新型大语言模型的预训练与后训练范式,Meta的Llama 3.1语言模型

前言:大型语言模型(LLMs)的发展历程可以说是非常长,从早期的GPT模型一路走到了今天这些复杂的、公开权重的大型语言模型。最初,LLM的训练过程只关注预训练,但后来逐步扩展到了包括预训练和后训练在内的完整流程。后训练通常涵盖监督指导微调和对齐过程,而这些在ChatGPT的推广下变得广为人知。
自ChatGPT首次发布以来,训练方法学也在不断进化。在这几期的文章中,我将回顾近1年中在预训练和后训练方法学上的最新进展。
关于LLM开发与训练流程的概览,特别关注本文中讨论的新型预训练与后训练方法
每个月都有数百篇关于LLM的新论文提出各种新技术和新方法。然而,要真正了解哪些方法在实践中效果更好,一个非常有效的方式就是看看最近最先进模型的预训练和后训练流程。幸运的是,在近1年中,已经有四个重要的新型LLM发布,并且都附带了相对详细的技术报告。
在本文中,我将重点介绍以下模型中的Meta的 Llama 3.1语言模型 预训练和后训练流程:
• 阿里巴巴的 Qwen 2
• 苹果的 智能基础语言模型
• 谷歌的 Gemma 2
• Meta AI 的 Llama 3.1
我会完整的介绍列表中的全部模型,但介绍顺序是基于它们各自的技术论文在arXiv.org上的发表日期,这也巧合地与它们的字母顺序一致。
4. Meta AI的Llama 3.1
Meta发布的Llama LLM新版本总是大事。这次发布伴随着一份92页的技术报告:《Llama 3模型群》。最后,在本节中,我们将查看上个月发布的第四份重要模型论文。
4.1 Llama 3.1概述
除了发布一个巨大的4050亿参数模型,Meta还更新了他们之前的80亿和700亿参数模型,使它们在MMLU性能上略有提升。

MMLU基准测试不同模型的表现。
虽然Llama 3像其他最近的LLM一样使用群组查询注意力,但令人惊讶的是,Meta AI拒绝使用滑动窗口注意力和混合专家方法。换句话说,Llama 3.1看起来非常传统,重点显然放在预训练和后训练上,而非架构创新。
与之前的Llama版本相似,它的权重是公开可用的。此外,Meta表示他们更新了Llama 3的许可证,现在终于可以(被允许)使用Llama 3进行合成数据生成或知识蒸馏以改善其他模型。
4.2 Llama 3.1预训练
Llama 3在庞大的15.6万亿标记数据集上进行训练,这比Llama 2的1.8万亿标记有显著增加。研究人员表示,它支持至少八种语言(而Qwen 2能处理20种语言)。
Llama 3的一个有趣方面是它的词汇量为128,000,这是使用OpenAI的tiktoken分词器开发的。(对于那些对分词器性能感兴趣的人,我在这里做了一个简单的基准比较。)
在预训练数据质量控制方面,Llama 3采用了基于启发式的过滤以及基于模型的质量过滤,利用像Meta AI的fastText和基于RoBERTa的分类器这样的快速分类器。这些分类器还有助于确定训练期间使用的数据混合的上下文类别。
Llama 3的预训练分为三个阶段。第一阶段涉及使用15.6万亿标记进行标准的初始预训练,上下文窗口为8k。第二阶段继续预训练,但将上下文长度扩展到128k。最后一个阶段涉及退火,进一步提高模型的性能。让我们更详细地看看这些阶段。
4.2.1 预训练I:标准(初始)预训练
在他们的训练设置中,他们开始使用由4096个序列长度的400万标记组成的批次。这意味着批量大小大约为1024标记,假设400万这个数字是四舍五入得到的。在处理了首批252百万标记后,他们将序列长度增加到8192。在训练过程中,处理了2.87万亿标记后,他们再次将批量大小翻倍。
此外,研究人员并没有在整个训练过程中保持数据混合不变。相反,他们调整了训练过程中使用的数据混合,以优化模型学习和性能。这种动态处理数据的方法可能有助于改善模型跨不同类型数据的泛化能力。
**4.2.2 预训练II:继续预训练以延长上下文 **
与其他一步增加其上下文窗口的模型相比,Llama 3.1的上下文延长是一个更渐进的方法:在这里,研究人员通过六个不同阶段将上下文长度从8000增加到128000标记。这种分步增加可能让模型更平滑地适应更大的上下文。
此过程使用的训练集涉及8000亿标记,约占总数据集大小的5%。
4.2.3 预训练III:在高质量数据上退火
对于第三阶段预训练,研究人员在一个小但高质量的混合上训练模型,他们发现这有助于改善基准数据集上的性能。例如,在GSM8K和MATH训练集上退火提供了在相应的GSM8K和MATH验证集上的显著提升。
在论文的3.1.3节中,研究人员表示退火数据集大小为400亿标记(总数据集大小的0.02%);这400亿退火数据集用于评估数据质量。在3.4.3节中,他们表示实际的退火只在4000万标记上进行(退火数据的0.1%)。

Llama 3.1预训练技术总结。
4.3 Llama 3.1后训练
在后训练过程中,Meta AI团队采用了一种相对简单的方法,包括监督微调(SFT)、拒绝采样和直接偏好优化(DPO)。
他们观察到,像带PPO的RLHF这样的强化学习算法与这些技术相比,稳定性较低且更难扩展。值得注意的是,SFT和DPO步骤在多轮中反复迭代,融合了人工生成和合成数据。
在描述更多细节之前,他们的工作流程如下图所示。
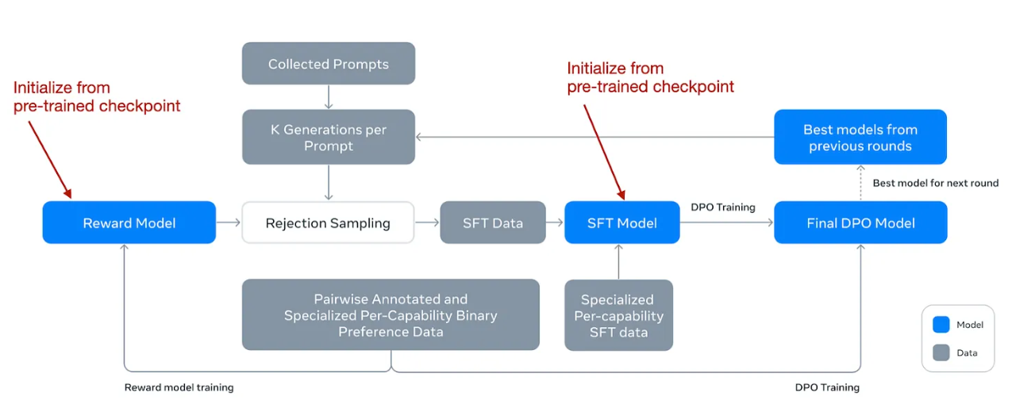
来自Llama 3.1论文的带注释的图表,描述了后训练过程。
请注意,尽管他们使用了DPO,但他们也开发了一个奖励模型,就像在RLHF中一样。起初,他们使用预训练阶段的一个检查点训练奖励模型,利用人工标注数据。这个奖励模型随后被用于拒绝采样过程,帮助选择适当的提示进行进一步训练。
在每一轮训练中,他们不仅对奖励模型,还对SFT和DPO模型应用了模型平均技术。这种平均涉及合并最近和以前模型的参数,以稳定(并改善)随时间的性能。
对于那些对模型平均的技术细节感兴趣的人,我在我早期文章《理解模型融合和权重平均》的部分中讨论了这个话题,文章标题为《模型融合、专家混合,以及向更小LLM的迈进》。
总之,核心是一个相对标准的SFT + DPO阶段。然而,这个阶段在多轮中重复。然后,他们在拒绝采样中加入了一个奖励模型(像Qwen 2和AFM那样)。他们还使用了像Gemma那样的模型平均;然而,这不仅适用于奖励模型,而是涉及所有模型。
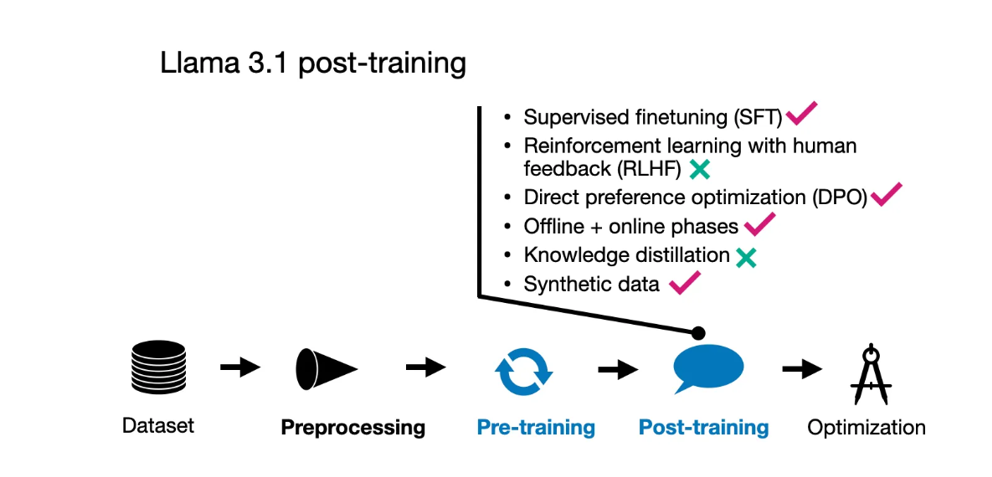
Llama 3.1后训练技术总结。
4.4 结论
Llama 3模型保持相当标准,与早期的Llama 2模型类似,但采用了一些有趣的方法。值得注意的是,庞大的15万亿标记训练集使Llama 3与其他模型区别开来。有趣的是,像苹果的AFM模型一样,Llama 3也实施了三阶段预训练过程。
与其他最近的大型语言模型不同,Llama 3没有采用知识蒸馏技术,而是选择了一条更直接的模型开发路径。在后训练中,模型使用了直接偏好优化(DPO)而不是其他模型中流行的更复杂的强化学习策略。总的来说,这种选择很有趣,因为它表明了通过简单(但经过验证的)方法精炼LLM性能的重点。
5. 主要收获
从本文讨论的这四个模型中我们可以学到什么:阿里巴巴的Qwen 2,苹果的基础模型(AFM),谷歌的Gemma 2,以及Meta的Llama 3?
这四个模型在预训练和后训练上采取了略有不同的方法。当然,方法论有所重叠,但没有哪个训练流程是完全相同的。在预训练方面,一个共有的特征似乎是所有方法都使用了多阶段预训练流程,其中一般的核心预训练之后是上下文延长,有时还有高质量的退火步骤。下面的图表再次一览无余地显示了预训练中使用的不同方法。

预训练所用技术概述
在后训练方面,也没有哪个流程是完全相同的。看来拒绝采样现在已经成为后训练过程中的常见要素。然而,当谈到DPO或RLHF时,还没有共识或偏好(无意中的双关语)。

后训练所用技术概述
因此,总的来说,没有单一的配方,而是有许多路径可以开发出高性能的LLM。
最后,这四个模型的表现大致相当。不幸的是,其中几个模型还没有进入LMSYS和AlpacaEval排行榜,所以我们还没有直接的比较,除了在MMLU和其他多项选择基准上的得分。
新型大语言模型的预训练与后训练范式,Meta的Llama 3.1语言模型的更多相关文章
- css预处理器和后处理器
因为我是前端刚入门,昨天看了一个大神写的的初级前端需要掌握的知识,然后我就开始一一搜索,下面是我对css预处理器和后处理器的搜索结果,一是和大家分享下这方面的知识,另一方面方便自己以后翻阅.所以感兴趣 ...
- 产品在焊接时出现异常,尤其是尺寸较大的QFP芯片,焊接后出现虚焊、冷焊、假焊等问题?
1 不良描述 客户采用我们提供的SMT设备后,部分产品在焊接时出现异常,尤其是尺寸较大的QFP芯片,焊接后出现虚焊.冷焊.假焊等不良.应客户要求对这一批不良产品以及生产条件进行分析,以便找到改善的依据 ...
- SVM训练结果参数说明 训练参数说明 归一化加快速度和提升准确率 归一化还原
原文:http://blog.sina.com.cn/s/blog_57a1cae80101bit5.html 举例说明 svmtrain -s 0 -?c 1000 -t 1 -g 1 -r 1 - ...
- 如何解决 Iterative 半监督训练 在 ASR 训练中难以落地的问题丨RTC Dev Meetup
前言 「语音处理」是实时互动领域中非常重要的一个场景,在声网发起的「RTC Dev Meetup丨语音处理在实时互动领域的技术实践和应用」活动中,来自微软亚洲研究院.声网.数美科技的技术专家,围绕该话 ...
- 迁移学习算法之TrAdaBoost ——本质上是在用不同分布的训练数据,训练出一个分类器
迁移学习算法之TrAdaBoost from: https://blog.csdn.net/Augster/article/details/53039489 TradaBoost算法由来已久,具体算法 ...
- Expo大作战(十九)--expo打包后,发布分用程序到商店的注意事项
简要:本系列文章讲会对expo进行全面的介绍,本人从2017年6月份接触expo以来,对expo的研究断断续续,一路走来将近10个月,废话不多说,接下来你看到内容,讲全部来与官网 我猜去全部机翻+个人 ...
- 【服务总线 Azure Service Bus】Service Bus在使用预提取(prefetching)后出现Microsoft.Azure.ServiceBus.MessageLockLostException异常问题
问题描述 Service Bus接收端的日志中出现大量的MessageLockLostException异常.完整的错误消息为: Microsoft.Azure.ServiceBus.MessageL ...
- ML2021 | (腾讯)PatrickStar:通过基于块的内存管理实现预训练模型的并行训练
前言 目前比较常见的并行训练是数据并行,这是基于模型能够在一个GPU上存储的前提,而当这个前提无法满足时,则需要将模型放在多个GPU上.现有的一些模型并行方案仍存在许多问题,本文提出了一种名为 ...
- 从大公司做.NET 开发跳槽后来到小公司的做.NET移动端微信开发的个人感慨
从14年11月的实习到正式的工作的工作我在上一家公司工作一年多了.然而到16年5月20跳槽后自己已经好久都没有在写博客了,在加上回学校毕业答辩3天以及拿档案中途耽搁了几天的时间,跳槽后虽然每天都在不停 ...
- GIS大数据存储预研
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1. 背景 在实际项目运行中,时常会出现希望搜索周边所有数据的需求.但是 ...
随机推荐
- SQL Server – 我常用语句
前言 旧没用又忘记了, 又没有 intellisense, 记入这里吧. Reset Auto Increment DBCC CHECKIDENT ('TableName'); -- check cu ...
- 2024.7.5-2024.7.20 HA省学会集训游记(焦作一中)
这是一篇长篇小说 DAY1 除了DAY4-DAY5个别内容以外,这些都是补的,但是全写完有太多了qwq,挑题写了 树状数组和线段树基础 很多都是一些模板题,太模板的题不再做太多解释 题目: P4062 ...
- Python — 循环语句
while循环语句 语法: 嵌套使用: for循环语句:(for循环外部不允许访问临时变量) 语法: 使用: 待处理的数据集: range语句: 嵌套for循环: continue: break: 随 ...
- HarmonyOS NEXT 底部选项卡功能
在HarmonyOS NEXT中使用ArkTS实现一个完整的底部选项卡功能,可以通过以下几个步骤来完成: 创建Tabs组件:使用Tabs组件来创建底部导航栏,并通过barPosition属性设置其位置 ...
- 一篇文章彻底讲懂malloc的实现(ptmalloc)
一.前言 C语言提供了动态内存管理功能, 在C语言中, 程序员可以使用 malloc() 和 free() 函数显式的分配和释放内存. 关于 malloc() 和free() 函数, C语言标准只是规 ...
- 开源项目更新|WPF/Uno Platform/WinUI 3三个版本的《英雄联盟客户端》
哈喽大家好! 我们是中韩Microsoft MVP夫妇 Vicky&James^^很高兴能加入博客园和大家分享我们的技术! 自2008年以来,我们一直深耕于WPF技术,积累了丰富的经验.这 ...
- C#/.NET/.NET Core优秀项目和框架2024年9月简报
前言 公众号每月定期推广和分享的C#/.NET/.NET Core优秀项目和框架(每周至少会推荐两个优秀的项目和框架当然节假日除外),公众号推文中有项目和框架的介绍.功能特点.使用方式以及部分功能截图 ...
- 1. react项目【前端】+C#【后端】从0到1
1.创建前端基础框架 1.1 前端创建 软件: 1.1.1 npx create-react-app pc ps:pc 是文件名 : 1.1.2 npm start 启动项目 2.创建后端基础框架 软 ...
- 什么是数据库连接池druid
每次数据库连接都要断开重连浪费时间,性能 [ 底层需要 tcp 连接 ] 资源复用 : 提升系统响应速度 : 避免数据库连接遗漏 :[ 长时间不操作会强制断开 ] 使用: 初始连接数:连接的个数 pa ...
- 更改后端的数据格式适配el-tree组织树
.markdown-body { line-height: 1.75; font-weight: 400; font-size: 16px; overflow-x: hidden; color: rg ...