linux记录-安装elk记录(参考博文)
什么是ELK?
通俗来讲,ELK是由Elasticsearch、Logstash、Kibana 、filebeat三个开源软件的组成的一个组合体,这三个软件当中,每个软件用于完成不同的功能,ELK 又称为ELK stack,官方域名为stactic.co,ELK stack的主要优点有如下几个:
处理方式灵活: elasticsearch是实时全文索引,具有强大的搜索功能
配置相对简单:elasticsearch全部使用JSON 接口,logstash使用模块配置,kibana的配置文件部分更简单。
检索性能高效:基于优秀的设计,虽然每次查询都是实时,但是也可以达到百亿级数据的查询秒级响应。
集群线性扩展:elasticsearch和logstash都可以灵活线性扩展
前端操作绚丽:kibana的前端设计比较绚丽,而且操作简单
什么是Elasticsearch:
是一个高度可扩展的开源全文搜索和分析引擎,它可实现数据的实时全文搜索搜索、支持分布式可实现高可用、提供API接口,可以处理大规模日志数据,比如Nginx、Tomcat、系统日志等功能。
什么是Logstash
可以通过插件实现日志收集和转发,支持日志过滤,支持普通log、自定义json格式的日志解析。
什么是kibana:
主要是通过接口调用elasticsearch的数据,并进行前端数据可视化的展现。
什么是Beats
Beats在这里是一个轻量级日志采集器,其实Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比 Logstash,Beats所占系统的CPU和内存几乎可以忽略不计

为什么使用 ELK?
ELK组件在海量日志系统的运维中,可用于解决以下主要问题:
- 分布式日志数据统一收集,实现集中式查询和管理
- 故障排查
- 安全信息和事件管理
- 报表功能
ELK组件在大数据运维系统中,主要可解决的问题如下:
- 日志查询,问题排查,故障恢复,故障自愈
- 应用日志分析,错误报警
- 性能分析,用户行为分析
一、elasticsearch部署:
1.新建用户es:useradd es
2.下载包
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.6.0.tar.gz
wget https://artifacts.elastic.co/downloads/kibana/kibana-6.6.0-linux-x86_64.tar.gz
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.6.0.tar.gz
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.6.0-linux-x86_64.tar.gz
3.环境初始化化(IP 主机名 jdk git npm)
4.解压
tar xf elasticsearch-6.6.0.tar.gz
mv elasticsearch-6.6.0 es
mkdir data
mkdir logs
chown -R es. es/
cd es/config
vi elasticsearch.yml # 编辑内容
cluster.name: elk
node.name: node-1
path.data: /es/data #当然这个目录可以你自己定
path.logs: /es/logs #当然这个目录可以你自己定
network.host: 你这台的ip
http.port: 9200
discovery.zen.ping.unicast.hosts: ["你的ip"]
http.cors.enabled: true # 开放插件head访问
http.cors.allow-origin: "*" # 开放插件head访问
bootstrap.system_call_filter: false
启动
cd es
./bin/elasticsearch &
配置
一、max file descriptors [65535] for elasticsearch process is too low, increase to at least [65536]
异常原因:单进程可打开文件数不够
解决办法:
sudo vim /etc/security/limits.conf
在最下面一行添加(具体数值看你报错的数,按照他推荐的来):
es soft nofile 65536 # 软限制,小于等于下面的数值
es hard nofile 65536 # 硬限制
返回后重新登录该账户(不然数量不变化)
ulimit -Hn # 查看数量是否为65536
二、max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
异常原因:jvm最大进程数低
解决办法:
sudo vim /etc/sysctl.conf
然后添加下面这行
vm.max_map_count=655360
保存退出,然后查看
sysctl -p # 显示的数量为更改后的就没问题了
三、(我的服务器并未报这个异常)
memory locking requested for elasticsearch process but memory is not locked
解决办法:
vim /etc/security/limits.conf
es - memlock unlimited
四、(我的服务器并未报这个异常)
max number of threads [3802] for user [elastic] is too low, increase to at least [4096]
解决办法:
$ vim /etc/security/limits.d/20-nproc.conf
es - nproc 4096
最后敲下面这行命令如果显示下面这样的json就算成功了
curl http://192.168.66.128:9200
{
"name" : "node-1",
"cluster_name" : "elk",
"cluster_uuid" : "SgN1OKlHRy6eaeMKCEHJig",
"version" : {
"number" : "6.6.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "a9861f4",
"build_date" : "2019-01-24T11:27:09.439740Z",
"build_snapshot" : false,
"lucene_version" : "7.6.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
安装head插件(安装完就可以在浏览器显示了)
git clone https://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head/
sudo npm install -g grunt-cli
sudo npm install # 这一步我报错了,安装phantomjs错误,但是无大碍。
修改Gruntfile.js:
connect: {
server: {
options: {
port: 9100,
hostname: "*", # 新增
base: '.',
keepalive: true
}
}
}
});
修改_site/app.js # 如果不好找这一行,进入vi后非编辑状态下输入/localhost就找到了
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://你的ip:9200"; # 修改为自己的服务
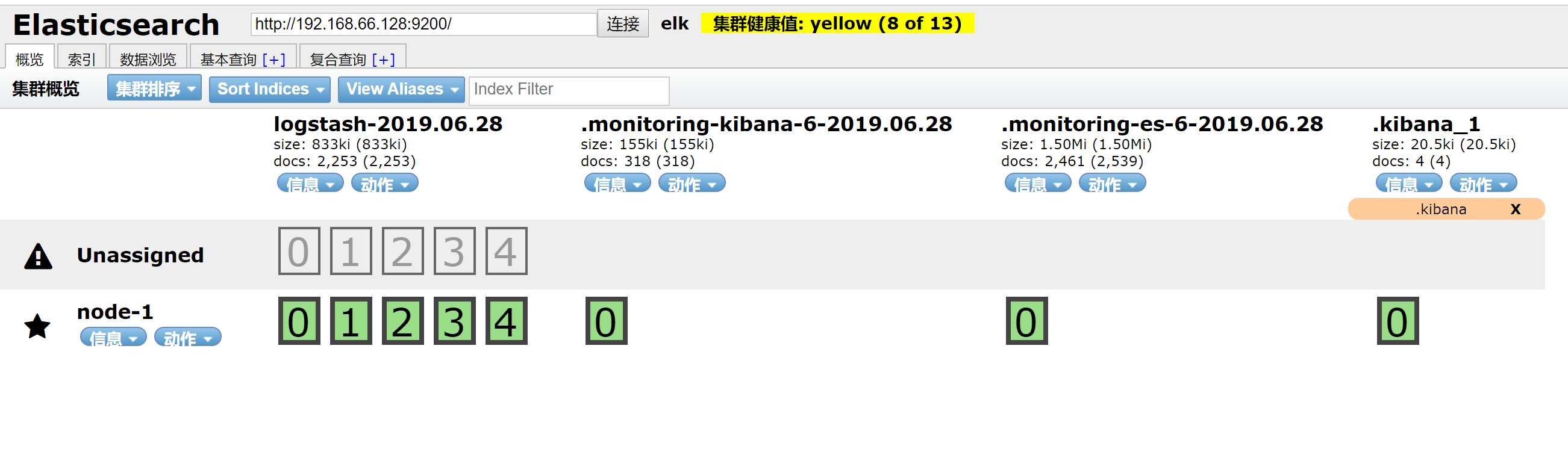
grunt server #启动命令
安装logstash
tar xvf logstash-6.6.0.tar.gz
mv logstash-6.6.0 logstash
测试logstash服务是否正常
bin/logstash -e 'input { stdin { } } output { stdout {} }'
输入hello 确定
创建配置目录和配置文件logstash/etc/nginx.conf
# 监听5044端口作为输入
input {
beats {
port => "5044"
}
}
# 数据过滤
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
geoip {
source => "clientip"
}
}
# 输出配置为本机的9200端口,这是ElasticSerach服务的监听端口
output {
elasticsearch {
hosts => ["192.168.66.128:9200"]
}
}
启动服务
nohup bin/logstash -f etc/nginx.conf --config.reload.automatic &
安装filebeat
解压文件
vim filebeat.yml
enabled: true
- /var/log/nginx/*.log
#output.elasticsearch:
# hosts: ["localhost:9200"]
output.logstash:
hosts: ["192.168.66.128:5044"]
验证:egrep -v '^$|#' filebeat.yml
启动FileBeat
nohup ./filebeat -e -c filebeat.yml &>/dev/null &
安装kibana
tar xvf kibana-6.6.0-linux-x86_64.tar.gz
mv kibana-6.6.0-linux-x86_64 kibana
vim kibana/config/kibana/yaml
server.port: 5601
server.host: "192.168.66.128"
server.name: "es"
elasticsearch.preserveHost: true
elasticsearch.username: "es"
elasticsearch.password: "es"
i18n.locale: "cn"
xpack.monitoring.ui.container.elasticsearch.enabled: "true"
启动
bin/kibana
http://192.168.66.128:5601
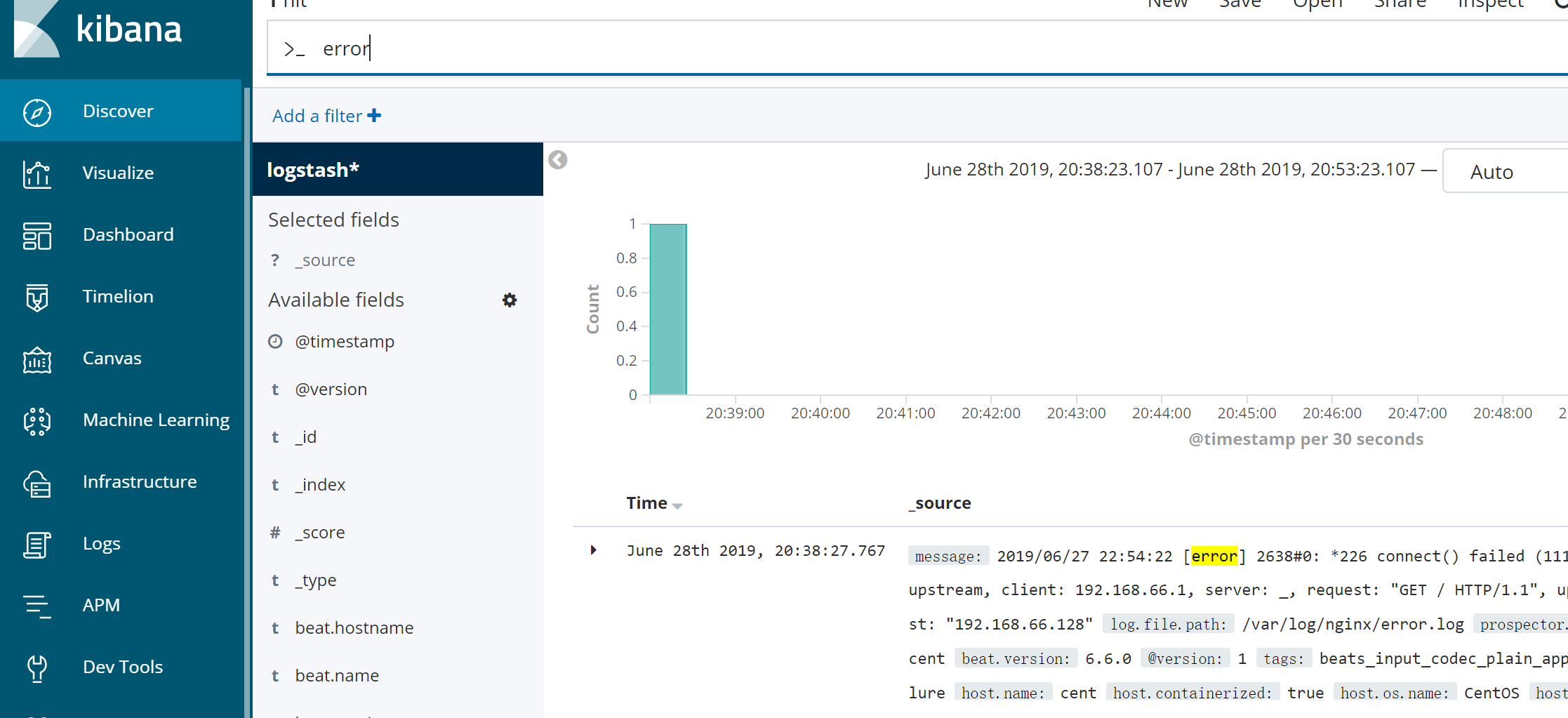
Discover->输入logstash-*,点击”Next step”->选择Time Filter,再点击“Create index pattern”->页面提示创建Index Patterns成功:
在下图的此处可以关键词搜索:error*,也可以查看nginx的报错信息
配置tomcat
filebeat.yml添加
- type: log
enabled: true
paths:
- /usr/app/tomcat8087/logs/localhost_access_log.*.txt
重启filebeat
kill -9 $(ps -ef | grep -i "filebeat" | awk '{print $2}')
nohup ./filebeat -e -c filebeat.yml &>/dev/null &
kibana搜索tomcat
linux记录-安装elk记录(参考博文)的更多相关文章
- 第一次linux下安装nginx记录
CentOS 7 安装Nginx 并配置自动启动 1.下载Nginx安装包---->地址:http://nginx.org/en/download.html 2.上传安装包到服务期 : rz 命 ...
- centos 7 安装WordPress的参考博文
安装方法: https://www.cnblogs.com/flankershen/p/7476415.html 安装完,测试不成功的解决办法: https://blog.csdn.net/u0104 ...
- 自学linux(安装系统,图形化界面,安装chrome)STEP1
1. 下载虚拟机VMware并安装 破解版: https://www.xitmi.com/2417.html 2. 下载centos7,6据说已经找不到了? 阿里云镜像: https://mirror ...
- linux下安装opcache扩展
linux下安装opcache扩展 参考:http://www.php.net/manual/zh/opcache.installation.php 1 2 3 4 5 6 7 wget http ...
- 记录Linux下安装elasticSearch时遇到的一些错误
记录Linux下安装elasticSearch时遇到的一些错误 http://blog.sina.com.cn/s/blog_c90ce4e001032f7w.html (2016-11-02 22: ...
- Linux下部署docker记录(0)-基础环境安装
以下是centos系统安装docker的操作记录 1)第一种方法:采用系统自带的docker安装,但是这一般都不是最新版的docker安装epel源[root@docker-server ~]# wg ...
- Linux mint 安装踩坑记录
记得之前电脑上的那个Ubuntu是去年寒假的时候安装的,算下来自己用Linux也快一年了.虽然在去年暑假的时候我也曾经想过要把Ubuntu升级到18.04可是当时安装了几次都没有成功,自己也就放弃了. ...
- Linux安装过程记录信息
全新的linux安装完成后,会在root目录下有一下三个文件,记录了Linux的安装细节 anaconda-ks.cfg 以Kickstart配置文件的格式记录安装过程中设置的选项信息 install ...
- 【记录】Linux环境安装mysql8.0
话说mysql8.0版本比5.7版本要快2倍以上,这么看宣传怎么能不装8.0呢,但是新版本和旧版本有不少不同导致若使用以前的一些安装方法会导致安到一半就由于各种找不到文件卡住. 尝试了不少次,只有使用 ...
随机推荐
- 评估预测函数(1)---算法不能达到我们的目的时,Deciding what to try next
在设计机器学习系统时,一些建议与指导,让我们能明白怎么选择一条最合适,最正确的道路. 当我们要开发或者要改进一个机器学习系统时,我们应该接下来做些什么? try smaller sets of fea ...
- oracle 查询月份
①:select substr(to_char(sysdate,'yyyy-mm-dd'),6,2) from dual; ②:select to_char(sysdate,'MM') from du ...
- java设计模式解析(11) Chain责任链模式
设计模式系列文章 java设计模式解析(1) Observer观察者模式 java设计模式解析(2) Proxy代理模式 java设计模式解析(3) Factory工厂模式 java设计模式解析(4) ...
- Python读取csv内容
#encoding:utf-8 import csv csv_file=csv.reader(open("d://wu.csv","r"))print(csv_ ...
- js获取当前时间往后加6天
获取当前时间往后加6天,并绑定星期几(星期几是最笨的的方法,一个一个判读),后期在优化 <!DOCTYPE html> <html lang="en"> & ...
- Coins in a Line III
Description There are n coins in a line, and value of i-th coin is values[i]. Two players take turns ...
- PHP流程控制之for循环控制语句
王同学反复往返与北京和大连,并且在本上记录往返次数.在PHP中还有另外一种实现方式能够实现同样的计数.无锡大理石测量平台 for 循环是 PHP 中的一种计数型循环,它的语法比较数活多变.这是一个必须 ...
- php大文件分块上传断点续传demo
前段时间做视频上传业务,通过网页上传视频到服务器. 视频大小 小则几十M,大则 1G+,以一般的HTTP请求发送数据的方式的话,会遇到的问题:1,文件过大,超出服务端的请求大小限制:2,请求时间过长, ...
- learning java 访问文件和目录
import java.io.File; import java.io.IOException; public class FileTest { public static void main(Str ...
- am335x system upgrade rootfs using yocto make rootfs(十二)
1 Scope of Document This document describes how to make am335x arago rootfs using ycoto project ...