Go并发编程实践
前言
并发编程一直是Golang区别与其他语言的很大优势,也是实际工作场景中经常遇到的。近日笔者在组内分享了我们常见的并发场景,及代码示例,以期望大家能在遇到相同场景下,能快速的想到解决方案,或者是拿这些方案与自己实现的比较,取长补短。现整理出来与大家共享。
简单并发场景
很多时候,我们只想并发的做一件事情,比如测试某个接口的是否支持并发。那么我们就可以这么做:
func RunScenario1() {
count := 10
var wg sync.WaitGroup
for i := 0; i < count; i++ {
wg.Add(1)
go func(index int) {
defer wg.Done()
doSomething(index)
}(i)
}
wg.Wait()
}
使用goroutine来实现异步,使用WaitGroup来等待所有goroutine结束。这里要注意的是要正确释放WaitGroup的counter(在goroutine里调用Done()方法)。
但此种方式有个弊端,就是当goroutine的量过多时,很容易消耗完客户端的资源,导致程序表现不佳。
规定时间内的持续并发模型
我们仍然以测试某个后端API接口为例,如果我们想知道这个接口在持续高并发情况下是否有句柄泄露,这种情况该如何测试呢?
这种时候,我们需要能控制时间的高并发模型:
func RunScenario2() {
timeout := time.Now().Add(time.Second * time.Duration(10))
n := runtime.NumCPU()
waitForAll := make(chan struct{})
done := make(chan struct{})
concurrentCount := make(chan struct{}, n)
for i := 0; i < n; i++ {
concurrentCount <- struct{}{}
}
go func() {
for time.Now().Before(timeout) {
<-done
concurrentCount <- struct{}{}
}
waitForAll <- struct{}{}
}()
go func() {
for {
<-concurrentCount
go func() {
doSomething(rand.Intn(n))
done <- struct{}{}
}()
}
}()
<-waitForAll
}
上面的代码里,我们通过一个buffered channel来控制并发的数量(concurrentCount),然后另起一个channel来周期性的发起新的任务,而控制的条件就是 time.Now().Before(timeout),这样当超过规定的时间,waitForAll 就会得到信号,而使整个程序退出。
这是一种实现方式,那么还有其他的方式没?我们接着往下看。
基于大数据量的并发模型
前面说的基于时间的并发模型,那如果只知道数据量很大,但是具体结束时间不确定,该怎么办呢?
比如,客户给了个几TB的文件列表,要求把这些文件从存储里删除。再比如,实现个爬虫去爬某些网站的所有内容。
而解决此类问题,最常见的就是使用工作池模式了(Worker Pool)。以删文件为例,我们可以简单这样来处理:
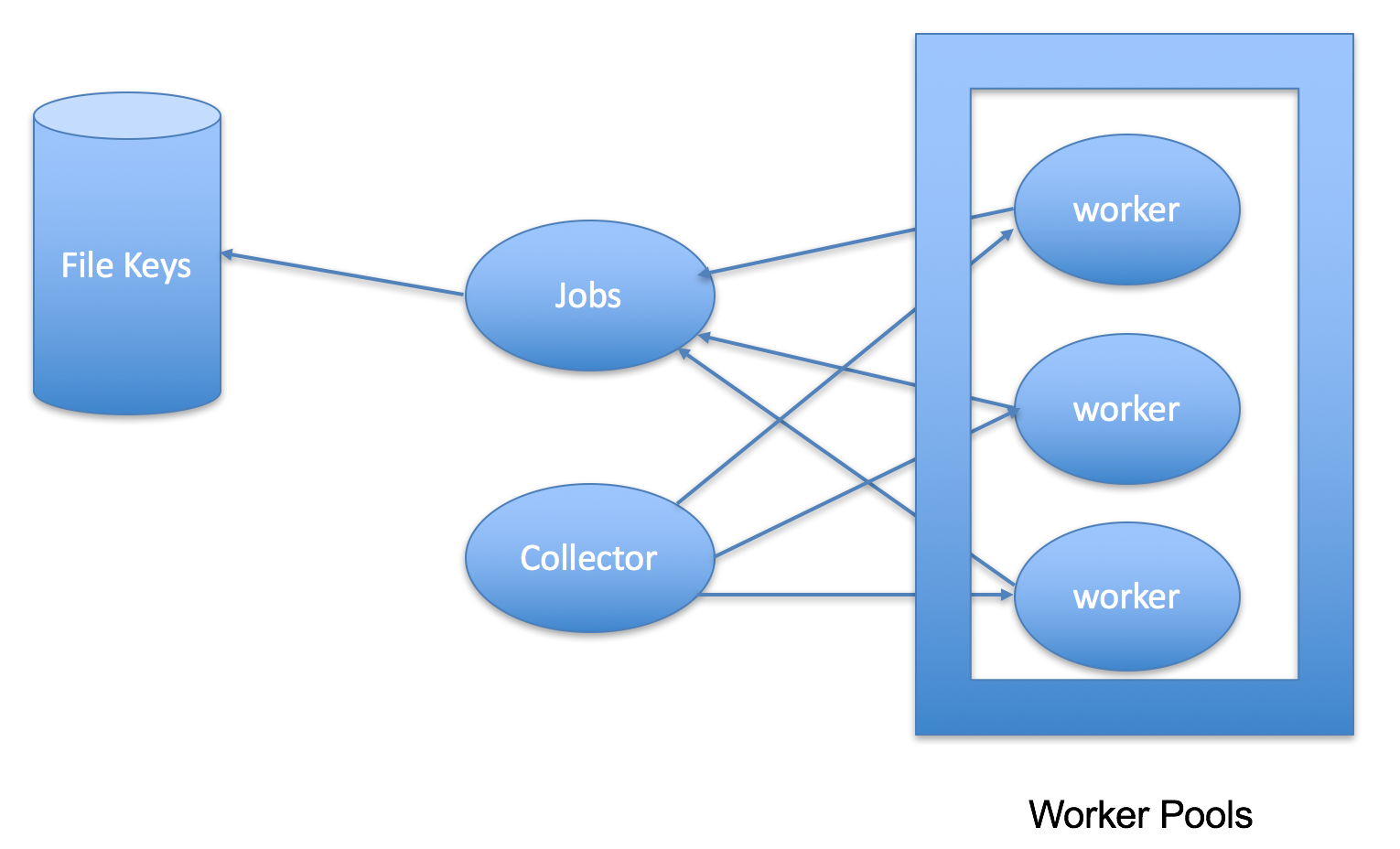
- Jobs - 可以从文件列表里读取文件,初始化为任务,然后发给worker
- Worker - 拿到任务开始做事
- Collector - 收集worker处理后的结果
- Worker Pool - 控制并发的数量
虽然这只是个简单Worker Pool模型,但已经能满足我们的需求:
func RunScenario3() {
numOfConcurrency := runtime.NumCPU()
taskTool := 10
jobs := make(chan int, taskTool)
results := make(chan int, taskTool)
var wg sync.WaitGroup
// workExample
workExampleFunc := func(id int, jobs <-chan int, results chan<- int, wg *sync.WaitGroup) {
defer wg.Done()
for job := range jobs {
res := job * 2
fmt.Printf("Worker %d do things, produce result %d \n", id, res)
time.Sleep(time.Millisecond * time.Duration(100))
results <- res
}
}
for i := 0; i < numOfConcurrency; i++ {
wg.Add(1)
go workExampleFunc(i, jobs, results, &wg)
}
totalTasks := 100 // 本例就要从文件列表里读取
wg.Add(1)
go func() {
defer wg.Done()
for i := 0; i < totalTasks; i++ {
n := <-results
fmt.Printf("Got results %d \n", n)
}
close(results)
}()
for i := 0; i < totalTasks; i++ {
jobs <- i
}
close(jobs)
wg.Wait()
}
在Go里,分发任务,收集结果,我们可以都交给Channel来实现。从实现上更加的简洁。
仔细看会发现,本模型也是适用于按时间来控制并发。只要把totalTask的遍历换成时间控制就好了。
等待异步任务执行结果
goroutine和channel的组合在实际编程时经常会用到,而加上Select更是无往而不利。
func RunScenario4() {
sth := make(chan string)
result := make(chan string)
go func() {
id := rand.Intn(100)
for {
sth <- doSomething(id)
}
}()
go func() {
for {
result <- takeSomthing(<-sth)
}
}()
select {
case c := <-result:
fmt.Printf("Got result %s ", c)
case <-time.After(time.Duration(30 * time.Second)):
fmt.Errorf("指定时间内都没有得到结果")
}
}
在select的case情况,加上time.After()模型可以让我们在一定时间范围内等待异步任务结果,防止程序卡死。
定时反馈异步任务结果
上面我们说到持续的压测某后端API,但并未实时收集结果。而很多时候对于性能测试场景,实时的统计吞吐率,成功率是非常有必要的。
func RunScenario5() {
concurrencyCount := runtime.NumCPU()
for i := 0; i < concurrencyCount; i++ {
go func(index int) {
for {
doUploadMock()
}
}(i)
}
t := time.NewTicker(time.Second)
for {
select {
case <-t.C:
// 计算并打印实时数据
}
}
}
这种场景就需要使用到Ticker,且上面的Example模型还能控制并发数量,也是非常实用的方式。
知识点总结
上面我们共提到了五种并发模式:
- 简单并发模型
- 规定时间内的持续并发模型
- 基于大数据量的持续并发模型
- 等待异步任务结果模型
- 定时反馈异步任务结果模型
归纳下来其核心就是使用了Go的几个知识点:Goroutine, Channel, Select, Time, Timer/Ticker, WaitGroup. 若是对这些不清楚,可以自行Google之。
另完整的Example 代码可以参考这里:https://github.com/jichangjun/golearn/blob/master/src/carlji.com/experiments/concurrency/main.go
使用方式: go run main.go <场景>
比如 :
参考文档
这篇是Google官方推荐学习Go并发的资料,从初学者到进阶,内容非常丰富,且权威。
Contact me ?
Email: jinsdu@outlook.com
Blog: http://www.cnblogs.com/jinsdu/
Github: https://github.com/CarlJi
童鞋,如果觉得本文还算用心,还算有用,何不点个赞呢(⊙o⊙)?
Go并发编程实践的更多相关文章
- [Java 并发] Java并发编程实践 思维导图 - 第一章 简单介绍
阅读<Java并发编程实践>一书后整理的思维导图.
- [Java 并发] Java并发编程实践 思维导图 - 第二章 线程安全性
依据<Java并发编程实践>一书整理的思维导图.
- 并发编程实践五:ReentrantLock
ReentrantLock是一个可重入的相互排斥锁,实现了接口Lock,和synchronized相比,它们提供了同样的功能.但ReentrantLock使用更灵活.功能更强大,也更复杂.这篇文章将为 ...
- 并发编程实践三:Condition
Condition实例始终被绑定到一个锁(Lock)上.Lock替代了Java的synchronized方法,而Condition则替代了Object的监视器方法,包含wait.notify和noti ...
- 读Java并发编程实践中,向已有线程安全类添加功能--客户端加锁实现示例
在Java并发编程实践中4.4中提到向客户端加锁的方法.此为验证示例,写的不好,但可以看出结果来. package com.blackbread.test; import java.util.Arra ...
- [Java 并发] Java并发编程实践 思维导图 - 第四章 对象的组合
依据<Java并发编程实践>一书整理的思维导图. 第一部分: 第二部分:
- Java并发编程实践
最近阅读了<Java并发编程实践>这本书,总结了一下几个相关的知识点. 线程安全 当多个线程访问某个类时,不管运行时环境采用何种调度方式或者这些线程将如何交替执行,并且在主调代码中不需要任 ...
- java并发编程实践笔记
文章转自:http://kenwublog.com/java-concurrency-in-practise-note 1, 保证线程安全的三种方法 :a, 不要跨线程访问共享变量b, 使共享变量是 ...
- 笔记:java并发编程实践1
Java 5.0 adds ConcurrentHashMap, a replacement for synchronized hash-based Map implementations, and ...
随机推荐
- Trim(',')的作用去除最有一个','
public bool XMLDataImport() { List<string> sqllist = new List<string>(); ...
- springMVC入门配置及helloworld实例
1. 新建web project 2. 往lib里copy必须的jar 3. 改写web.xml <?xml version="1.0" encoding="UTF ...
- (简单) POJ 2750 Potted Flower,环+线段树。
Description The little cat takes over the management of a new park. There is a large circular statue ...
- mysql管理 ------查看 MySQL 数据库中每个表占用的空间大小
如果想知道MySQL数据库中每个表占用的空间.表记录的行数的话,可以打开MySQL的 information_schema 数据库.在该库中有一个 TABLES 表,这个表主要字段分别是: TABLE ...
- Spark 的combineByKey函数
在Spark中有许多聚类操作是基于combineByKey的,例如group那个家族的操作等.所以combineByKey这个函数也是比较重要,所以下午花了点时间看来下这个函数.也参考了http:// ...
- iOS 开发之动画篇 - 从 UIView 动画说起
毋庸置疑的:在iOS开发中,制作动画效果是最让开发者享受的环节之一.一个设计严谨.精细的动画效果能给用户耳目一新的效果,吸引他们的眼光 —— 这对于app而言是非常重要的. 本文作为动画文集的第一篇, ...
- jquery遍历二维数组
function eachTowArray() { var ar = [[1,2,3],[4,5,6],[7,8,9]]; var result=""; //结果存放变量 ...
- ajax修改密码
<div>用户名:<input type="text" id="uid" /><span id="tt" st ...
- Struts2标签遍历List<Map<String,String>>
<s:if test="resultList != null && resultList.size() > 0"> <s:iterator ...
- Oracle数据库中的函数
1.随机数函数:DBMS_RANDOM.RANDOM )) FROM DUAL; --产生一个100以内的随机数 *dbms_random.value) FROM dual; --产生一个100-10 ...