从纳秒到毫秒的“时空之旅”:CPU是如何看待内存与硬盘的?
在数据暴涨时代,如何高效存储和管理海量数据已成为应用系统的核心挑战。这不仅关乎读写性能,更涉及并发场景下性能与持久化之间的平衡。要应对这一挑战,既需要理解不同存储介质的物理特性与性能边界,也需通过数据结构、存储模型与操作系统机制的协同设计,达成技术上的最优平衡。
本文将从计算机系统的分层存储体系这一基础视角出发,阐述B+树如何为关系型数据库(如MySQL)的优化复杂查询效率,LSM树如何为NoSQL数据库(如RocksDB)实现高吞吐写入,以及Kafka的日志结构如何借助顺序存储特性突破传统消息队列的性能瓶颈。
计算机存储设计
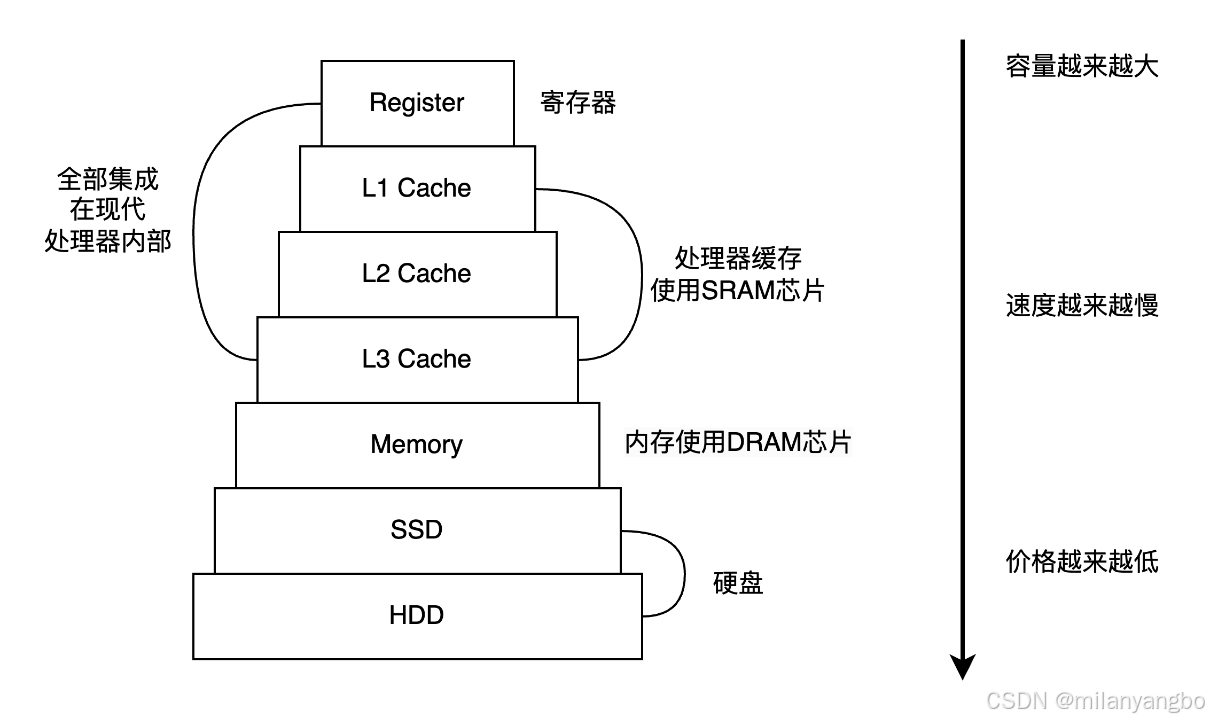
现代计算机的存储器设计地采用了一种分层次的结构。从塔尖的寄存器、高速缓存,到塔身的内存(主存),再到塔基的外部存储(硬盘/SSD),存储器的访问速度逐级递减,而容量逐级递增,单位存储成本也随之显著降低。
寄存器
寄存器(Register)是集成在处理器内部的、数量极少但速度最快的高速存储单元。处理器的算术逻辑单元(Arithmetic And Logic Unit,ALU)直接通过指令集对其进行读写,几乎没有延迟。然而,其制造成本极为高昂,导致容量非常有限。
1)通用寄存器(General-Purpose Registers):用于暂存参与运算的数据、中间结果或地址。其位数(如32位、64位)与处理器的字长相匹配。
2)特殊目的寄存器(Special-Purpose Registers):承载特定控制或状态信息,如程序计数器(PC,指向下一条待执行指令)、堆栈指针(SP)、指令寄存器(IR)、状态寄存器(Flags)等。
3)浮点寄存器(Floating-Point Registers):专用于存储和处理浮点数,支持高精度的科学计算。通常是几个或几十个字节,取决于浮点数的精度和计算需求。
高速缓存
高速缓存是介于处理器与主存之间的一道屏障,用以弥合两者巨大的速度差异。它通常采用静态随机存取存储器(Static Random-Access Memory,SRAM),SRAM由触发器构成,只要供电,数据就能保持,无需刷新电路,因此访问速度极快,接近寄存器,但成本和功耗也较高。
现代处理器普遍集成L1、L2、L3三层高速缓存。
1)L1 Cache:每个处理器核心独享,容量最小(如几十KB),速度最快。通常进一步划分为指令缓存(Instruction Cache)和数据缓存(Data Cache),以支持指令预取和数据读写的并行。
2)L2 Cache:容量和速度介于L1和L3之间。早期设计为核心独享,现代多核处理器中,部分架构(如Intel的一些型号)采用共享L2,而另一些(如AMD的一些型号)仍为核心独享或小组共享。
3)L3 Cache:通常为多核心共享,容量最大(如几MB到几十MB),速度相对最慢,但仍远快于主存。作为主存前最后一道高速防线。
内存
内存,即主存,是计算机运行程序和数据的主要工作区域。它主要采用动态随机存取存储器(Dynamic Random Access Memory,DRAM),DRAM利用电容存储电荷来表示数据位,电容会漏电,因此需要周期性刷新(Refresh)电路来维持数据,这使其速度慢于SRAM,但存储密度更高,单位容量成本更低。
内存用于存放当前正在执行的操作系统、应用程序代码、运行时数据栈、堆等。CPU通过内存总线直接寻址访问内存中的数据。其容量通常以GB或TB计。
外部存储
机械硬盘(Hard Disk Drive、HDD)和固态硬盘(Solid State Drive、SSD)是两种最常见的硬盘,作为计算机的外部存储,处理器想要访问它们存储的数据需要很长时间,如下表所示,在 SSD 中随机访问 4KB 数据需要的时间是访问内存的1500 倍,机械硬盘的寻道时间是访问内存的100000倍。
硬盘是计算机主要的非易失性(断电后数据不丢失)大容量存储设备,用于长期保存用户数据和程序。常见的有机械硬盘(Hard Disk Drive、HDD)和固态硬盘(Solid State Drive、SSD)。处理器访问外部存储数据需通过I/O总线,其速度远慢于内存。
1)机械硬盘:通过磁头在旋转的盘片上读写数据。其访问时间主要由寻道时间(磁头移动到目标磁道)、旋转延迟(盘片旋转到目标扇区)和数据传输时间构成。随机访问性能差,顺序访问性能尚可。
2)固态硬盘 :基于NAND闪存芯片存储数据,无机械部件,随机读写性能远超HDD,延迟极低。但其写入操作(尤其随机写)涉及擦除再写入的特性,存在写放大问题和寿命限制。
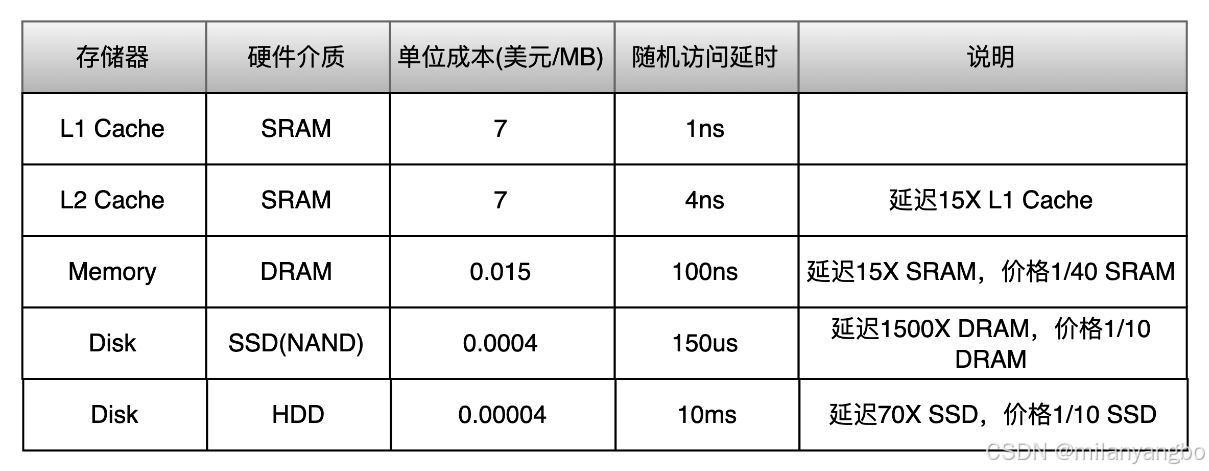
I/O操作
I/O(Input/Output)是计算机系统与外部世界(包括外设、网络、其他系统)进行数据交换的核心过程。它既包括从键盘、鼠标、磁盘、网络等输入源读取数据,也包括将数据输出到显示器、打印机、磁盘、网络等目标。
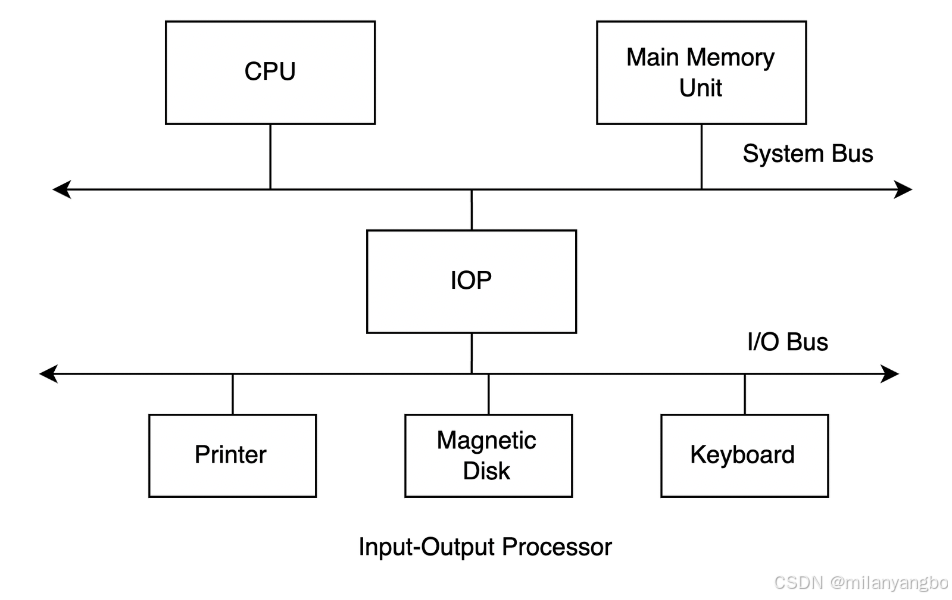
I/O 模式
在计算机体系结构中,硬盘属于一种常见的输入输出设备,处理器想要访问硬盘中的数据要先通过 I/O 将硬盘中的数据读入到内存中,再访问存储在内存中的数据。计算机中包含三种比较常见的 I/O 模式: 程序控制 I/O(Programmed I/O)、中断驱动 I/O(Interrupt-driven I/O)和直接内存访问(Direct Memory Access,DMA)。
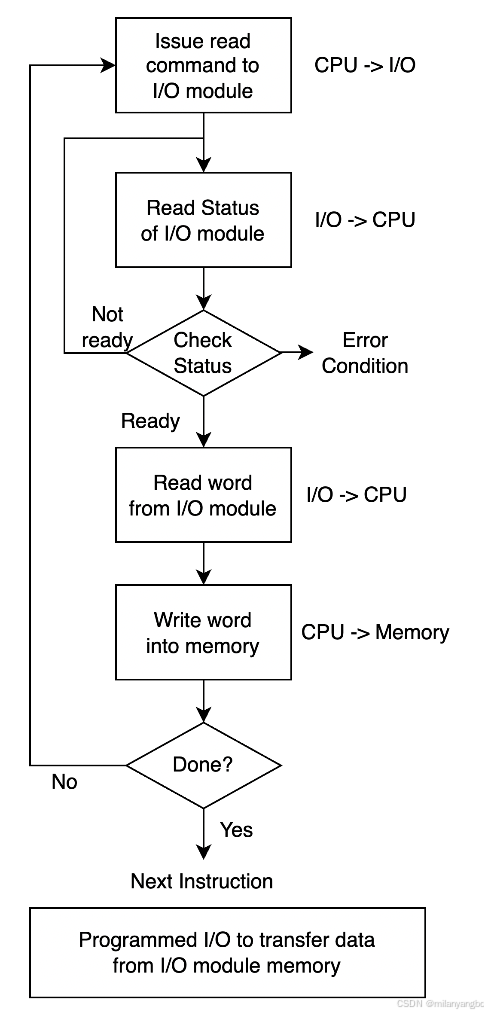
程序控制 I/O
程序控制I/O是最简单的一种 I/O 模式。比如发起系统调用write,处理器会向I/O设备写入数据,写入后会一直轮询I/O设备的状态等待它完成。这个过程涉及到一个内核态和用户态的切换。这种方式虽然简单,但是它会占用全部的处理器资源,在某些复杂的系统中会造成计算资源的严重浪费。
中断驱动 I/O
由于程序控制I/O让处理器处于不必要的繁忙之中,所以出现了中断驱动I/O,通过中断功能和特殊命令来通知接口,只要I/O设备有了需要的数据,便会发出中断请求信号。同时处理器可以继续执行其他程序。与程序控制I/O 相比,中断驱动 I/O 将一部分工作交给了 I/O 设备,所以能够提高资源的利用率。
然而以上两种I/O模式的数据传输都需要处理器干预,并且都有两个缺点:
1)I/O传输速率受处理器的速度限制。
2)每次I/O传输必须执行许多指令。
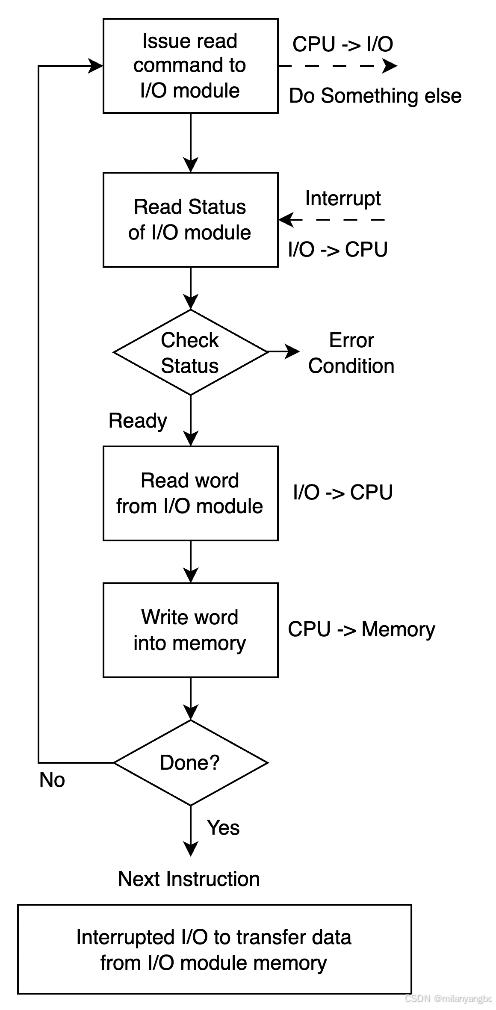
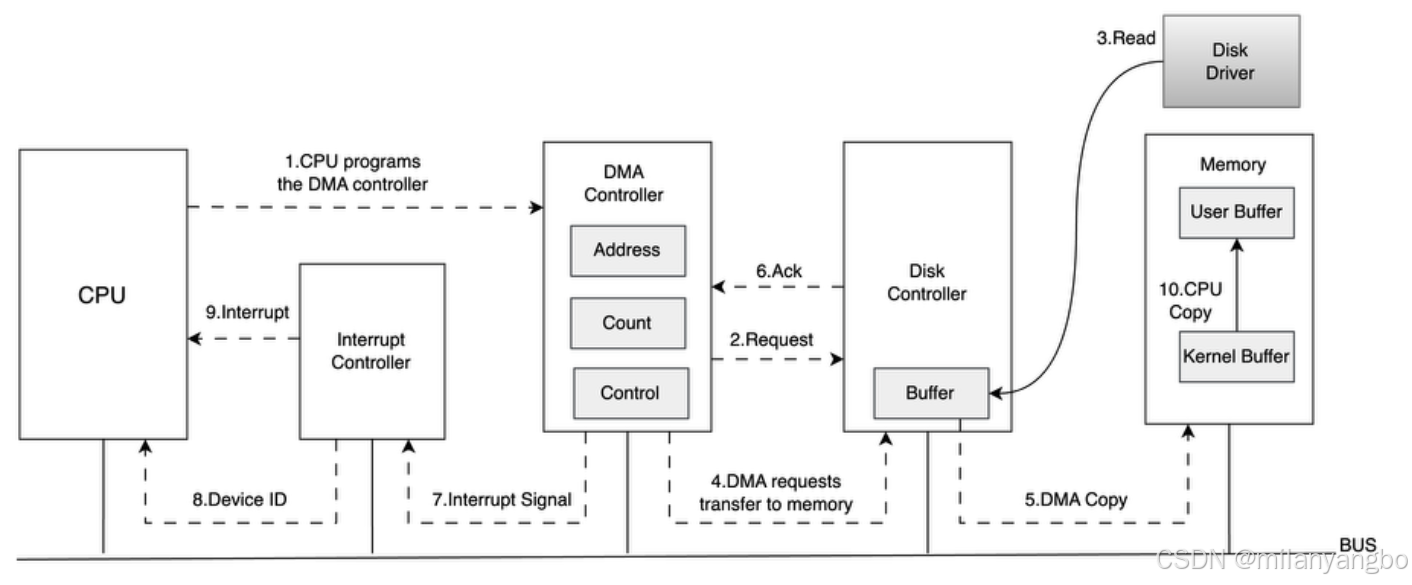
DMA
为解决处理器参与数据传输的瓶颈,引入DMA控制器(Direct Memory Acess Controller, DMAC)。处理器只需向DMAC下达指令(源地址、目标地址、数据长度等),DMAC便能直接在I/O设备和内存之间开辟通路,独立完成数据传输,传输结束后再通过中断通知处理器。处理器在此期间可以并行执行其他任务,仅在传输开始和结束时介入。现代计算机系统默认广泛采用DMA进行I/O操作。
尽管DMA大幅提升效率,但I/O操作(涉及总线仲裁、上下文切换、中断处理等)仍是程序中相对耗时和复杂的操作。
未完待续
很高兴与你相遇!如果你喜欢本文内容,记得关注哦!!!
从纳秒到毫秒的“时空之旅”:CPU是如何看待内存与硬盘的?的更多相关文章
- goLang 纳秒转 毫秒 转 英文时间格式
package main import ( "fmt" "time" ) func main(){ fmt.Println(time.Now().Unix()) ...
- 秒的换算:ms(毫秒),μs(微秒),ns(纳秒),ps(皮秒)
皮秒 皮秒,符号ps(英语:picosecond ).1皮秒等于一万亿分之一秒(10-12秒) 1,000 皮秒 = 1纳秒 1,000,000 皮秒 = 1微秒 1,000,000,000 皮秒 = ...
- 检测Java程序运行时间的2种方法(高精度的时间[纳秒]与低精度的时间[毫秒])
第一种是以毫秒为单位计算的. 代码如下: long startTime=System.currentTimeMillis(); //获取开始时间 doSomeThing(); //测试的代码段 lon ...
- java获取当前系统毫秒,纳秒
//获取当前系统毫秒 System.out.println(System.currentTimeMillis()); //获取当前系统纳秒 System.out.println(System.nano ...
- 秒(s) 毫秒(ms) 微秒(μs) 纳秒(ns) 皮秒(ps)及Java获得 .
Date date=new Date(); long hm=date.getTime(); //获取毫秒 或者 毫秒级:System.currentTimeMillis() 纳秒级: System.n ...
- TimeStamp 毫秒和纳秒
毫秒 /** * Returns the time represented by this Timestamp object, as a long value * containing the num ...
- java的计时:毫秒、纳秒
System.currentTimeMillis()获取毫秒值,但是其精度依赖操作系统 想实现较为精确的毫秒,可以采用 System.nanoTime()/1000000L System.nanoTi ...
- 前端Tips#4 - 用 process.hrtime 获取纳秒级的计时精度
本文同步自 JSCON简时空 - 前端Tips 专栏#4,点击阅读 视频讲解 视频地址 文字讲解 如果去测试代码运行的时长,你会选择哪个时间函数? 一般第一时间想到的函数是 Date.now 或 Da ...
- linux下的定时或计时操作(gettimeofday等的用法,秒,微妙,纳秒(转载)
一.用select()函数实现非阻塞时的等待时间,用到结构体struct timeval {},这里就不多说了. 二.用gettimeofday()可获得微妙级(0.000001秒)的系统时间,调用两 ...
- SQL Server返回DATETIME类型,年、月、日、时、分、秒、毫秒
SQL Server返回DATETIME类型的年.月.日,有两种方法,如下所示: DECLARE @now DATETIME=GETDATE() --第一种方法 SELECT @now,YEAR(@n ...
随机推荐
- Django Web应用开发实战第十一章
一.会话控制 Django内置的会话控制简称为session,可以为用户提供基础的数据存储. 数据主要存储在服务器上,并且网站上的任意站点都能使用会话数据. 当用户第一次访问网站时,网站的服务器将自动 ...
- 关于cc1链-lazymap版复现
关于cc1链-lazymap版复现 思路,在cc链中最重要的其实是transform方法;其反射调用执行的性质+transformchain性质,导致可以通过构造反射调用链子,也就是Runtime.e ...
- RL之深夜有感
世界似乎就是一个巨大的强化学习环境(Env),身处其中的每个人就是里面的智能体,有的为生计四处奔波:有的要探寻精神上的欢娱:有的似乎想跳出Env,不想再继续下去了:可以说每个人的target都不尽相同 ...
- mysql练习题版本一
有些题还没有解决 -- 查询" 01 "课程比" 02 "课程成绩高的学生的信息及课程分数 1.1 查询同时存在" 01 "课程和" ...
- [计算机组成原理] 字符集编码: Unicode 字符集(UTF8/UTF16/UTF32) 和 `BOM`(Byte Order Mark/字节序标记) / UnicodeTextUtils
Unicode字符集 Unicode 字符集的 BOM := Byte Order Mark := 字符顺序标记 BOM(Byte Order Mark)在分析unicode之前,先把bom(byte ...
- Spring Boot 启动优化实践
作者:vivo 互联网服务器团队- Liu Di 本文系统性分析并优化了一个Spring Boot项目启动耗时高达 280 秒的问题.通过识别瓶颈.优化分库分表加载逻辑.异步初始化耗时任务等手段,最终 ...
- SolidWorks Flexnet Serve 正在启动...
SolidWorks Flexnet Serve 正在启动... 解决方案 设置->主页->电脑名称改成英文 电脑重启 具体流程 事情是这样,当我在安装solidworks2022时候发现 ...
- C# 去掉字符串中的html 标签,保留指定的标签和属性
/// <summary> /// 使用示例 /// </summary> public static void HtmlRemove() { string requestBo ...
- 如何通过ETL做数据转换
在数字化时代,数据被誉为新时代的石油,而数据的价值往往隐藏在海量数据背后的信息中.然而,海量的原始数据并不总是直接可用的,这就需要一种有效的工具来对数据进行提取.转换和加载(ETL),从而将数据转化为 ...
- SpringBoot--自动配置的替换和关闭
SpringBoot启用自动配置需要使用@EnableAutoConfiguration注解,整个应用只需一个该注解,因此,只要将该注解加到主配置类即可. 由于 @SpringBootApplicat ...