Graph4Stream:基于图的流计算加速

作者:汪煜
之前在「姊妹篇」《Stream4Graph:动态图上的增量计算》中,向大家介绍了在图计算技术中引入增量计算能力「图+流」,GeaFlow流图计算相比Spark GraphX取得了显著的性能提升。那么在流计算技术中引入图计算能力「流+图」,GeaFlow流图计算相比Flink关联计算性能如何呢?
当今时代,数据正以前所未有的速度和规模产生,对海量数据进行实时处理在异常检测、搜索推荐、金融交易等各个领域都有着广泛的应用。流计算作为最主要的实时数据处理技术也变得越来越重要。
与批处理需要等待数据全部到齐才进行计算不同,流计算将持续生成的数据流划分成微批,对每个微批的数据进行增量计算。这样的计算特性使得流计算具有高吞吐、低延迟的特性。常见的流计算引擎包括Flink、Spark Streaming等,他们都采用表的方式处理流中的数据。随着流计算应用的深入,越来越多的计算场景涉及到大数据之间关联关系的计算,此时基于表的流计算引擎性能会大幅下降。
蚂蚁图计算团队开源的流图计算引擎GeaFlow,将图计算与流计算相结合,提供了高效的流图处理框架,大幅提升了计算性能。下面为大家介绍传统流计算引擎在关联关系计算的局限性,GeaFlow流图计算高效的原理以及他们的性能对比。
1. 流计算引擎:Flink
Flink是经典的基于表的流处理引擎,他将输入的数据流切分成微批,每次计算当前批次的数据。在计算过程中,Flink将计算任务翻译成由map、filter、join等基础算子组成的有向图,每个算子都有他的上游输入和下游输出。增量数据经过所有算子的计算后输出当前批次的结果。
我们以k-Hop算法为例,描述Flink的计算过程。k-Hop是指K跳关系,例如在社交网络中k-Hop指的是可以通过K个中间人相互认识的关系链,在交易分析中指资金的K次连续转移的路径。假定以2跳关系为例,输入的数据格式 src dst代表了两两关系。Flink的计算SQL如下文所示
-- create source table
CREATE TABLE edge (
src int,
dst int
) WITH (
);
CREATE VIEW `v_view` (`vid`) AS
SELECT distinct * from
(
SELECT `src` FROM `edge`
UNION ALL
SELECT `dst` FROM `edge`
);
CREATE VIEW `e_view` (`src`, `dst`) AS
SELECT `src`, `dst` FROM `edge`;
CREATE VIEW `join1_edge`(`id1`, `dst`) AS SELECT `v`.`vid`, `e`.`dst`
FROM `v_view` AS `v` INNER JOIN `e_view` AS `e`
ON `v`.`vid` = `e`.`src`;
CREATE VIEW `join1`(`id1`, `id2`) AS SELECT `e`.`id1`, `v`.`vid`
FROM `join1_edge` AS `e` INNER JOIN `v_view` AS `v`
ON `e`.`dst` = `v`.`vid`;
CREATE VIEW `join2_edge`(`id1`, `id2`, `dst`) AS SELECT `v`.`id1`, `v`.`id2`, `e`.`dst`
FROM `join1` AS `v` INNER JOIN `e_view` AS `e`
ON `v`.`id2` = `e`.`src`;
CREATE VIEW `join2`(`id1`, `id2`, `id3`) AS SELECT `e`.`id1`, `e`.`id2`, `v`.`vid`
FROM `join2_edge` AS `e` INNER JOIN `v_view` AS `v`
ON `e`.`dst` = `v`.`vid`;
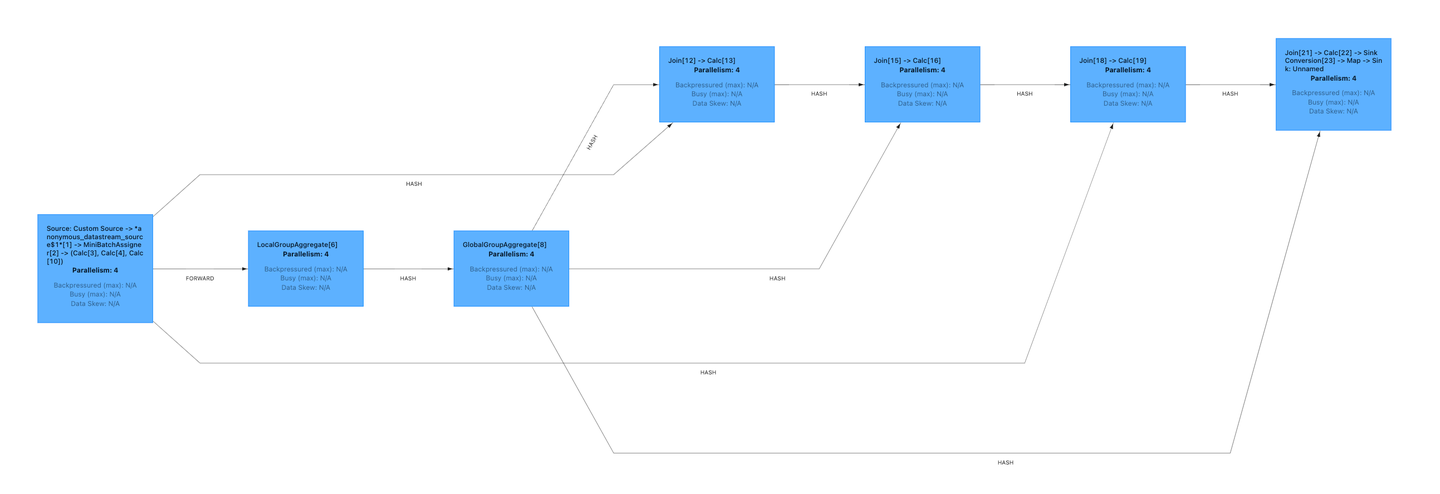
它的执行计划如下图所示,他由Aggregate、Calc、Join等算子组成,数据流经每个算子最终得到增量结果。核心算子join实现了关联关系的查找,我们来详细分析Join算子的实现方式。
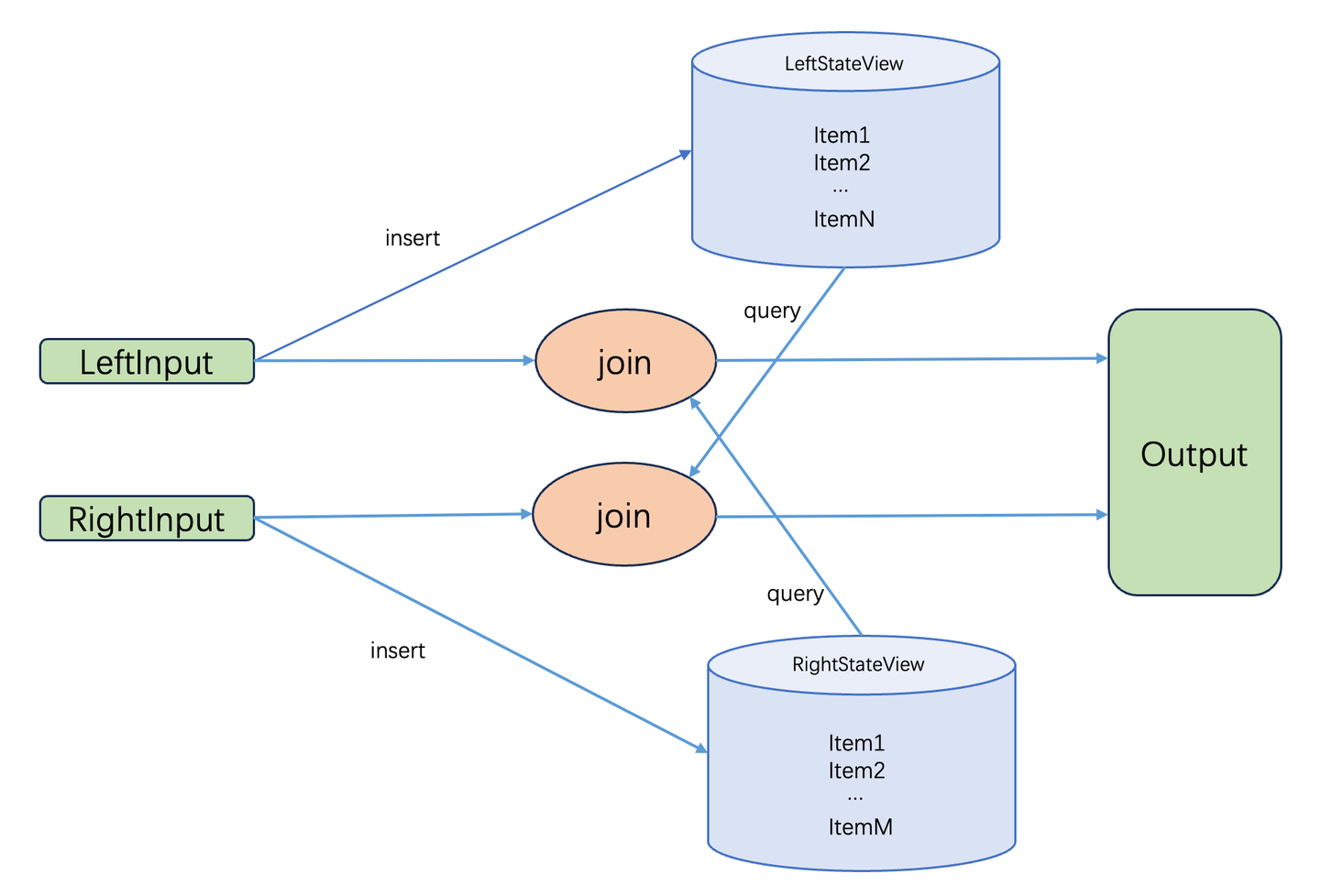
如下图所示,Join算子有两个输入流LeftInput和RightInput,分别代表了join的左表和右表,Join算子在接收到上游的数据后执行计算。以左输入流为例,输入的数据首先被加入到LeftStateView中保存起来,然后去RightStateView中查询是否有数据符合join条件,这个查询过程需要遍历RightStateView,最后将join结果输入到下一个算子中。
join计算主要的性能瓶颈就在遍历RightStateView。LeftStateView和RightStateView实际上存储join的左表和右表。随着数据不断输入,StateView中的数据量持续膨胀,最终导致遍历的耗时急剧上升,严重影响系统性能。
2. 流图计算引擎:GeaFlow
2.1 图计算&流图
图计算是一种基于图数据格式的计算范式,其中图G(V,E)由点集合V和边集合E构成,边代表了数据之间的关联关系。以公开数据集web-Google为例,其中每一行数据由两个数字组成,代表了两个页面之间的跳转关系。如下图所示,左侧是原始数据,常规的数据建模方式是建立一张包含两列数据的表,而图的建模方式是将网页作为点,将页面的跳转关系作为边,构成一张跳转网络图。在表的建模方式中,关联关系的计算是通过表的join实现的,join需要遍历左表或者右表。而在图计算中,关联关系被直接存储在边中,省去了遍历的过程。
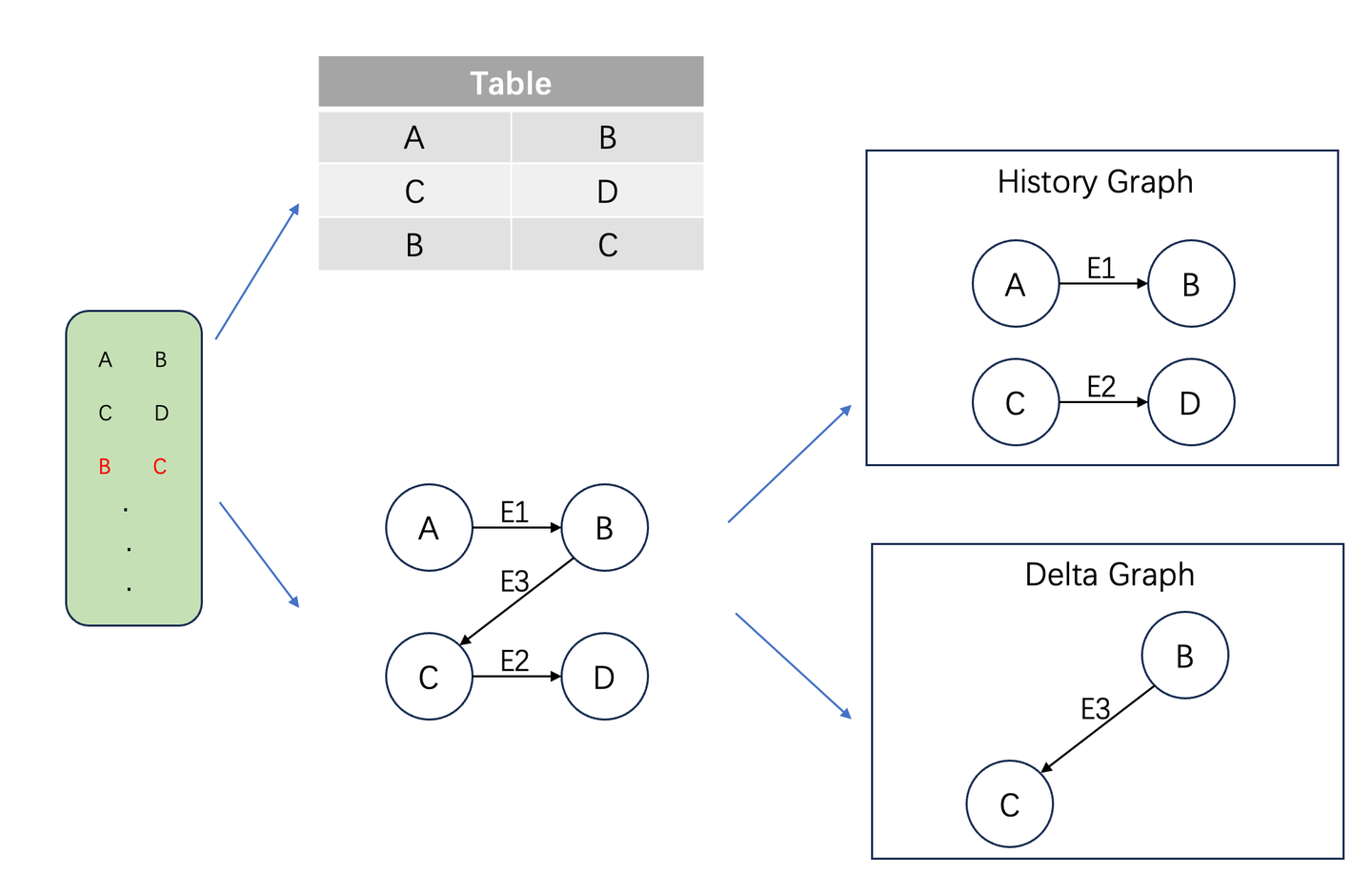
流图是图在流场景中的应用,他依据数据流对图的更新将图分成历史图和增量图两个部分。例如在上图中,假设第一行和第二行数据已经输入并完成相应计算,当前处理第三行数据。此时历史图就是由前两行数据建模得到,而增量图是由第三行数据组成的图,两者合并起来就得到完整的图。在流图上应用增量图算法,可以高效完成计算任务,实现实时计算。
2.2 GeaFlow架构
GeaFlow引擎的计算流程分为流数据输入、分布式增量图计算、增量结果输出几个部分。和传统的流计算引擎一样,输入的实时数据按照窗口被切分成微批。对于当前批次的数据,先按照建模策略解析成点边构成增量图。增量图和之前数据构成的历史图一道组成完整的流图。计算框架在流图上应用增量图算法得到增量结果输出,最后把增量图添加到历史图中。
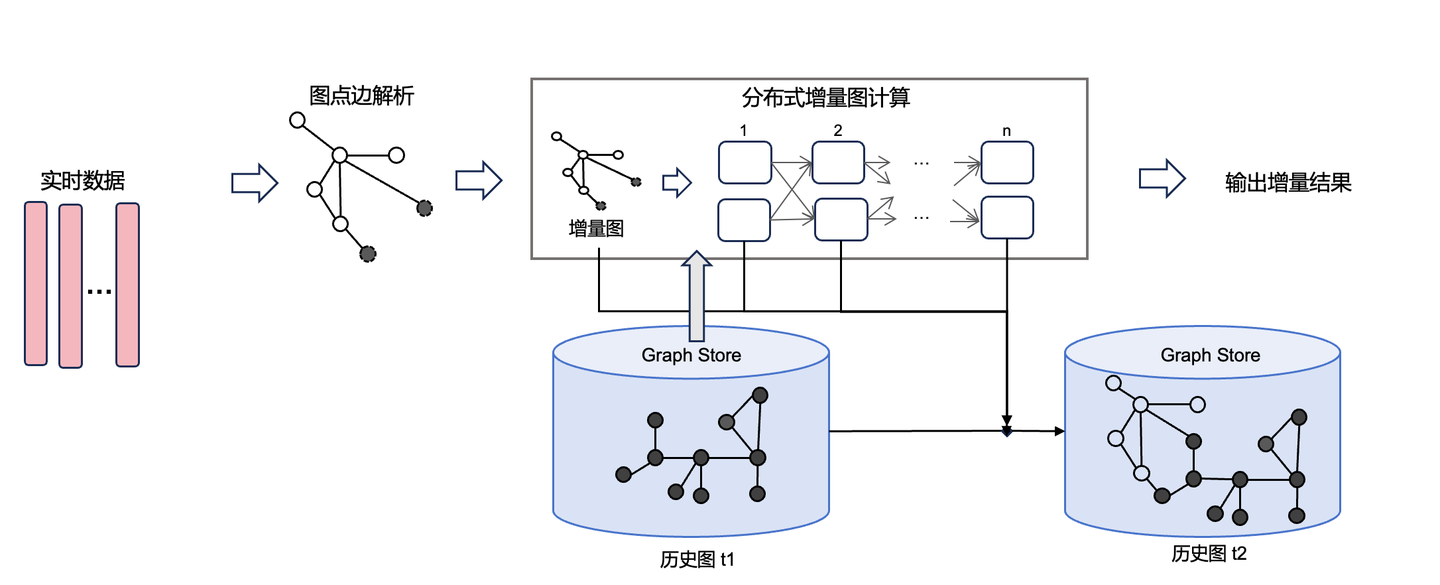
GeaFlow计算框架是以点为中心的迭代计算模型。他以增量图中的点作为第一轮迭代的起点。在每一轮迭代中,每个点都独立维护自身的状态,根据与每个点关联的历史图和增量图完成当前迭代轮次的计算,最后将计算结果通过消息传递给邻居点,开启下一轮迭代。
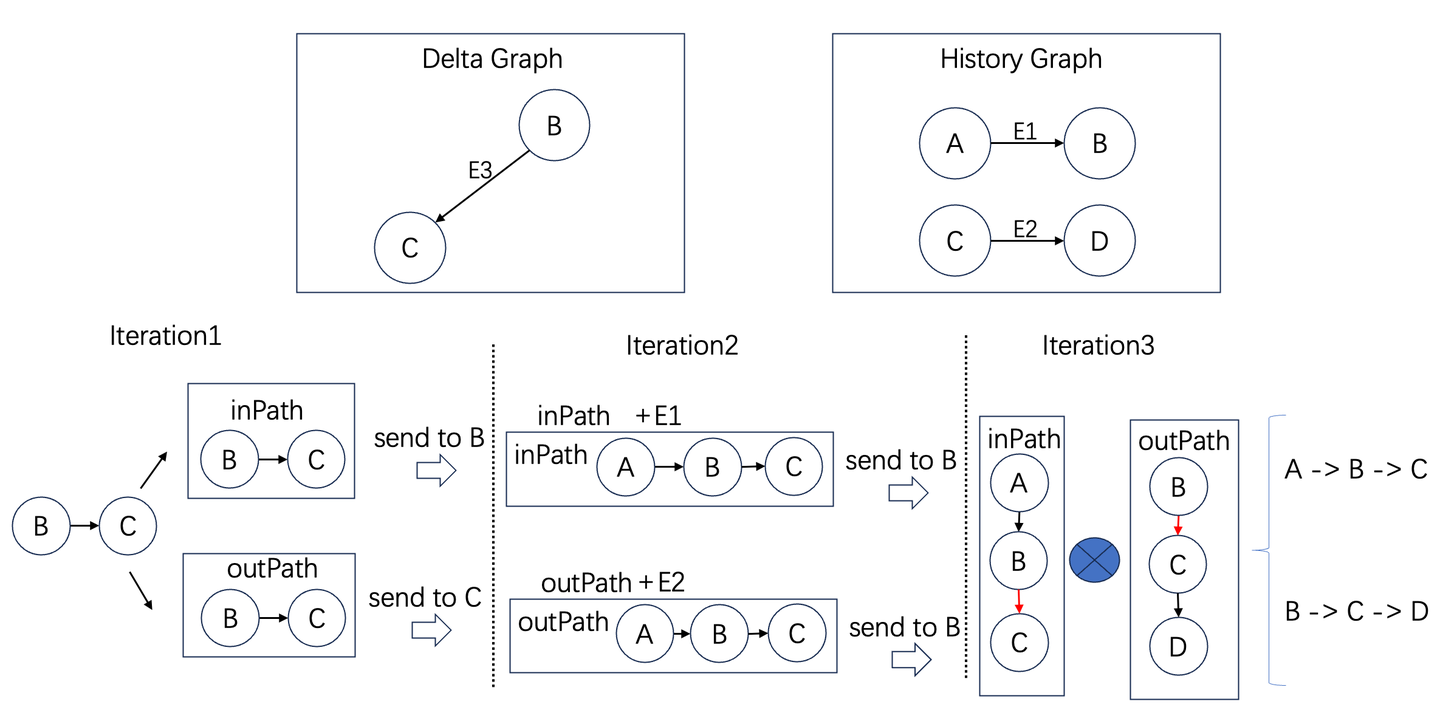
以前文中提到的k-Hop为例,增量算法如下:在第一轮迭代中,我们找到增量图中的所有边,将这些边作为初始的入向路径和出向路径,分别发送到他们的起点和终点。在后续的迭代中不断扩展入向路径和出向路径。当达到求取跳数时,将出向路径和入向路径发送给起点,在起点组合成最终结果。详细代码实现在开源仓库的IncKHopAlgorithm.java文件中。
下图是两跳场景的描述。在第一轮迭代,增量边B->C分别构建入向路径和出向路径,将他们分别发送给点B和点C。在第二轮迭代,B收到入向路径,并加上当前点的入边形成2跳入向路径,发送给点B。同样点C也收到出向路径,加上当前的出边形成2跳出向路径,发送给点B。最后一轮迭代在B点将收到的出向和入向路径整合成新增的路径。可以看到,和Flink中需要查找所有的历史关系不同,GeaFlow采用基于流图的增量图算法,计算量和图中的增量路径成正比。
上述图算法已经集成到GeaFlow的IncKHop算子中,用户可以直接通过DSL调用。
set geaflow.dsl.max.traversal=4;
set geaflow.dsl.table.parallelism=4;
CREATE GRAPH modern (
Vertex node (
id int ID
),
Edge relation (
srcId int SOURCE ID,
targetId int DESTINATION ID
)
) WITH (
storeType='rocksdb',
shardCount = 4
);
CREATE TABLE web_google_20 (
src varchar,
dst varchar
) WITH (
type='file',
geaflow.dsl.table.parallelism='4',
geaflow.dsl.column.separator='\t',
`geaflow.dsl.source.file.parallel.mod`='true',
geaflow.dsl.file.path = 'resource:///data/web-google-20',
geaflow.dsl.window.size = 8
);
INSERT INTO modern.node
SELECT cast(src as int)
FROM web_google_20
;
INSERT INTO modern.node
SELECT cast(dst as int)
FROM web_google_20
;
INSERT INTO modern.relation
SELECT cast(src as int), cast(dst as int)
FROM web_google_20;
;
CREATE TABLE tbl_result (
ret varchar
) WITH (
type='file',
geaflow.dsl.file.path='${target}'
);
USE GRAPH modern;
INSERT INTO tbl_result
CALL inc_khop(2) YIELD (ret)
RETURN ret
;
3. GeaFlow 性能测试
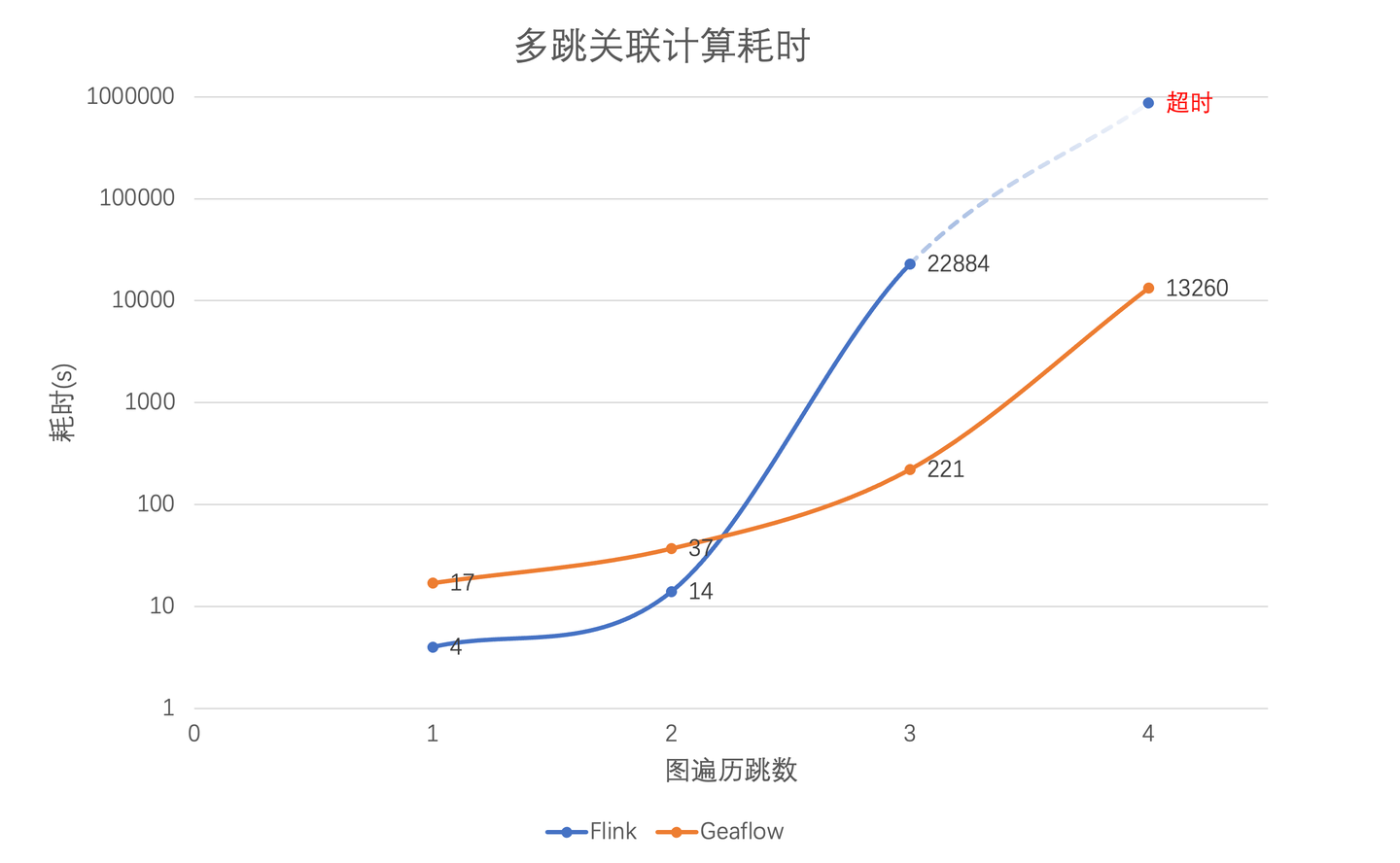
为了验证GeaFlow的流图计算性能,我们以k-Hop算法为例设计了和Flink的对比实验。我们将指定数据作为输入源输入到计算引擎中,执行k-Hop算法,并统计所有数据完成计算的时间来比较系统的性能。我们采用公开数据集web-Google.txt作为输入,实验环境为16台8核16G的服务器,分别比较了一跳、两跳、三跳、四跳关系计算的场景。
实验结果如图所示,横坐标是分别是一跳关系、两跳关系、三跳关系、四跳关系,纵坐标是处理完所有数据的耗时,采用对数指标。可以看到在一跳、两跳场景中,Flink的性能要好于GeaFlow,这是因为在一跳、两跳场景中参与join计算的数据量比较小,join需要遍历的左表和右表都很小,遍历本身耗时短,而且Flink的计算框架可以缓存join的历史计算结果。但是到了三跳、四跳场景时候,由于计算复杂度的上升,join算子需要遍历的表迅速膨胀,带来计算性能的急剧下降,甚至四跳场景超过一天也无法完成计算。而GeaFlow采用基于流图增量图算法,计算耗时只和增量路径相关,和历史的关联关系计算结果无关,所以性能明显优于Flink。
4. 总结和展望
传统的Flink等流计算引擎在计算关联关系时需要用到join算子,join算子需要遍历全量的历史数据,这使得他们在大数据关联计算场景中性能不佳。GeaFlow引擎通过支持流图计算框架,将图计算引入到流计算中,采用增量图计算的方法大大提升了实时数据的处理系性能。
目前GeaFlow项目代码已经开源,我们希望基于GeaFlow构建面向图数据的统一湖仓处理引擎,以解决多样化的大数据关联性分析诉求。同时我们也在积极筹备加入Apache基金会,丰富大数据开源生态,因此非常欢迎对图技术有浓厚兴趣同学加入社区共建。
社区中有诸多有趣的工作尚待完成,你可以从如下简单的「Good First Issue」开始,期待你加入同行。
参考链接
- GeaFlow项目地址:https://github.com/TuGraph-family/tugraph-analytics
- web-Google数据集地址:https://snap.stanford.edu/data/web-Google.html
- GeaFlow Issues:https://github.com/TuGraph-family/tugraph-analytics/issues
- 增量k-Hop算法实现源码:https://github.com/TuGraph-family/tugraph-analytics/blob/master/geaflow/geaflow-dsl/geaflow-dsl-plan/src/main/java/com/antgroup/geaflow/dsl/udf/graph/IncKHopAlgorithm.java
Graph4Stream:基于图的流计算加速的更多相关文章
- 云知声 Atlas 超算平台: 基于 Fluid + Alluxio 的计算加速实践
Fluid 是云原生基金会 CNCF 下的云原生数据编排和加速项目,由南京大学.阿里云及 Alluxio 社区联合发起并开源.本文主要介绍云知声 Atlas 超算平台基于 Fluid + Alluxi ...
- 开源一个自己造的轮子:基于图的任务流引擎GraphScheduleEngine
GraphScheduleEngine是什么: GraphScheduleEngine是一个基于DAG图的任务流引擎,不同语言编写.运行于不同机器上的模块.程序,均可以通过订阅GraphSchedul ...
- 指标统计:基于流计算 Oceanus(Flink) 实现实时 UVPV 统计
作者:吴云涛,腾讯 CSIG 高级工程师导语 | 最近梳理了一下如何用 Flink 来实现实时的 UV.PV 指标的统计,并和公司内微视部门的同事交流.然后针对该场景做了简化,并发现使用 Flink ...
- 基于Kafka的实时计算引擎如何选择?Flink or Spark?
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
- 基于Kafka的实时计算引擎如何选择?(转载)
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
- 《Kafka Stream》调研:一种轻量级流计算模式
原文链接:https://yq.aliyun.com/articles/58382 摘要: 流计算,已经有Storm.Spark,Samza,包括最近新起的Flink,Kafka为什么再自己做一套流计 ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- Storm流计算之项目篇(Storm+Kafka+HBase+Highcharts+JQuery,含3个完整实际项目)
1.1.课程的背景 Storm是什么? 为什么学习Storm? Storm是Twitter开源的分布式实时大数据处理框架,被业界称为实时版Hadoop. 随着越来越多的场景对Hadoop的MapRed ...
- 学习笔记TF067:TensorFlow Serving、Flod、计算加速,机器学习评测体系,公开数据集
TensorFlow Serving https://tensorflow.github.io/serving/ . 生产环境灵活.高性能机器学习模型服务系统.适合基于实际数据大规模运行,产生多个模型 ...
- 大数据开发实战:Spark Streaming流计算开发
1.背景介绍 Storm以及离线数据平台的MapReduce和Hive构成了Hadoop生态对实时和离线数据处理的一套完整处理解决方案.除了此套解决方案之外,还有一种非常流行的而且完整的离线和 实时数 ...
随机推荐
- java第二章数组学习
java第二章数组 数组的概念和特点 数组(Array),是多个相同类型数据按一定顺序排列的集合,并使用一个 名字命名,并通过编号的方式对这些数据进行统一管理. 特点 数组本身是引用数据类型,而数组中 ...
- c# 设置WebBrowser的UserAgent
void SuppressScriptErrors(WebBrowser webBrowser, bool hide) { webBrowser.Navigating += (s, e) => ...
- cxGrid列的OnValidate事件处理程序
procedure TForm1.cxGrid1DBTableView1AColumnPropertiesValidate(Sender: TObject; var DisplayValue: Var ...
- 再获权威认可!天翼云论文被IEEE/ACM CCGrid收录
近日,由天翼云弹性网络开拓者团队撰写的<Towards Better QoS and Lower Costs of P4 EIP Gateway at the Edge>论文被The 24 ...
- [业界方案] ClickHouse业界解决方案学习笔记
[业界方案] ClickHouse业界解决方案学习笔记 目录 [业界方案] ClickHouse业界解决方案学习笔记 0x00 摘要 0x01 简介 0x02 OLAP场景的特点 0x03 选型原因 ...
- macos修改hosts后清理dns缓存
sudo killall -HUP mDNSResponder sudo killall mDNSResponderHelper sudo dscacheutil -flushcache
- deepseek等AI工具是程序员技能发展的双刃剑
2025年,全球已有73%的程序员日常使用AI编码工具(Gartner 2025Q1数据).当我们惊叹于GitHub Copilot生成完整功能模块仅需10秒时,也需要警惕一个现象:新一代程序员在ID ...
- 流程控制之do while循环
语法 do { //代码语句}while(布尔表达式): 与while的区别 while是先判断再执行,do while是先执行再判断 循环体至少会被执行一次 实例1: package com. ...
- Vue 页面批量导入其他组件
<template> <div> <template v-for="(item) in names"> <component :is=&q ...
- redis - [06] redis-benchmark性能测试
题记部分 001 || 参数含义 002 || 测试100个并发,100000个请求 启动redis-server redis-server /etc/redis.conf 进行性能测试 redis- ...