张高兴的大模型开发实战:(六)在 LangGraph 中使用 MCP 协议
什么是 MCP 协议
MCP(Model Context Protocol,模型上下文协议)是一种专为大语言模型设计的开源通信协议,使用 MCP 可以标准化模型与外部数据源、工具或服务之间的交互。也就是说通过 MCP 协议,可以使模型具备调用外部工具的能力,比如获取数据、执行外部操作等。
MCP 协议与 API 调用的区别
到这里,可能不少同学会有疑问,MCP 协议听起来和 API 调用差不多,就算不使用 MCP 协议,也可以通过 API 调用来实现模型与外部数据源、工具或服务之间的交互。MCP 协议的意义在于为不同的 API 创建了一个通用标准,就像 USB-C 让不同设备能够通过相同的接口连接一样。
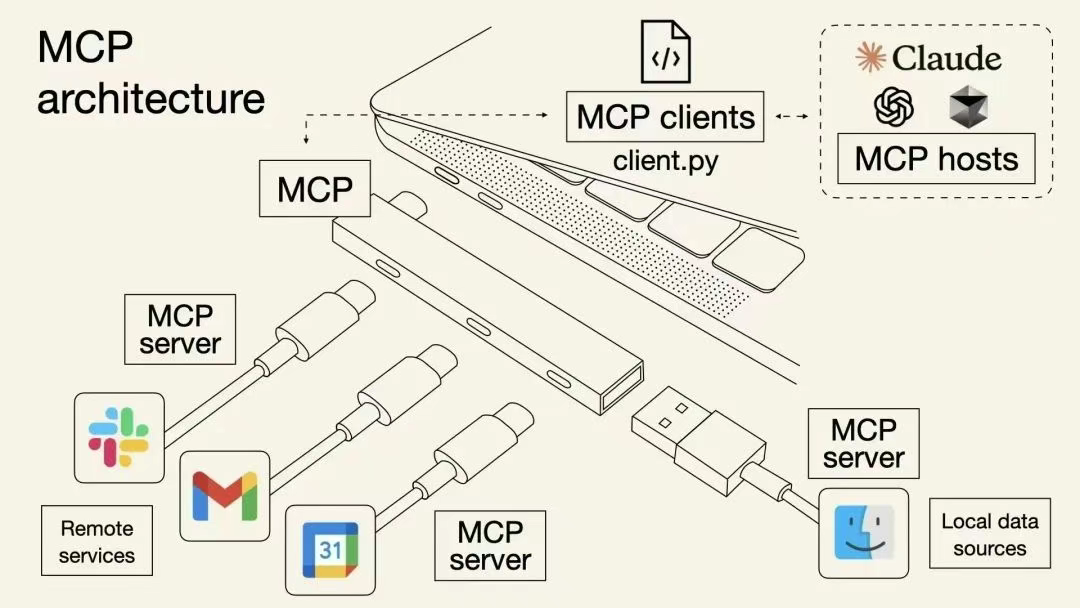
与 API 调用相比,MCP 协议具有一些特性:
- 上下文感知与会话状态管理:MCP 协议允许模型在多个请求之间保持上下文感知和会话状态管理。这意味着模型可以记住之前的对话历史、用户偏好和其他相关信息,从而提供更个性化和上下文相关的响应。API 调用通常是无状态的,每个请求都是独立的,模型无法记住之前的对话历史或上下文信息。例如,用户问“我的快递到哪了?”,MCP 会自动关联历史订单信息并返回物流状态,无需用户重复提供订单号。而 API 调用需要手动提供订单号才能查询物流状态。
- 双向实时通信:MCP 协议支持双向实时通信,允许模型和外部服务之间进行实时交互。这使得模型能够在需要时主动请求信息或执行操作,而不仅仅是被动响应请求。API 调用通常是单向的,模型只能在接收到请求时进行响应。例如,MCP 服务在处理复杂任务时,可主动反馈中间结果(如“正在查询数据库,请稍候”)。
- 动态工具发现与集成:MCP 协议允许模型动态发现和集成新的工具或服务,而无需修改代码或重新部署。这使得模型能够灵活地适应新的需求和环境。API 调用通常是静态的,模型只能使用预先定义的 API 接口。例如,用户问“帮我订机票”,MCP 会自动识别可用的航班查询工具和支付接口,无需提前配置。而 API 调用需要单独开发调用机票查询和支付的接口。
MCP 协议的连接方式
MCP 协议通常使用两种方式建立连接。
SSE(Server-Sent Events)
SSE 是一种基于 HTTP 的通信协议,它使用单向连接,从 MCP 服务端到客户端发送数据流。SSE 适用于需要实时更新的场景,例如聊天应用、股票行情等。在通过 SSE 连接时,你会用到类似 http://localhost:8001/sse 的 URL 地址,因此 SSE 连接更像传统的网络 API 调用。
stdio(标准输入输出)
stdio 通过标准输入输出流进行通信,通常 MCP 服务端是运行在本地的,适用于本地开发和调试。
在 LangGraph 中使用 MCP 协议
下面通过一个最简单的实例来演示如何在 LangGraph 中使用 MCP 协议。项目文件结构如下:
.
├── mcp_servers # MCP 服务器
│ ├── math.py # 数学计算
│ └── weather.py # 天气查询
└── main.py # 主程序
首先安装所需要的包。
pip install langchain-mcp-adapters mcp
然后在 mcp_servers 目录下创建两个 MCP 服务。math.py 使用 stdio 连接,实现了加法和乘法运算,用于解决数学计算问题。weather.py 使用 SSE 连接,实现了天气和时间查询功能。
math.py 代码如下:
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("Math")
@mcp.tool()
def add(a: int, b: int) -> int:
return a + b
@mcp.tool()
def multiply(a: int, b: int) -> int:
return a * b
if __name__ == "__main__":
mcp.run(transport="stdio")
weather.py 代码如下:
from datetime import datetime
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("Weather", port=8001)
@mcp.tool()
def get_weather(location: str) -> str:
return "晴天"
@mcp.tool()
def get_time() -> str:
return datetime.now().strftime('%Y-%m-%d %H:%M:%S')
if __name__ == "__main__":
mcp.run(transport="sse")
接着在 main.py 中引用相关的包。
import asyncio
from contextlib import asynccontextmanager
from typing import Annotated, TypedDict
from langchain.prompts import ChatPromptTemplate
from langchain_mcp_adapters.client import MultiServerMCPClient
from langgraph.graph import END, START, StateGraph
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode, tools_condition
from langchain_ollama import ChatOllama
编写 load_mcp_tools() 方法,将 MCP 服务转换成 LangChain 中的工具(langchain_core.tools)。
@asynccontextmanager
async def load_mcp_tools():
"""加载 MCP 工具"""
async with MultiServerMCPClient(
{
"math": {
"command": "python",
"args": ["mcp_servers/math.py"],
"transport": "stdio",
},
"weather": {
"url": f"http://localhost:8001/sse",
"transport": "sse",
}
}
) as client:
yield client.get_tools()
加载模型、设置提示词以及定义 LangGraph 图的状态。
model = ChatOllama(model="qwen2.5:7b")
prompt = ChatPromptTemplate.from_template("You are an assistant for question-answering tasks. If necessary, external tools can also be called to answer. If you don't know the answer, just say that you don't know. Answer in Chinese.\n\nQuestion: {question}")
class State(TypedDict):
messages: Annotated[list, add_messages]
编写 create_graph() 方法,创建一个最简单的图,仅包含一个对话节点和一个工具节点。在 LangGraph 中调用工具,需要将工具转换成工具节点 ToolNode,工具节点会自动处理工具的调用和结果的返回。
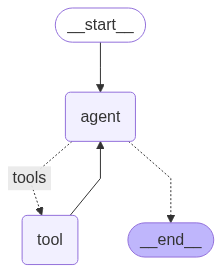
@asynccontextmanager
async def create_graph():
"""创建图"""
def agent(state: State):
messages = state["messages"]
state["messages"] = llm_with_tool.invoke(messages)
return state
async with load_mcp_tools() as tools: # 获取 MCP 工具
print(f"可用的 MCP 工具:{[tool.name for tool in tools]}")
llm_with_tool = prompt | model.bind_tools(tools) # 绑定工具并创建模型调用链
graph_builder = StateGraph(State)
graph_builder.add_node(agent)
# 添加工具节点
graph_builder.add_node("tool", ToolNode(tools))
graph_builder.add_edge(START, "agent")
graph_builder.add_conditional_edges(
"agent",
tools_condition, # LangGraph 中预定义的方法,用于判断是否需要调用工具
{
"tools": "tool",
END: END,
},
)
graph_builder.add_edge("tool", "agent")
yield graph_builder.compile()
最后编写主程序,运行观察一下结果。
async def main():
async with create_graph() as graph:
result = await graph.ainvoke({"messages": "徐州天气怎么样"})
print(result["messages"][-1].content)
result = await graph.ainvoke({"messages": "现在几点了"})
print(result["messages"][-1].content)
result = await graph.ainvoke({"messages": "(3+5)x12等于多少"})
print(result["messages"][-1].content)
if __name__ == "__main__":
asyncio.run(main())
可以看到输出结果如下:
可用的 MCP 工具:['add', 'multiply', 'get_weather', 'get_time']
徐州现在的天气是晴天。
现在的时刻是17:22:15。
(3+5)×12等于96。
张高兴的大模型开发实战:(六)在 LangGraph 中使用 MCP 协议的更多相关文章
- 大数据开发实战:HDFS和MapReduce优缺点分析
一. HDFS和MapReduce优缺点 1.HDFS的优势 HDFS的英文全称是 Hadoop Distributed File System,即Hadoop分布式文件系统,它是Hadoop的核心子 ...
- 大数据开发实战:Stream SQL实时开发三
4.聚合操作 4.1.group by 操作 group by操作是实际业务场景(如实时报表.实时大屏等)中使用最为频繁的操作.通常实时聚合的主要源头数据流不会包含丰富的上下文信息,而是经常需要实时关 ...
- 大数据开发实战:Stream SQL实时开发一
1.流计算SQL原理和架构 流计算SQL通常是一个类SQL的声明式语言,主要用于对流式数据(Streams)的持续性查询,目的是在常见流计算平台和框架(如Storm.Spark Streaming.F ...
- 大数据开发实战:Spark Streaming流计算开发
1.背景介绍 Storm以及离线数据平台的MapReduce和Hive构成了Hadoop生态对实时和离线数据处理的一套完整处理解决方案.除了此套解决方案之外,还有一种非常流行的而且完整的离线和 实时数 ...
- 大数据开发实战:Stream SQL实时开发二
1.介绍 本节主要利用Stream SQL进行实时开发实战,回顾Beam的API和Hadoop MapReduce的API,会发现Google将实际业务对数据的各种操作进行了抽象,多变的数据需求抽象为 ...
- 大数据开发实战:Storm流计算开发
Storm是一个分布式.高容错.高可靠性的实时计算系统,它对于实时计算的意义相当于Hadoop对于批处理的意义.Hadoop提供了Map和Reduce原语.同样,Storm也对数据的实时处理提供了简单 ...
- 大数据开发实战:Hadoop数据仓库开发实战
1.Hadoop数据仓库架构设计 如上图. ODS(Operation Data Store)层:ODS层通常也被称为准备区(Staging area),它们是后续数据仓库层(即基于Kimball维度 ...
- 大数据开发实战:Hive优化实战3-大表join大表优化
5.大表join大表优化 如果Hive优化实战2中mapjoin中小表dim_seller很大呢?比如超过了1GB大小?这种就是大表join大表的问题.首先引入一个具体的问题场景,然后基于此介绍各自优 ...
- 大数据开发实战:Hive优化实战2-大表join小表优化
4.大表join小表优化 和join相关的优化主要分为mapjoin可以解决的优化(即大表join小表)和mapjoin无法解决的优化(即大表join大表),前者相对容易解决,后者较难,比较麻烦. 首 ...
- 大数据开发实战:Hive优化实战1-数据倾斜及join无关的优化
Hive SQL的各种优化方法基本 都和数据倾斜密切相关. Hive的优化分为join相关的优化和join无关的优化,从项目的实际来说,join相关的优化占了Hive优化的大部分内容,而join相关的 ...
随机推荐
- Maven - 项目的JDK编译level是1.5,修改不掉??
背景 idea中的maven项目,父项目和子项目的Project Structure的language level都是1.5,怎么修改为8?尝试修改并应用后会失效,还是会自动恢复为1.5. 1.S ...
- Linux用户登录失败锁定策略
1.账户锁定策略介绍 在Linux系统中,为了提高系统安全性,防止暴力破解攻击,我们可以通过配置PAM(Pluggable Authentication Modules)模块来限制登录失败次数并锁定用 ...
- Python基础--python数据结构(字符串、列表和元组)
前言 !!!注意:本系列所写的文章全部是学习笔记,来自于观看视频的笔记记录,防止丢失.观看的视频笔记来自于:哔哩哔哩武沛齐老师的视频:2022 Python的web开发(完整版) 入门全套教程,零基础 ...
- Unable to Connect: sPort: 0 C# ServiceStack.Redis 访问 redis
需求: 对数据库中的不断抓取的文章进行缓存,因此需要定时访问数据,写入缓存中 在捕获到的异常日志发现错误:Unable to Connect: sPort: 0 使用的访问方式是线程池的方式:Poo ...
- 带大家做了个 AI 项目,没想到这么简单!
大家好,我是程序员鱼皮,现在已经是全民 AI 时代了,咱们程序员更要想办法榨干 AI,把 AI 利用起来.前几天我一时兴起,直播用 2 多个小时的时间,从需求分析开始,带大家做了一个 AI 海龟汤游戏 ...
- Pydantic多态模型:用鉴别器构建类型安全的API接口
title: Pydantic多态模型:用鉴别器构建类型安全的API接口 date: 2025/3/20 updated: 2025/3/20 author: cmdragon excerpt: Py ...
- MySQL-对Change Buffer的理解
Change Buffer的处理过程 对非唯一的普通索引的新增或更新操作,如果索引B+树的需要新增或更新的数据页不在内存中,则直接更新change buffer,等到后面需要使用这个数据页(真正读到内 ...
- dxSpreadSheet的报表demo-关于设计报表模板的Datagroup问题
看随机的报表DEMO,主从表也好,数据分组也好.呈现的非常到位. 问题:可是自己在实现数据分组时,一旦设定分组字段就出现了混乱的数据记录. 问题的原因: 看一下一个报表页面设计时需要理清的概念. 页头 ...
- 行为识别TSM训练ucf101数据集
序言 最近有个行为检测的需求,打算用行为识别做,纯小白入这个方向,啃了两周的TSM原理和源码,训练好自己的数据集后,发现好像没法应用到自己的需求场景??玛德!算了,还是要记录一下.原理就没别要讲了,网 ...
- ubuntu 22.04安装NFS
一.概述 1. 定义 NFS(Network File System)是一种分布式文件系统协议,最初由 Sun Microsystems 开发,并于1984年发布.它允许不同主机通过网络共享文件和目录 ...