Django中的QuerySet查询优化之实例篇
转载的,做个笔记,原文链接
在数据库有外键的时候,使用 select_related() 和 prefetch_related() 可以很好的减少数据库请求的次数,从而提高性能。本文通过一个简单的例子详解这两个函数的作用。虽然QuerySet的文档中已经详细说明了,但本文试图从QuerySet触发的SQL语句来分析工作方式,从而进一步了解Django具体的运作方式。
实例背景
假定一个个人信息系统,需要记录系统中各个人的故乡、居住地、以及到过的城市。数据库设计如下:
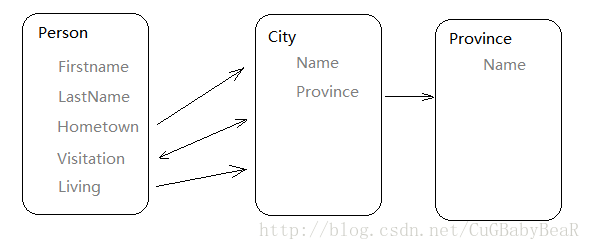
models.py 内容:
from django.db import models
class Province(models.Model):
name = models.CharField(max_length=10)
def __unicode__(self):
return self.name
class City(models.Model):
name = models.CharField(max_length=5)
province = models.ForeignKey(Province)
def __unicode__(self):
return self.name
class Person(models.Model):
firstname = models.CharField(max_length=10)
lastname = models.CharField(max_length=10)
visitation = models.ManyToManyField(City, related\_name = "visitor")
hometown = models.ForeignKey(City, related\_name = "birth")
living = models.ForeignKey(City, related\_name = "citizen")
def __unicode__(self):
return self.firstname + self.lastname
PS:
注1:创建的app名为“QSOptimize”
注2:为了简化起见,qsoptimize_province 表中只有2条数据:湖北省和广东省,qsoptimize_city表中只有三条数据:武汉市、十堰市和广州市
一些实例
选择哪些函数
如果我们想要获得所有家乡是湖北的人,最无脑的做法是先获得湖北省,再获得湖北的所有城市,最后获得故乡是这个城市的人。就像这样:
>>> hb = Province.objects.get(name__iexact=u"湖北省")
>>> people = []
>>> for city in hb.city_set.all():
... people.extend(city.birth.all())
...
显然这不是一个明智的选择,因为这样做会导致1+(湖北省城市数)次SQL查询。反正是个反例,导致的查询和获得掉结果就不列出来了。
prefetch_related() 或许是一个好的解决方法,让我们来看看。
>>> hb = Province.objects.prefetch_related("city_set__birth").objects.get(name__iexact=u"湖北省")
>>> people = []
>>> for city in hb.city_set.all():
... people.extend(city.birth.all())
...
因为是一个深度为2的prefetch,所以会导致3次SQL查询:
SELECT `QSOptimize_province`.`id`, `QSOptimize_province`.`name`
FROM `QSOptimize_province`
WHERE `QSOptimize_province`.`name` LIKE '湖北省' ;
SELECT `QSOptimize_city`.`id`, `QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`
FROM `QSOptimize_city`
WHERE `QSOptimize_city`.`province_id` IN (1);
SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`, `QSOptimize_person`.`lastname`,
`QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id`
FROM `QSOptimize_person`
WHERE `QSOptimize_person`.`hometown_id` IN (1, 3);
嗯…看上去不错,但是3次查询么?倒过来查询可能会更简单?
>>> people = list(Person.objects.select_related("hometown__province").filter(hometown__province__name__iexact=u"湖北省"))
SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`, `QSOptimize_person`.`lastname`,
`QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id`, `QSOptimize_city`.`id`,
`QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`, `QSOptimize_province`.`id`, `QSOptimize_province`.`name`
FROM `QSOptimize_person`
INNER JOIN `QSOptimize_city` ON (`QSOptimize_person`.`hometown_id` = `QSOptimize_city`.`id`)
INNER JOIN `QSOptimize_province` ON (`QSOptimize_city`.`province_id` = `QSOptimize_province`.`id`)
WHERE `QSOptimize_province`.`name` LIKE '湖北省';
+----+-----------+----------+-------------+-----------+----+--------+-------------+----+--------+
| id | firstname | lastname | hometown_id | living_id | id | name | province_id | id | name |
+----+-----------+----------+-------------+-----------+----+--------+-------------+----+--------+
| 1 | 张 | 三 | 3 | 1 | 3 | 十堰市 | 1 | 1 | 湖北省 |
| 2 | 李 | 四 | 1 | 3 | 1 | 武汉市 | 1 | 1 | 湖北省 |
| 3 | 王 | 麻子 | 3 | 2 | 3 | 十堰市 | 1 | 1 | 湖北省 |
+----+-----------+----------+-------------+-----------+----+--------+-------------+----+--------+
3 rows in set (0.00 sec)
完全没问题。不仅SQL查询的数量减少了,python程序上也精简了。
select_related()的效率要高于prefetch_related()。因此,最好在能用select_related()的地方尽量使用它,也就是说,对于ForeignKey字段,避免使用prefetch_related()。
联用
对于同一个QuerySet,你可以同时使用这两个函数。
在我们一直使用的例子上加一个model:Order (订单)
class Order(models.Model):
customer = models.ForeignKey(Person)
orderinfo = models.CharField(max_length=50)
time = models.DateTimeField(auto_now_add = True)
def __unicode__(self):
return self.orderinfo
如果我们拿到了一个订单的id 我们要知道这个订单的客户去过的省份。因为有ManyToManyField显然必须要用prefetch_related()。如果只用prefetch_related()会怎样呢?
>>> plist = Order.objects.prefetch_related('customer__visitation__province').get(id=1)
>>> for city in plist.customer.visitation.all():
... print city.province.name
...
显然,关系到了4个表:Order、Person、City、Province,根据prefetch_related()的特性就得有4次SQL查询
SELECT `QSOptimize_order`.`id`, `QSOptimize_order`.`customer_id`, `QSOptimize_order`.`orderinfo`, `QSOptimize_order`.`time`
FROM `QSOptimize_order`
WHERE `QSOptimize_order`.`id` = 1 ;
SELECT `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`, `QSOptimize_person`.`lastname`, `QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id`
FROM `QSOptimize_person`
WHERE `QSOptimize_person`.`id` IN (1);
SELECT (`QSOptimize_person_visitation`.`person_id`) AS `_prefetch_related_val`, `QSOptimize_city`.`id`,
`QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`
FROM `QSOptimize_city`
INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`)
WHERE `QSOptimize_person_visitation`.`person_id` IN (1);
SELECT `QSOptimize_province`.`id`, `QSOptimize_province`.`name`
FROM `QSOptimize_province`
WHERE `QSOptimize_province`.`id` IN (1, 2);
+----+-------------+---------------+---------------------+
| id | customer_id | orderinfo | time |
+----+-------------+---------------+---------------------+
| 1 | 1 | Info of Order | 2014-08-10 17:05:48 |
+----+-------------+---------------+---------------------+
1 row in set (0.00 sec)
+----+-----------+----------+-------------+-----------+
| id | firstname | lastname | hometown_id | living_id |
+----+-----------+----------+-------------+-----------+
| 1 | 张 | 三 | 3 | 1 |
+----+-----------+----------+-------------+-----------+
1 row in set (0.00 sec)
+-----------------------+----+--------+-------------+
| _prefetch_related_val | id | name | province_id |
+-----------------------+----+--------+-------------+
| 1 | 1 | 武汉市 | 1 |
| 1 | 2 | 广州市 | 2 |
| 1 | 3 | 十堰市 | 1 |
+-----------------------+----+--------+-------------+
3 rows in set (0.00 sec)
+----+--------+
| id | name |
+----+--------+
| 1 | 湖北省 |
| 2 | 广东省 |
+----+--------+
2 rows in set (0.00 sec)
更好的办法是先调用一次select_related()再调用prefetch_related(),最后再select_related()后面的表
>>> plist = Order.objects.select_related('customer').prefetch_related('customer__visitation__province').get(id=1)
>>> for city in plist.customer.visitation.all():
... print city.province.name
...
这样只会有3次SQL查询,Django会先做select_related,之后prefetch_related的时候会利用之前缓存的数据,从而避免了1次额外的SQL查询:
SELECT `QSOptimize_order`.`id`, `QSOptimize_order`.`customer_id`, `QSOptimize_order`.`orderinfo`,
`QSOptimize_order`.`time`, `QSOptimize_person`.`id`, `QSOptimize_person`.`firstname`,
`QSOptimize_person`.`lastname`, `QSOptimize_person`.`hometown_id`, `QSOptimize_person`.`living_id`
FROM `QSOptimize_order`
INNER JOIN `QSOptimize_person` ON (`QSOptimize_order`.`customer_id` = `QSOptimize_person`.`id`)
WHERE `QSOptimize_order`.`id` = 1 ;
SELECT (`QSOptimize_person_visitation`.`person_id`) AS `_prefetch_related_val`, `QSOptimize_city`.`id`,
`QSOptimize_city`.`name`, `QSOptimize_city`.`province_id`
FROM `QSOptimize_city`
INNER JOIN `QSOptimize_person_visitation` ON (`QSOptimize_city`.`id` = `QSOptimize_person_visitation`.`city_id`)
WHERE `QSOptimize_person_visitation`.`person_id` IN (1);
SELECT `QSOptimize_province`.`id`, `QSOptimize_province`.`name`
FROM `QSOptimize_province`
WHERE `QSOptimize_province`.`id` IN (1, 2);
+----+-------------+---------------+---------------------+----+-----------+----------+-------------+-----------+
| id | customer_id | orderinfo | time | id | firstname | lastname | hometown_id | living_id |
+----+-------------+---------------+---------------------+----+-----------+----------+-------------+-----------+
| 1 | 1 | Info of Order | 2014-08-10 17:05:48 | 1 | 张 | 三 | 3 | 1 |
+----+-------------+---------------+---------------------+----+-----------+----------+-------------+-----------+
1 row in set (0.00 sec)
+-----------------------+----+--------+-------------+
| _prefetch_related_val | id | name | province_id |
+-----------------------+----+--------+-------------+
| 1 | 1 | 武汉市 | 1 |
| 1 | 2 | 广州市 | 2 |
| 1 | 3 | 十堰市 | 1 |
+-----------------------+----+--------+-------------+
3 rows in set (0.00 sec)
+----+--------+
| id | name |
+----+--------+
| 1 | 湖北省 |
| 2 | 广东省 |
+----+--------+
2 rows in set (0.00 sec)
值得注意的是,可以在调用prefetch_related之前调用select_related,并且Django会按照你想的去做:先select_related,然后利用缓存到的数据prefetch_related。然而一旦prefetch_related已经调用,select_related将不起作用。
总结
- 因为select_related()总是在单次SQL查询中解决问题,而prefetch_related()会对每个相关表进行SQL查询,因此select_related()的效率通常比后者高。
- 鉴于第一条,尽可能的用select_related()解决问题。只有在select_related()不能解决问题的时候再去想prefetch_related()。
- 你可以在一个QuerySet中同时使用select_related()和prefetch_related(),从而减少SQL查询的次数。
- 只有prefetch_related()之前的select_related()是有效的,之后的将会被无视掉。
Django中的QuerySet查询优化之实例篇的更多相关文章
- Django中的QuerySet查询优化之select_related
在数据库有外键的时候,使用 select_related() 和 prefetch_related() 可以很好的减少数据库请求的次数,从而提高性能.本文通过一个简单的例子详解这两个函数的作用.虽然Q ...
- Django中的QuerySet查询优化之prefetch_related
转载的,做个笔记,原文链接 在数据库有外键的时候,使用 select_related() 和 prefetch_related() 可以很好的减少数据库请求的次数,从而提高性能.本文通过一个简单的例子 ...
- Django中的app及mysql数据库篇(ORM操作)
Django常见命令 在Django的使用过程中需要使用命令让Django进行一些操作,例如创建Django项目.启动Django程序.创建新的APP.数据库迁移等. 创建Django项目 一把我们都 ...
- Django中manger/QuerySet类与mysql数据库的查询
Django中的单表操作 1.精确查询 #查询的结果返回是容器Query Set的函数(Query Set模型类)# 1. all() 查询的所有的符合条件的结果,支持正向索引,支持索引切片,不 ...
- Django中的QuerySet
一.QuerySet 查询集,类似一个列表,包含了满足查询条件的所有项.QuerySet 可以被构造,过滤,切片,做为参数传递,这些行为都不会对数据库进行操作.只有你查询的时候才真正的操作数据库.意味 ...
- Django——Django中的QuerySet API 与ORM(对象关系映射)
首先名词解释. ORM: 对象关系映射(英语:Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序技术,用于实现面向对象编程语言里不同类型 ...
- vue-learning:41 - Vuex - 第二篇:const store = new Vue.Store(option)中option选项、store实例对象的属性和方法
vuex 第二篇:const store = new Vue.Store(option)中option选项.store实例对象的属性和方法 import Vuex from 'vuex' const ...
- Django中常用字段
一.Django框架的常用字段 Django ORM 常用字段和参数 常用字段 常用字段 AutoField int自增列,必须填入参数 primary_key=True.当model中如果没有自增列 ...
- Django中的Model(操作表)
Model 操作表 一.基本操作 # 增 models.Tb1.objects.create(c1='xx', c2='oo') #增加一条数据,可以接受字典类型数据 **kwargs obj = m ...
随机推荐
- c++中的static,const,const static以及它们的初始化
const定义的常量在超出其作用域之后其空间会被释放,而static定义的静态常量在函数执行后不会释放其存储空间. static表示的是静态的.类的静态成员函数.静态成员变量是和类相关的,而不是和类的 ...
- Node.js创建服务及实现静态资源托管/接口请求
1.环境 采用12.13.x版本 2.创建server.js 文件内容如下: let http = require("http"); let fs = require(" ...
- 01_搭建新浪云SAE
Step1:注册新浪云计算平台用新浪微博登陆新浪云计算平台,网址:http://sae.sina.com.cn/ 登陆成功之后会跳转到安全设置页面,安全设置页面要填写的东西比较多,需要注意:安全设置里 ...
- AQS面试题
问:什么是AQS? 答:AQS的全称为(AbstractQueuedSynchronizer),这个类在java.util.concurrent.locks包下面.AQS是一个用来构建锁和同步器的框架 ...
- A tow-day exam
D1 T1l \(des:\) 给出一棵树,判断树上两条路径是否相交 \(sol:\) 判断其中一条路径的两个端点以及两端点的 \(lca\) 是否存在于另一条链上 由于这是一棵树,任一点为根后这样判 ...
- Poj 1743 Musical Theme(后缀数组+二分答案)
Musical Theme Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 28435 Accepted: 9604 Descri ...
- Kafka 幂等生产者和事务生产者特性(讨论基于 kafka-python | confluent-kafka 客户端)
Kafka 提供了一个消息交付可靠性保障以及精确处理一次语义的实现.通常来说消息队列都提供多种消息语义保证 最多一次 (at most once): 消息可能会丢失,但绝不会被重复发送. 至少一次 ( ...
- Hbase监控指标项
名词解释 JMX:Java Management Extensions,用于用于Java程序扩展监控和管理项 GC:Garbage Collection,垃圾收集,垃圾回收机制 指标项来源 主机名 u ...
- avalon结合原生js tab切换
<div class="fishqc-tap"> <div ms-class="[@codePic!=''&&@codeInfo!='' ...
- ManualResetEven使用的最清楚说明
ManualResetEven使用的最清楚说明 快速阅读 理解ManualResetEvent,以及如何使用. 官方说明 官方介绍:https://docs.microsoft.com/en-us/d ...