BigdataAIML-Important Data Features preprocessing points非常重要的数据维度预处理方面
https://developer.ibm.com/tutorials/awb-k-means-clustering-in-python/
PCA: 对2D数据非常好理解,但是对tensor(3D以上维度),假设维度为N,
可以理解为 求一个 方阵, 每一条N维列向量的数据乘以这个方阵(即进行多维坐标轴旋转),
得到的是降维变换(小于等于N维空间的)后的向量;
算法会有一些前提条件与假设,而通过数据预处理,
不仅可以保障与满足这些,同时能提高模型的有效计算速度。
“不空”、“不漏”、“不乱”、“不限”、“不差”、“不异”:
- Dedkind Split
- 不限、不差、不异
例如:- 大多数算法假设数据是完整而有效的。
- Naive-Bayes算法假设数据维度之间的correlationship是非常小的。
- K-Means算法要估计最佳的Number of Cluster簇数。
Preprocessing
Ensure that the columns were imported with the correct data types.
$ print(df.dtypes)
distance_center float64
num_rooms float64
property_size float64
age float64
utility_cost float64
label int64
dtype: objectCheck for missing values.
Consider imputation or removing missing values if there are many.
$ df.isnull().sum()
distance_center 0
num_rooms 0
property_size 0
age 0
utility_cost 0
label 0
dtype: int64Check for outliers.
Consider removing outliers If appropriate, so that the final cluster shapes are not skewed.Standardize scales first using scikit-learn;
Identify correlated features using mathematics(Measure of correlationship);
Consider using a pairwise plot to identify strong correlations and remove features that are highly correlated.
![]()
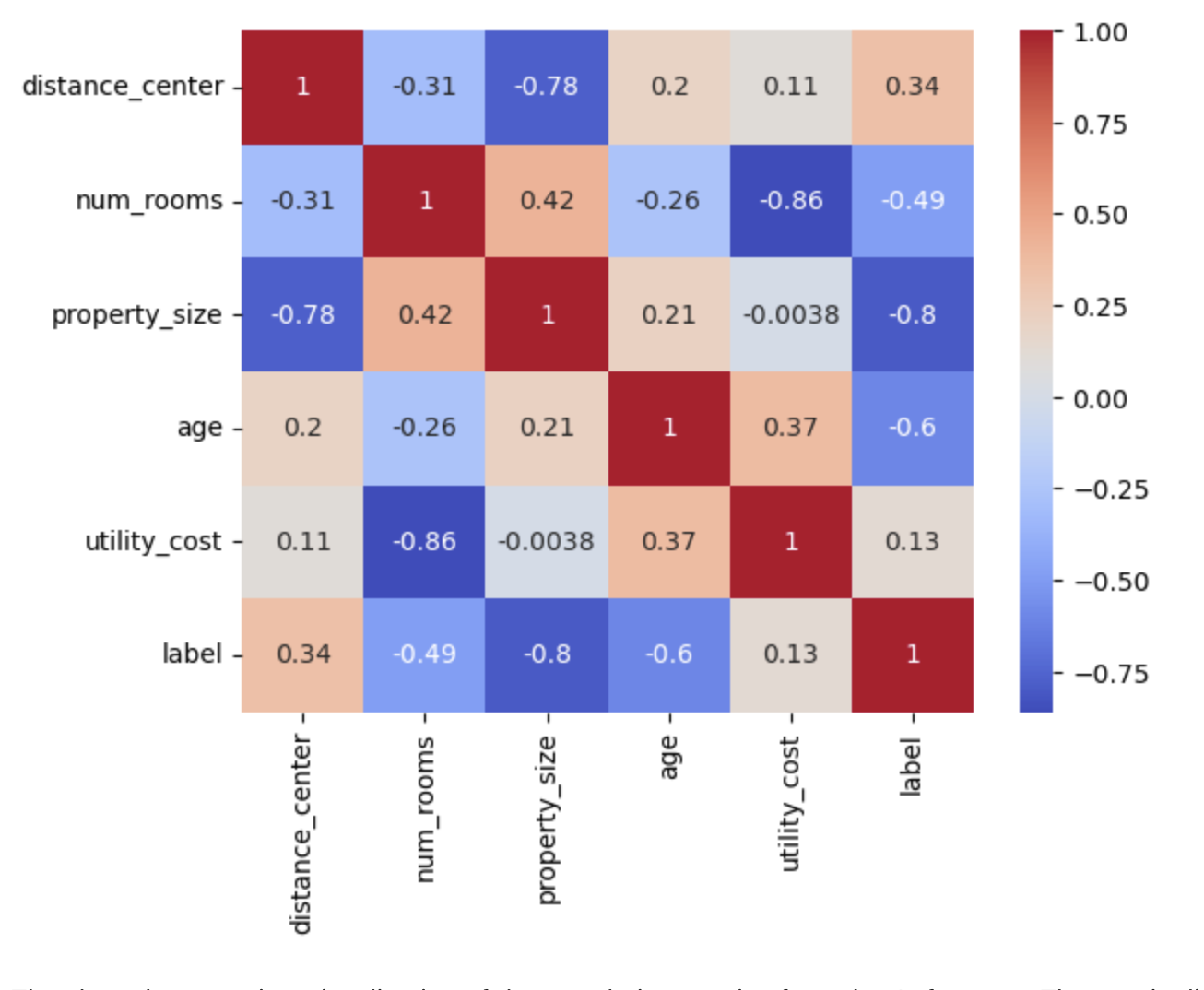
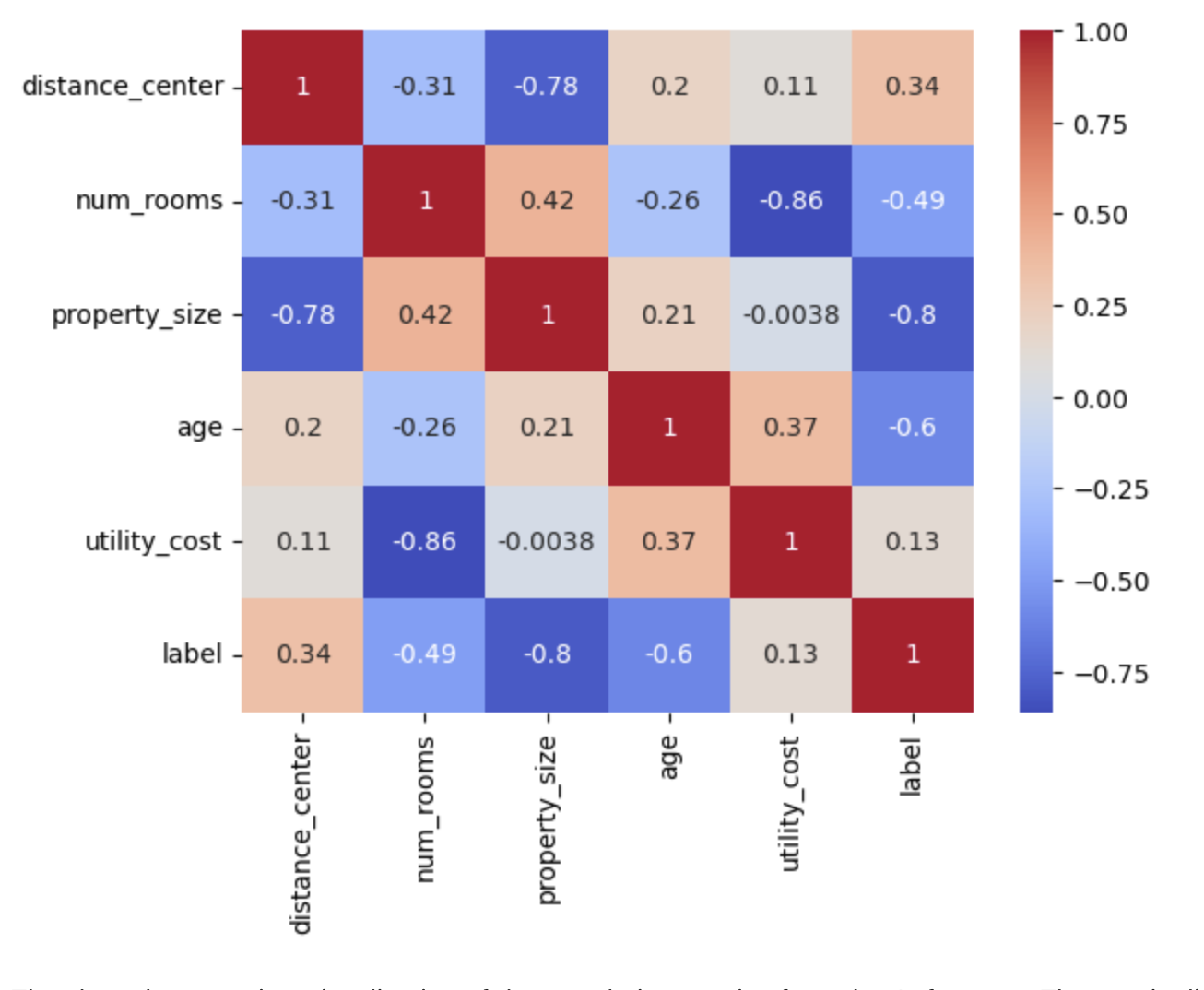{kind=link}
EDA(Exploratory Data Analysis)
These are the steps you will follow:
- Create a AI project and open a Jupyter Notebook.
- Generate a data set and do preprocess.
- Perform EDA (exploratory data analysis).
- Choose K clusters using WCSS.
- Interpret K-means clustering.
Example: Choose best K for K-Means model
When EDA is complete, you must choose how many clusters to separate your data into.
- set K manually in scikit-learn If you already know how many groups you want to make.
- use the elbow method to test different K values, If you are not sure how many groups are appropriate,
- The elbow method works by computing the Within Cluster Sum of Squares (WCSS), quantifies the variance (or spread) of data within a cluster.
- If WCSS decreases, the data within the clusters are more similar.
- As K increases, there should be a natural decrease in WCSS because the distance between the data in its cluster to its center will be smaller.
- The ideal K is the "elbow" point of the graph, where WCSS stops decreasing or starts to marginally decrease as K increases.
- The elbow method is particularly useful for big data sets that have lots of potential clusters because there is a trade-off between computational power required to run the algorithm and the number of clusters generated.
Use the following steps to implement the elbow method.
- Create an empty list to hold WCSS values at different K values.
- Fit the clusters with different K values.
- At each K value, append the WCSS value to the list.
- Graph the WCSS values versus the number of clusters.
Use the elbow method to find a good number of clusters using WCSS (within-cluster sums of squares)
wcss = []
Let's check for up to 10 clusters
for i in range(1, 11):
kmeans = KMeans(n_clusters=i, init='k-means++', max_iter=300, n_init=10, random_state=42)
kmeans.fit(df)
wcss.append(kmeans.inertia_)
plt.plot(range(1, 11), wcss)
plt.title('Elbow Method')
plt.xlabel('Number of clusters')
plt.ylabel('WCSS')
plt.show()
Select the "elbow point" of the graph as your K value.
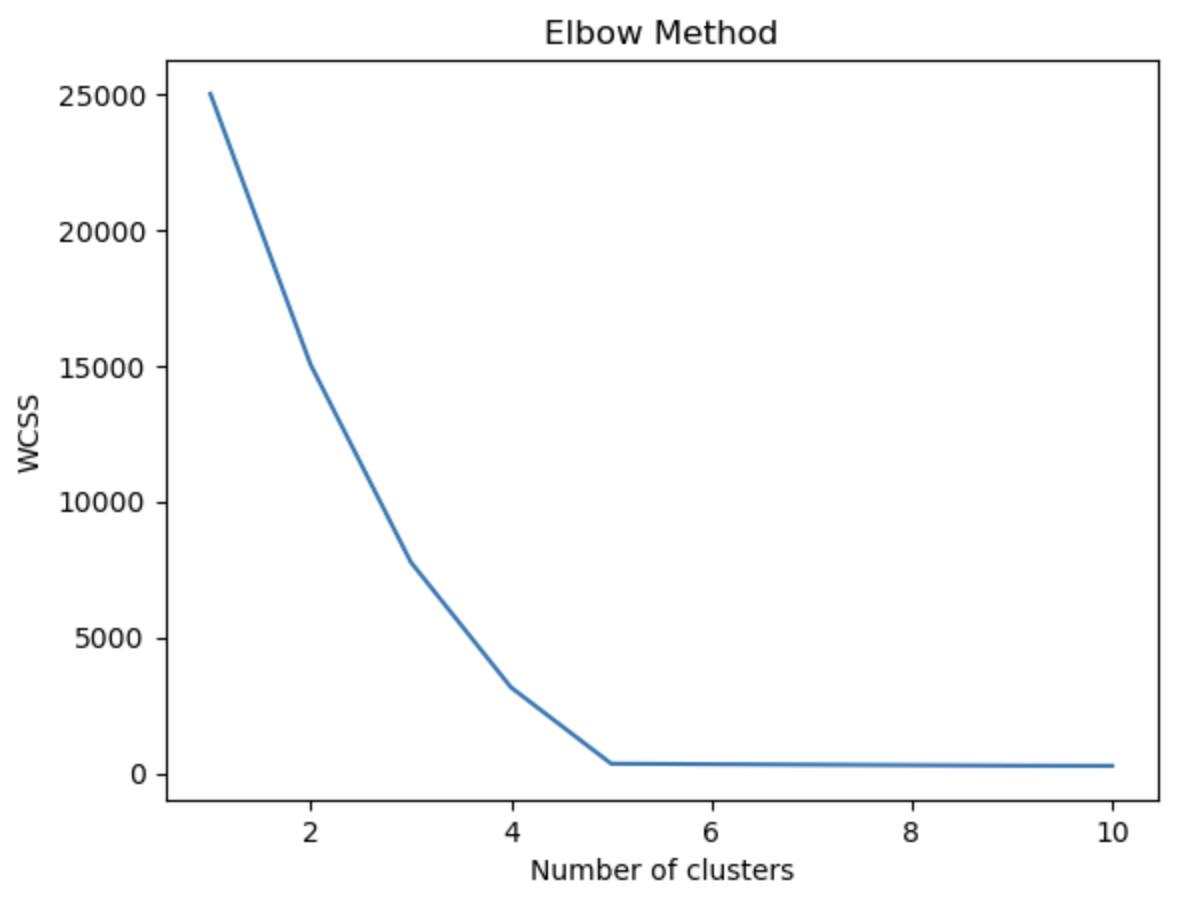
Elbow method graph
Rerun K-means with your chosen K value. Use the n_clusters parameter to set the K value.
Be sure to set the random_state parameter for reproducibility.
The graph indicates that 5 is the ideal number of clusters, which makes sense because we set the make-blobs number of centers parameter equal to 5.
Ideal number of clusters

Step 5. Interpret K-means clustering
**Using PCA(Principal Component Analysis) and similar dimensionality reduction technique
so you can graph your clusters in a two-dimensional space and visualize the groupings.
This tutorial does not cover the exact details of PCA,
but our data has five dimensions, and thus dimensionality reduction is needed to visualize clusters of data with more than two dimensions in a 2-D space.
It's likely that most data sets that you encounter when performing K-means clustering have data with more than two dimensions.
The following steps are the high-level steps to interpret K-means clustering.
BigdataAIML-Important Data Features preprocessing points非常重要的数据维度预处理方面的更多相关文章
- Spring Data:企业级Java的现代数据访问技术(影印版)
<Spring Data:企业级Java的现代数据访问技术(影印版)>基本信息原书名:Spring Data:Modern Data Access for Enterprise Java作 ...
- 17.1.1.8?Setting Up Replication with Existing Data设置复制使用存在的数据
17.1.1.8?Setting Up Replication with Existing Data设置复制使用存在的数据 当设置复制使用存在的数据,你需要确定如何最好的从master 得到数据到sl ...
- 【转】Jmeter中使用CSV Data Set Config参数化不重复数据执行N遍
Jmeter中使用CSV Data Set Config参数化不重复数据执行N遍 要求: 今天要测试上千条数据,且每条数据要求执行多次,(模拟多用户多次抽奖) 1.用户id有175个,且没有任何排序规 ...
- Jmeter===Jmeter中使用CSV Data Set Config参数化不重复数据执行N遍(转)
Jmeter中使用CSV Data Set Config参数化不重复数据执行N遍 要求: 今天要测试上千条数据,且每条数据要求执行多次,(模拟多用户多次抽奖) 1.用户id有175个,且没有任何排序规 ...
- Azure Data Factory(二)复制数据
一,引言 上一篇主要只讲了Azure Data Factory的一些主要概念,今天开始新的内容,我们开始通过Azure DevOps 或者 git 管理 Azure Data Factory 中的源代 ...
- 使用Spring Data ElasticSearch+Jsoup操作集群数据存储
使用Spring Data ElasticSearch+Jsoup操作集群数据存储 1.使用Jsoup爬取京东商城的商品数据 1)获取商品名称.价格以及商品地址,并封装为一个Product对象,代码截 ...
- Define the Data Model and Set the Initial Data 定义数据模型并设置初始数据
This topic describes how to define the business model and the business logic for WinForms and ASP.NE ...
- Jmeter—6 CSV Data Set Config 通过文件导入数据
线程组循环次数大于1的时候,请求里每次提交的数据都相同.有的系统限制了不能提交相同数据,我们通过 CSV Data Set Config 加载csv文件数据. 1 创建一个文本文件,输入参数值保存为. ...
- 转:代码的坏味道之二十 :Data Class(纯稚的数据类)或POJO
所谓Data Class是指:它们拥有一些值域(fields),以及用于访问(读写]这些值域的函数,除此之外一无长物.这样的classes只是一种「不会说话的数据容器」,它们几乎一定被其他classe ...
- [译] 使用Using Data Quality Services (DQS) 清理用户数据
SQL Server 2012 Data Quality Services (DQS) 允许你使用自己的知识库来清洗数据. 在本文中我会展示一个简单示例. 使用DQS清理步骤如下: A. 建立DQS ...
随机推荐
- thinkphp 命令行执行导入
<?phpdeclare (strict_types=1);namespace app\command;use think\console\Command;use think\console\I ...
- C# 线程(二)——Thread学习
参照:C#多线程 - .NET开发菜鸟 - 博客园 (cnblogs.com) C# Thread 线程状态知识 - 大圣的笑 - 博客园 (cnblogs.com) 背景: 在.NET Framew ...
- HarmonyOS运动开发:如何监听用户运动步数数据
前言 在开发运动类应用时,准确地监听和记录用户的运动步数是一项关键功能.HarmonyOS 提供了强大的传感器框架,使得开发者能够轻松地获取设备的运动数据.本文将深入探讨如何在 HarmonyOS 应 ...
- servlet 转发与重定向
目录 转发 重定向 重定向与转发本质都是跳转到新的URL 重定向与转发的本质区别在于:转发是一个服务端的行为,而重定向是一个浏览器的行为. 下面是图解: 转发 转发的作用在服务器端,将请求发送给服务器 ...
- 【BUG】Python3|安装python3-pip依赖缺失,might want to run ‘apt --fix-broken install‘ to correct these. unment
今天装python,版本装错了. 然后删又删不掉,装pip又装不上,报错是这样的: 想装的时候: 7f2a0f717aa3:~/$ sudo apt-get install python3-pip p ...
- Grid 布局-容器项
grid 网格布局是一个用于web的二维布局系统, 多行多列. flex 单行布局则更倾向于一维布局, 一行或者一列. Grid 重点 只是用表格进行排版哈, 横向内容直接无关联哦. 容器项 子项 布 ...
- 小程序简单 tab 切换实现
也是终于找到了数据可视化的最佳载体, 用小程序来做可视化简直完美. 尤其对于像我这种搞数据的, 数据分析, 数据报表, 可视化一直是一个巨大难题, 当我认识的最终的方案还是要用前端的时候, 感觉还有麻 ...
- DOM基础操作小结
最近一个多月都在看看前端的内容. 因为这半年都在做BI嘛, 感觉有些东西呀, 还是用前端来做会更加能满足客户的需求, 于是呢, 就网上找了一些资料, 学习了一波前端基础. 这里也是做个简单的笔记, 关 ...
- BP算法完整推导 2.0 (下)
上篇主要阐述 BP算法的过程, 以及 推导的 4 大公式的结论, 现在呢要来逐步推导出这写公式的原理. 当理解到这一步, 就算真正理解 BP算法了. 也是先做一个简单的回顾一下, 不是很细, 重点在推 ...
- C++/Python混合编程
以 C++ 为底层基础,Python 作为上层建筑,共同搭建起高性能.易维护.可扩展的混合系统. Python 本身就有 C 接口,可以用 C 语言编写扩展模块,把一些低效耗时的功能改用 C 实现,有 ...