Hadoop单机和伪分布式安装
本教程为单机版+伪分布式的Hadoop,安装过程写的有些简单,只作为笔记方便自己研究Hadoop用。
环境
| 操作系统 | Centos 6.5_64bit | |
| 本机名称 | hadoop001 | |
| 本机IP | 192.168.3.128 | |
| JDK | jdk-8u40-linux-x64.rpm | 点此下载 |
| Hadoop | 2.7.3 | 点此下载 |
Hadoop 有两个主要版本,Hadoop 1.x.y 和 Hadoop 2.x.y 系列,比较老的教材上用的可能是 0.20 这样的版本。Hadoop 2.x 版本在不断更新,本教程均可适用。如果需安装 0.20,1.2.1这样的版本,本教程也可以作为参考,主要差别在于配置项,配置请参考官网教程或其他教程。
单机安装
一、创建Hadoop用户
为了方便之后的操作,不干扰其他用户,咱们先建一个单独的Hadoop用户并设置密码[root@localhost ~]# useradd -m hadoop -s /bin/bash
[root@localhost ~]# passwd hadoop
Changing password for user hadoop.
New password:
BAD PASSWORD: it is based on a dictionary word
BAD PASSWORD: is too simple
Retype new password:
passwd: all authentication tokens updated successfully.
//还要修改host文件
[root@hadoop001 .ssh]# vim /etc/hosts
192.168.3.128 hadoop001
二、创建SSH无密码登录
单节点、集群都需要用到SSH登录,方便无障碍登录和通讯。
[hadoop@hadoop001 .ssh]$ cd ~/.ssh/
[hadoop@hadoop001 .ssh]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): // 回车
Enter passphrase (empty for no passphrase): //回车
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
97:75:b0:56:3b:57:8c:1f:b1:51:b6:d9:9f:77:f3:cf hadoop@hadoop001
The key's randomart image is:
+--[ RSA 2048]----+
| . .=*|
| +.+O|
| + +=+|
| + . o+|
| S o o+|
| . =|
| .|
| ..|
| E|
+-----------------+
[hadoop@hadoop001 .ssh]$ cat ./id_rsa.pub >> ./authorized_keys
[hadoop@hadoop001 .ssh]$ ll
total 12
-rw-rw-r--. 1 hadoop hadoop 398 Mar 14 14:09 authorized_keys
-rw-------. 1 hadoop hadoop 1675 Mar 14 14:09 id_rsa
-rw-r--r--. 1 hadoop hadoop 398 Mar 14 14:09 id_rsa.pub
[hadoop@hadoop001 .ssh]$ chmod 644 authorized_keys
[hadoop@hadoop001 .ssh]$ ssh hadoop001
Last login: Tue Mar 14 14:11:52 2017 from hadoop001
这样的话本机免密码登录已经配置成功了。
三、安装JDK
rpm -qa |grep java // 卸载所有出现的包
rpm -e --nodeps java-x.x.x-gcj-compat-x.x.x.x-40jpp.115 // 执行jdk-8u40-linux-x64.rpm包,不用配环境变量,不过需要加JAVA_HOME echo "JAVA_HOME"=/usr/java/latest/ >> /etc/environment
测试安装成功与否
[hadoop@hadoop001 soft]$ java -version
java version "1.8.0_40"
Java(TM) SE Runtime Environment (build 1.8.0_40-b25)
Java HotSpot(TM) 64-Bit Server VM (build 25.40-b25, mixed mode)
四、安装Hadoop
//安装到opt目录下
[root@hadoop001 soft]# tar -zxf hadoop-2.7.3.tar.gz -C /opt/
修改目录权限
[root@hadoop001 opt]# ll
total 20
drwxr-xr-x. 9 root root 4096 Aug 17 2016 hadoop-2.7.3 [root@hadoop001 opt]# chown -R hadoop:hadoop hadoop-2.7.3/
[root@hadoop001 opt]# ll
total 20
drwxr-xr-x. 9 hadoop hadoop 4096 Aug 17 2016 hadoop-2.7.3
添加环境变量
[hadoop@hadoop001 bin]$ vim ~/.bash_profile
# hadoop
HADOOP_HOME=/opt/hadoop-2.7.3 PATH=$PATH:$HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export PATH
测试安装成功与否
[hadoop@hadoop001 bin]$ hadoop
Usage: hadoop [--config confdir] [COMMAND | CLASSNAME]
CLASSNAME run the class named CLASSNAME
or
where COMMAND is one of:
fs run a generic filesystem user client
version print the version
jar <jar> run a jar file
note: please use "yarn jar" to launch
YARN applications, not this command.
checknative [-a|-h] check native hadoop and compression libraries availability
distcp <srcurl> <desturl> copy file or directories recursively
archive -archiveName NAME -p <parent path> <src>* <dest> create a hadoop archive
classpath prints the class path needed to get the
credential interact with credential providers
Hadoop jar and the required libraries
daemonlog get/set the log level for each daemon
trace view and modify Hadoop tracing settings Most commands print help when invoked w/o parameters.
单词统计
创建输入文件夹input放输入文件
[root@hadoop001 /]# mkdir -p /data/input //创建测试文件word.txt [root@hadoop001 /]# vim word.txt Hi, This is a test file.
Hi, I love hadoop and love you . //授权
[root@hadoop001 /]# chown hadoop:hadoop /data/input/word.txt //运行单词统计
[hadoop@hadoop001 hadoop-2.7.3]$ hadoop jar /opt/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /data/input/word.txt /data/output/ //...中间日志省略
17/03/14 15:22:44 INFO mapreduce.Job: Counters: 30
File System Counters
FILE: Number of bytes read=592316
FILE: Number of bytes written=1165170
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=3
Map output records=14
Map output bytes=114
Map output materialized bytes=127
Input split bytes=90
Combine input records=14
Combine output records=12
Reduce input groups=12
Reduce shuffle bytes=127
Reduce input records=12
Reduce output records=12
Spilled Records=24
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=0
Total committed heap usage (bytes)=525336576
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=59
File Output Format Counters
Bytes Written=85
执行成功,到output目录下看结果
[hadoop@hadoop001 output]$ vim part-r-00000
. 1
Hi, 2
I 1
This 1
a 1
and 1
file. 1
hadoop 1
is 1
love 2
test 1
you 1
【至此单机安装完成】
伪分布式安装
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /$HADOOP_HOME/etc/hadoop/ 中,伪分布式至少需要修改2个配置文件 core-site.xml 和 hdfs-site.xml 。
Hadoop的配置文件是 xml 格式,每个配置以声明 property 的 name 和 value 的方式来实现。
修改core-site.xml
<configuration> <property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop-2.7.3/tmp</value>
<description>Abase for other temporary directories.</description>
</property> <property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:9000</value>
</property> </configuration>
修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property> <property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/dfs/name</value>
</property> <property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/dfs/data</value>
</property>
</configuration>
伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(官方教程如此),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
修改mapred-site.xml
文件默认不存在,只有一个模板,复制一份
[hadoop@hadoop001 hadoop]$ cp mared-site.xml.template mared-site.xml
configration下添加
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
修改yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop001:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop001:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop001:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop001:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop001:8088</value>
</property>
格式化namenode
[hadoop@hadoop001 hadoop]$ hdfs namenode –format
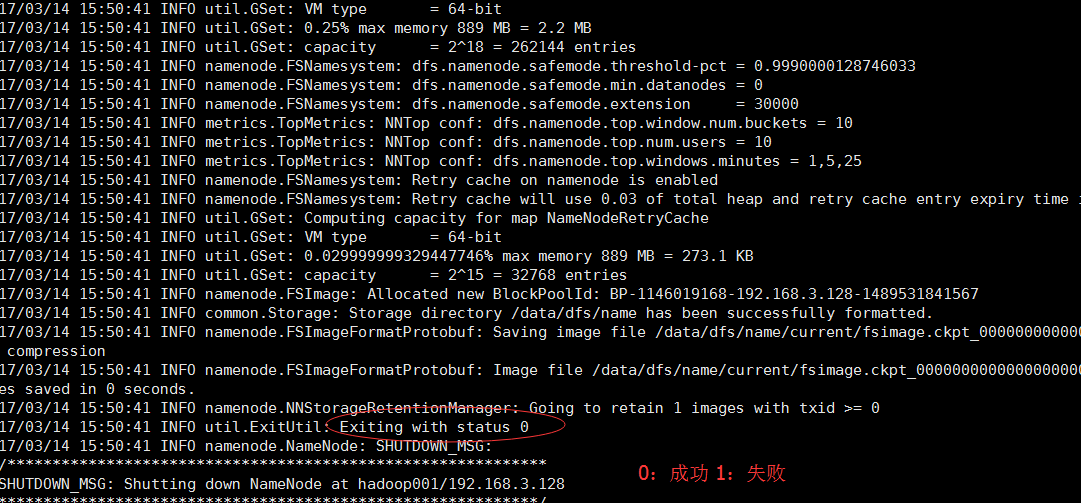
好,格式化后启动namenode和datanode的守护进程,发现报错

设置一下hadoop-env.sh文件,把${JAVA_HOME}替换成绝对路径
[hadoop@hadoop001 hadoop-2.7.3]$ vim etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_40/
重新启动start-dfs.sh + start-yarn.sh 或者 start-all.sh
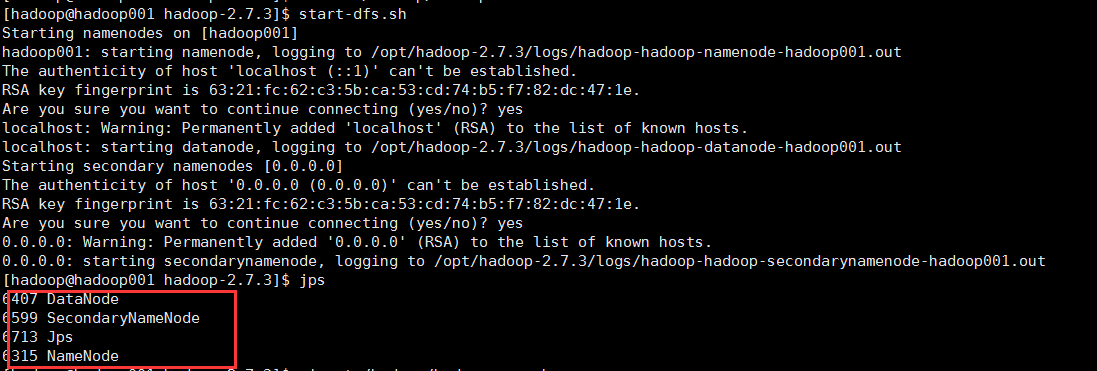
守护进程已经成功启动了,证明配置伪分布式成功。
远程访问http://192.168.3.128:50070,发现无法访问,本地可以访问。
原因其实是修改了hadoop-env.sh 后没有重启格式化namenode,重新格式化后发现datanode启动不起来了。
最后,删除datanode数据文件下VERSION文件,格式化后重启就可以了。
Hadoop单机和伪分布式安装的更多相关文章
- hadoop2.7.2单机与伪分布式安装
环境相关 系统:CentOS 6.8 64位 jdk:1.7.0_79 hadoop:hadoop 2.7.2 安装java环境 详见:linux中搭建java开发环境 创建hadoop用户 # 以r ...
- ZooKeeper:win7上安装单机及伪分布式安装
zookeeper是一个为分布式应用所设计的分布式的.开源的调度服务,它主要用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用,协调及其管理的难度,提高性能的分布式服务. 本章的目的:如何 ...
- Hadoop单机模式/伪分布式模式/完全分布式模式
一.Hadoop的三种运行模式(启动模式) 一.单机(非分布式)模式 这种模式在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统. 默认情况下,Hadoop即处于该模式,用于开发 ...
- Hadoop单机、伪分布式、分布式集群搭建
JDK安装 设置hostname [root@bigdata111 ~]# vi /etc/hostname 设置机器hosts [root@bigdata111 ~]# vi /etc/hosts ...
- hadoop 单机模式 伪分布式 完全分布式区别
1.单机(非分布式)模式 这种模式在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统,一般仅用于本地MR程序的调试 2.伪分布式运行模式 这种模式也是在一台单机上运行,但用不同的 ...
- hadoop+zookeeper+hbase伪分布式安装
基本安装步骤 安装包下载 从大数据组件下载地址下载以下组件安装包 hadoop-2.6.0-cdh5.6.0.tar.gz hbase-1.0.0-cdh5.6.0.tar.gz zookeeper- ...
- hadoop最简伪分布式安装
本次安装运行过程使用的是Ubuntu16.04 64位+Hadoop2.5.2+jdk1.7.0_75 Notice: Hadoop2.5.2版本默认只支持64位系统 使用的jdk可以为1.7和1.8 ...
- 网站用户行为分析——Hadoop的安装与配置(单机和伪分布式)
Hadoop安装方式 Hadoop的安装方式有三种,分别是单机模式,伪分布式模式,伪分布式模式,分布式模式. 单机模式:Hadoop默认模式为非分布式模式(本地模式),无需进行其他配置即可运行.非分布 ...
- 第二章 伪分布式安装hadoop hbase
安装单机模式的hadoop无须配置,在这种方式下,hadoop被认为是一个单独的java进程,这种方式经常用来调试.所以我们讲下伪分布式安装hadoop. 我们继续上一章继续讲解,安装完先试试SSH装 ...
随机推荐
- pureMVC简单示例及其原理讲解三(View层)
本篇说的是View层,即视图层,在本示例中包括两个部分:MXML文件,即可视控件:Mediator. 可视控件 可视控件由UserForm.mxml(图1)和UserList.mxml(图2)两个文件 ...
- web下c#用jquery.tmpl.min.js插件实现分页查询_yginuo
背景:webform或者mvc下实现插件快速分页 ps:我这里用的mvc开发的,数据库连接.用的ADO.NET实体数据模型 此案例下载地址(内含需要用到的一个插件与数据库):http://downlo ...
- JUC学习笔记--JUC中并发工具类
JUC中并发工具类 CountDownLatch CountDownLatch是我目前使用比较多的类,CountDownLatch初始化时会给定一个计数,然后每次调用countDown() 计数减1, ...
- 支付宝ios支付请求Java服务端签名报的一个错(ALI40247) 原创
今天做app的支付宝支付,遇到些问题,以前做支付宝支付签名都是直接在客户端App进行,今天下了最新版本ios的支付宝支付demo,运行demo时底部有红色的显眼字体,告知用户签名必须在服务端进行... ...
- linux 中c/c++实现终端命令行命令
在终端中可以从用下面命令获得帮助: man system 在c/c++代码中实现和在终端中输入的命令行一样的效果,以命令(audacious -p &)为例,该代码实现用audacious在后 ...
- 从jvm的角度来看java的多线程
最近在学习jvm,发现随着对虚拟机底层的了解,对java的多线程也有了全新的认识,原来一个小小的synchronized关键字里别有洞天.决定把自己关于java多线程的所学整理成一篇文章,从最基础的为 ...
- iOS开发tips-UITableView、UICollectionView行高/尺寸自适应
UITableView 我们都知道UITableView从iOS 8开始实现行高的自适应相对比较简单,首先必须设置estimatedRowHeight给出预估高度,设置rowHeight为UITabl ...
- runtime ---- iOS
1.runtime是什么?runtime是一套底层的C语言的API(包括C语言数据类型,C语言函数) 实际上平时我们写的OC代码底层都是基于runtime,实际上也就是最后都转成了runtime代码 ...
- 解决HTML导出Excel表数字变成科学计数法
- js 中导出excel 较长数字串会变成科学计数法 在做项目中,碰到如题的问题.比如要将居民的信息导出到excel中,居民的身份证号码因为长度过长(大于10位),excel会自动的将过长的数字串转 ...
- Javascript面对对象. 第一篇
Javascript,有两个种开发模式: 1.函数式(过程化)2.面对对象(oop),面对对象语言有一个标志,就是类,而通过类可以创建任何多个属性和方法,而Ecmascript没有类的概念,因此它的对 ...