seq2seq模型详解及对比(CNN,RNN,Transformer)
一,概述
在自然语言生成的任务中,大部分是基于seq2seq模型实现的(除此之外,还有语言模型,GAN等也能做文本生成),例如生成式对话,机器翻译,文本摘要等等,seq2seq模型是由encoder,decoder两部分组成的,其标准结构如下:
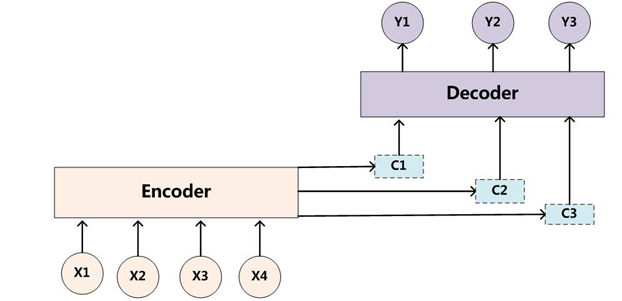
原则上encoder,decoder可以由CNN,RNN,Transformer三种结构中的任意一种组合。但实际的应用过程中,encoder,decnoder的结构选择基本是一样的(即encoder选择CNN,decoder也选择CNN,如facebook的conv2conv)。因此本文我们也就介绍encoder,decoder是同种结构的三种模型,并对比其内部结构在编码和解码的不同之处。
二,模型介绍
1)基于RNN的seq2seq模型
在这里的encoder和decoder都采用RNN系列模型,一般是GRU,LSTM等。一般有两种用法:即单向encoder-单向decoder;双向encoder-单向decoder(在这里要保证encoder的hidden_size等于decoder的hidden_size,但是对于双向encoder时,因为一般采用拼接来融合双向信息,因此此时encoder的hidden_size一般为decoder的hidden_size的一半)。
基于RNN的encoder端和用RNN做分类问题基本一致,但在decoder端需要融入encoder端的信息,因此是有一些不一样的,以GRU为例(LSTM同理):
encoder端:
$r_t = \sigma(W_r [h_{t-1}, x_t])$
$z_t = \sigma(W_z [h_{t-1}, x_t])$
$\hat{h_t} = tanh(W_{\hat{h}} [r_t * h_{t-1}, x_t])$
$h_t = (1 - z_t) * h_{t-1} + z_t * \hat{h_t}$
decoder端:需要融入attention后的encoder的编码向量$c_t$
$r_t = \sigma(W_r [h_{t-1}, x_t, c_t])$
$z_t = \sigma(W_z [h_{t-1}, x_t, c_t])$
$\hat{h_t} = tanh(W_{\hat{h}} [r_t * h_{t-1}, x_t, c_t])$
$h_t = (1 - z_t) * h_{t-1} + z_t * \hat{h_t}$
注:在decoder中的矩阵$W_r, W_z, W_{\hat{h}}$和encoder中的维度是不同的,因为后面的$ [h_{t-1}, x_t, c_t]$是拼接操作,这里面的$ h_{t-1}, x_t, c_t$都对应一个映射矩阵,只是为了方便操作,将他们对应的矩阵也拼接在一起计算了。
2)基于conv的seq2seq模型
基于卷积的seq2seq模型好像使用范围没有那么广,目前我见到的只有在机器翻译和语法纠错中有用到(当然肯定不排除在其他任务中有使用),但是基于卷积的seq2seq是引入了不少有意思的知识,首先引入了stacking conv来捕捉长距离的信息。主要围绕facebook的Convolutional Sequence to Sequence Learning 来讲解。
1)不采用池化,只采用卷积操作,并且通过padding使得每一层卷积后的序列长度不变(这种操作可以确保在多层conv中序列长度保持一致)。
2)对于输入$x$,其维度为$n*d$,在这里假设kernel size的大小为$k$,则给定一个卷积的参数矩阵$W$,其维度为$2d*kd$(本质就是一个kernel size为k的一维卷积对序列做卷积操作,并且filter size为2d,这样使得卷积后的token的向量的维度为2d),使得转换后的$h$(x的隐层表示)的维度为$n*2d$。
3)引入GLU门机制激活函数,其表达式如下:
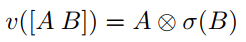
以上面得到的$h$为例,其前半段$h*d$置为A,其后半段$h*d$置为B,对B用sigmoid函数激活后类似于门机制,然后对$A$和$\sigma(B)$做元素对应相乘,这样也保证了每一层卷积后的输出维度和输入维度一致(这就是为什么第2步要使得卷积后的token的向量维度为$2d$,这种门机制在很多地方都可以使用,用来取代激活函数,既可以做非线性转换,又可以过滤重要的信息)。
4)采用了multi-step attention来连接encoder和decoder,即对decoder的每一层都单独计算attention(至于为什么要这样做,我猜可能是因为卷积是提取局部信息的,而每一层提取的局部信息都不一样,因为每一层对encoder的结果的关注位置也是不一样的,因此每一层对encoder的attention也应该是不一样的)。
3)基于transformer的seq2seq模型
基于transformer的seq2seq模型来源于attention is all you need,具体的介绍可以见详解Transformer模型(Atention is all you need)。
三,三种模型的对比
从encoder,decoder,attention三个部位来对比
encoder端:
1)RNN
RNN的encoder端和常见的用于分类的RNN模型没有什么区别,输入$x$,得到最后一层的隐层状态,用于之后计算attention。
2)conv
在这里采用stacking conv来对输入$x$编码,作者认为这种stacking conv是可以捕获到长距离的信息的,假设卷积的kernel size为3,第一层卷积能覆盖的最大长度为3(对原始序列),第二层卷积能覆盖的最大长度为$3^2$(对原始序列),依次类推,因此随着卷积层的增长,在原始序列上能覆盖的最大长度呈指数增长。同样去最后一层的隐层状态,用于之后计算attention。同时在每一层之间都引入了残差连接和batch normalization。
3)transformer
transformer的encoder和之前介绍的用transformer做分类基本一致(文本分类实战(八)—— Transformer模型)。整个结构由self-attention和feed forward层组合而成的,同样将最后一层的隐层状态用于之后计算attention。
attention端:
1)RNN
RNN的attention都是基于decoder中的目标词和encoder的序列中的每一个词计算点积(或者其他的计算方式,如MLP,conv等都可以),然后softmax得到一个概率分布,也就是attention的权值。然后对encoder的序列中的每个词对应的向量做加权和得到最终的attention的结果。具体的如下图:

2)conv
卷积中的attention的计算和RNN中的基本一致,但是最后在做加权和的时候引入了最初encoder中embedding的词向量,其表达式如下:

上面式子中$\alpha_{ij}^l$是表示$l$解码层对应的attention权重,$z_j^u$表示的是encoder最后的隐层结果,$e_j$表示的是encoder最初的embedding层的词向量,$j$表示encoder中第$j$个词。
3)transformer
transformer的attention计算有点不太一样,在这里仍然使用了在做self-attention计算中的multi-attention和scaled-attention。因此这里虽然目标词是来源于decoder,但是整个计算过程和transformer中的self-attention是一致的。
decoder端:
1)RNN
RNN在解码时一般都是用单层,因为从左到右的这种单层模式也符合解码的模式,dencoder的层数也一般和encoder保持一致。RNN的解码如上面的GRU示例一样,只是在计算的过程中引入了encoder的结果,其他的和encoder没什么太大的差异。
2)conv
conv在解码时主要是在序列的补全时和encoder不一样,为了保持卷积后序列的长度不变,encoder时会在序列的两端添加长度为$(kernel size - 1) / 2$的pad。而在decoder时会在序列的左端添加长度为$(kernel size - 1)$的pad(在这里kernel size一般取奇数,便于添加pad)。另外不同于RNN的是(RNN是将attention引入到了RNN结构中),conv在解码时的卷积操作只是提取序列的特征,然后经过GLU操作到和encoder的隐层相同的向量维度之后再计算attention,最后将attention的结果和GLU的结果和卷积前的结果相加作为下一层的输入。另外在解码的每一层都引入了残差连接和batch normalization。
3)transformer
transformer的decoder层其实和encoder层差不多,主要不同在加入了encoder的attention的结果,但这里和RNN,conv又优点不一样,这里是先对decoder中的序列做self-attention提取特征,然后再做对encoder的attention,然后进入到feed forward层,因此在这里的操作是串行的。同样再transformer中因为层数比较多,也引入了残差连接和Layer normalization(在自然语言处理中很多layer normalization的用的比batch normalization,除非是卷积,不然一般不用batch normalization)。
除了上面的不同点之外,一般来说transformer和conv的层数都比较深,因此也就需要残差连接和normalization来避免模型过拟合。此外在transformer和conv中都会引入位置向量来引入序列的位置信息,但是在RNN中,因为RNN的本质是从前往后又依赖关系的,因此位置信息在这种传递过程中已经存在了。
上述模型具体的代码见 https://github.com/jiangxinyang227/NLP-Project/tree/master/dialogue_generator
参考文献:
Convolutional Sequence to Sequence Learning
NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
Attention Is All You Need
A Multilayer Convolutional Encoder-Decoder Neural Network for Grammatical Error Correction
seq2seq模型详解及对比(CNN,RNN,Transformer)的更多相关文章
- ASP.NET Core的配置(2):配置模型详解
在上面一章我们以实例演示的方式介绍了几种读取配置的几种方式,其中涉及到三个重要的对象,它们分别是承载结构化配置信息的Configuration,提供原始配置源数据的ConfigurationProvi ...
- ISO七层模型详解
ISO七层模型详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在我刚刚接触运维这个行业的时候,去面试时总是会做一些面试题,笔试题就是看一个运维工程师的专业技能的掌握情况,这个很 ...
- 28、vSocket模型详解及select应用详解
在上片文章已经讲过了TCP协议的基本结构和构成并举例,也粗略的讲过了SOCKET,但是讲解的并不完善,这里详细讲解下关于SOCKET的编程的I/O复用函数. 1.I/O复用:selec函数 在介绍so ...
- 第94天:CSS3 盒模型详解
CSS3盒模型详解 盒模型设定为border-box时 width = border + padding + content 盒模型设定为content-box时 width = content所谓定 ...
- JVM的类加载过程以及双亲委派模型详解
JVM的类加载过程以及双亲委派模型详解 这篇文章主要介绍了JVM的类加载过程以及双亲委派模型详解,类加载器就是根据指定全限定名称将 class 文件加载到 JVM 内存,然后再转化为 class 对象 ...
- 云时代架构阅读笔记六——Java内存模型详解(二)
承接上文:云时代架构阅读笔记五——Java内存模型详解(一) 原子性.可见性.有序性 Java内存模型围绕着并发过程中如何处理原子性.可见性和有序性这三个特征来建立的,来逐个看一下: 1.原子性(At ...
- css 06-CSS盒模型详解
06-CSS盒模型详解 #盒子模型 #前言 盒子模型,英文即box model.无论是div.span.还是a都是盒子. 但是,图片.表单元素一律看作是文本,它们并不是盒子.这个很好理解,比如说,一张 ...
- 图解机器学习 | LightGBM模型详解
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/34 本文地址:http://www.showmeai.tech/article-det ...
- 数据备份RAID1 和RAID5详解和对比
数据备份RAID1 和RAID5详解和对比 RAID 全称 Redundant Array of Independent Disks,中文意思"独立的冗余磁盘列队". RAID 一 ...
随机推荐
- stringstream字符串流的妙用
现在有一个数组,其值为从1到10000的连续增长的数字.出于某次偶然操作,导致这个数组中丢失了某三个元素,同时顺序被打乱,现在需要你用最快的方法找出丢失的这三个元素,并且将这三个元素根据从小到大重新拼 ...
- WebAPI 使用控制台启动
using System; using System.Web.Http; using System.Web.Http.SelfHost; namespace UAC_OAuth2Center { pu ...
- Kubernetes 学习(八)Kubernetes 源码阅读之初级篇------源码及依赖下载
0. 前言 阅读了一段时间 Golang 开源代码,准备正式阅读 Kubernetes 项目代码(工作机 Golang 版本为 Go 1.12) 参照 <k8s 源码阅读> 选择 1.13 ...
- Spring IOC 常用的注解
一.@Bean 1.配置类 @Configuration public class MainConfig { @Bean public Person person(){ return new Pers ...
- Eclipse JAX-RS (REST Web Services) 2.0 requires Java 1.6 or newer
pom.xml文件中添加: <build> <plugins> <plugin> <groupId>org.apache.maven.plugins&l ...
- Oracle的创建表空间及用户
学习笔记: 1.创建表空间 --创建表空间 create tablespace thepathofgrace datafile 'c:\thepathofgrace.dbf' size 100m au ...
- form.submit()提交后返回数据的处理
form.submit()发送请求一般是单向的,如果需要取返回的数据,一般会发送ajax请求,但是如果form中有附件呢?(以后有时间给大家分享ajax上传附件的功能),确实需要返回数据来知道该功能是 ...
- 1 Python命令行参数(脚本神器)
#!/usr/bin/env python3.7 # -*- coding:utf-8 -*- # Author: Lancer 2019-09-02 10:07:21 import sys,geto ...
- 两道JVM面试题,竟让我回忆起了中学时代!
作者:肥朝 原文链接:https://mp.weixin.qq.com/s/4wJ6ANal0blLOseasfIuVw 中学授课模式 考虑到可能有部分粉丝对JVM参数不清楚,所以我们参照中学的授课模 ...
- php 获取文件下的所有文件。php 获取文件下的所有子文件。php 递归获取文件下的所有文件。封装好的方法
//php 获取文件下的所有文件.php 获取文件下的所有子文件.php 递归获取文件下的所有文件.直接上封装好的php代码 <?php //文件路径 $dir = dirname(__FILE ...