JupyterHub 平台
情况:计算工作站放在实验室,多个同学需要接入使用,且需要各自独立的环境,并使用 Jupyter notebook 平台以方便协作。
步骤
1. 安装 Anaconda
由于是多人环境,应调用 root 权限在安装过程中指定安装到 /opt/anaconda/ 路径下,这样所有用户均可读,但无法直接在 base 环境下安装模块。
为了让每个用户都能访问到 conda,需要逐个在用户的 .bashrc 文件中加入 export PATH='/opt/anaconda:$PATH'。
2. 安装 JupyterHub
JupyterHub 是 Jupyter notebook 的多用户版本,每个用户可以通过自己的系统用户名和密码登录到个人独立的 Jupyter notebook 中,这样不同人的代码和数据都保存于其自己的用户目录下,同时用户的资源消耗和管理也更清晰简单,非常适合单机多用户的需求。
在 Anaconda 的 base 环境下安装 JupyterHub,注意 base 环境只有 root 可写。
(base)$ sudo conda install JupyterHub
在 base 环境下启用 JupyterHub 时亦需要通过 root,否则将会启用单用户模式,导致其他用户无法登陆。
(base)$ sudo jupyterhub
3. 安装 JupyterHub 调用 Anaconda 环境依赖
通过 conda create 创建的环境并不会默认显示在 JupyterHub 的 kernel 选项中,需要安装依赖。
(base)$ sudo conda install nb_conda_kernels
4. 用户使用
- 每个用户开始使用时,需要先建立自己的个人环境,注意由于是建立个人环境,因此该环境会写入
~/.conda下,故不再需要 root 权限,且每个用户都可以随意安装需要的 python 模块
$ conda create --name crew2. 建立好后,进入个人环境并安装 JupyterHub kernel
(base)$ source activate crew # 激活个人环境,注意下一行环境标识符发生变化
(crew)$ conda install ipykernel3. 安装所需的模块,这样模块会被安装到用户的个人环境下,不会对 base 环境或其他用户的环境造成影响,且一个用户可以创建多个相互独立的环境
(crew)$ pip install numpy # or use conda install numpy4. 访问 JupyterHub,此时可以在页面中选择所创建的个人环境的 kernel
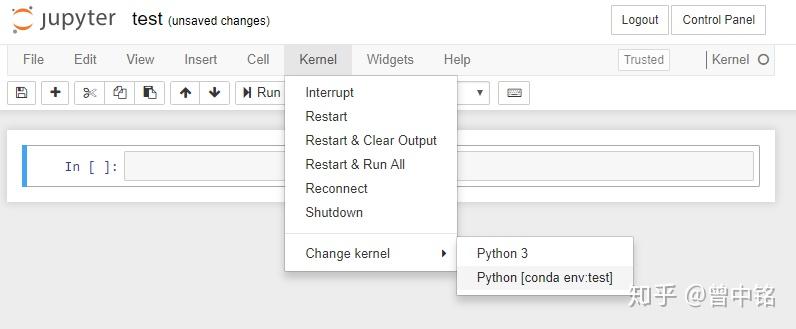
实际尝试
- 由于可能每个同学都需要使用 tensorflow 或 keras 等深度学习模块,因此我在 base 环境中预先安装好了这些模块,这样在进行深度学习时不需要费劲地重新安装模块。
- 如果同学需要安装自己的模块,则可以直接从 base 环境新建一个个人环境,个人环境会继承 base 环境已有的模块
$ conda create -n crew- 如果同学不需要继承 base 环境,而是想新建一个空白的新环境,也可以用 conda 做到
$ conda create -n crew python=3.6搭建基于 Anaconda 管理的多用户 JupyterHub 平台的更多相关文章
- 搭建基于python +opencv+Beautifulsoup+Neurolab机器学习平台
搭建基于python +opencv+Beautifulsoup+Neurolab机器学习平台 By 子敬叔叔 最近在学习麦好的<机器学习实践指南案例应用解析第二版>,在安装学习环境的时候 ...
- 搭建基于 STM32 和 rt-thread 的开发平台
我们需要平台 如果说,SharePoint 的价值之一在于提供了几乎开箱即用的 innovation 环境,那么,智能设备的开发平台也一样.不必每次都从头开始,所以需要固定的工作室和开发平台作为创新的 ...
- 面向服务体系架构(SOA)和数据仓库(DW)的思考基于 IBM 产品体系搭建基于 SOA 和 DW 的企业基础架构平台
面向服务体系架构(SOA)和数据仓库(DW)的思考 基于 IBM 产品体系搭建基于 SOA 和 DW 的企业基础架构平台 当前业界对面向服务体系架构(SOA)和数据仓库(Data Warehouse, ...
- 搭建基于SornaQube的自动化安全代码检测平台
一.背景和目的 近年来,随着新业务.新技术的快速发展,应用软件安全缺陷层出不穷.虽然一般情况下,开发者基本都会有单元测试.每日构建.功能测试等环节来保证应用的可用性.但在安全缺陷方面,缺乏安全意识.技 ...
- 手工搭建基于ABP的框架 - 工作单元以及事务管理
一个业务功能往往不只由一次数据库请求(或者服务调用)实现.为了功能的完整性,我们希望如果该功能执行一半时出错,则撤销前面已执行的改动.在数据库层面上,事务管理实现了这种完整性需求.在ABP中,一个完整 ...
- 如何用Baas快速在腾讯云上开发小程序-系列2:搭建Phabricator开发管理平台
版权声明:本文由贺嘉 原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/905333001487424158 来源:腾云阁 h ...
- 搭建基于MinGW平台的《OpenGL蓝皮书(OpenGL SuperBibe 5th)》示例代码编译环境
副标题:搭建基于MinGW平台的<OpenGL超级宝典>(OpenGL蓝皮书第5版)GLTools 编译环境.示例代码:Triangle.cpp @ SB5.zip 以下内容以及方法均参考 ...
- 基于Prometheus和Grafana的监控平台 - 环境搭建
相关概念 微服务中的监控分根据作用领域分为三大类,Logging,Tracing,Metrics. Logging - 用于记录离散的事件.例如,应用程序的调试信息或错误信息.它是我们诊断问题的依据. ...
- centos7搭建ELK Cluster集群日志分析平台(一):Elasticsearch
应用场景: ELK实际上是三个工具的集合,ElasticSearch + Logstash + Kibana,这三个工具组合形成了一套实用.易用的监控架构, 很多公司利用它来搭建可视化的海量日志分析平 ...
随机推荐
- 如何使用Python的Django框架创建自己的网站
如何使用Python的Django框架创建自己的网站 Django建站主要分四步:1.创建Django项目,2.将网页模板移植到Django项目中,3.数据交互,4.数据库 1创建Django项目 本 ...
- SparkStreaming之checkpoint检查点
一.简介 流应用程序必须保证7*24全天候运行,因此必须能够适应与程序逻辑无关的故障[例如:系统故障.JVM崩溃等].为了实现这一点,SparkStreaming需要将足够的信息保存到容错存储系统中, ...
- k8s运维处理
k8s运维处理 驱逐节点容器,进行docker,等重要组件的重启时,打驱逐标记 kubectl drain [option --node ip] 进行重启docker或kubelet等其他操作,操作完 ...
- virt-install创建虚拟机并制作成模板
一.使用virt-install创建新的虚拟机 virt--template --ram --vcpu= --virt-type kvm --cdrom=/Data/kvm/iso/CentOS-.i ...
- 《快活帮》第九次团队作业:Beta冲刺与验收准备
项目 内容 这个作业属于哪个课程 2016计算机科学与工程学院软件工程(西北师范大学) 这个作业的要求在哪里 实验十三 团队作业9:BETA冲刺与团队项目验收 团队名称 快活帮 作业学习目标 (1)掌 ...
- template_DefaultType
#include <iostream> using namespace std; template <typename T1,typename T2=int> class Te ...
- hash isEqual
hash Returns an integer that can be used as a table address in a hash table structure. If two object ...
- 电商平台+keepalived高可用
192.168.189.131 电商平台 192.168.189.129 MySQL主192.168.189.130 MySQL备192.168.189.181 VIP 配置MySQL为互为主从并结合 ...
- SQL盲注学习-布尔型
本次实验还是使用sqli-labs环境.在开始SQL盲注之前首先学习一下盲注需要用到的基础语法. 1.left()函数:left(str,lenth)它返回具有指定长度的字符串的左边部分. left( ...
- 总结TCP与UDP的区别
TCP的优点: 可靠,稳定 TCP的可靠体现在TCP在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认.窗口.重传.拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源. TCP的缺 ...