【Python】批量导出word文档中的图片、嵌入式文件
Python 批量导出word文档中的图片、嵌入式文件
需求
学生试卷中的题目有要提交截图的,也有要提交文件的,为了方便学生考试,允许单独交或者嵌入Word中提交,那么事后如何整理学生的答案?单独提交的比较方便,直接扫描文件名匹配名字后放入指定文件夹即可。但是嵌入到Word中的图片和文件怎么提取出来呢?
现有如下需求:提取出一个Word文档中所有的图片(png、jpg)和嵌入的文件(任意格式)放入到指定的文件夹。
解决
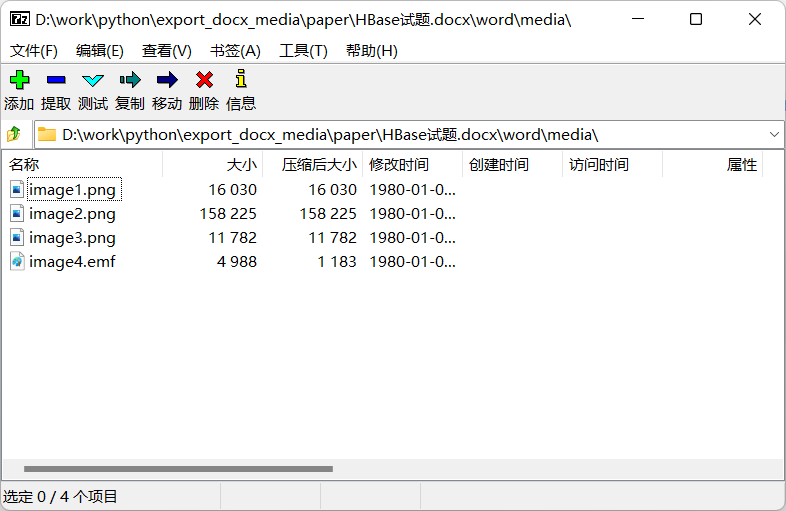
docx是一个压缩包,解压缩后图片一般都放在文档名.docx\word\media\目录下:
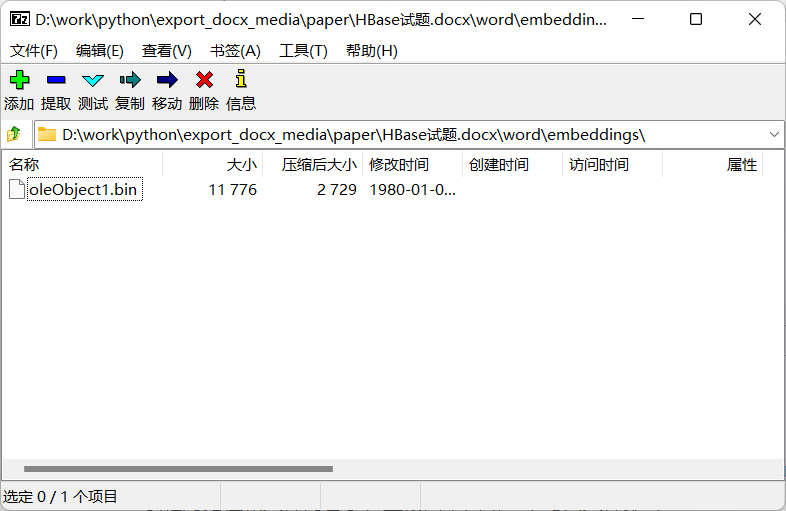
而嵌入式文件一般都放在文档名.docx\word\embeddings\目录下:
经过询问度娘,发现提取图片比较简单,直接使用docx库中的Document.part.rels{k:v.target_ref}找到文件的相对路径,用Document.part.rels{k:v.target_part.blob}读出文件内容。简单判断一下路径和文件后缀是不是我们需要的media下的png文件和embeddings下的bin文件,是的话写入到新文件中即可:
提取图片
安装python-docx库
pip install python-docx
提取
import os
from docx import Document # pip install python-docx
is_debug = True
if __name__ == '__main__':
# 需要导出的Word文档路径
target_file = r'paper\HBase试题.docx'
# 导出文件所在目录
output_dir = r'paper\output'
# 加载Word文档
doc = Document(target_file)
# 遍历Word包中的所有文件
dict_rel = doc.part.rels
# r_id:文件身份码,rel:文件对象
for r_id, rel in dict_rel.items():
if not ( # 如果文件不是在media或者embeddings中的,直接跳过
str(rel.target_ref).startswith('media')
or str(rel.target_ref).startswith('embeddings')
):
continue
# 如果文件不是我们想要的后缀,也直接跳过
file_suffix = str(rel.target_ref).split('.')[-1:][0]
if file_suffix.lower() not in ['png', 'jpg', 'bin']:
continue
# 如果输出目录不存在,创建
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 构建导出文件的名字和路径
file_name = r_id + '_' + str(rel.target_ref).replace('/', '_')
file_path = os.path.join(output_dir,file_name)
# 将二进制数据写入到新位置的文件中
with open(file_path, "wb") as f:
f.write(rel.target_part.blob)
# 打印结果
if is_debug:
print('导出文件成功:', file_name)
运行结果:
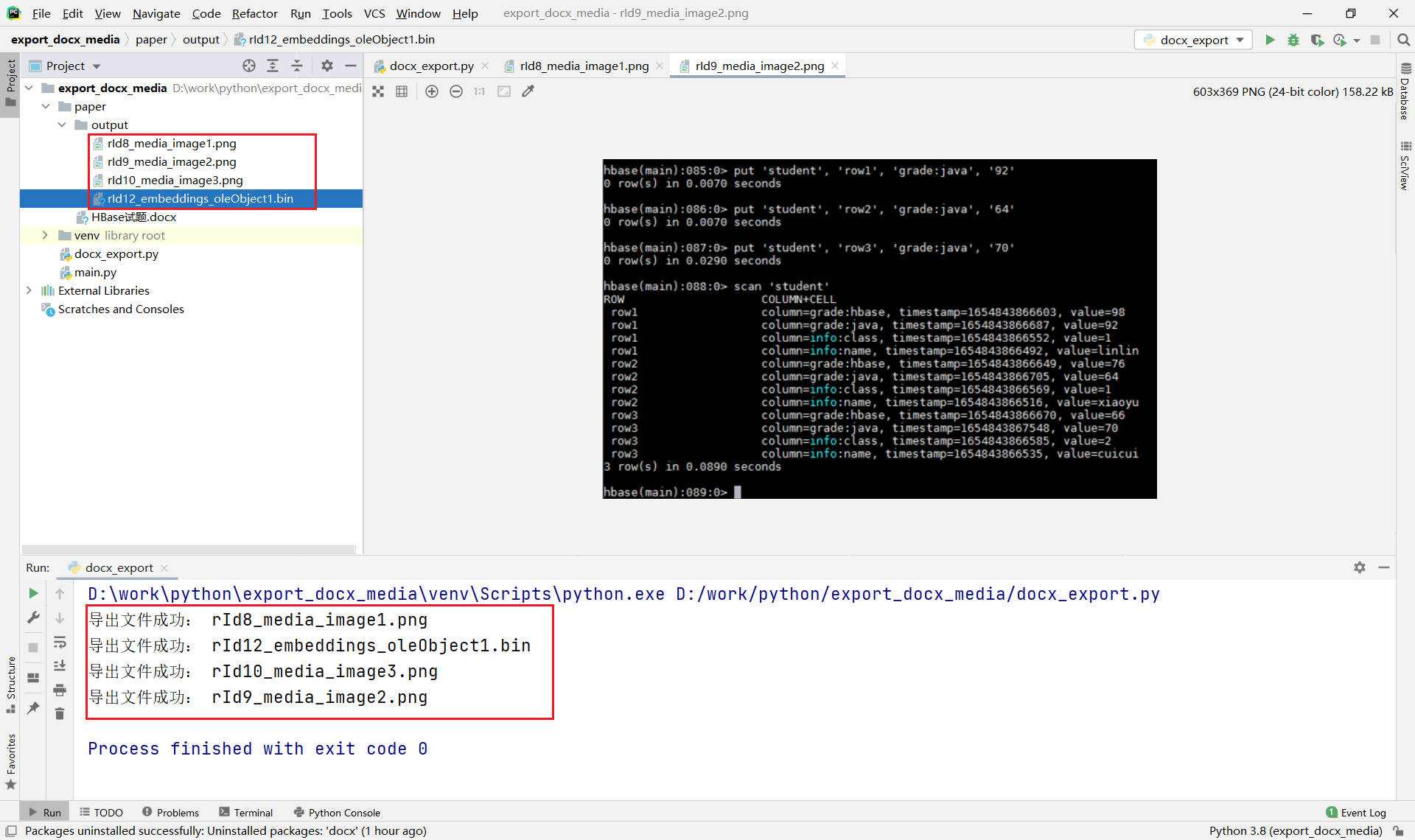
可以看到,图片都能正常导出,但是学生嵌入的JAVA文件并没有导出,或者说导出的是bin文件,没有完全导出。
提取嵌入式文件
再次询问度娘发现,这种其实也是zip压缩包,但是不能直接提取出,它有个更专业的名字,叫ole文件,我们之前的doc、xls、ppt等没有带x的上古文档文件都是这种格式。那如何提取出文件呢?度娘告诉我有个叫oletools的项目可以,于是下载下来浅浅地分析了下,发现确实可以!
oletools项目地址:https://github.com/decalage2/oletools
或者gitee上别人转存的地址:https://gitee.com/yunqimg/oletools
我是用的gitee上的版本,因为github打不开 QwQ
经相关文档介绍,项目下的oletools-master\oletools\oleobj.py就可以提取这种bin后缀的ole文件,简单试一下,在oleobj.py所在目录下打开命令行,把刚刚提取出的rId12_embeddings_oleObject1.bin文件复制到oleobj.py所在目录,执行如下命令:
注意: 在此之前我执行了一下安装oletools的命令,如果不安装可能会出错:pip install oletools,或者说oleobj.py依赖olefile:pip install olefile,在安装oletools时顺便安装了olefile。
python oleobj.py rId12_embeddings_oleObject1.bin
成功导出
Microsoft Windows [版本 10.0.22000.708]
(c) Microsoft Corporation。保留所有权利。
D:\Minuy\Downloads\oletools-master\oletools-master\oletools>python oleobj.py rId12_embeddings_oleObject1.bin
oleobj 0.56 - http://decalage.info/oletools
THIS IS WORK IN PROGRESS - Check updates regularly!
Please report any issue at https://github.com/decalage2/oletools/issues
-------------------------------------------------------------------------------
File: 'rId12_embeddings_oleObject1.bin'
extract file embedded in OLE object from stream '\x01Ole10Native':
Parsing OLE Package
Filename = "Boos.java"
Source path = "D:\111\´ó20´óÊý¾Ý Àî¾üÁé\Boos.java"
Temp path = "C:\Users\ADMINI~1\AppData\Local\Temp\Boos.java"
saving to file rId12_embeddings_oleObject1.bin_Boos.java
D:\Minuy\Downloads\oletools-master\oletools-master\oletools>
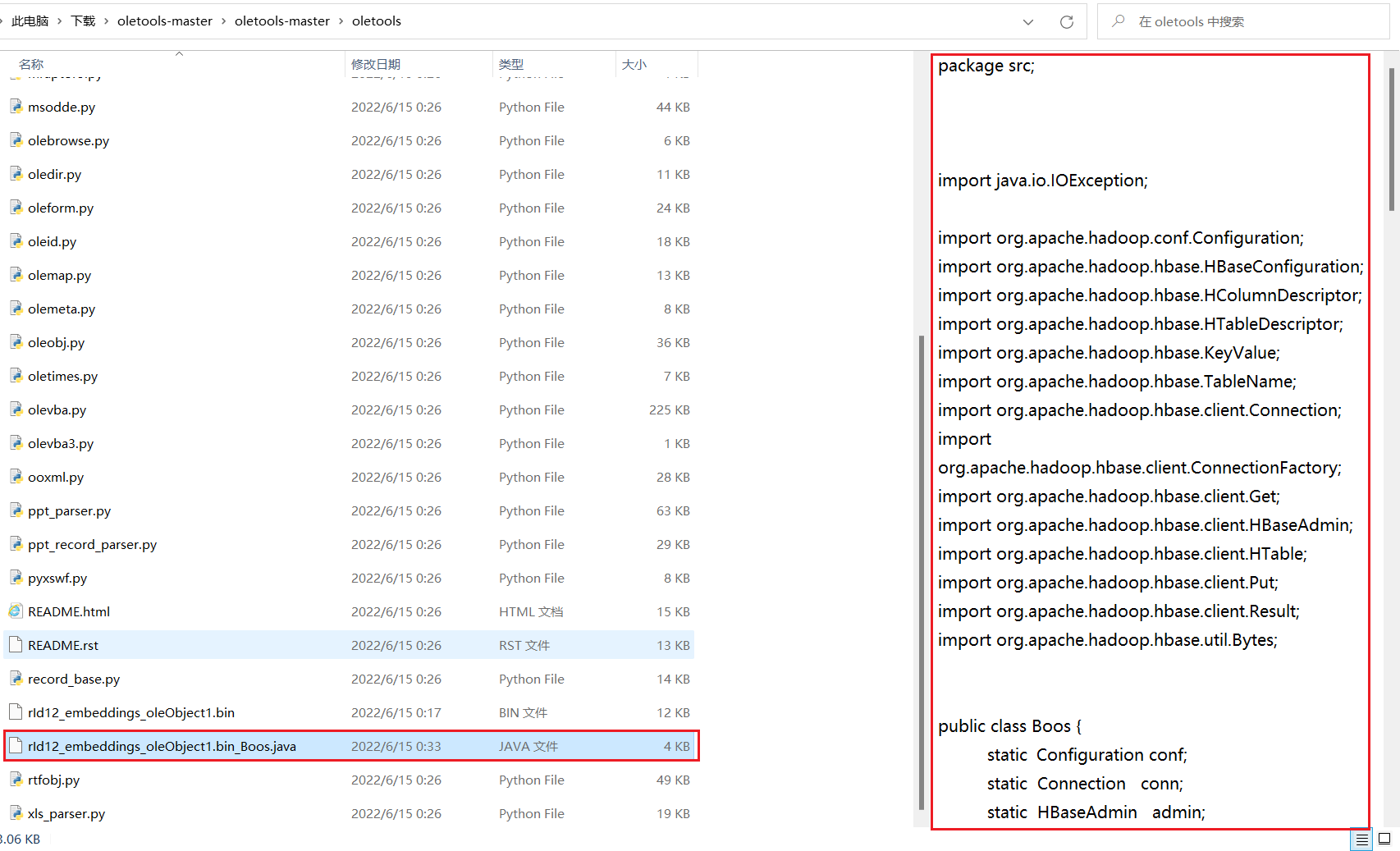
导出的文件也能正常访问:
于是把oletools目录复制到工程项目下,稍微修改一下oleobj.py能让我的代码调用它,在oleobj.py中添加如下代码:
def export_main(ole_files, output_dir, log_leve=DEFAULT_LOG_LEVEL):
ensure_stdout_handles_unicode()
logging.basicConfig(level=LOG_LEVELS[log_leve], stream=sys.stdout,
format='%(levelname)-8s %(message)s')
# 启用日志模块
log.setLevel(logging.NOTSET)
any_err_stream = False
any_err_dumping = False
any_did_dump = False
for container, filename, data \
in xglob.iter_files(ole_files,
recursive=False,
zip_password=None,
zip_fname='*'):
if container and filename.endswith('/'):
continue
# 输出文件夹
err_stream, err_dumping, did_dump = \
process_file(filename, data, output_dir)
any_err_stream |= err_stream
any_err_dumping |= err_dumping
any_did_dump |= did_dump
return_val = RETURN_NO_DUMP
if any_did_dump:
return_val += RETURN_DID_DUMP
if any_err_stream:
return_val += RETURN_ERR_STREAM
if any_err_dumping:
return_val += RETURN_ERR_DUMP
return return_val
def export_ole_file(ole_files, output_dir, debug=False):
debug_leve = 'critical'
if debug:
debug_leve = 'info'
# 导出
result = export_main(
ole_files,
output_dir,
debug_leve
)
if result and debug:
print('导出ole文件出错', ole_files)
在提取文件的代码后面加上如下调用:
if str(rel.target_ref).startswith('embeddings'):
# 解压嵌入式文件
export_ole_file([file_path], output_dir)
再次运行
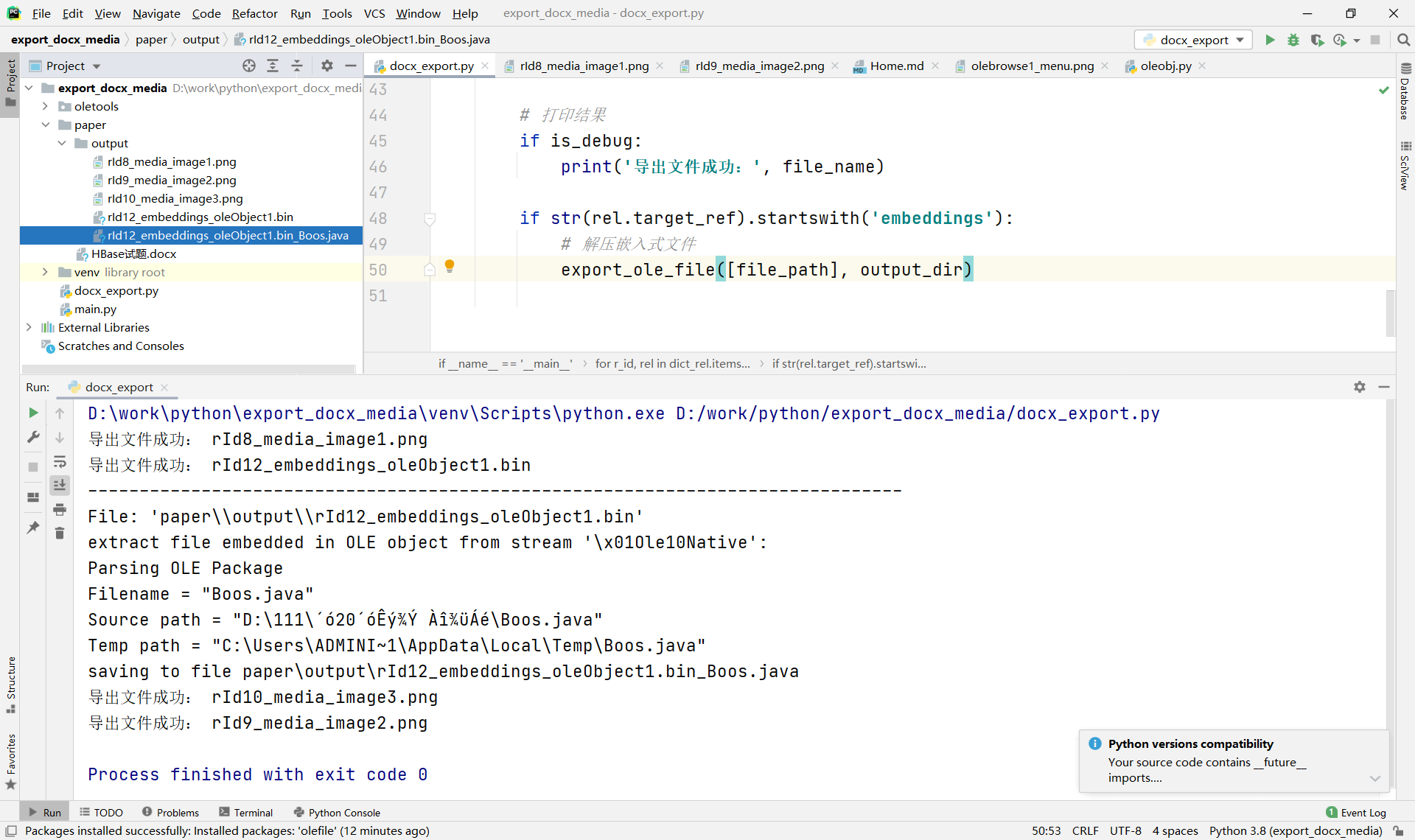
成功导出嵌入到Word中的文件!
成功解决问题~
资源
oletools:https://gitee.com/yunqimg/oletools
本项目:https://gitcode.net/XiaoYuHaoAiMin/export_docx_media_file
本项目打包:https://download.csdn.net/download/XiaoYuHaoAiMin/85643779
参考文档
https://blog.csdn.net/culun797375/article/details/108840682 (手动提取)
https://github.com/decalage2/oletools (本次主角之一oletools的仓库)
https://gitee.com/yunqimg/oletools (oletools在gitee上的副本)
https://blog.csdn.net/u011420268/article/details/106402153 (插入附件,想参考其普通文件如何转ole的,但是好像没转ole格式)
https://blog.csdn.net/lly1122334/article/details/109669667 (python-docx的使用)
https://zhuanlan.zhihu.com/p/446557096(oletools教程)
https://blog.csdn.net/tixxxa/article/details/120429483 (导出附件Python实现,没用oletools,好像不行,有兴趣的同志可以研究下)
https://blog.csdn.net/Cody_Ren/article/details/103886098 (ole文件结构,发现oletools后放弃自己写了)
https://blog.csdn.net/m0_60574457/article/details/119279798 (oletools中文教程,好像是readme.md翻译过来的)
【Python】批量导出word文档中的图片、嵌入式文件的更多相关文章
- C# 导出word文档及批量导出word文档(1)
这里用到了两个dll,一个是aspose.word.dll,另外一个是ICSharpCode.SharpZipLib.dll,ICSharpCode.SharpZipLib.dll是用于批量 ...
- C# 导出word文档及批量导出word文档(4)
接下来是批量导出word文档和批量打印word文件,批量导出word文档和批量打印word文件的思路差不多,只是批量打印不用打包压缩文件,而是把所有文件合成一个word,然后通过js来调用 ...
- Python批量创建word文档(2)- 加图片和表格
Python创建word文档,任务要求:小杨在一家公司上班,每天都需要给不同的客户发送word文档,以告知客户每日黄金价格.要求在文档开始处给出banner条,价格日期等用表格表示.最后贴上自己的联系 ...
- Python批量创建word文档(1)- 纯文字
Python创建word文档,任务要求:小杨在一家公司上班,每天都需要给不同的客户发送word文档,以告知客户每日黄金价格.最后贴上自己的联系方式.代码如下: 1 ''' 2 #python根据需求新 ...
- Java 用Freemarker完美导出word文档(带图片)
Java 用Freemarker完美导出word文档(带图片) 前言 最近在项目中,因客户要求,将页面内容(如合同协议)导出成word,在网上翻了好多,感觉太乱了,不过最后还是较好解决了这个问题. ...
- 【Java】用Freemarker完美导出word文档(带图片)
Java 用Freemarker完美导出word文档(带图片) 前言 最近在项目中,因客户要求,将页面内容(如合同协议)导出成word,在网上翻了好多,感觉太乱了,不过最后还是较好解决了这个问题. ...
- C# 提取Word文档中的图片
C# 提取Word文档中的图片 图片和文字是word文档中两种最常见的对象,在微软word中,如果我们想要提取出一个文档内的图片,只需要右击图片选择另存为然后命名保存就可以了,今天这篇文章主要是实现使 ...
- 如何批量删除word文档中的超级链接?
有时候从网页上copy来的文章中,会带有非常多的链接,这些链接很烦人是吧?如何批量删除(一次性全部删除)word文章中的超链接呢? 有些朋友说,Ctrl+A全选文章,然后点击格式工具栏上的“清除格式” ...
- 利用POI操作不同版本号word文档中的图片以及创建word文档
我们都知道要想利用java对office操作最经常使用的技术就应该是POI了,在这里本人就不多说到底POI是什么和怎么用了. 先说本人遇到的问题,不同于利用POI去向word文档以及excel文档去写 ...
- C# 导出word文档及批量导出word文档(3)
在初始化WordHelper时,要获取模板的相对路径.获取文档的相对路径多个地方要用到,比如批量导出时要先保存文件到指定路径下,再压缩打包下载,所以专门写了个关于获取文档的相对路径的类. #regio ...
随机推荐
- Java中hashCode() 和 equals()
该文章为转载(原文链接在结尾),虽然篇幅偏长,但是却能使你真正理解hashCode和queals各自的作用以及之间的联系,尤其是第四部分,读完肯定会让你有所收获. 第1部分 equals() 的作用 ...
- CDS标准视图:银行对账单行项目 I_BankStatementItem
视图名称:银行对账单行项目 I_BankStatementItem 视图类型:基础视图 视图代码: 点击查看代码 @AbapCatalog.sqlViewName: 'IBANKSTATMENTITM ...
- CDS标准视图:维护活动类型描述 I_MaintenanceActivityTypeText
视图名称:维护活动类型描述 I_MaintenanceActivityTypeText 视图类型:基础 视图代码: 点击查看代码 @AbapCatalog.sqlViewName: 'IMTACTTY ...
- LCR 170. 交易逆序对的总数
交易逆序对的总数 在股票交易中,如果前一天的股价高于后一天的股价,则可以认为存在一个「交易逆序对」.请设计一个程序,输入一段时间内的股票交易记录 record,返回其中存在的「交易逆序对」总数. 示例 ...
- Java方法引用、lambda如何序列化&方法引用与lambda实现原理
系列文章目录和关于我 0.引入 最近笔者使用flink实现一些实时数据清洗(从kafka清洗数据写入到clickhouse)的功能,在编写flink作业后进行上传,发现运行的时候抛出:java.io. ...
- 第五章 dubbo源码解析目录
第十章 dubbo线程模型 一 netty的线程模型 在netty中存在两种线程:boss线程和worker线程. 1 boss线程 作用: accept客户端的连接: 将接收到的连接注册到一个wor ...
- 关于 static 和 final 的一些理解
今天主要回顾一下 static 和 final 这两个关键字. 1. static - 静态 修饰符 - 用于修饰数据(变量.对象).方法.代码块以及内部类. 1.1 静态变量 用 ...
- Python 潮流周刊#86:Jupyter Notebook 智能编码助手(摘要)
本周刊由 Python猫 出品,精心筛选国内外的 250+ 信息源,为你挑选最值得分享的文章.教程.开源项目.软件工具.播客和视频.热门话题等内容.愿景:帮助所有读者精进 Python 技术,并增长职 ...
- C#从数据库中加载照片的
从数据库中读取人员照片信息并加载到图片控件的代码 string conn = "Server=192.168.xx.xx;Database=dbName;User ID=sa;passwor ...
- Jenkins+Ant+JaCoCo的代码覆盖率集成实践
Jenkins+Ant+JaCoCo的代码覆盖率集成实践 一.工具介绍 Jenkins: Jenkins是一个开源的.基于Java开发的持续集成工具,它可以帮助开发人员自动化构建.测试和部署软件项目. ...