FastMCP实践开发应用
一、概述
1. 定义与功能
- 定义:FastMCP是一个用于构建MCP服务器的Python框架,它为开发者提供了一种简单优雅的方式来创建MCP服务器,使AI助手能够访问本地工具和资源。
- 核心功能:
- 工具(Tools):类似于API的POST端点,支持执行计算和产生副作用,可以处理复杂的输入输出。
- 资源(Resources):类似于API的GET端点,用于加载信息到LLM的上下文,支持静态和动态资源。
- 提示模板(Prompts):定义可重用的交互模式,支持结构化的消息序列,帮助规范AI交互行为。
- 图片处理:内置图片数据处理,自动处理格式转换,支持工具和资源中使用。
2. 使用场景
- 开发AI助手工具集:为Claude等AI助手提供本地功能扩展,构建特定领域的工具链。
- 数据库交互:安全地暴露数据库查询功能,提供schema信息给AI参考。
- 文件处理:读取和处理本地文件,处理图片等多媒体内容。
- API集成:包装现有API为AI可用的工具,提供统一的访问接口。
二、安装使用
安装
安装很简单,一条命令搞定
pip install fastmcp
使用
官方示例:
server.py
from fastmcp import FastMCP
mcp = FastMCP("Demo ")
@mcp.tool()
def add(a: int, b: int) -> int:
"""Add two numbers"""
return a + b
if __name__ == "__main__":
mcp.run()
注意:直接运行server.py,并不是sse方式。
如果我们想用sse方式,还需要更改代码
from fastmcp import FastMCP
mcp = FastMCP("Demo ",port=9000)
@mcp.tool()
def add(a: int, b: int) -> int:
"""Add two numbers"""
return a + b
if __name__ == "__main__":
mcp.run(transport='sse')
再次运行,就是sse方式了。
打开浏览器,访问:http://127.0.0.1:9000/sse
效果如下:
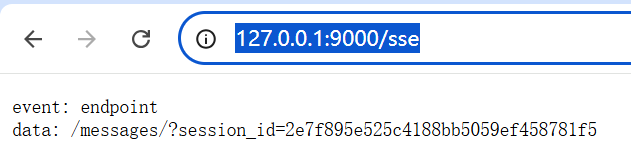
三、开发mysql8应用
在上一篇文章中,已经写了MCP的mysql8应用,但是并不是使用FastMCP框架开发的。我把那段代码改造一下即可
.env文件内容如下:
# MySQL数据库配置
MYSQL_HOST=192.168.20.128
MYSQL_PORT=3306
MYSQL_USER=root
MYSQL_PASSWORD=abcd@1234
MYSQL_DATABASE=test
server.py
from fastmcp import FastMCP
from mysql.connector import connect, Error
from dotenv import load_dotenv
import os mcp = FastMCP("operateMysql", port=9000) # @mcp.tool()
# def add(a: int, b: int) -> int:
# """Add two numbers"""
# return a + b def get_db_config():
"""从环境变量获取数据库配置信息 返回:
dict: 包含数据库连接所需的配置信息
- host: 数据库主机地址
- port: 数据库端口
- user: 数据库用户名
- password: 数据库密码
- database: 数据库名称 异常:
ValueError: 当必需的配置信息缺失时抛出
""" # 加载.env文件
load_dotenv() config = {
"host": os.getenv("MYSQL_HOST", "localhost"),
"port": int(os.getenv("MYSQL_PORT", "3306")),
"user": os.getenv("MYSQL_USER"),
"password": os.getenv("MYSQL_PASSWORD"),
"database": os.getenv("MYSQL_DATABASE"),
}
print(config)
if not all([config["user"], config["password"], config["database"]]):
raise ValueError("缺少必需的数据库配置") return config @mcp.tool()
def execute_sql(query: str) -> list:
"""执行SQL查询语句 参数:
query (str): 要执行的SQL语句,支持多条语句以分号分隔 返回:
list: 包含查询结果的TextContent列表
- 对于SELECT查询:返回CSV格式的结果,包含列名和数据
- 对于SHOW TABLES:返回数据库中的所有表名
- 对于其他查询:返回执行状态和影响行数
- 多条语句的结果以"---"分隔 异常:
Error: 当数据库连接或查询执行失败时抛出
"""
config = get_db_config()
try:
with connect(**config) as conn:
with conn.cursor() as cursor:
statements = [stmt.strip() for stmt in query.split(";") if stmt.strip()]
results = [] for statement in statements:
try:
cursor.execute(statement) # 检查语句是否返回了结果集 (SELECT, SHOW, EXPLAIN, etc.)
if cursor.description:
columns = [desc[0] for desc in cursor.description]
rows = cursor.fetchall() # 将每一行的数据转换为字符串,特殊处理None值
formatted_rows = []
for row in rows:
formatted_row = [
"NULL" if value is None else str(value)
for value in row
]
formatted_rows.append(",".join(formatted_row)) # 将列名和数据合并为CSV格式
results.append(
"\n".join([",".join(columns)] + formatted_rows)
) # 如果语句没有返回结果集 (INSERT, UPDATE, DELETE, etc.)
else:
conn.commit() # 只有在非查询语句时才提交
results.append(f"查询执行成功。影响行数: {cursor.rowcount}") except Error as stmt_error:
# 单条语句执行出错时,记录错误并继续执行
results.append(
f"执行语句 '{statement}' 出错: {str(stmt_error)}"
)
# 可以在这里选择是否继续执行后续语句,目前是继续 return ["\n---\n".join(results)] except Error as e:
print(f"执行SQL '{query}' 时出错: {e}")
return [f"执行查询时出错: {str(e)}"] @mcp.tool()
def get_table_name(text: str) -> list:
"""根据表的中文注释搜索数据库中的表名 参数:
text (str): 要搜索的表中文注释关键词 返回:
list: 包含查询结果的TextContent列表
- 返回匹配的表名、数据库名和表注释信息
- 结果以CSV格式返回,包含列名和数据
"""
config = get_db_config()
sql = "SELECT TABLE_SCHEMA, TABLE_NAME, TABLE_COMMENT "
sql += f"FROM information_schema.TABLES WHERE TABLE_SCHEMA = '{config['database']}' AND TABLE_COMMENT LIKE '%{text}%';"
return execute_sql(sql) @mcp.tool()
def get_table_desc(text: str) -> list:
"""获取指定表的字段结构信息 参数:
text (str): 要查询的表名,多个表名以逗号分隔 返回:
list: 包含查询结果的列表
- 返回表的字段名、字段注释等信息
- 结果按表名和字段顺序排序
- 结果以CSV格式返回,包含列名和数据
"""
config = get_db_config()
# 将输入的表名按逗号分割成列表
table_names = [name.strip() for name in text.split(",")]
# 构建IN条件
table_condition = "','".join(table_names)
sql = "SELECT TABLE_NAME, COLUMN_NAME, COLUMN_COMMENT "
sql += (
f"FROM information_schema.COLUMNS WHERE TABLE_SCHEMA = '{config['database']}' "
)
sql += f"AND TABLE_NAME IN ('{table_condition}') ORDER BY TABLE_NAME, ORDINAL_POSITION;"
return execute_sql(sql) @mcp.tool()
def get_lock_tables() -> list:
"""
获取当前mysql服务器InnoDB 的行级锁 返回:
list: 包含查询结果的TextContent列表
"""
sql = """SELECT
p2.`HOST` AS 被阻塞方host,
p2.`USER` AS 被阻塞方用户,
r.trx_id AS 被阻塞方事务id,
r.trx_mysql_thread_id AS 被阻塞方线程号,
TIMESTAMPDIFF(SECOND, r.trx_wait_started, CURRENT_TIMESTAMP) AS 等待时间,
r.trx_query AS 被阻塞的查询,
l.OBJECT_NAME AS 阻塞方锁住的表,
m.LOCK_MODE AS 被阻塞方的锁模式,
m.LOCK_TYPE AS '被阻塞方的锁类型(表锁还是行锁)',
m.INDEX_NAME AS 被阻塞方锁住的索引,
m.OBJECT_SCHEMA AS 被阻塞方锁对象的数据库名,
m.OBJECT_NAME AS 被阻塞方锁对象的表名,
m.LOCK_DATA AS 被阻塞方事务锁定记录的主键值,
p.`HOST` AS 阻塞方主机,
p.`USER` AS 阻塞方用户,
b.trx_id AS 阻塞方事务id,
b.trx_mysql_thread_id AS 阻塞方线程号,
b.trx_query AS 阻塞方查询,
l.LOCK_MODE AS 阻塞方的锁模式,
l.LOCK_TYPE AS '阻塞方的锁类型(表锁还是行锁)',
l.INDEX_NAME AS 阻塞方锁住的索引,
l.OBJECT_SCHEMA AS 阻塞方锁对象的数据库名,
l.OBJECT_NAME AS 阻塞方锁对象的表名,
l.LOCK_DATA AS 阻塞方事务锁定记录的主键值,
IF(p.COMMAND = 'Sleep', CONCAT(p.TIME, ' 秒'), 0) AS 阻塞方事务空闲的时间
FROM performance_schema.data_lock_waits w
INNER JOIN performance_schema.data_locks l ON w.BLOCKING_ENGINE_LOCK_ID = l.ENGINE_LOCK_ID
INNER JOIN performance_schema.data_locks m ON w.REQUESTING_ENGINE_LOCK_ID = m.ENGINE_LOCK_ID
INNER JOIN information_schema.INNODB_TRX b ON b.trx_id = w.BLOCKING_ENGINE_TRANSACTION_ID
INNER JOIN information_schema.INNODB_TRX r ON r.trx_id = w.REQUESTING_ENGINE_TRANSACTION_ID
INNER JOIN information_schema.PROCESSLIST p ON p.ID = b.trx_mysql_thread_id
INNER JOIN information_schema.PROCESSLIST p2 ON p2.ID = r.trx_mysql_thread_id
ORDER BY 等待时间 DESC;""" return execute_sql(sql) if __name__ == "__main__":
mcp.run(transport="sse")
对比了一下代码,比上次写的少了89行,说明框架使用,还是比较简洁的。
启动应用
python server.py
输出:
INFO: Started server process [19624]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:9000 (Press CTRL+C to quit)
使用Cherry Studio客户端进行测试
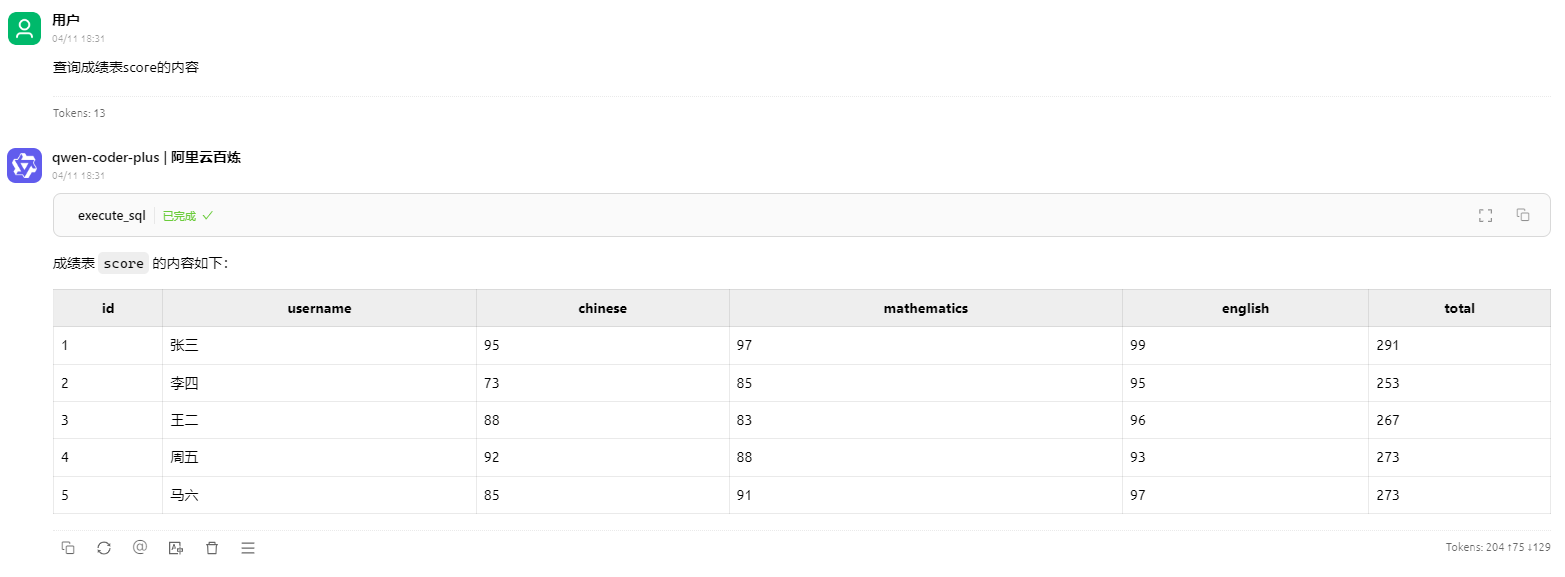
效果是一样的。
FastMCP实践开发应用的更多相关文章
- abp学习(四)——根据入门教程(aspnetMVC Web API进一步学习)
Introduction With AspNet MVC Web API EntityFramework and AngularJS 地址:https://aspnetboilerplate.com/ ...
- TypeScript 在开发应用中的实践总结
背景 以前 hybrid app 的移动端开发模式下,H5 和客户端通信的 js sdk 代码使用 js 编写,sdk 方法的说明使用文档输出.对于开发的使用来说,在 IDE 中不能得到友好的参数类型 ...
- Atitit.软件架构高扩展性and兼容性原理与概论实践attilax总结
Atitit.软件架构高扩展性and兼容性原理与概论实践attilax总结 1. 什么是可扩展的应用程序?1 2. 松耦合(ioc)2 3. 接口的思考 2 4. 单一用途&模块化,小粒度化2 ...
- WinForm/MIS项目开发之中按钮级权限实践
一.前言 AgileEAS.NET SOA 中间件平台是一款基于基于敏捷并行开发思想和Microsoft .Net构件(组件)开发技术而构建的一个快速开发应用平台.用于帮助中小型软件企业建立一条适合市 ...
- 高并发应用场景下的负载均衡与故障转移实践,AgileEAS.NET SOA 负载均衡介绍与实践
一.前言 AgileEAS.NET SOA 中间件平台是一款基于基于敏捷并行开发思想和Microsoft .Net构件(组件)开发技术而构建的一个快速开发应用平台.用于帮助中小型软件企业建立一条适合市 ...
- 《开源安全运维平台:OSSIM最佳实践》内容简介
<开源安全运维平台:OSSIM最佳实践 > 李晨光 著 清华大学出版社出版 内 容 简 介在传统的异构网络环境中,运维人员往往利用各种复杂的监管工具来管理网络,由于缺乏一种集成安全运维平台 ...
- 使用 Eclipse C/C++ Development Toolkit 开发应用程序
使用 Eclipse C/C++ Development Toolkit 开发应用程序 (转) 来自http://blog.csdn.net/favory/article/details/189080 ...
- Android最佳性能实践(二)——分析内存的使用情况
由于Android是为移动设备开发的操作系统,我们在开发应用程序的时候应当始终把内存问题充分考虑在内.虽然Android系统拥有垃圾自动回收机制,但这并不意味着我们就可以完全忽略何时去分配或释放内存. ...
- Data.gov.uk电子政务云,牛津大学NIE金融大数据实验室王宁:数据治理的现状和实践
牛津大学NIE金融大数据实验室王宁:数据治理的现状和实践 我是牛津互联网研究院的研究员,是英国开放互联网的一个主要的研究机构和相关政策制订的一个机构.今天主要给大家介绍一下英国数据治理的一些现状和实践 ...
- (转) Android平台上关于IM的实践总结
前言 IM通信在互联网发展到现在已经是码农的世界里人尽皆知的技术,特别在当下移动互联网迅猛发展的时代这种技术的开发也更加火热,其中老牌的代表作就有QQ和MSN,和最近新崛起的微信,默默,易信,来往等眼 ...
随机推荐
- 【Maven】---操作指南
Maven坐标与依赖 最近想深度学习下maven,找到一本书叫<Maven实战>,这本书讲的确实很好,唯一遗憾的是当时maven教学版本是3.0.0的,而目前已经到了3.5.4了,版本存在 ...
- wget命令简单使用
wget是Linux下一个文件下载工具.wget支持HTTP.HTTPS.FTP协议,可使用HTTP代理. 所谓自动下载,是指 wget 可以在用户退出系统的之后在继续后台执行,直到下载任务完成. w ...
- C++:Boost库
今日安装一个PSI库时,需要boost库,在此认识一下boost库,转载:macOS 中Boost的安装和使用 介绍 Boost是一个功能强大,构造精良,跨越平台,代码开源,完全免费的C++程序库. ...
- Linux软连接与硬链接的概念
- Nickel pg walkthrough Intermediate window
nmap ┌──(root㉿kali)-[~] └─# nmap -p- -A -sS 192.168.196.99 Starting Nmap 7.94SVN ( https://nmap.org ...
- WAIC 2024盛大召开,天翼云以全栈智算能力赋能AI时代!
7月5日,2024世界人工智能大会期间,中国电信星辰人工智能生态论坛在上海世博中心启幕.论坛以"星辰注智,焕新领航"为主题,围绕人工智能技术发展趋势,分享中国电信与产业各界在人工智 ...
- shell 数组函数进阶练习
一维数组的定义.统计.引用和删除等操作. A=( test1 test2 test3 ) ,定义数组一般以括号的方式来定义, 数组的值可以随机定义. echo ${A[0]} ,代表引用第一个数组变量 ...
- 发那科焊接机器人M-10iA维修总结
发那科作为工业机器人制造商,其焊接机器人产品广泛应用于各种工业领域.然而,随着时间的推移,焊接机器人可能会出现故障,因此了解发那科焊接机器人M-10iA维修知识显得尤为重要. 一.日常法那科机械手维护 ...
- 使用JAVA8 filter对List多条件筛选
记录项目开发的过程中遇到的一些问题及解决方法,由于公司操作数据库都是统一使用工具生成的存在一些多表查询模糊查询,这些操作只能在集合方面下手了,比如发送邮件记录方面查询,对用户的名字及邮件模糊检索 年龄 ...
- Edge、谷歌浏览器默认下载器开启多线程下载
浏览器默认下载器开启多线程下载 Chrome 浏览器,地址栏输入并回车: chrome://flags/#enable-parallel-downloading Edge 新版浏览器,地址栏输入并回车 ...