word2vec原理总结
一篇很好的入门博客,http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
他的翻译,https://www.jianshu.com/p/1405932293ea
可以作为参考的,https://blog.csdn.net/mr_tyting/article/details/80091842
有论文和代码,https://blog.csdn.net/mr_tyting/article/details/80091842
word2vector,顾名思义,就是将语料库中的词转化成向量,以便后续在词向量的基础上进行各种计算。
最常见的表示方法是counting 编码。假设我们的语料库中是如下三句话:
I like deep learning
I like NLP
I enjoy flying
利用counting编码,我们可以绘出如下矩阵:
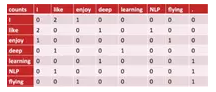
假设语料库中的单词数量是N,则上图矩阵的大小就是N*N,其中的每一行就代表一个词的向量表示。如第一行
0 2 1 0 0 0 0
是单词I的向量表示。其中的2代表I这个单词与like这个词在语料库中共同出现了2次。
但是这种办法至少有三个缺陷:
- 1是词语数量较大时,向量维度高且稀疏,向量矩阵巨大而难以存储
- 2是向量并不包含单词的语义内容,只是基于数量统计。
- 3是当有新的词加入语料库后,整个向量矩阵需要更新
尽管我们可以通过SVD来降低向量的维度,但是SVD本身却是一个需要巨大计算量的操作。
很明显,这种办法在实际中并不好用。我们今天学习的skip gram算法可以成功克服以上三个缺陷。它的基本思想是首先将所有词语进行one-hot编码,输入只有一个隐藏层的神经网络,定义好loss后进行训练,后面我们会讲解如何定义loss,这里暂时按下不表。训练完成后,我们就可以用隐藏层的权重来作为词的向量表示!!
这个思想乍听起来很神奇是不是?其实我们早就熟悉它了。auto-encoder时,我们也是用有一个隐藏层的神经网络进行训练,训练完成后,丢去后面的output层,只用隐藏层的输出作为最终需要的向量对象,藉此成功完成向量的压缩。
Word2Vec工作流程
Word2Vec有两种训练方法,一种叫CBOW,核心思想是从一个句子里面把一个词抠掉,用这个词的上文和下文去预测被抠掉的这个词;第二种叫做Skip-gram,和CBOW正好反过来,输入某个单词,要求网络预测它的上下文单词。下面以Skip-gram为例介绍,
1、word2Vec只是一个三层 的神经网络。
2、喂给模型一个word,然后用来预测它周边的词。
3、然后去掉最后一层,只保存input_layer 和 hidden_layer。
4、从词表中选取一个词,喂给模型,在hidden_layer 将会给出该词的embedding repesentation。
用神经网络训练,大体有如下几个步骤:
准备好data,即X和Y
定义好网络结构
定义好loss
选择合适的优化器
进行迭代训练
存储训练好的网络
一、构造训练数据
假设我们的语料库中只有一句话:The quick brown fox jumps over the lazy dog.
这句话中共有8个词(这里The与the算同一个词)。skip gram算法是怎么为这8个词生成词向量的呢?
其实非常简单,(x,y)就是一个个的单词对。比如(the,quick)就是一个单词对,the就是样本数据,quick就是该条样本的标签。
那么,如何从上面那句话中生成单词对数据呢?答案就是n-gram方法。多说不如看图:
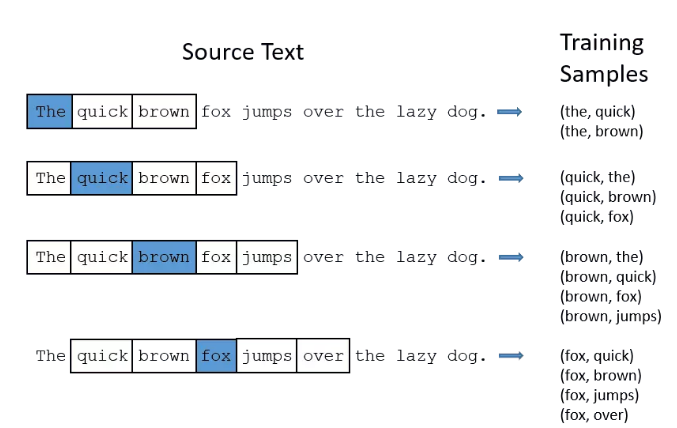
你可能会想,(fox,brown)也是一个单词对,它输入神经网络后,岂不是希望神经网络告诉我们,在8个单词中,brown是更可能出现在fox周围?如果是这样,那么训练完成后的神经网络,输入fox,它的输出会是brown和jumps的哪一个呢?
答案是取决于(fox,brown)和(fox,jumps)两个单词对谁在训练集中出现的次数比较多,神经网络就会针对哪个单词对按照梯度下降进行更多的调整,从而就会倾向于预测谁将出现在fox周围。
二、数字化表示单词对
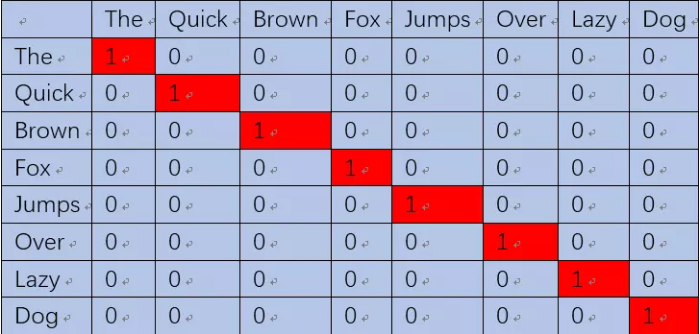
(the,quick)单词对就表示成【(1,0,0,0,0,0,0,0),(0,1,0,0,0,0,0,0)】。这样就可以输入神经网络进行训练了,当我们将the输入神经网络时,希望网络也能输出一个8维的向量,并且第二维尽可能接近1(即接近quick),其他维尽可能接近0。也就是让神经网络告诉我们,quick更可能出现在the的周围。当然,我们还希望这8维向量所有位置的值相加为1,因为相加为1就可以认为这个8维向量描述的是一个概率分布,正好我们的y值也是一个概率分布(一个位置为1,其他位置为0),我们就可以用交叉熵来衡量神经网络的输出与我们的label y的差异大小,也就可以定义出loss了。
网络结构如下,它的隐藏层并没有激活函数,但是输出层却用了softmax,这是为了保证输出的向量是一个概率分布。
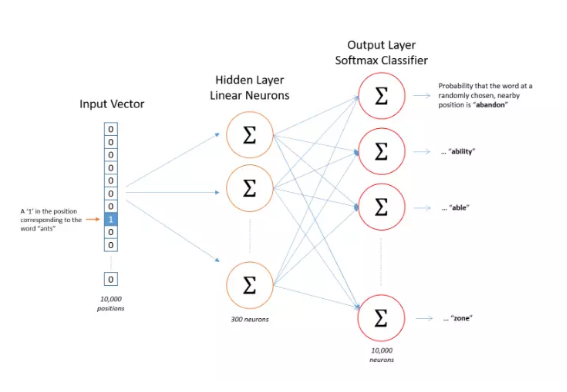
4、隐藏层
这取决于我们希望得到的词向量是多少维,有多少个隐藏神经元词向量就是多少维。每一个隐藏的神经元接收的输入都是一个8维向量,假设我们的隐藏神经元有3个(仅仅是为了举例说明使用,实际中,google推荐的是300个,但具体多少合适,需要你自己进行试验,怎么效果好怎么来),如此以来,隐藏层的权重就可以用一个8行3列的矩阵来表示,这个8行3列的矩阵的第一行,就是三个隐藏神经元对应于输入向量第一维的权重,如下图所示:
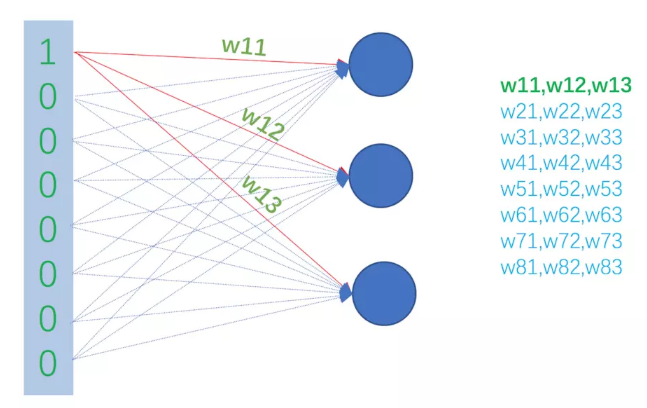
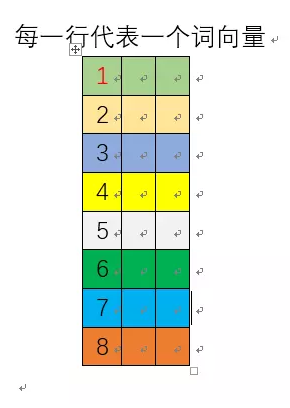
网络训练完成后,这个8行3列的矩阵的每一行就是一个单词的词向量!如下图所示:
网络的输入是one-hot编码的单词,它与隐藏层权重矩阵相乘实际上是取权重矩阵特定的行,如下图所示:
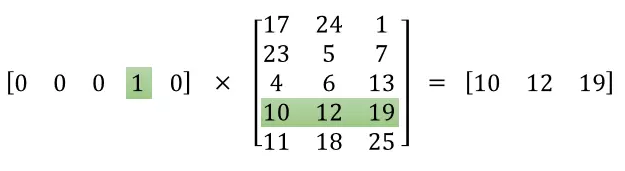
这意味着,隐藏层实际上相当于是一个查找表,它的输出就是输入的单词的词向量
5、输出层
输出层的神经元数量和语料库中的单词数量一样。每一个神经元可以认为对应一个单词的输出权重,词向量乘以该输出权重就得到一个数,该数字代表了输出神经元对应的单词出现在输入单词周围的可能性大小,通过对所有的输出层神经元的输出进行softmax操作,我们就把输出层的输出规整为一个概率分布了。如下图所示:
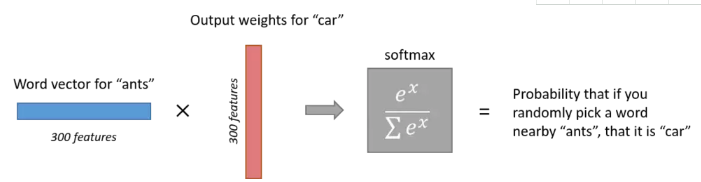
这里有一点需要注意,我们说输出的是该单词出现在输入单词周围的概率大小,这个“周围”包含单词的前面,也包含单词的后面。
首先,语义相近的词往往有着类似的上下文。这是什么意思呢?举例来说,“聪明”和“伶俐”两个词语义是相近的,那么它们的使用场景也是相似的,它们周围的词很大程度上是相近或相同的。
语义相近的词有着相似的上下文,让我们的神经网络在训练过程中对相近的词产生相近的输出向量。网络如何做到这一点呢?答案就是训练完成后,网络能够对语义相近的词产生相近的词向量。因为此时的输出层已经训练完成,不会改变了。
6、负采样

在tensorflow里面实现的word2Vec,vocab_szie并不是所有的word的数量,而且先统计了所有word的出现频次,然后选取出现频次最高的前50000的词作为词袋。具体操作请看代码 tensorflow/examples/tutorials/word2vec/word2vec_basic.py,其余的词用unkunk代替。
采用一种所谓的”负采样”的操作,这种操作每次可以让一个样本只更新权重矩阵中一小部分,减小训练过程中的计算压力。
举例来说:一个input output pair如:(“fox”,“quick”),由上面的分析可知,其true label为一个one−hot向量,并且该向量只是在quick的位置为1,其余的位置均为0,并且该向量的长度为vocab size,由此每个样本都缓慢能更新权重矩阵,而”负采样”操作只是随机选择其余的部分word,使得其在true label的位置为0,那么我们只更新对应位置的权重。例如我们如果选择负采样数量为5,则选取5个其余的word,使其对应的output为0,这个时候output只是6个神经元,本来我们一次需要更新300∗10,000参数,进行负采样操作以后只需要更新300∗6=1800个参数。
word2vec原理总结的更多相关文章
- word2vec原理(一) CBOW与Skip-Gram模型基础
word2vec原理(一) CBOW与Skip-Gram模型基础 word2vec原理(二) 基于Hierarchical Softmax的模型 word2vec原理(三) 基于Negative Sa ...
- word2vec原理(二) 基于Hierarchical Softmax的模型
word2vec原理(一) CBOW与Skip-Gram模型基础 word2vec原理(二) 基于Hierarchical Softmax的模型 word2vec原理(三) 基于Negative Sa ...
- word2vec原理(三) 基于Negative Sampling的模型
word2vec原理(一) CBOW与Skip-Gram模型基础 word2vec原理(二) 基于Hierarchical Softmax的模型 word2vec原理(三) 基于Negative Sa ...
- word2vec原理(一) CBOW与Skip-Gram模型基础——转载自刘建平Pinard
转载来源:http://www.cnblogs.com/pinard/p/7160330.html word2vec是google在2013年推出的一个NLP工具,它的特点是将所有的词向量化,这样词与 ...
- word2vec原理(一) CBOW+Skip-Gram模型基础
word2vec是google在2013年推出的一个NLP工具,它的特点是将所有的词向量化,这样词与词之间就可以定量的去度量他们之间的关系,挖掘词之间的联系.本文的讲解word2vec原理以Githu ...
- word2vec原理CBOW与Skip-Gram模型基础
转自http://www.cnblogs.com/pinard/p/7160330.html刘建平Pinard word2vec是google在2013年推出的一个NLP工具,它的特点是将所有的词向量 ...
- 【转载】word2vec原理推导与代码分析
本文的理论部分大量参考<word2vec中的数学原理详解>,按照我这种初学者方便理解的顺序重新编排.重新叙述.题图来自siegfang的博客.我提出的Java方案基于kojisekig,我 ...
- Word2Vec原理及代码
一.Word2Vec简介 Word2Vec 是 Google 于 2013 年开源推出的一款将词表征为实数值向量的高效工具,采用的模型有CBOW(Continuous Bag-Of-Words,连续的 ...
- word2vec原理分析
本文摘录整编了一些理论介绍,推导了word2vec中的数学原理,理论部分大量参考<word2vec中的数学原理详解>. 背景 语言模型 在统计自然语言处理中,语言模型指的是计算一个句子的概 ...
- word2vec原理知识铺垫
word2vec: 词向量计算工具====>训练结果 词向量(word embedding) 可以很好的度量词与词的相似性,word2vec为浅层神经网络 *值得注意的是,word2vec是计算 ...
随机推荐
- 分页查询——Hibernate Criteria实现一次查询取得总记录数和分页后结果集
使用Hibernate criteria进行分页查询时,如何实现一次查询取得总记录数和分页后结果集 - bto310 - ITeye博客 https://bto310.iteye.com/blog/1 ...
- 使用django的MTV开发模式返回一个网页
1.MTV开发模式介绍 M:Models 模型(数据) 与数据组织相关的功能.组织和存储数据的方法和模式,与数据模型相关的操作. T:Templates 模板(样式) 与表现相关的所有功能.页面展示风 ...
- python预课05 爬虫初步学习+jieba分词+词云库+哔哩哔哩弹幕爬取示例(数据分析pandas)
结巴分词 import jieba """ pip install jieba 1.精确模式 2.全模式 3.搜索引擎模式 """ txt ...
- 在IAR平台建立STC8ASK64S4A12单片机工程
转载:http://www.51hei.com/bbs/forum.php?mod=viewthread&tid=168481&page=1#pid737250 一般我们使用STC单 ...
- MongoDB干货系列2-MongoDB执行计划分析详解(2)(转载)
写在之前的话 作为近年最为火热的文档型数据库,MongoDB受到了越来越多人的关注,但是由于国内的MongoDB相关技术分享屈指可数,不少朋友向我抱怨无从下手. <MongoDB干货系列> ...
- CLR Exception---E0434F4D
什么是CLR Exception---E0434F4D 就是公共语言运行时(CLR)异常,异常代码为0xE0434F4D.因此任何托管异常,如NullReferenceException.invali ...
- 8-ESP8266 SDK开发基础入门篇--编写串口上位机软件
https://www.cnblogs.com/yangfengwu/p/11087558.html 咱用这个编写 ,版本都无所谓哈,只要自己有就可以,不同版本怎么打开 https://www.cnb ...
- python开发面试问题
python语法以及其他基础部分 可变与不可变类型: 浅拷贝与深拷贝的实现方式.区别:deepcopy如果你来设计,如何实现: __new__() 与 __init__()的区别: 你知道几种设计模式 ...
- A_G_C_007
AGC007 A Shik and Stone 我是沙比这都能蛙一发 https://agc007.contest.atcoder.jp/submissions/7946110 B Construct ...
- 【CSP-S膜你考】即时战略(模拟)
Problem B. 即时战略 (rts.c/cpp/pas) 注意 Input file: rts.in Output file: rts.out Time Limit : 2 seconds Me ...