SciTech-EECS-BigDataAIML-NN(神经网络): 常用的18种Activation(激活函数)
SciTech-EECS-BigDataAIML-NN(神经网络):
常用的18种Activation(激活函数)
- 简介
- 为什么要用激活函数
- 激活函数的分类
- 常见的几种激活函数
4.0.Softmax函数
4.1.Sigmoid函数
4.2.Tanh函数
4.3.ReLU函数
4.4.Leaky Relu函数
4.5.PRelu函数
4.6.ELU函数
4.7.SELU函数
4.8.Swish函数
4.9.Mish函数
一:简介
激活函数(Activation Function),就是在人工神经网络的神经元上运行的函数,将神经元的输入映射到输出端,目标帮助网络学习数据的复杂模式。
下图展示了一个神经元是 如何 输入激活函数 以及 如何得到该神经元最终的输出:
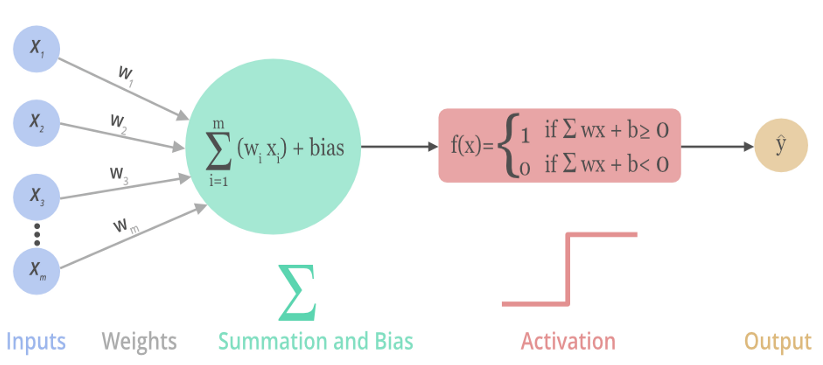
二:为什么要用激活函数
如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,就是最原始的感知机(Perceptron)。
使用激活函数 能够给神经元引入 非线性因素,使神经网络可以任意逼*任何非线性函数,使深层神经网络表达能力更加强大,于是神经网络就可以应用到众多的非线性模型。
三:激活函数的分类
激活函数可以分为两大类:
- 饱和激活函数: sigmoid、 tanh...
- 非饱和激活函数: ReLU 、Leaky Relu 、ELU、PReLU、RReLU...
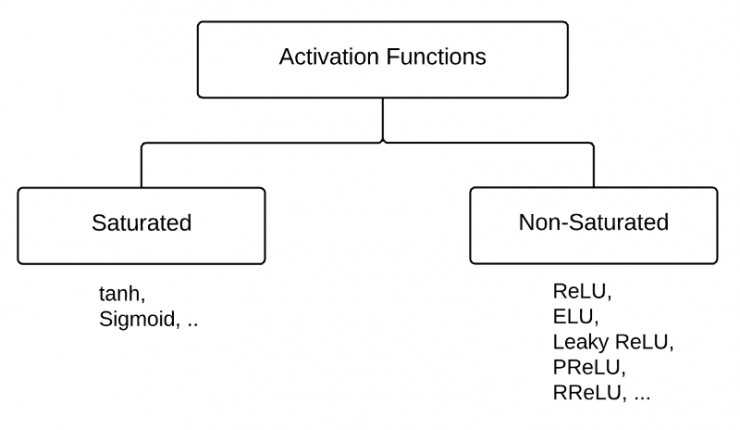
首先,我们先了解一下什么是饱和?

反之,不满足以上条件的函数则称为非饱和激活函数。
- Sigmoid函数需要一个实值输入,压缩至[0,1]的范围
- tanh函数需要讲一个实值输入,压缩至 [-1, 1]的范围
相对于饱和激活函数,使用非饱和激活函数的优势在于两点:
- 非饱和激活函数能解决深度神经网络(层数非常多)带来的梯度消失问题
- 使用非饱和激活函数能加快收敛速度。
四:常见的几种激活函数
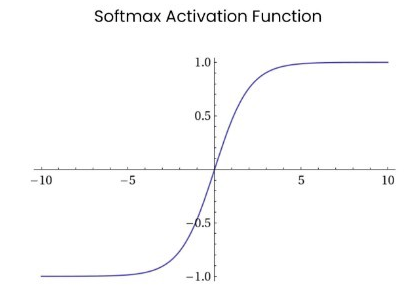
4.0.Softmax函数
- Softmax激活函数的数学表达式为:
![]()
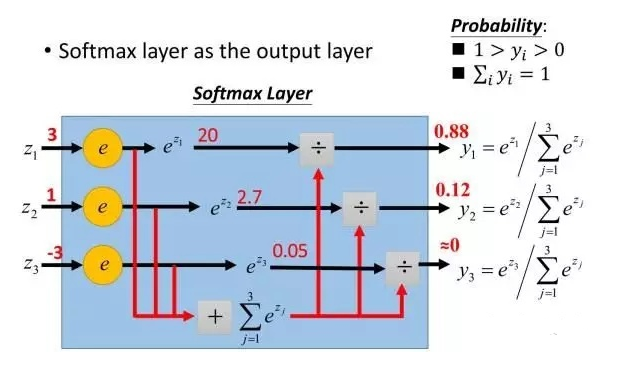
下图给出 Softmax 对 输出值 的 映射:
![]()
- 函数图像如下:
![]()
- Softmax函数常用作“输出层”当激活函数, 将输出层的值映射到0-1区间,
将神经元输出 构造成概率分布,用于多分类问题,
Softmax激活函数映射值越大,则真实类别可能性越大.
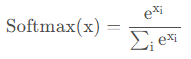
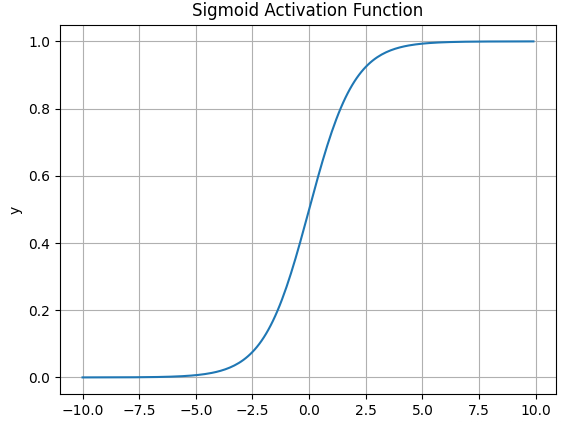
4.1.Sigmoid函数
Sigmoid激活函数的数学表达式为:
\(\large f(x) = \dfrac{1}{1+e^{-x}}\)导数表达式为:
\(\large f^{'}(x) = f(x)(1-f(x))\)函数图像如下:
![]()
Sigmoid 函数在历史上曾非常常用,输出值范围为[0,1]之间的实数。
但是现在它已经实际很少使用。什么情况下适合使用Sigmoid?
- Sigmoid 函数的输出范围是 0 到 1。非常适合作为模型的输出函数用于输出一个0~1范围内的概率值,比如用于表示二分类的类别或者用于表示置信度。
- 梯度*滑,便于求导,也防止模型训练过程出现突变的梯度.
Sigmoid有哪些缺点?
- 容易造成梯度消失。我们由其导函数图像了解到,
sigmoid的导数都是小于0.25的,那么在进行反向传播时,
梯度相乘 结果会步步趋于0,少有梯度信号 通过 神经元 传到 前面层的梯度更新,
因此这时 前面层的权值 几乎没有更新,这就叫梯度消失。 - 此外,为防止饱和,必须对于权重矩阵的初始化特别留意。
如果初始化权重过大,可能很多神经元得到一个比较小的梯度,
致使神经元不能很好的更新权重提前饱和,神经网络就学习不了。 - 函数输出 如果不是以 0 为中心的,梯度可能会向特定方向移动,导致降低权重更新的效率。
- Sigmoid 函数 执行 指数运算,会用到大量计算资源。
- 容易造成梯度消失。我们由其导函数图像了解到,
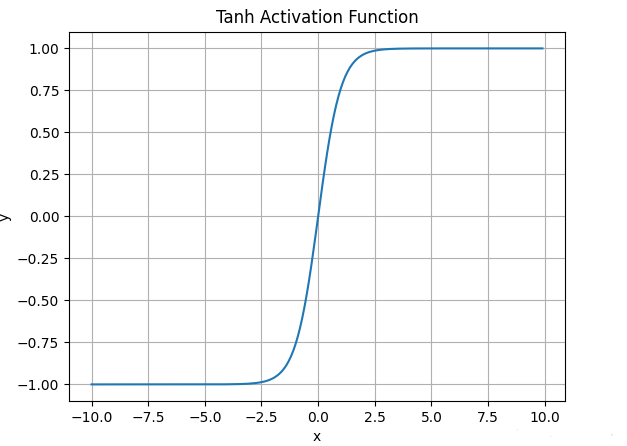
4.2.Tanh函数
tanh激活函数的数学表达式为:
\(\large f(x) = \dfrac{e^{x} - e^{-x}}{e^{-x} + e^{-x}}\)
实际上,Tanh函数是 sigmoid 的变形:\(\large tanh(x) = 2Sigmoid(2x) - 1\)函数图像如下:
![]()
与sigmoid不同的是, tanh是“零为中心”的。
因此在实际应用,tanh会比sigmoid更好一些。
但是在饱和神经元的情况下,tanh还是没有解决梯度消失问题。什么情况下适合使用Tanh?
- tanh 的输出间隔为 1,并且整个函数以 0 为中心,比 sigmoid 函数更好;
- 在 tanh 图,负输入将被强映射为负,而零输入被映射为接*零。
Tanh有哪些缺点?
- 仍然存在梯度饱和的问题
- 依然进行的是指数运算
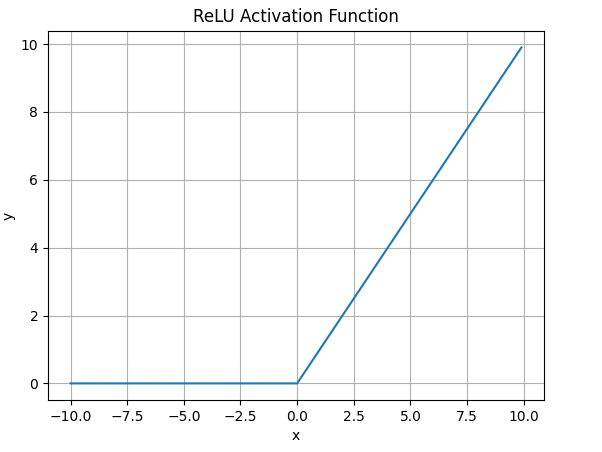
4.3.ReLU函数
ReLU激活函数的数学表达式为:
\(\large ReLU(x) = max(0,x)\)ReLU函数图像如下
![]()
什么情况下适合使用ReLU?
- ReLU解决了梯度消失的问题: 当输入值为正时,神经元不会饱和;
- ReLU线性、非饱和的性质,在SGD能够快速收敛
- 计算复杂度低,不需要进行指数运算
ReLU有哪些缺点?
- 与Sigmoid一样,其输出不是以0为中心的
- Dead ReLU 问题。当输入为负时,梯度为0。
这个神经元及之后的神经元的梯度永远为0, 将不响应任何数据,导致相应参数永远不会被更新。训练神经网络时,一旦学习率没有设置好,第一次更新权重时, 输入是负值, 那么这个含有ReLU的神经节点就会死亡,不会被激活。
所以,要设置一个合适的较小的学习率,来降低这种情况的发生.
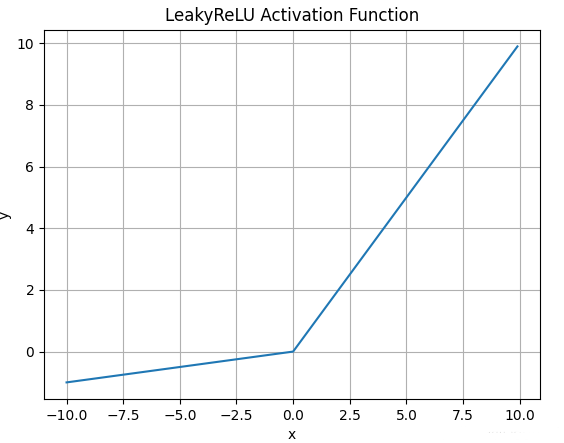
4.4.Leaky Relu函数
- Leaky Relu激活函数的数学表达式为:
\(\large LeakyReLU(x) = max(\alpha x,x)\) - 函数图像如下:
![]()
- 什么情况下适合使用Leaky ReLU?
- 解决ReLU输入值为负时神经元死亡的问题
- Leaky ReLU线性、非饱和的性质,在SGD中能够快速收敛
- 计算复杂度低,不需要进行指数运算
- Leaky ReLU有哪些缺点?
函数中的α,需要通过先验知识人工赋值(一般设为0.01)- 有些*似线性,导致在复杂分类时效果不好。
- 注意:理论上, Leaky ReLU 有 ReLU 的所有优点,
而且 Dead ReLU 不会有任何问题,
但实际上, 尚未完全证明 Leaky ReLU 总比 ReLU 更好.
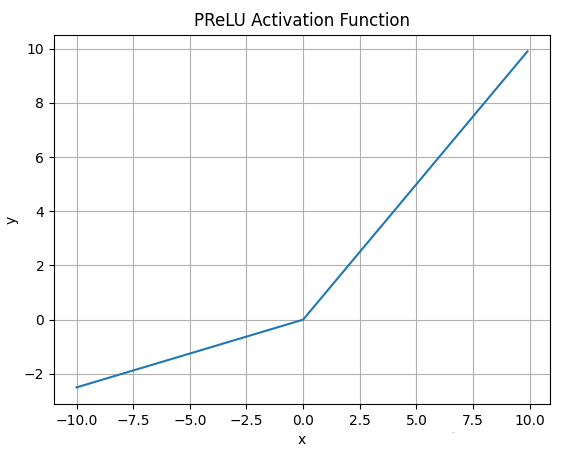
4.5.PRelu函数
PRelu激活函数的数学表达式为:
\(\large PReLU(\alpha, x) = \begin{cases} \alpha x,\ for \ x < 0 \\ x,\ for \ x >= 0 \end{cases}\)函数图像如下:
![]()
PRelu也是解决ReLU的神经元坏死问题.
与Leaky ReLU不同: PRelu负半轴的斜率参数α 是学习得到的,而不是人工设置的恒定值.
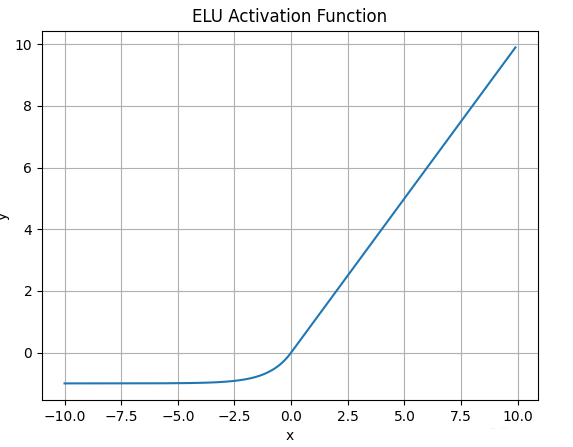
4.6.ELU函数
- ELU激活函数的数学表达式为:
\(\large ELU(\alpha, x) = \begin{cases} \alpha (e^x - 1),\ for \ x <= 0 \\ x,\ for \ x > 0 \end{cases}\) - 函数图像如下:
![]()
- 与Leaky ReLU和PRelu不同的是,ELU的负半轴是一指数函数, 而不是一条直线.
- 什么情况下适合使用ELU?
- ELU试图将输出均值接*于零, 使正常梯度更接*于单位自然梯度,加快学习速度.
- ELU 在较小输入下饱和至负值, 会减少前向传播的变异和信息
- ELU有哪些缺点?
计算的时需要计算指数,计算资源用的多。
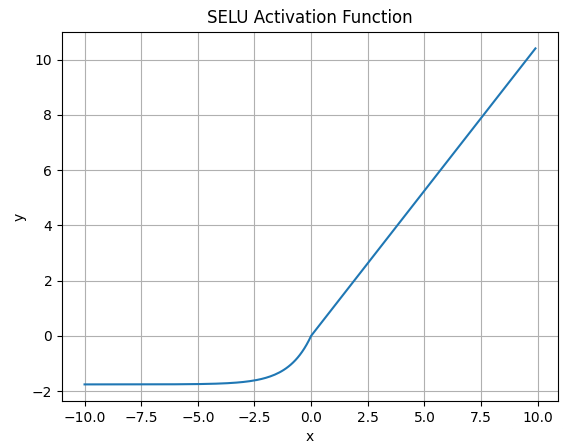
4.7.SELU函数
SELU激活函数的数学表达式为:
\(\large SELU(\alpha, x) = \lambda \begin{cases} \alpha (e^x - 1),\ for \ x <= 0 \\ x,\ for \ x > 0 \end{cases}\)
其中λ = 1.0507 , α = 1.6733函数图像如下:
![]()
SELU 允许构建一个映射 g,其性质能够实现 SNN(自归一化神经网络)。SNN 不能通过ReLU、sigmoid 、tanh 和 Leaky ReLU 实现。这个激活函数需要有:
- 负值和正值,以便控制均值;
- 饱和区域(导数趋*于零),以便抑制更低层的较大方差;
- 大于 1 的斜率,以便在更低层中的方差过小时增大方差;
- 连续曲线。后者能确保一个固定点,其中方差抑制可通过方差增大来获得均衡。
通过乘上指数线性单元(ELU)来满足激活函数的这些性质,
而且 λ>1 能够确保正值净输入的斜率大于 1
SELU是在自归一化网络定义的,通过调整均值和方差来实现内部的归一化。
这种内部归一化比外部归一化更快,这使得网络能够更快得收敛
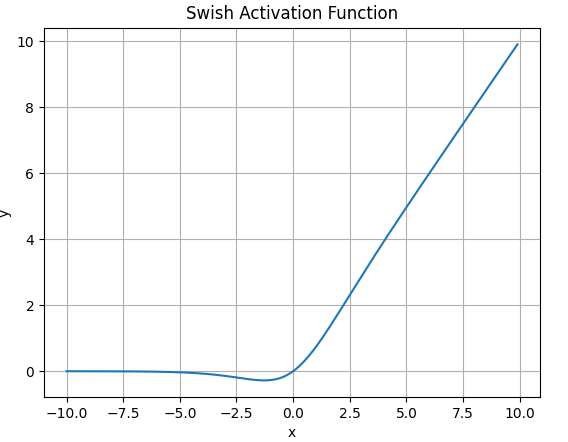
4.8.Swish函数
- Swish激活函数的数学表达式为:
\(\large Swish(x) = x * Sigmoid(x)\) - 函数图像如下:
![]()
- Swish无界性有助于防止慢训练期间, 梯度渐* 0 并导致饱和;
同时, 有界性也是有优势的, 因为有界激活函数可有很强的正则化(防止过拟合, 进而增强泛化能力), 并且较大的负输入问题也能解决. - Swish在x=0 附*更为*滑而非单调的特性, 增强了输入数据和要学习的权重的表达能力。
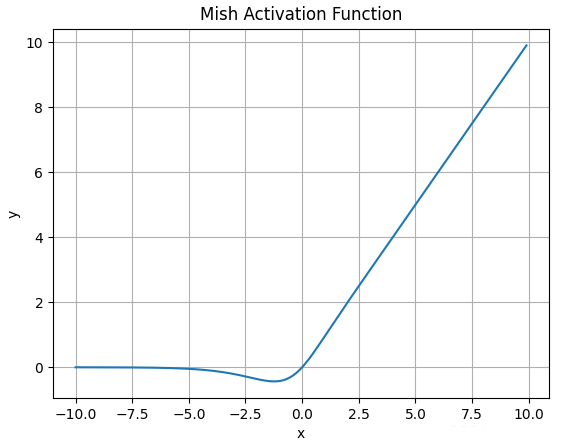
4.9.Mish函数
Mish激活函数的数学表达式为:
\(\large Mish(x) = x * tanh( ln(1+e^x))\)函数图像如下:
![]()
Mish的图像与Swish类似, 但要更为*滑,缺点是计算复杂度要更高一些
SciTech-EECS-BigDataAIML-NN(神经网络): 常用的18种Activation(激活函数)的更多相关文章
- Pytorch_第六篇_深度学习 (DeepLearning) 基础 [2]---神经网络常用的损失函数
深度学习 (DeepLearning) 基础 [2]---神经网络常用的损失函数 Introduce 在上一篇"深度学习 (DeepLearning) 基础 [1]---监督学习和无监督学习 ...
- Python实现NN(神经网络)
Python实现NN(神经网络) 参考自Github开源代码:https://github.com/dennybritz/nn-from-scratch 运行环境 Pyhton3 numpy(科学计算 ...
- cs231n神经网络 常用激活函数
CS231n课程笔记翻译:神经网络笔记1(上) 一.常用激活函数 每个激活函数(或非线性函数)的输入都是一个数字,然后对其进行某种固定的数学操作.下面是在实践中可能遇到的几种激活函数: ——————— ...
- 18种CSS3loading效果完整版,兼容各大主流浏览器,提供在线小工具使用
今天把之前分享的两篇博客<CSS3实现10种Loading效果>和 <CSS3实现8种Loading效果[二]>整理了一下.因为之前所分享的各种loading效果都只是做了we ...
- 【转载】Python编程中常用的12种基础知识总结
Python编程中常用的12种基础知识总结:正则表达式替换,遍历目录方法,列表按列排序.去重,字典排序,字典.列表.字符串互转,时间对象操作,命令行参数解析(getopt),print 格式化输出,进 ...
- Python编程中常用的12种基础知识总结
原地址:http://blog.jobbole.com/48541/ Python编程中常用的12种基础知识总结:正则表达式替换,遍历目录方法,列表按列排序.去重,字典排序,字典.列表.字符串互转,时 ...
- java常用的几种线程池比较
1. 为什么使用线程池 诸如 Web 服务器.数据库服务器.文件服务器或邮件服务器之类的许多服务器应用程序都面向处理来自某些远程来源的大量短小的任务.请求以某种方式到达服务器,这种方式可能是通过网络协 ...
- 18种CSS3loading效果完整版
今天把之前分享的两篇博客<CSS3实现10种Loading效果>和 <CSS3实现8种Loading效果[二]>整理了一下.因为之前所分享的各种loading效果都只是做了we ...
- Java常用的几种线程池
常用的几种线程池 5.1 newCachedThreadPool 创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程. 这种类型的线程池特点是: 工作线程的创 ...
- 浅谈MySQL中优化sql语句查询常用的30种方法 - 转载
浅谈MySQL中优化sql语句查询常用的30种方法 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中使 ...
随机推荐
- EF core番外——EF core 输出生成的SQL 到控制台
----------------版权声明:本文为CSDN博主「爱睡觉的程序员」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明.原文链接:https://blog.cs ...
- java中的虚函数
一.Java中的虚函数 普通函数就是虚函数(同等于C语言中virtual关键词修饰的方法) 虚函数的存在是为了多态 C++中普通成员函数加上virtual关键字就成为虚函数 Java中其实没有虚函数的 ...
- JTextField限制输入数据类型(java GUI)
package javaBasic; import java.awt.*; import java.awt.event.*; import javax.swing.*; public class Co ...
- 读书笔记:深度工作(deep work)
读书笔记:深度工作(deep work) 目录 读书笔记:深度工作(deep work) 第一部分:The Idea 第二部分:The Rules 准则一:工作要深入 准则二:拥抱无聊 准则三:远离社 ...
- Linux环境使用apt-get安装telnet、curl、ifconfig、vim、ping等工具【转】
当在Linux服务器执行Telnet命令时,如果提示command not found: telnet,说明服务器上并未安装Telnet命令,需要安装此命令.下面介绍在linux服务器如何安装te ...
- 【译】Visual Studio 扩展管理器更新
Visual Studio 2022 的最新更新引入了专门的设计用于改进扩展管理方式的功能.这些更新提供的工具可以帮助您自动化过程,为配置提供详细的控制,并增强用户界面以简化您的开发工作流程. 无缝自 ...
- Go中的map和指针
本文参考:https://www.liwenzhou.com/posts/Go/08_map/ MAP(映射) Go语言中提供的映射关系容器为map,其内部使用散列表(hash)实现.(类似于Pyth ...
- Springboot笔记<8>异常处理 文件上传
文件上传 springboot可以直接使用 org.springframework.web.multipart.MultipartFile实现文件上传功能. 1.创建form表单: <!DOCT ...
- Opencv学习:使用Opencv对图象进行抠图和滤镜处理,实现“你的名字”动漫图片效果
最近接到了一个坑爹题目,是这么要求的: 仿照 <你的名字>,对天坛图像.src.jpg进行处理.要求 (一)背景(天空)分割,替换后再融合 在自然界的图片中,很难出现动漫中大多大多的云彩. ...
- 袋鼠云数据湖平台「DataLake」,存储全量数据,打造数字底座
一.什么是数据湖? 在探讨数据湖技术或如何构建数据湖之前,我们需要先明确,什么是数据湖? 数据湖的起源,应该追溯到2010年10月.基于对半结构化.非结构化存储的需求,同时为了推广自家的Pentaho ...